In this blog post I'm going to start exploring the topic of blur filters. My original intention was to…
- Provide an overview and optimization ideas for a few of the popular real time image blur filters, applicable on very different range of hardware (from sub-4W mobile device GPUs to high end 250W+ desktop GPUs).
- Give an example of the techniques that runs on Windows Desktop OpenGL and Android OpenGL ES 3.0 and 3.1, including compute shader use on OpenGL ES 3.1.
...but I realised that it might take more than one blog post (and a lot more work) to properly explore the topic, so below is the first installment. Thus, please feel free to contribute ideas and corrections in the comments section at the bottom.
Image Blur Filters
Image blur filters are commonly used in computer graphics – whether it is an integral part of a Depth of Field or HDR Bloom, or another post process effect, blur filters are present in most 3D game engines and often in multiple places. Blurring an image is a fairly trivial thing to do: just collect neighboring pixels, average them and you get your new value, right?

Bloom and Depth of Field – two common uses of a blur filter
Well, yes, but there are different ways of doing it with different visual results, quality and performance.
In this article I’ll focus primarily on performance (and quality trade-offs), as the difference in cost between a naïve and a more optimal solution can sometimes be an order of magnitude, but also different algorithms can be more optimal on different hardware.
I have set out to explore and contrast three most common techniques and how they behave in a sample of modern GPU hardware, ranging from mobile GPUs to integrated graphics and discrete GPU cards. Please feel free to comment if you are using something better or different - I would love to add it to the sample for profiling and testing, and provide with the next update.
These three algorithms are:
- Classic convolution blur using Gaussian distribution
- A generalization of a Kawase Bloom – old but still very applicable filter presented by Masaki Kawase in his GDC2003 presentation “Frame Buffer Postprocessing Effects in DOUBLE-S.T.E.A.L (Wreckless)”
- A compute shader based moving average algorithm inspired by Fabian “ryg” Giesen’s articles: Fast blurs 1 and Fast blurs 2.
They are all generic algorithms that are fully applicable to effects like a Bloom HDR filter. However, in a specific scenario, for example for use in Depth of Field, they would require additional customization (such as weighted sampling to avoid haloing/bleeding) which can impact relative performance. Even more modification would be needed to achieve something akin to a median filter (Median filter). However, the optimizing techniques and numbers presented here should be helpful even if you are setting out to do a special blur like Bokeh (Bokeh), Airy disk (Airy disk) or various image space lens flare effects. The sample also provides a real time Graph visualization which can be used to analyze any custom blur technique.
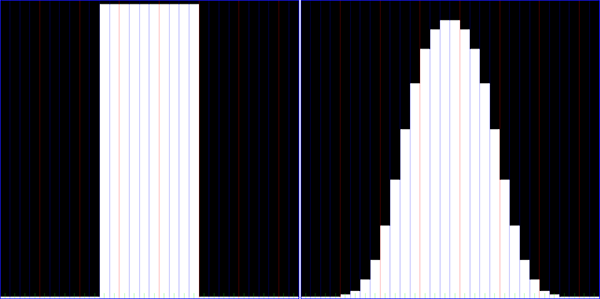
Cross-section of a white 10x10 pixel block on black background before/after application of a 15x15 Gauss blur filter
It should also be noted that, although generic algorithms are easier to understand, implement, reuse and maintain, there are cases where specialized ones might do a better job. One such example (although I have not compared it with algorithms presented here) is presented here (based on "HDR: The Bungie Way. Microsoft Gamefest 2006.").
2D Gaussian Blur Filter
Let’s start with a “Gaussian blur filter”, a widely used filter that reduces image detail and noise (for example, to simulate lens out of focus blurring). It is called Gaussian because the image is blurred using a Gaussian curve (Gaussian function).
