Authors: Zhenyu Yu, Vaibhav Shankar, Prashant Kodali, Michael Cheng, and Sushma Venkatesh Reddy, Intel
Abstract
AVX (Advanced Vector Extensions) are SIMD (Single Instruction, Multiple Data) extensions to the x86 instruction set for significant performance acceleration by parallel computation1. Although the latest high-end Chrome OS* (web-based operating system) device is built on Intel® Core™ architecture with AVX support, many software components are not fully utilized or optimized for it. In this paper, we will present our work in identifying software components that have such gap through comparative analysis (Chrome OS vs. Clear Linux*) and in enabling AVX support to attain significant performance improvement. As a result, more than 5% performance gains on Chrome OS was achieved on various web benchmarks, which effectively helps Intel to up sell Core platform for higher ASP (average selling price) through by better competitive leadership.
Introduction
AVX (Advanced Vector Extensions) are extensions to the x86 instruction set for microprocessors to support SIMD (Single Instruction, Multiple Data) operations for significant performance acceleration by parallel computation. AVX has evolved for 3 generations: AVX for 256-bit float point SIMD over SSE; AVX2 for 256-bit integer SIMD over AVX and AVX-512 for 512-bit SIMD over 256-bit SIMD.
Chrome OS is a web-based operation system, which is based on Linux and use Chrome browser as user interface. Chrome OS device, like Chromebook, is a new kind of thin and light client device based on Chrome OS. The device is primarily designed for various tasks including internet browsing, social networking, web productivity, education and entertainment, etc. Recently Chrome OS device is becoming more and more popular with a projected annual growth rate of 13.8% till 2023. Beyond the product capability, its performance becomes the key differentiating factor while selecting of Chrome OS device, like Chromebook 6.
Chrome OS device is mostly built on Intel platform, covering both Atom and Core architectures. Atom-based product occupies the large volume of marketing share and Core-based product mostly targets for high-end segment. On the Core architecture, AVX is one of the biggest differentiation technologies for better performance and user experience, which is well demonstrated on Clear Linux. Intel's recent Chromebook is built on the platform that supports AVX2. However, many software components of Chrome OS are not fully utilized or optimized for it.
In order to accelerate the selling of Core-based Chrome OS device, we’ve identified which software components have abovementioned gap through comparative analysis (Chrome OS vs. Clear Linux) and enabled AVX support respectively for differentiated performance improvement. As a result, more than 5% performance improvement on Chrome OS was achieved on various web benchmarks, which effectively helps Intel to up sell the Core platform for higher ASP (average selling price) by better competitive leadership.
Body
Clear Linux is an open source, rolling release Linux distribution led by Intel and optimized for performance. Clear Linux fully adopts AVX in its kernel, libraries and packages for IA platform differentiation. By comparing AVX utilization on Chrome OS against Clear Linux, we can verify the AVX usage status and identify the corresponding gaps to close.

Figure 1. Physical register file in Intel® architecture
We use the SEP / VTune profiling tool to collect hardware event data for AVX usage. The specific event we profiled is AVX_PWR_GATING.PRFV1_USED, which refers to the clock cycle count of PRF (Physical register file) module in actual use. PRF is a key enabler for AVX out of order execution since Sandy Bridge architecture4 (refer to Figure 1) so that the usage of PRF can reliably and directly reflect the AVX utilization from system perspective.
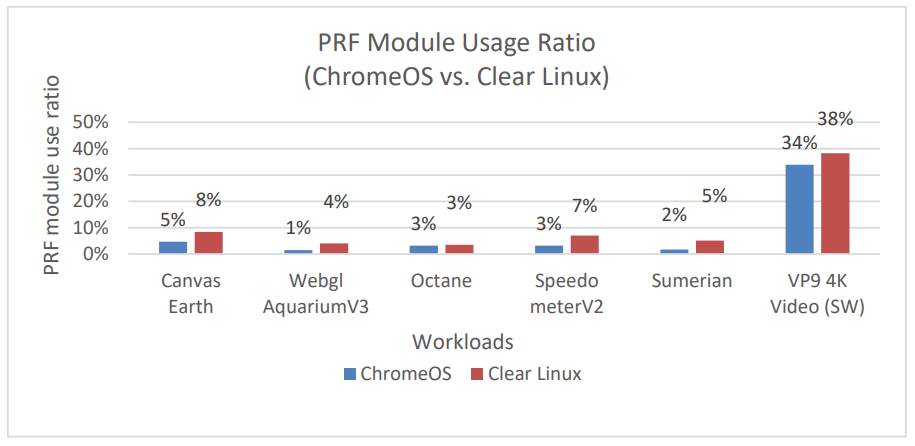
Figure 2. Comparison of PRF module in use ratio between Chrome OS and Clear Linux
Among the available platforms when we carried out investigation, we chose Kaby Lake with both Clear Linux and Chrome OS installed for data collection. Using SEP / VTune, we collected PRF counter against a wide range of popular browser workloads covering scenarios of rendering, media and computation (refer to Figure 2).
