Abstract
Developed by the Intel big data department, Apache Hadoop* authentication service (HAS) is a pluggable identity authentication framework based on Kerberos*. HAS supports integrating existing identity management systems of enterprises to Kerberos in the form of a plugin, so that security administrators do not need to migrate and synchronize between the existing user account system and the Kerberos database. In addition, a single HAS server instance supports multiple authentication plugins, and users can select one plugin for authentication at the client. Most components of the open source big data ecosystem can access HAS at a very low cost, and users can conveniently access various component services of the Hadoop* ecosystem by using identity information in the existing authentication system. HAS is implemented based on Apache Kerby* (an implementation version of Kerberos) and we will contribute HAS to the Apache Kerby project. According to the community plan, HAS will be released in Apache Kerby 2.0. The HAS framework has been used in Alibaba Cloud Elastic MapReduce (E-MapReduce (EMR))* and Cloud HBase*. These products implement multiple plugins based on the interface provided by HAS to enable connecting the existing identity management system to a Kerberized cluster so that user identity information can be better managed and the maintenance cost can be reduced.
1. Background
1.1 Authentication in Apache Hadoop* cluster
The security issue of Hadoop clusters covers authentication and authorization, as shown in Figure 1. Authentication refers to the process of verifying a user’s identity. Services can be accessed only after users provide valid identity information. Authorization refers to the access control over specific resources when a user accesses services. Authentication is the foundation of authorization. Authorization without identity authentication is not secure. The combination of authentication and authorization can prevent attackers from counterfeiting valid users and obtaining permissions so as to ensure the security of the system and data.
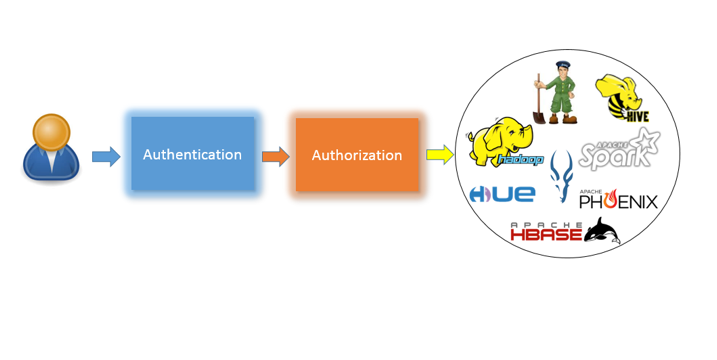
Figure 1. Authentication and authorization
Authentication in a Hadoop cluster includes service authentication and user authentication.
1.1.1 Service authentication
The open source big data ecosystem has many components such as Hadoop Distributed File System (HDFS)*, YARN*, and HBase. These components start related service processes, for example, NameNode and DataNode, on nodes of the cluster. If a new machine is added as DataNode to join the HDFS cluster, the DataNode can receive data. If a service is allowed to join the system without authenticating its identity, the data may be illegally obtained. If the HDFS service enables service authentication, only nodes with valid identity information can join the cluster.
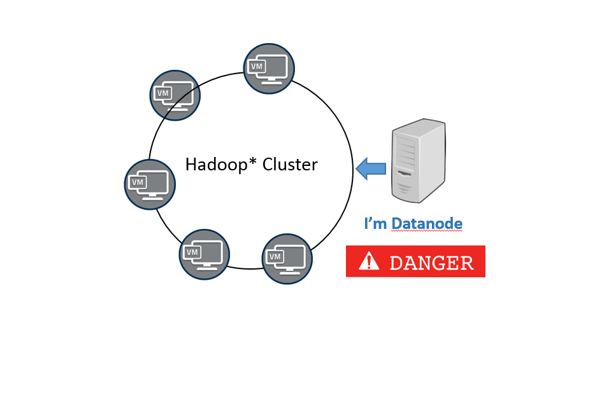
Figure 2. Without service authentication
1.1.2 User authentication
Most big data components implement permission control based on user or group. If user authentication is not used, the service just trusts the identity information provided by clients; that is, so long as a client accesses the service using a user ID, the service uses the user for permission check. Therefore, it is easy for clients to counterfeit other users; for example, a super account of the HDFS. After secure user authentication is enabled, the behavior can be prevented by verifying user identity information before granting access.

