Designing and Fine-tuning a Distracted-Driver AI Model
The third Combating Distracted-Driver Behavior article in this five-part series, Training and Evaluation of a Distracted-Driver AI Model, started addressing how to implement the solution. This fourth article continues exploring the same topic, looking in particular at designing and fine-tuning the model.
Model Design and Fine-Tuning R&D
Transfer Learning with Inception v3
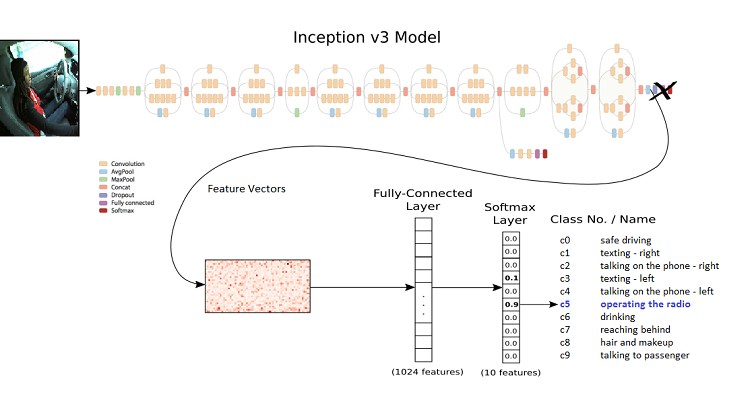
Model Fine-Tuning
The model fine-tuning parameters are determined by the experimental design outcomes.
Inception v3
The first set of experiments involved models built on transfer learning with Inception v3 offered with TensorFlow* retrain.py that requires Bazel commands to run. The weights were initialized using the ImageNet dataset. The training data was used in its plain-vanilla form.
Permutations of various hyperparameters—such as different learning rates (0.1, 0.001, and 0.001), batch size (16, 32, and 128), and iterations (10,000, 50,000, and 100,000)—were tried for the first set of experiments.
Observations Recorded for a Change in Batch Size
Evaluating the results using the manually labeled dataset, we obtained the highest test accuracy: 67.77% with batch size 16, with the learning rate at 0.01 and the iterations set to 50,000. A batch size of 128 with the same values for the other hyper parameters resulted in a lower accuracy of 66.88%.
| Observations Recorded for a Change in Batch Size - Inception v3 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | 100% | 100% | 0.114744 | 67.77% |
| 128 | 50000 | 0.01 | 100.00% | 96.00% | 0.073 | 66.88% | ||
Observations Recorded for a Change in Number of Iterations
An increase in the number of iterations resulted in a decrease in test accuracy, implying overfitting to the training data.
| Observations Recorded for a Change in Number of Iterations - Inception v3 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | 100% | 100% | 0.114744 | 67.77% |
| 16 | 100000 | 0.01 | 100.00% | 97% | 0.016751 | 66.72% | ||
| 16 | 200000 | 0.01 | 100.00% | 97% | 0.02403 | 66.88% | ||
Observations Recorded for a Change in Learning Rate
A higher learning rate of 0.01 gave better accuracy of 67.77% when compared with a learning rate of 0.001 that resulted in a test accuracy of 66.51%.
| Observations Recorded for a Change in Batch Size - Inception v3 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | 100% | 100% | 0.114744 | 67.77% |
| 128 | 50000 | 0.01 | 100.00% | 96.00% | 0.073 | 66.88% | ||
These observations, along with the fact that the training accuracy in every case was much higher than the test accuracy, imply that there were issues generalizing. The dataset comprises frames from a video clip. A look at the dataset indicates highly correlated images present per class. The abysmal test accuracy compared to the training accuracy could be attributed to overfitting on irrelevant features with respect to levels of driver distraction.