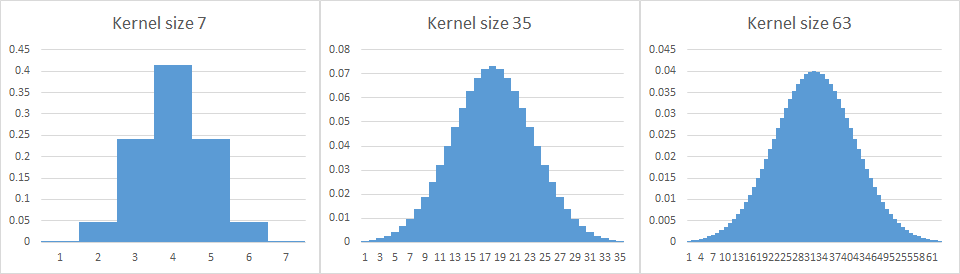
Examples of 1D convolution filter kernels with Gaussian “bell curve”
Naïve Implementation
The common way of doing Gaussian blur is to use a convolution kernel (Convolution). This simply means that we build a 2D matrix of normalized pre-calculated Gaussian function values and use them as weights, and then do a weighted sum of all neighboring pixels in order to calculate each pixel’s new (filtered) value.
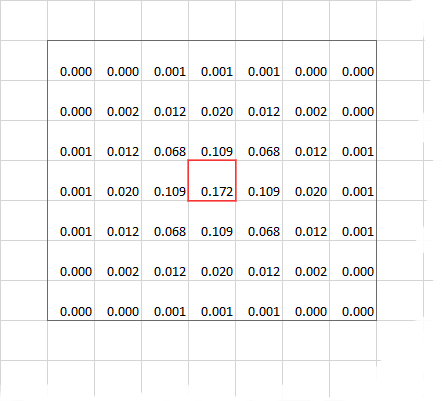
An example of a 7x7 convolution kernel with Gauss distribution values. Adding them all together should yield 1 as values are normalized.
For a 2D filter, this also means that to calculate each pixel, we have to do a kernel sized double loop so the algorithm complexity becomes O( n^2 ) for each pixel (where n is the kernel height and/or width, since they are the same). For anything but smallest kernel sizes, this gets very costly, very quickly.
Separable Horizontal / Vertical
Thankfully, 2D Gaussian filter kernel is separable as it can be expressed as the outer product of two vectors, which in turn means that the filter can be split into two passes, horizontal and vertical, each with O( n ) complexity per pixel (where n is the kernel size). This drastically reduces computation cost while providing the exact same results.
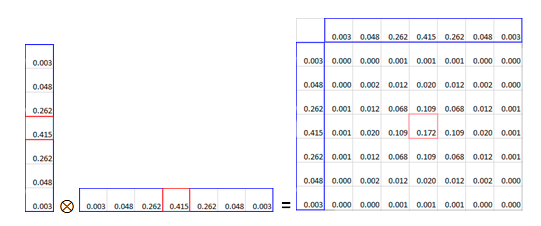
Example of a 7x7 convolution kernel done using the two pass separable filter approach
It is useful to note that at this stage, the same algorithm can be used for any other applicable convolution (see link above for more details), such as some sharpening filters or edge detection such as Sobel filter.
Better Separable Implementation Using GPU Fixed Function Sampling
So far we have ignored actual hardware implementation, but when we apply this algorithm to a real world scenario, the Gaussian blur filter pass needs to happen in real time, often on images with 1280x720 or more pixels. Modern GPUs (both on mobile and desktop devices) are designed with this in mind so it is no wonder that they can do it in just a few milliseconds – however, saving some of those few milliseconds could still mean a difference between a game running at sub-optimal 25 or smooth 30 frames per second.
Algorithmically much better, this separable filter can run on highly parallel GPU execution units as it is, by executing image reads, math and writes in the form of GPU shaders.
Shader pseudocode for horizontal separable gauss 7x7 filter pass:
color = vec3( 0, 0, 0 );
for( int i = 0; i < 7; i++ )
{
color += textureLoad( texCoordCenter + vec2( i, 0 ) ) * SeparableGaussWeights[p];
}
return color;
However, as detailed in https://rastergrid.com/blog/2010/09/efficient-gaussian-blur-with-linear-sampling/, we can take advantage of fixed function GPU hardware, namely samplers, which can load two (in our case) neighboring pixel values and return an interpolated result based on the provided texture coordinate values, all for approximately the cost of one texture read. This roughly halves the number of shader instructions (halves the number of sampling instructions and slightly increases the number of arithmetic instructions) and can increase performance by a factor of two (or less, if we are memory bandwidth limited).