Figure 3. Without user authentication
1.2 What is Kerberos
There are many authentication technologies. Kerberos is a secure network authentication protocol that is widely used and is implemented based on symmetric cryptographic technology. In the Hadoop big data ecosystem, Kerberos protocol is the only built-in user authentication mode that is secure. Most open source data components support Kerberos and can enable Kerberos authentication for both service and user. Kerberos provides authentication in the form of a third-party service; that is, Kerberos is independent of related services, and multiple services can use the same third-party Kerberos service.
When a user needs to access a service protected by Kerberos, the Kerberos protocol process can be divided into two phases—user identity authentication and service access.
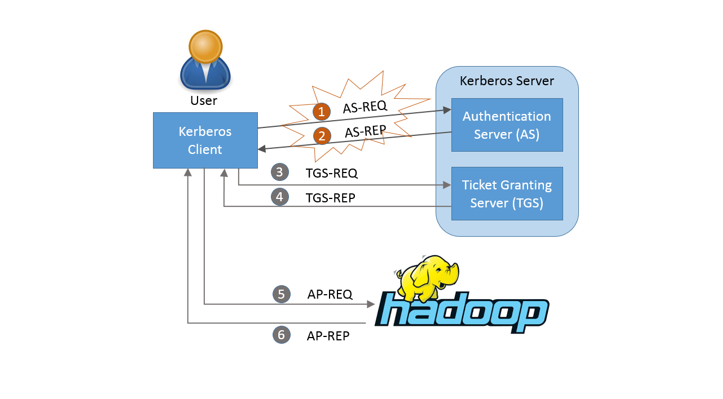
Figure 4. Kerberos protocol flow
1.2.1 User identity authentication
User authentication is a process of checking validity of identity information provided by users in the Kerberos authentication service. Identity information can be user names and passwords or information that can provide real identities in other forms. If user information passes the validity check, the Kerberos authentication service returns a valid ticket-granting ticket (TGT) token, proving that the user has passed identity authentication. The user uses the TGT in the subsequent service access process.
1.2.2 Service access
When the user needs to access a service, the user requests the ticket-granting service (TGS) from the Kerberos server based on the TGT obtained in the first phase, providing the name of the service to be accessed. TGS checks the TGT and information about the service to be accessed. After the information passes the check, TGS returns a service-granting ticket (SGT) token to the user, as shown in Step 4 in Figure 4. The user requests the component service based on the SGT and related user authentication information. The component service decrypts the SGT information in a symmetrical way and finishes user authentication. If the user passes the authentication process, the user can successfully access related resources of the service, as shown in Step 5 and Step 6 in Figure 4.
The TGT obtained in the first phase can be cached at the client (within a valid time) so long as the TGT is still valid. The user can directly use the TGT to access the service in the second phase and access multiple component services with single sign-on (SSO). The pluggable authentication mode we propose in HAS is a change to the first phase.
2. Introduction to HAS
2.1 Challenges
At present, the Hadoop big data ecosystem only embeds and supports Kerberos authentication mode as the only secure authentication. However, using Kerberos authentication on the big data platform is challenged in many aspects. First, we don’t have a complete Java* Kerberos library. The support provided by the Java* Development Kit/Java* Runtime Environment (JDK/JRE) lacks complete encryption and checksum types and the Generic Security Standard Application Programming Interface/Simple Authentication and Security Layer (GSSAPI/SASL) layer is hidden. It is difficult to change and add functions. Second, Kerberos leads to much overhead in deployment. Kerberos is essentially a protocol or secure channel. If authentication details can be hidden to common users, the complexity can be greatly reduced. Enterprises or Internet companies have their own identity authentication systems in multiple scenarios; for example, the cloud identity resource management system generally provided by a cloud provider for enterprises. However, Kerberos used by the Hadoop big data platform does not support other authentication mechanisms, except for password authentication. It is difficult to connect the existing identity authentication system to the Kerberos authentication flow.
HAS aims to address these challenges and issues. It provides a complete authentication solution for the Hadoop open source ecosystem. HAS is implemented based on Apache Kerby, which is a Java* implementation version of Kerberos protocol. Kerberos and the use of Kerberos in the big data ecosystem have been tested for a long time, which greatly reduces the risk of HAS implementation. HAS proposes a new authentication mode. By integrating with the existing authentication and authorization system, HAS makes other authentication modes supported on Hadoop/Apache Spark* possible, except for Kerberos. In addition, this authentication mode does not require separate maintenance of the identity information. This greatly reduces complexity and risk of enterprise identity management. In addition, HAS provides a series of interfaces and tools to simplify and hide Kerberos for end users.