Based on the profiling data we collected, we found that PRF module is used more on Clear Linux, indicating there is more AVX instruction running comparing to Chrome OS. At the same time, we also chose several workloads which use relatively more AVX instructions to understand which software components have the gaps. Using VP9 4K video playback as example (refer to Figure 3), graphics driver (i965) and runtime libraries, such as libc and libpthread, are the outstanding ones.
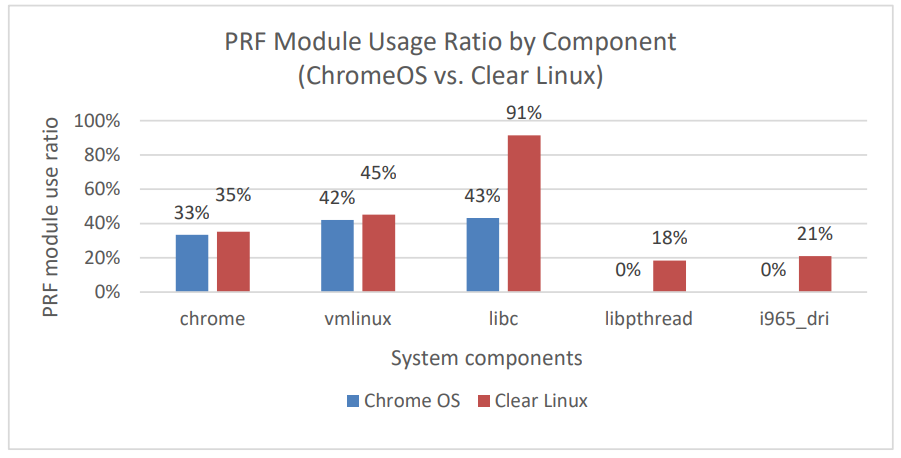
Figure 3. Comparison of PRF module in use ratio, breaking down into SW components
Besides the black-box approach through data driven analysis, we also resorted to white-box source scan to identify the AVX gap based on our knowledge and the usage of specific software components. As Chrome browser is one of the largest components in Chrome OS, we chose Chrome browser and the 3rd party libraries used by Chrome for further investigation. As a result, two issues have been identified and listed below:
- Compiler generated AVX instruction. In current Chrome browser building configuration, one general architecture, x86-64, is specified as target architecture for all 64-bit IA processors. Considering Chrome OS device is separately designed and built on one specific hardware platform, we can propagate the corresponding platform information to Chrome browser to choose appropriate instruction set, like AVX, for differentiated performance gains.
- AVX friendly algorithm and function. Besides compiler code generation, performance intensive function can further be optimized according to runtime situation. For example, in Skia5, which is a very famous Canvas2D engine used by Chrome, we found that many functions are only optimized to SSE version, instead of the latest AVX features.
Although AVX is powerful, it is not a silver bullet for differentiating performance under all circumstances. For some functions in specific workloads, enabling AVX may bring performance regression instead. Hence we need to be careful in choosing and applying AVX. Based on our experience, possible reasons for AVX performance penalties include:
- AVX to SSE transition overhead. Processor need to save/restore YMM registers when transiting between 256-bit AVX and SSE instruction, which causes performance penalty.
- Data alignment. 256-bit AVX requires data aligns to 32 byte in memory, otherwise penalty would happen when misaligned memory access takes place.
- Data length. Although AVX can process more data at the same time than SSE, it also needs more cycles to fill and d the pipeline. If there is no sufficient data to be processed, AVX cannot show more performance benefits than current SSE implementation.