To do this, we have to calculate new set of weights and sampling offsets such that when sampling two neighboring pixels with a linear filter, we get an interpolated average between them which is in correct proportions in regards to their original Gauss separable filter weights. Then, we add all the samples up using the new set of weights, and we end up with a filter that is much faster but has identical quality compared to the non-optimized naïve implementation that we started from.
Actual GLSL code from the sample used to do a separable horizontal or vertical pass for a 7x7 filter:
// automatically generated by GenerateGaussFunctionCode in GaussianBlur.h
vec3 GaussianBlur( sampler2D tex0, vec2 centreUV, vec2 halfPixelOffset, vec2 pixelOffset )
{
vec3 colOut = vec3( 0, 0, 0 );
////////////////////////////////////////////////;
// Kernel width 7 x 7
//
const int stepCount = 2;
//
const float gWeights[stepCount] ={
0.44908,
0.05092
};
const float gOffsets[stepCount] ={
0.53805,
2.06278
};
////////////////////////////////////////////////;
for( int i = 0; i < stepCount; i++ )
{
vec2 texCoordOffset = gOffsets[i] * pixelOffset;
vec3 col = texture( tex0, centreUV + texCoordOffset ).xyz +
texture( tex0, centreUV – texCoordOffset ).xyz;
colOut += gWeights[i] * col;
}
return colOut;
}
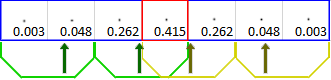
4 texture samples used to get 7 sample separable filter (two center ones overlap for code simplicity reasons – this inefficiency becomes irrelevant with bigger kernels), with arrows marking offsets (gOffsets from code above).
Testing shows that this two approach can bump up performance by nearly a factor of two, increasing with kernel size. However, for very large kernels, the algorithm becomes limited by memory bandwidth (hardware-specific) providing diminishing benefit: the effect starts being noticeable on Intel GPUs on kernel sizes at and above 127x127 (RGBA8), but is likely higher on discrete GPUs (not tested).
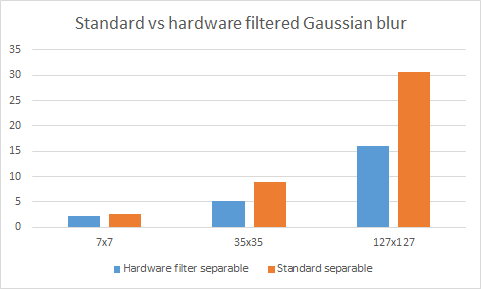
Effect of using hardware sampling and filtering on an i5-4350U Ultrabook (cost in milliseconds)
Very similar performance differences were observed both on discrete desktop GPU (Nvidia GTX 650) and a Bay Trail tablet CPU with integrated graphics (Atom Z3770) with tested (7x7, 35x35, 127x127) kernel sizes.
The FastBlurs sample demonstrates this optimized Gauss filter implementation and contains GLSL shader code generator (in GaussianBlur.h) to generate any custom kernel size. In addition, the GLSL code can be generated by running the sample, selecting the required kernel width and clicking on the “Gaussian Blur” interface button repeatedly a few times.
Working in Lower Resolution
So, we’ve got a good Gaussian blur implementation – but our “getting-hit” in-game effect requires a large blur kernel and our target hardware is a high res mobile device. Gaussian is still a bit too expensive, can we do better?
Well, it turns out it is fairly common to sacrifice some quality and, since blurring is a low-pass filter (preserves low frequency signals while attenuating high frequency ones), down-scale to a smaller resolution buffer, for example to ½ by ½, perform the blur effect and then up-scale back to the original frame buffer. For the blur filter this has two big benefits:
- The number of pixels that need to be processed is reduced by 4 for a ½ x ½ intermediate blur buffer.