2.2 HAS system architecture
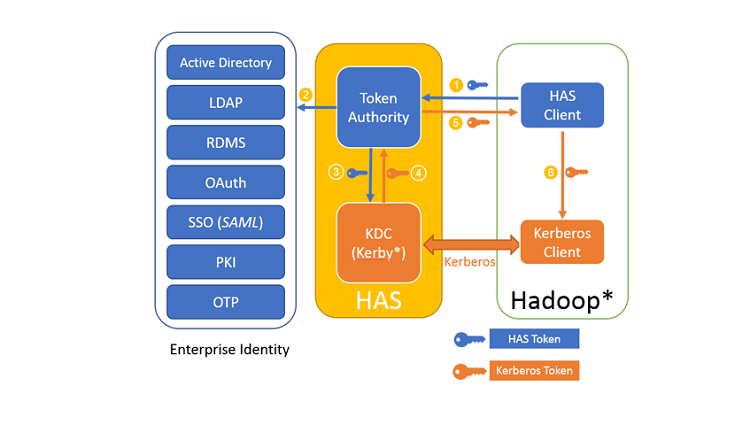
Figure 5. HAS system architecture
Benefiting from the basic work of Apache Kerby, HAS implements a new authentication solution for the Hadoop open source big data ecosystem at a lower cost. Apache Kerby is a sub-project of the Apache Directory* and is a Java version of Kerberos. HAS uses the efficient and high-availability key distribution center (KDC) provided by Kerby as a part of the server to issue the Kerberos ticket. The token authority part in HAS converts information of the existing authentication system (for example, OAuth2.0) into a token and exchanges the token for a Kerberos ticket in the Kerby KDC. After the Kerberos ticket is obtained, services in the Hadoop cluster can be accessed through the Kerberos protocol flow.
2.3 Key points of HAS implementation
- Hadoop services continuously use the original Kerberos authentication mechanism.
Before the cluster is deployed, the keytab used by each node is distributed to reliable locations. When the cluster is started and runs, nodes in the cluster can be used properly only after the nodes are authenticated by the KDC of HAS through the keytab. Nodes that attempt to counterfeit cannot communicate with nodes inside the cluster because the nodes do not obtain key information in advance. In this way, malicious use or tampering of the Hadoop cluster is prevented and the reliability and the security of the Hadoop cluster are guaranteed.
- Hadoop users can also continue to log in using a familiar authentication mode.
HAS is compatible with the MIT Kerberos protocol. Users can also be authenticated by using passwords or keytabs before accessing corresponding services.
- In the new authentication mechanism, the combination of your plugin and the existing authentication system can be customized and implemented.
The new authentication mechanism in HAS adopts the plugin mode to connect to the existing authentication system and features high customizability. Multiple authentication plugins can be implemented based on user requirements.
- Based on the new authentication mechanism, security administrators don’t need to synchronize user account information to the Kerberos database.
Because user account information does not need to be duplicated, the maintenance cost is reduced and the threat of information leakage is reduced.
2.4 HAS protocol flow
HAS is compatible with Kerberos and extends Kerberos functionality. It proposes a new authentication mechanism, called Kerberos-based token authentication. This mechanism is an implementation of TokenPreauth. TokenPreauth is used to integrate Kerberos identity authentication and the system based on tokens and helps Kerberos evolve on the cloud and the big data platform. Compared with traditional Kerberos authentication, this new authentication mode has the following advantages: 1. The KDC (HAS server) does not need to store any user information in advance; 2. Multiple users can execute tasks on one machine at the same time. Because HAS does not rely on other authentication modes in Hadoop, Hadoop needs only minimum change. Figure 5 shows the flowchart of Kerberos-based token authentication.