Results
Since we know which software component needs to be optimized through AVX, tuning the compilation flag passed to compiler is one of the easiest way to close the gap. Modern compilers (GCC, Clang, etc.) fully supports AVX generation from C/C++ code. The major compilation flag we used is -march=, which can enable available features for specified architecture. This approach is applicable to every component in Chrome OS. Currently we’ve done our experiments on Chrome browser and graphics driver (i965) in prioritized manner.
During our experiments, we consider two compilation options, namely -march=haswell and march=skylake, and chose Core m3-7Y30 (Kaby Lake platform having the same CPU architecture as Sky Lake) Chromebook to evaluate the performance impact.
Based on our experiment result, we can see ~2% more performance on rendering intensive workloads after we enable AVX in graphics driver (i965, see Figure 4). At the same time, we can also observe up to 5% performance gains on various browser benchmarks (see Figure 5)
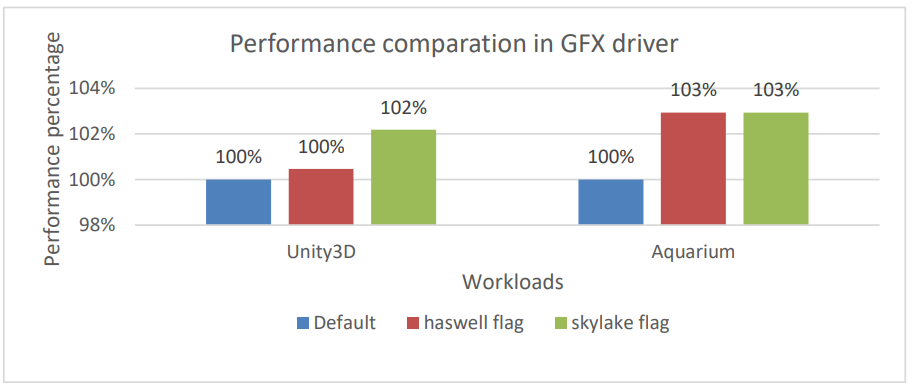
Figure 4. Performance comparison of AVX enabling in graphics driver
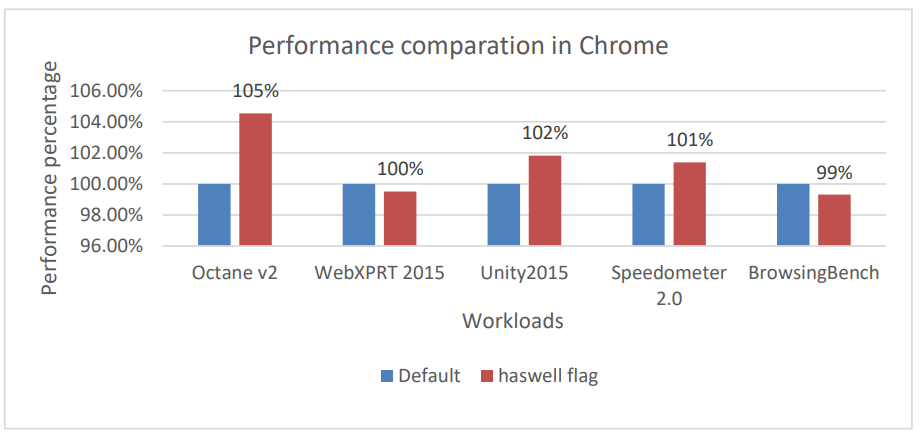
Figure 5. Performance comparison of AVX enabling in Chrome
With regards to runtime libraries, we chose glibc as the starting point for experiment. In glibc, AVX instruction is directly hand-written in the source of corresponding hot function (see Figure 6). So as a later version of glibc is used, more functions are optimized with AVX. For example, glibc 2.27 starts to support AVX2, and in glibc 2.28, it also applies AVX to hot function for data transferring.

Figure 6. Code snippet of AVX implementation of memcpy in glibc
As default glibc 2.23 in Chrome OS is outdated, we chose relatively newer glibc version 2.27 for stability consideration, with selected AVX patches backported from latest glibc version 2.28 for experiment. In order to utilize its fullest potential, we need at first update glibc within the cros_sdk, a Gentoo base development environment for Chrome OS, and follow by fixing all bugs that was induced in the upgrade.