- Same kernel size in the smaller buffer covers 2 x 2 larger area, so for the same final effect the blur kernel should be reduced by ½ in each dimension.
These two things compound so that the cost for the similar effect is reduced by a factor of 8 when a ½ x ½ intermediate buffer is used, although there is a fixed cost associated with down-sampling to it, and up-sampling the results back into the main one. So this only makes sense for Blur kernels of, for example, 7x7 and above (smaller kernels are also not enough to hide losses in quality due to down-scaling and up-scaling).

Blurring using intermediate lower resolution buffer at approx. 1/6 of the computation cost
The main drawback is that with a small amount of blur (small blur kernels), the “blockiness” pattern from down-sampling to lower resolution and back becomes obvious, so this can be problematic if an effect needs to fade in/out, especially with moving images. This can be resolved, for fade-in and fade-out effects, by interpolating between blurred down-sampled and the final image for small kernel values. In some other cases, such as when using a blur filter to produce a Bloom effect, issues with lower resolution intermediate buffers are even more attenuated by movement and bloom function, so trial and error is often needed to find a more optimal blur filter resolution with regards to quality vs performance.
To stress the importance of working in smaller (½ by ½, or even ¼ by ¼) intermediate buffers whenever possible, I’ve used the accompanying sample to measure the time needed to blur an image 2560x1600 image on a big desktop AMD R9-290X GPU, and a 1280x720 image on a Nexus 7 tablet:
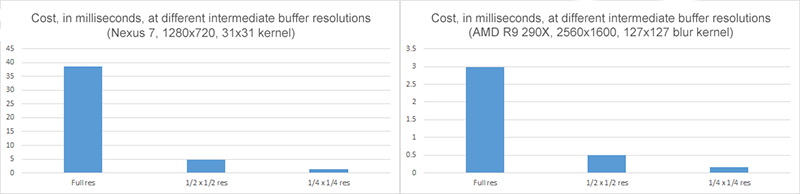
Impact of working in lower resolution intermediate buffers
In the case of R9-290X, a large blur kernel of 127x127 is used for the full resolution image, requiring around 3ms in computation time. Using ½ by ½ intermediate buffer requires a 63x63 blur kernel and executes in 0.5ms, producing nearly identical quality image at 1/6 of the time; ¼ by ¼ intermediate buffer requires only 0.17ms. Performance difference on Nexus 7 Android tablet is proportionally similar (running appropriate, much smaller workloads).
"Kawase Blur" Filter
So we’ve got an optimized Gaussian blur implementation and we are processing it in ½ by ½ resolution for our HDR Bloom effect (in a hypothetical game development scenario), but it is still costing us 3ms per frame. Can we do better? Dropping the resolution to ¼ by ¼ doesn’t look good enough, as it causes Bloom to shimmer on movement, and reducing the kernel size does not produce enough of the effect.
Well, one Bloom-specific alternative is the (already mentioned) Compute Shader HDR and Bloom (based on "HDR: The Bungie Way. Microsoft Gamefest 2006."). However, it requires a number of render targets, is a bit messier to implement and maintain, not very reusable as a generic blur algorithm and is, by default, fixed to one kernel size (making the effect screen resolution dependent and not easily “tweakable” by artists).
However, it turns out that there is a generic blur algorithm that can have even better performance than our optimized Gaussian solution – although there is a trade-off in in filter quality / correctness (it provides fair from ideal distribution, but is acceptable for most game engine purposes) – introduced by Masaki Kawase in his GDC2003 presentation “Frame Buffer Postprocessing Effects in DOUBLE-S.T.E.A.L (Wreckless)”. Initially used for Bloom effect, it can be generalized to closely match Gauss in appearance.
It is a multi-pass filter where each pass uses results from the previous one and applies small amount of blur, accumulating enough to approximate Gauss distribution. In each pass, the new pixel value is the average of 16 samples in a rectangular pattern at variable distance from the pixel center. The number of passes and sampling distance from the center varies depending on the expected result.