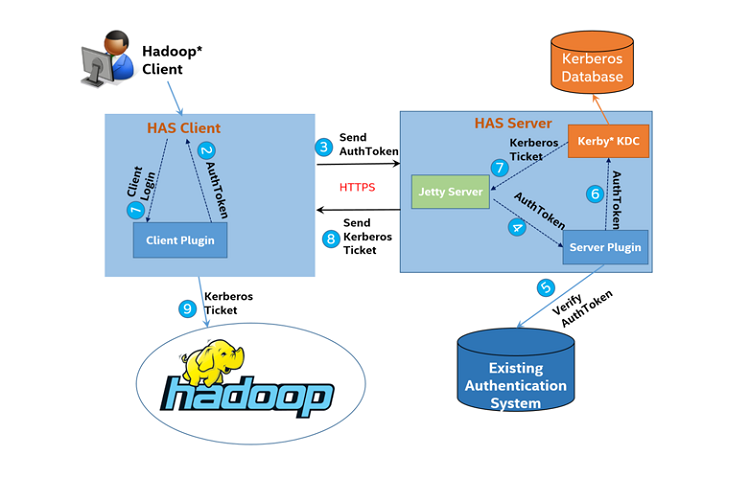
Figure 6. Kerberos-based token authentication
Assume that user A wants to access the HDFS and view file content in the root directory. The detailed flow is as follows after “hadoop fs –ls/” is entered in Hadoop Shell:
- Hadoop Shell invokes HasClient, and HasClient then checks the plugin type in the configuration file and invokes the corresponding client plugin.
- The client plugin collects user authentication information, for example, password, and packs the user information in AuthToken.
- HasClient sends the AuthToken to HasServer over HTTPS.
- After HasServer receives the AuthToken from HasClient, HasServer invokes the corresponding plugin on the server.
- The plugin on the server verifies the user identity information packed in the AuthToken in the existing authentication system.
- If the information is successfully verified, the plugin returns an AuthToken that passes verification to the KDC.
- After the KDC receives the AuthToken, the KDC issues a Kerberos ticket.
- HasServer sends the Kerberos ticket to HasClient over HTTPS.
- After Hadoop Shell obtains the Kerberos ticket, Hadoop Shell can continue with the subsequent access process and finally obtain data.
It should be noted that if Hadoop uses Kerberos authentication mode based on a password, Hadoop can only obtain the user name from the authentication result and obtains information such as user group by using another method before performing authorization. However, in the new authentication mechanism “Kerberos-based token authentication”, when HAS obtains the Kerberos ticket issued by the KDC, the JSON Web Token (JWT)* is encapsulated in the authorization data. The token includes rich identity information. After the Hadoop service obtains the ticket, the Hadoop service can decapsulate the token and further use information in the token for fine-grained authorization.
3. Use Scenario of HAS
Generally, Internet companies or cloud service providers have their own identity authentication systems. If these companies want to combine these systems with Hadoop, they only need to implement plugins based on HAS framework to integrate their user authentication systems with Hadoop, as shown in Figure 7.
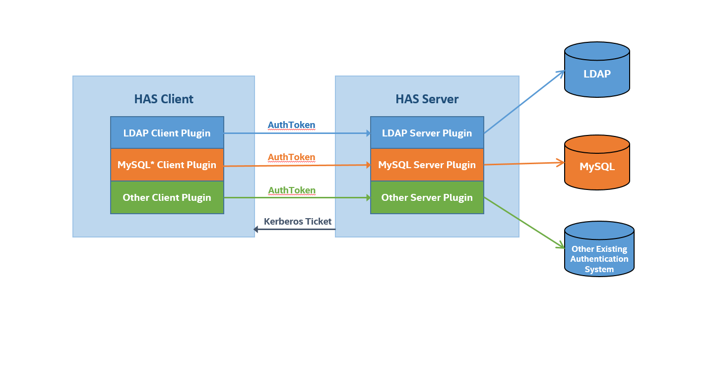
Figure 7. HAS plugins
To develop their own authentication system plugins, enterprises or companies need to complete the following steps:
1. Implement a pair of plugin interfaces, namely the client plugin interface and server plugin interface. Figure 8 shows information about the interfaces.
2. Deploy the client plugin on Hadoop client and server plugin on the HAS server.
3. Configure the plugin type to be written to interfaces in the configuration file of HAS
HAS client plugin HasClientPlugin
// Get the login module type ID, used to distinguish this module from others.
// Should correspond to the server side module.
String getLoginType()
// Perform all the client side login logics, the results wrapped in an AuthToken,
// will be validated by HAS server.
AuthToken login(Conf loginConf) throws HasLoginException
HAS server plugin HasServerPlugin
// Get the login module type ID, used to distinguish this module from others.
