Introduction
3rd Generation Intel® Core™ processors with Intel® Processor Graphics (HD2500, HD4000) is the first generation of Intel graphics to fully support DirectX* 11 and Compute Shader 5.0. While compute shaders provide increased flexibility and control over the graphics processor, the developer is more responsible for implementing shaders that will run well on the hardware. This sample demonstrates how to implement compute shaders for high dynamic range tone mapping and bloom for Intel® HD4000 processor graphics.
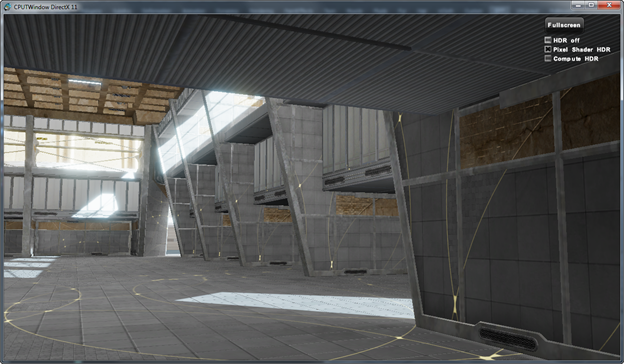
Tone Mapping and Bloom Algorithm
In standard graphics pipeline implementations the display values are limited to a 0 to 1.0f (or 0 to 255 integer) range. Values outside of that range are clamped. High Dynamic Range Imaging (HDR) [1] allows for a larger range (limited by the output format) to be used for intermediate calculations. Tone mapping is then used to convert the range of output values to something that can be displayed. There are many ways to perform the tone mapping. This implementation uses a simple tone mapping operator that first calculates the average log luminance of the scene and uses a predefined "middle grey" value.
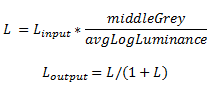
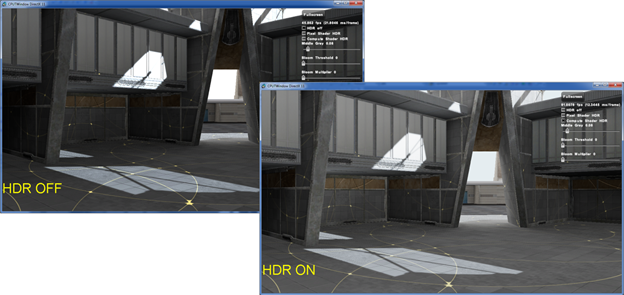
Figure 1: comparison of sample scene with HDR off and HDR on. Note the increased detail visible in very dark and very light areas.
The bloom implementation is based on the presentation "HDR: The Bungie Way" presented at Gamefest 2006 by Chris Tchou [2]. Computing bloom is done in two phases. First the bright pass is performed where values below a specified threshold are filtered out. The bright pass output is then downscaled by half 4 times. Each of the downscaled bright pass outputs are blurred with a separable Gaussian filter and then added to the next higher resolution bright pass output. The final output is a ¼ size bloom which is up sampled and added to the HDR output before tone mapping.

Figure 2: 1/16x1/16 downscaled bright pass and 1/16x1/16 blurred output

Figure 3: 1/8x1/8 downscaled bright pass, combined with 1/16x1/16 blurred output, 1/8x1/8 blurred output

Figure 4: 1/4x1/4 downscaled bright pass, combined with 1/8x1/8 blurred output, 1/4x1/4 blurred output

Figure 5: 1/2x1/2 downscaled bright pass, combined with 1/4x1/4 blurred output, 1/2x1/2 blurred output
Using the downscaled outputs gives a wide blur radius with significant bandwidth savings over a similar blur radius on a full resolution buffer.
Compute Shader Implementation Details
While the compute shader is more flexible than using pixel shaders for GPGPU programming, writing optimized compute shaders can be more difficult and requires some consideration of the underlying hardware.
The workgroup size determines how many workgroups can be executed on the hardware at the same time. Each group of 8 execution units (16 total for HD 4000) can run 1536 threads (8 execution units, 8 hardware threads per execution unit, 32 wide SIMD) and uses 64k of cache for shared local memory [3]. Because the cache is divided among workgroups, if the workgroup size is small, many workgroups can run concurrently, but the amount of shared memory each workgroup is limited (cache size / executing workgroups = shared memory per workgroup). For this sample and its high memory bandwidth requirements, workgroup sizes of 64 work threads performed well.
The compute shader performs well on two key points of the algorithm: computing the average log luminance and the separable blur. To compute the average log luminance is a common parallel reduce operation. The compute shader parallelizes the work across tiles and uses shared memory to limit writes to buffers. Unfortunately, compute shader 5.0 does not provide atomic floating point operations (floating point have ordering requirements), so the calculation still requires 2 passes. The average log luminance calculation can also be combined with the bright-pass for the bloom implementation which avoids reading the HDR render target.
The final pass where the bloom is added and the HDR values are tone mapped for display is implemented as a pixel shader is both versions. The final values for display should be in sRGB space, but sRGB format buffers are cannot be bound to the compute shader as resources. By using a pixel shader implementation for this step, the output buffer is the correct format, and the conversion to sRGB space is done outside the shader in an efficiently and consistent with other gamma correction on the display.
Performance
Overall, the compute shader gives a respectable 13% improvement over the pixel shader implementation in HD 4000 running at 1280x720 resolution (2.013 ms/frame average for compute shader v. 2.297 ms/frame for the pixel shader implementation). The performance gains are in the parallel reduce for the average luminance and the blurs used for bloom. Most of the algorithm is straightforward and maps well to using full-screen quads to perform the calculations, so the pixel shader implementation is still efficient.
Conclusion
The compute shader offers a flexible alternative to pixel shaders for some algorithms. Tone mapping and bloom, a simple technique, realize performance improvements when implemented using compute shaders with some additional development time for tuning.
References
- Erik Reinhard, Michael Stark, Peter Shirley, and James Ferwerda. 2002. "Photographic Tone Reproduction for Digital Images." In Proceedings of the 29th annual conference on Computer graphics and interactive techniques (SIGGRAPH '02). ACM, New York, NY, USA, 267-276. DOI=10.1145/566570.566575 http://doi.acm.org/10.1145/566570.566575
- Chris Tchou. "HDR: The Bungie Way." Microsoft Gamefest 2006.
- "Intel Processor Graphics Developer's Guide for 3rd Generation Intel® CoreTMProcessor Graphics on the Ivy Bridge microarchitecture" /content/www/us/en/develop/articles/intel-graphics-developers-guides.html