An example of 5-pass Kawase blur with 0, 1, 2, 2, 3 kernels, matching in output a 35x35 Gauss blur kernel. Marked in blue is 1 sample covering 4 pixels; marked in red is the destination pixel receiving averaged sum of those samples
This approach fully utilizes GPU Sampler hardware (Intel’s Ivy Bridge Graphics Architecture) to get four pixels with one sample call (4 samples / 16 pixel values per pass). The number of passes needed to achieve close equivalency to a specific Gauss distribution kernel size increases less than linearly with the Gauss kernel size.
The number of passes and kernel pattern of the four samples used to match specific Gauss filter kernels is, at the moment, based on empirical comparison – a more automatic approach will be explored in future updates to this article.
The sample provides a graph display used to enable more precise “matching” of different techniques to resemble Gauss filter distribution, and to ensure correctness of distribution.
Quality

Input values: 12x12 block of white pixels on black background
(Left: middle cross-section along x axis; right: top down view)
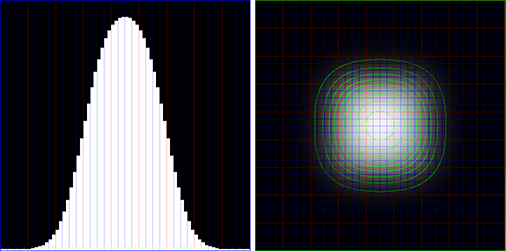
Values after applying a 35x35 Gauss filter
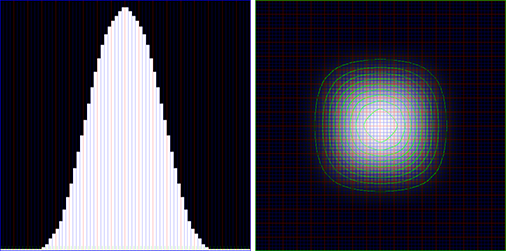
Values after applying a 5-pass Kawase filter with 0, 1, 2, 2, 3 kernels - closely (but not perfectly) matching the 35x35 Gauss filter
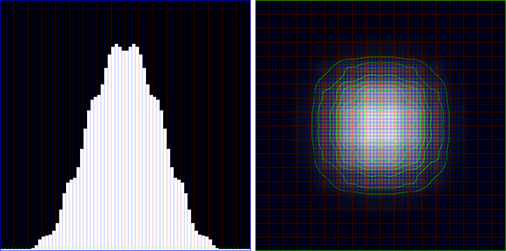
Values after applying a 4-pass Kawase filter with 2, 3, 3, 3 kernels - not closely matching… anything, but could be good for bright light streaks or a similar effect

From left: original image; 35x35 Gauss filter; closely matching Kawase filter; mismatched Kawase filter
Performance
Although better performing in almost all tested cases, the main impact of Kawase blur filter is at bigger kernels and some hardware benefits from it more (Nexus 7 specifically). Also, “bigger” GPUs need bigger working textures for the difference to become obvious.
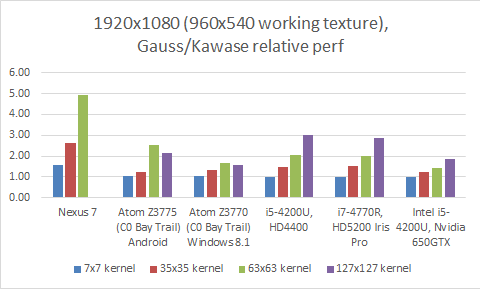
Gauss vs Kawase, performance at 1920x1080 (½ by ½ working texture)
(Nexus 7 numbers not shown for 127x127 Gauss kernel due to issues with big kernels)
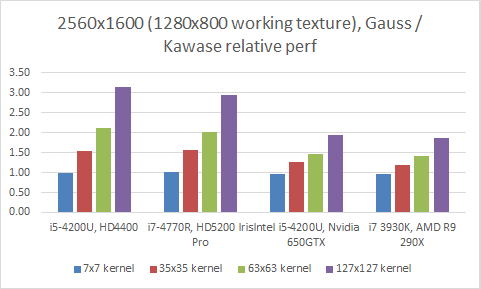
Gauss vs Kawase, performance at 2560x1080 (½ by ½ working texture)
(Intel 4th generation Ultrabook GPUs to discrete GPUs)
The sample measures the difference between drawing the basic scene (screenshot and moving triangles), and drawing the basic scene plus down-sampling to working texture size, applying blur and applying results back to the full resolution frame buffer texture.