Below is the complete table of observations for Inception V3:
| Complete Table of Experiments for Inception v3 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | 100% | 100% | 0.114744 | 67.77% |
| 16 | 100000 | 0.01 | 100% | 97% | 0.016751 | 66.72% | ||
| 16 | 200000 | 0.01 | 100% | 97% | 0.02403 | 66.88% | ||
| 16 | 50000 | 0.001 | 93.80% | 91% | 0.329047 | 66.51% | ||
| 16 | 200000 | 0.001 | 100% | 96% | 0.247419 | 67.19% | ||
| 32 | 50000 | 0.01 | 100% | 96% | 0.051351 | 66.30% | ||
| 32 | 100000 | 0.01 | 100% | 98% | 0.063137 | 66.51% | ||
| 128 | 50000 | 0.01 | 100.00% | 96.00% | 0.073 | 66.88% | ||
| 128 | 100000 | 0.01 | 99.20% | 98.00% | 0.048 | 66.88% | ||
| 128 | 50000 | 0.001 | 92.20% | 96.00% | 0.395 | 66.25% | ||
| 128 | 100000 | 0.001 | 96.10% | 93.00% | 0.2661 | 67.30% | ||
| 128 | 200000 | 0.001 | 97.70% | 99.00% | 0.157 | 67.14% | ||
Inception v3 vs. Inception v4
The next step was to verify our test accuracy on a model obtained from transfer learning on Inception v4.
The previous observations were made using the retrain.py file made available with tensorflow.git and run under Bazel as follows:
For Inception V4, the only option available with TensorFlow was to clone the model.git repository as follows:
TensorFlow-Slim (TF-Slim) is a lightweight package for defining, training, and evaluating models in TensorFlow. It has the code to define and train many state-of-the-art classification models. Hence, a shift from retrain.py made available with tensorflow.git for Inception V3 to TF-Slim model was made that supports both version 3 and version 4 of the Inception models.
Given that we had enough resources, we started the experiments on two parallel tracks. We built our models by pretraining Inception V3 and Inception V4 in parallel, using the ImageNet dataset as an initializer for weights.
Surprisingly, the Inception V3 for native TensorFlow outperformed the model obtained using TF-Slim for the same hyperparameters by 15.46%.
| Comparison Table - Inception v3 - TF Native vs TensorFlow Slim | ||||||||
|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 - TF native, retrain.py | 16 | 50000 | 0.01 | 100% | 100% | 0.114744 | 67.77% |
| Inception v3 - TF Slim | 15 | 50000 | 0.01 | 2.5 | 52.28% | |||
On the other hand, between Inception V3 and Inception V4, the latter outperformed the former, with the remaining hyperparameters the same, as expected.
| Comparison Table - Inception v4 vs - Inception v3, TensorFlow Slim | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v4 | 16 | 10000 | 0.01 | RMSProp | Default | 2.43 | 46.35% | 91.054 |
| Inception v3 | 16 | 10000 | 0.01 | RMSProp | Default | 2.87 | 37.37% | 90.298 | |
Either way, the test accuracy was very low.
Observations Recorded for a Change in Batch Size
The highest test accuracy (49.51%) was achieved with the largest batch (64). In general, test accuracy increased with batch size.
| Observations Recorded for a Change in Batch Size - Inception v4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v4 | 8 | 10000 | 0.01 | RMSProp | Default | 2.1841 | 40.26% | 81.844 |