// Should correspond to the client side module.
String getLoginType()
// Perform all the server side authentication logics, the results wrapped in an AuthToken,
// will be used to exchange a Kerberos ticket.
AuthToken authenticate(AuthToken userToken) throws HasAuthenException
4. HAS Use Case Study
4.1 E-MapReduce* authentication security practice
Alibaba Cloud E-MapReduce uses HAS framework and implements plugin authentication modes such as Resource Access Management (RAM) and Lightweight Directory Access Protocol (LDAP), that is, AccessKey of RAM, and user information of LDAP can be used to submit jobs and access the secure cluster of Kerberos.
4.1.1 RAM identity authentication plugin
After the RAM plugin is implemented in HAS, the EMR cluster can support Kerberos to use RAM identity information for authentication. The primary account administrator in RAM can create a sub-account on the user management page of RAM and realize access control over resources on the cloud through the sub-account. Then the administrator downloads the AccessKey of the sub-account and provides it to the corresponding developers. Later, the developers can configure the AccessKey so that users can directly use the AccessKey in the RAM sub-account to access the Kerberized Hadoop cluster. Different from the traditional MIT Kerberos mode in which principles are added on the Kerberos server in advance, identity authentication based on RAM helps enterprises better manage user identity information.
4.1.2 LDAP identity authentication plugin
By implementing the LDAP plugin in HAS, EMR makes identity information in LDAP connected to Kerberos. For example, identity information managed by LDAP of Apache Knox*/Hue*, that is, Knox, Hue and Kerberos share one set of LDAP identity information, so that the EMR cluster can support Kerberos clients in using account information in LDAP as identity information for identity authentication. Users can use the LDAP service (ApacheDS*) configured in the EMR cluster or other services that already exist by performing related configuration on the HAS server side.
4.2 Cloud HBase* authentication security practice
Cloud HBase of Alibaba Cloud also implements plugins of multiple authentication modes; for example, account password, RAM, and LDAP. Users can select one plugin authentication mode based on actual conditions. The identity authentication mode based on account password is different from the password authentication mode in Kerberos. The similarity of the two authentication modes is that account passwords are used and the information is stored in the Kerberos database. However, different from the traditional Kerberos authentication mode in which the kinit command needs to be run first before the secure HBase cluster can be accessed, the authentication mode using the HAS plugin provides the following operation: After a user accesses the cloud HBase secure cluster by using HBase Shell or accesses the remote secure HBase cluster by using HBase Java API, the client plugin automatically reads the account password from the configuration file, sends the password to the server, and completes user identity authentication. In this process, specific authentication details are hidden to users and the use complexity is reduced.
5. Outlook and Summary
5.1 Optimization of security and performance by using Intel Platform
HAS is being improved. In the future, we will optimize HAS in terms of security and performance by using Intel platform.
First, we will use the Intel® Software Guard Extensions (Intel® SGX) technology to improve security of HAS. Intel® SGX aims to improve security of application codes and data. It allows application developers to protect sensitive information from being illegally accessed or modified by fraud software running under higher privileges. After the next-generation Intel® Xeon® Scalable processor is launched with support for Intel SGX, we will use it to store Keytabs, credentials and certificates generated and used during HAS authentication in a trusted enclave, to protect them from being attacked by malicious software.
Secondly, after Kerberos authentication is added to the Hadoop open source big data cluster, Intel® AES New Instructions (Intel® AES-NI) can be used to accelerate and optimize the encryption and signature algorithms during Kerberos authentication. As a result, the time and overhead of the authentication process are reduced.
5.2 Summary
HAS is compatible with the Kerberos protocol authentication mode, so all components in the Hadoop ecosystem can use the original Kerberos authentication mode provided by HAS. HAS extends Kerberos with more flexible identity integration. The new authentication mechanism (Kerberos-based Token Authentication) supports most components in the Hadoop ecosystem and makes little or no change to the components. HAS provides a series of interfaces and tools to help simplify deployment. It also provides interfaces to help users implement plugins to integrate Kerberos with other user identity management systems. At present, HAS supports ZooKeeper*, MySQL*, and LDAP*. HAS will be contributed to the Apache Kerby project. We will merge it in the primary JIRA. According to the community plan, the HAS function will be released in Kerby 2.0.