Results show that Kawase blur seems to use 1.5x to 3.0x less computation time than the optimized Gauss blur filter implementation across the wide range of hardware, resolutions and kernel sizes, although it scales particularly well with bigger kernels and bigger working texture sizes, and on lower power GPUs.
Unfortunately, although the sample covers sizes up to 127x127, I don’t have (as of yet) a deterministic way of generating Kawase kernels to match arbitrary sized Gauss filter – this is one of the few things I plan to cover in the next article.
Moving Averages Compute Shader Version
Finally, it turns out it is possible to devise a simple, linear time per pixel blur filter ( with O( 1 ) complexity), by applying multiple passes of a “moving averages” box filter. However, due to the high fixed cost this approach seems to only starts reaching the performance of Gauss/Kawase filters on modern GPUs for very large blur kernel sizes, so it might only be applicable in very specific scenarios.
Still, it’s a cool thing to have in ones algorithm toolbox and could definitely come in handy. The moving averages box filter is explained in very fine detail in Ryg’s excellent articles (Fast blurs 1) but here is the short summary:
- A box filter is an image filter that replaces each pixel’s values with an average of m x n neighboring pixels (convolution filter kernel with all equal normalized values).
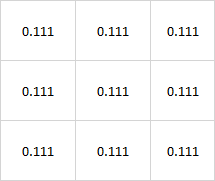
3x3 Box filter kernel
- 2D box filter can be achieved by doing 2 separable 1D horizontal/vertical passes, in the same way as described for the separable Gauss filter, for O( n ) complexity, however, in addition to that, it is possible to do each of the vertical and horizontal passes using “moving averages” for O( 1) complexity.
Moving averages basically does one pass over the whole column (or row), iterating over the whole length:
- For the first kernel size elements, a sum is created and averages are written into the output.
- Then, for the each new element, a value of the element no longer covered by the kernel size is subtracted from the average, and the value to the right is added. Averaged sum (divided by kernel size) is then written to the output.
The effect of this is that, for sufficiently large array size, computation time does not grow with the kernel size.
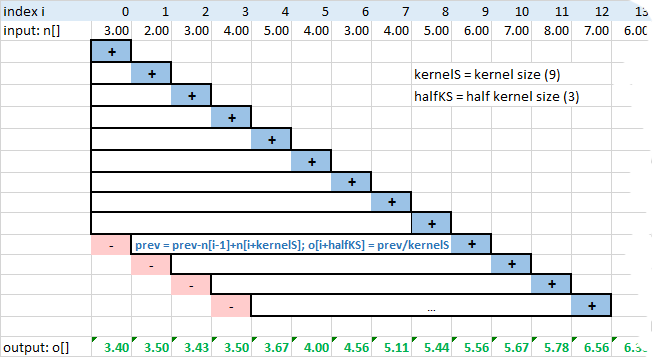
1D moving average algorithm, with kernel size 9
GLSL code for a horizontal moving averages Box filter pass:
vec3 colourSum = imageLoad( uTex0, ivec2( 0, y ) ).xyz * float(cKernelHalfDist);
for( int x = 0; x <= cKernelHalfDist; x++ )
colourSum += imageLoad( uTex0, ivec2( x, y ) ).xyz;
for( int x = 0; x < cTexSizeI.z; x++ )
{
imageStore( uTex1, ivec2( x, y ), vec4( colourSum * recKernelSize, 1.0 ) );
// move window to the next
vec3 leftBorder = imageLoad( uTex0, ivec2( max( x-cKernelHalf, 0 ), y ) ).xyz;
vec3 rightBorder = imageLoad( uTex0, ivec2( min( x+ cKernelHalf +1, cTexSizeI.z-1 ), y ) ).xyz;
colourSum -= leftBorder;
colourSum += rightBorder;
}
- While a single Box filter pass does not provide good enough blur effect for most purposes, re-applying a box filter multiple times over the same dataset approximates Gauss distribution (see https://en.wikipedia.org/wiki/Central_limit_theorem).