We also chose Core m3-7Y30 (Kaby Lake platform having the same CPU architecture as Sky Lake) Chromebook to evaluate the performance impact. The experimental design involves keeping all content same and varying one variable at a time. Since for Kaby Lake Chromebook, we had 4.14 kernel and older version of Android, we had to make extra checks to make sure we can build images with glibc 2.23 and newer version of Android. The table below (Refer to Table 1) gives the parameters for the experiment.
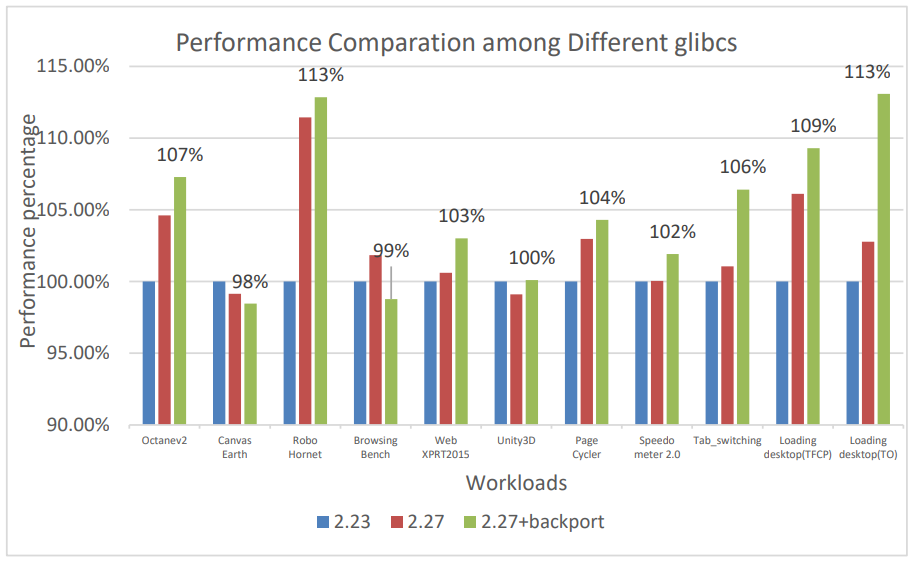
Figure 7. Performance comparison of AVX enabling in runtime library (glibc)
Based on our experiment result (refer to Figure 7), we can see that web user experience workloads, like page-loading and web browsing benchmarks, get the most performance gains from AVX optimized glibc, up by 9%~13%. At the same time, most of other browser benchmarks also see moderate performance improvement of 3%~6%.
Table 1. Build parameters for glibc experiment
| Variables | Image labeled as “2.23” | Image labeled as “2.27” | Image labeled as “2.27+backport” |
|---|---|---|---|
| Chrome OS kernel | 4.14 | 4.14 | 4.14 |
| Glibc version | 2.23 | 2.27 | 2.27+ backport |
| Android version | Android P | Android P | Android P |
Summary
Although the latest Intel Core architecture has AVX support, many software components running on it are not fully utilized or optimized for AVX. Therefore, thorough comparative analysis is necessary for those key software components, such as graphics driver, runtime libraries, Chrome browser, etc., for AVX optimization opportunities. At the same time, AVX enabling should be carefully designed and implemented using different approaches under different circumstances, including the avoidance of unnecessary performance regression in some special conditions. Finally many powerful developer tools, like the SEP/VTune and Compiler, can help us enable AVX quickly. Based on abovementioned, as a result, we achieved more than 5% performance improvement on Chrome OS, which effectively helps Intel to up sell Core platform for higher ASP (average selling price) by better competitive leadership.
Acknowledgments
We would like to appreciate Jaishankar Rajendran, Dong-Yuan Chen and his team, Tianyou Li and his team, Yongnian Le, Hong Zheng and Shuangshuang Zhou for their support to our work.
References
1. Gregory Lento, Optimizing Performance with Intel Advanced Vector Extensions, 2014
2. Why a Chromebook isn't the same thing as a budget laptop, 2016
3. An Overview of Intel’s Clear Linux, its Features and Installation Procedure, 2018
4. Anand Lal Shimpi, Intel's Sandy Bridge Architecture Exposed, 2010
5. Skia Graphics Library
6. Running Android in a Container