Blurring using intermediate lower resolution buffer at approx. 1/6 of the computation cost
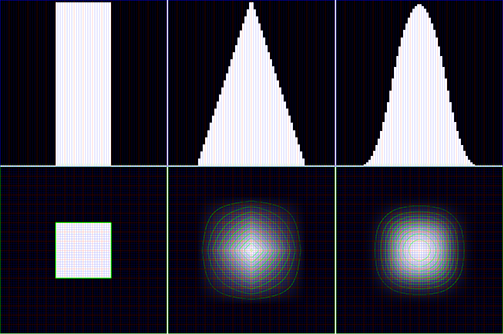
From left: no filter; 1-pass Box filter; 2-pass Box filter
The accompanying sample uses a two pass version, as it provides good enough quality at reasonable performance, although the 3 pass one does provide noticeably better results in some cases.
Performance
The following graph demonstrates the performance of a 2-pass Box Moving Averages against Gauss and Kawase filters. As expected, the Moving Averages filter has a fairly fixed cost regardless of the kernel size and it starts being more optimal at around 127x127 kernel size (especially on the more memory bound Ultrabook HD4400 GPU).
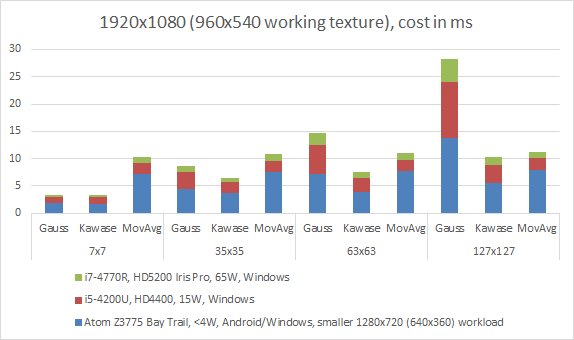
Combined across various hardware (will replace this with combined relative performance, makes more sense)
A few notes:
- Performance on Windows OpenGL and Android OpenGLES on Bay Trail (Atom Z3775) was near-identical in all cases so the numbers cover both platforms.
- The Moving Average filter is not supported on Nexus 7 because it lacks Compute Shader support.
- On tested AMD hardware there was an issue with the multi-pass compute shader, where a call to “glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT)” does not seem to work correctly, requiring a call to “glFinish()” instead, which invalidates correctness of performance numbers, so these were omitted.
- On tested Nvidia hardware, the performance is consistent but unexpectedly slow, hinting at a non-optimal algorithm implementation (for example, there are big performance variations based on compute shader group dispatch size and I could not find best fit for two different Nvidia GPUs), so these were omitted pending further investigation.
This also demonstrates how tricky it is to hit the “sweet spot” for a compute shader workload, in order to execute optimally, as it requires vendor-specific (and even vendor GPU generation-specific) tuning.
Summary
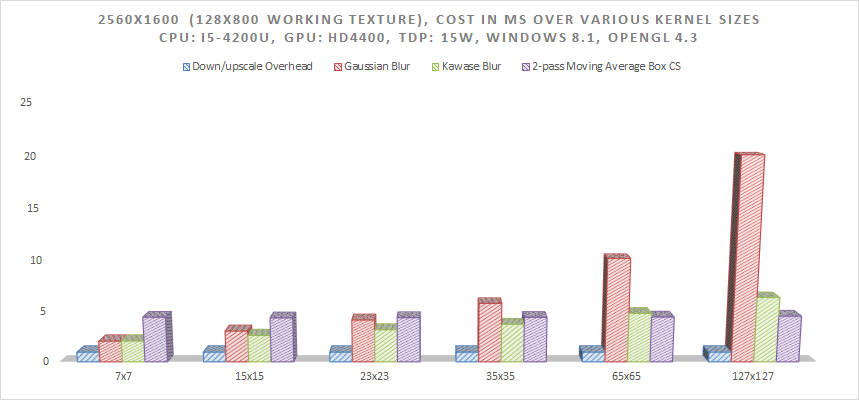
Performance of the 3 algorithms (and the cost of down-sampling and up-sampling to smaller working texture) on the most common 4th Generation Intel Ultrabook CPU on the market
I hope this article gave you some useful info on:
- How to potentially make your Gauss blur filter run faster (along with the source code generator).
- How to write and use a Kawase filter, a good alternative to Gauss from performance perspective for anything but smallest kernels sizes. This holds on hardware ranging from Nexus 7 tablets, across Intel Ultrabooks and to discrete GPUs.
- That a two (or more) pass Moving Average Box filter will do even better with very large kernel sizes, on platforms that support compute shaders (Intel’s Bay Trail being the first one to do so on Android, with its OpenGL ES3.1 support). However, compute shader approach only makes practical sense in specific scenarios and requires hardware-specific tuning.
If you have any suggestions, spot any errors or have any other kind of comment, please leave them in a comment section at the bottom of the page.
Few Additional Notes
Memory Layout on GPUs and Cache Friendliness
- Doing large kernels per pixel might be worse than doing multi-pass with smaller localized kernels access because of texture cache (and large kernels are wasteful and inefficient).
- Due to non-linear, tiled texture memory addressing (see How Video Cards Work), doing horizontal and vertical compute shader passes has essentially equal performance. This only holds for accessing Texture objects, but not when manually addressing a buffer in a scanline fashion, in which case memory access in the horizontal pass will be much more cache-friendly. In this case, transposing before and after the vertical pass can yield better overall performance.
Profiling Notes
All profiling (the “Run Benchmark” button in the sample) is done by drawing to the off-screen buffer in the size of the selected scene content (1280x720, 1600x900, 1920x1080 and 2560x1600) and displaying it to 1280x720 viewport, so the numbers are fairly device resolution independent.
First, the baseline cost is measured by drawing the off-screen content and applying it on screen (1280x720 viewport).
Then, the workload cost is measured (drawing the off-screen scene, down-sampling, applying filter, up-sampling, drawing to screen)
The difference between the baseline and the workload is displayed on screen.
While profiling, this is looped 8 times before drawing GUI and presenting on screen to reduce interference. V-sync is disabled (although this doesn’t seem to work on Nvidia latest driver, so it must be manually disabled in the graphics control panel).
Things That I Would Like to Cover in an Update
- Generic (and non-integer) Kernel size support and fading in/out of the effect:
The sample provides a generic Gauss kernel generator that works for any n*4-1 kernel size, but not for any size in between. "Kawase blur" comes in a number of presets, but at the moment there is not a generic way to calculate these. Moving Averages implementation is similar to the Gauss one.
What I would like to do next is to:
- Add support for any, non-integer kernel sizes for Gauss filter.
- Either a mathematically correct way of creating Kawase passes for any given Gauss kernel, or a brute force system to pre-generate these presets, along with handling of non-integer kernel sizes.
- Implement non-integer support for Moving Averages filter.
- Potentially implement a simple DoF / HDR Bloom effect using the Kawase filter for testing purposes.
- More optimal moving average compute shader implementation:
Need to investigate more optimal memory access patterns and GPU thread scheduling
- A better Gauss filter implementation?
Any ideas - send them my way (I already received a good one that I'm investigating)! :)
Code Sample
The code sample is built using OpenGL for Windows platform and OpenGL ES for Android platform (NDK) and demonstrates Gauss, Kawase and Moving Averages (Compute Shader) blur filters, and provides benchmarking support for each on various kernel sizes and screen resolutions.
When OpenGL ES 3.1 support is detected (such as on Intel Bay Trail Android tablets), the moving average compute shader path will be enabled.

"Fast blurs" code sample
A package with the source code and binaries is attached below.