| 16 | 10000 | 0.01 | RMSProp | Default | 2.43 | 46.35% | 91.054 | ||
| 64 | 10000 | 0.01 | RMSProp | Default | 1.938 | 49.51% | 92.01% | ||
Observations Recorded for a Change in Number of Iterations
As the number of iterations increased, test accuracy decreased. These results, although unexpected, are in line with the observations for Inception V3 and support the notion that the dataset is highly correlated.
| Observations Recorded for a Change in Number of Iterations - Inception v4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v4 | 16 | 5000 | 0.01 | RMSProp | Default | 2.0212 | 48.94% | 87.296 |
| 16 | 10000 | 0.01 | RMSProp | Default | 2.43 | 46.35% | 91.054 | ||
| 16 | 20000 | 0.01 | RMSProp | Default | 2.4142 | 38.78% | 88.014 | ||
Observations Recorded for a Change in Learning Rate
A learning rate of 0.001 gave better test accuracy (50.39%) than the higher learning rate of 0.01, which resulted in accuracy of 46.35%.
| Observations Recorded for a Change in Learning Rate - Inception v4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v4 | 16 | 10000 | 0.1 | RMSProp | Default | 11.71 | 39.58% | 84.282 |
| 16 | 10000 | 0.01 | RMSProp | Default | 2.43 | 46.35% | 91.054 | ||
| 16 | 10000 | 0.001 | RMSProp | Default | 1.991 | 50.39% | 91.07 | ||
Optimizers
Since optimization algorithms help minimize loss for the model’s error function, our next step was to try various types of optimizers and choose the one that led to the best results fastest.
The default optimizer for TF-Slim, Inception V3, and Inception v4 models is RMSprop. Other optimizers that were used to train the model include Adagrad, Adadelta, Adam, FTRL Momentum, and SGD. The best results were obtained with the default optimizer.
| Comparison Table - Inception v4 - Different Optimizers, TensorFlow Slim | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v4 | 16 | 5000 | 0.01 | RMSProp | Default | 2.0212 | 48.94% | 87.296 |
| 16 | 5000 | 0.01 | Adagrad | Default | 2.3168 | 43.36% | 89.338 | ||
| 16 | 5000 | 0.01 | Adadelta | Default | 2.1388 | 46.84% | 91.96 | ||
| 16 | 5000 | 0.01 | Adam | Default | 2.5954 | 42.69% | 89.162 | ||
| 16 | 5000 | 0.01 | FTRL | Default | 2.2802 | 42.36% | 89.79 | ||
| 16 | 5000 | 0.01 | Momentum | Default | 1.8261 | 48.57% | 89.48 | ||
| 16 | 5000 | 0.01 | SGD | Default | 2.9325 | 46.68% | 90.43 | ||
Grayscale vs. Color
The next set of experiments involved data wrangling and augmentation. We attempted to verify the relevance of color to our models, that is, whether a color image added any value. The training and test dataset were converted to grayscale for model training and inference. The expectation was faster inference with negligible difference in accuracy. The results were surprising in that the models performed much more poorly with grayscale images. This could be attributed to the fact that Inception V3 and Inception V4 models were originally trained against color images.
Original image:

Converted grayscale image:

| Observations Recorded for Augmented Dataset - Inception v3, TensorFlow Native | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Preprocessing | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | Augmentation-grey | 75% | 89% | 0.502 | 66.87% |
| 16 | 50000 | 0.01 | Default | 100% | 100% | 0.114744 | 67.77% | ||
| 16 | 100000 | 0.001 | Augmentation-color | 81.20% | 90% | 0.52 | 69.08% | ||
| 16 | 50000 | 0.001 | Default | 93.80% | 91% | 0.329047 | 66.51% | ||
Padding, Slicing, and Merging
To preserve the spatial information of the images (size 480 x 640) in the dataset, the height of the image was padded with pink borders across the training and test datasets, resulting in images of size 640*640. The training dataset was then sliced vertically to a 3:5 ratio, and the left and right halves of the images were randomly merged. With only 26 drivers in the training dataset per class, this seemed like a fine way to avoid overfitting. All the images from testing and training, including the synthetic images obtained from cropping (that is, slicing) and merging, were then resized to 299 x 299—the input size expected by the Inception models.
Original image:

Original image 2:

Crop and merge resultant of original images 1 and 2:

| Observations - Inception v4 - 3 is to 5 Ratio Split-Shuffle-Merge, TensorFlow Slim | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v4 | 32 | 10000 | 0.001 | RMSprop | 3:5 ratio split-shuffle-merge, padding plus original images | 2.46 | 50.02% | 89.74% |
| 32 | 10000 | 0.001 | RMSProp | 3:5 ratio split-shuffle-merge, padding sans original images | 2.33 | 50.52% | 89.22% | ||
Applying a Black Mask and Random-Pixel Mask to a Portion of the Image
In parallel to padding and cropping of the images, another approach was taken. A part of the driver’s apparel in all the images was masked by a black patch. Although it was difficult to make sure that the mask didn't cover any part of the image relevant to classification—for example, a cell phone—the mask dimensions were chosen so as to minimize that possibility.
Original image:

Black mask image with box size = (50, 50, 300, 300), coordinate position= (130,180):

Random-pixel mask:

Similar to black masking of a portion of the apparel, random pixel values were used to mask a portion of the apparel.
The results presented far lower accuracy than no preprocessing or grayscale conversions for both black masking and random-pixel masking.
| Comparison Table - Inception v3 - No Preprocessing vs Grayscale vs Black Mask, Random Pixel Mask Dataset Preprocessing, TensorFlow Slim | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | RMSProp | Default | 2.5 | 52.28% | 89 |
| 16 | 50000 | 0.01 | RMSProp | Grayscale | 2.19 | 47.30% | 88.53 | ||
| 16 | 50000 | 0.01 | RMSProp | Black Mask | 2.75 | 31.00% | 78.3 | ||
| 16 | 50000 | 0.01 | RMSProp | Random pixel mask | 2.92 | 37.60% | 86.01 | ||
Augmented Dataset—Random Crop, Zoom, Random Erasing, Skew, Shear, Grayscale
The training dataset comprises images from only 26 drivers. Overcoming the challenge of overfitting due to a highly correlated dataset has been one of the major challenges so far. To counter this, another parallel approach on data wrangling was used.
The images in the training set were subjected to random crops, zoom, random erasing, skewing, and shear. This was validated for the augmented dataset with and sans the grayscale conversions of the newly created training and validation dataset.
Some of the sample images are provided below for reference.
Original image:

Image obtained for random crop:

Image obtained for a random distortion:

Image obtained for a random erasing:

Image obtained with shear:

Image obtained with skew:

Image obtained with zoom:

Augmentation on color images displayed the highest accuracy:
| Observations Recorded for Augmented Dataset - Inception v3, TensorFlow Native | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Preprocessing | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | Augmentation-grey | 75% | 89% | 0.502 | 66.87% |
| 16 | 50000 | 0.01 | Default | 100% | 100% | 0.114744 | 67.77% | ||
| 16 | 100000 | 0.001 | Augmentation-color | 81.20% | 90% | 0.52 | 69.08% | ||
| 16 | 50000 | 0.001 | Default | 93.80% | 91% | 0.329047 | 66.51% | ||
Person Detection Followed by Classification
Another approach that seemed promising was driver detection followed by classification of the image into different categories.
We assumed that there are unnecessary elements in the image, such as the driver’s seat or a passenger in the back, which might influence the classification accuracy. In an attempt to remove such noise, we added a detection phase before classification. This is done to detect and extract the person part from the image.
For detection, we used COCO model with TensorFlow object-detection API. This identified the person with close to 100% accuracy. Once the bounding boxes were identified, the images were cropped and saved to a new folder. This became the training data for the classifier. To our surprise, we observed worse performance with TF-Slim models. With retrain.py, we got a 1.5% increase in performance.
| Observations Recorded for Person Detection Followed by Classification | ||||||
|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Preprocessing | Test Accuracy |
| TensorFlow | Inception v3 - TF Slim | 16 | 50000 | 0.01 | Default | 53 |
| Inception v3 - TF Slim | 16 | 50000 | 0.01 | Detection | 48 | |
| Inception v3 - TF Native, retrain.py | 16 | 50000 | 0.01 | Default | 66.51 | |
| Inception v3 - TF native, retrain.py | 16 | 50000 | 0.001 | Detection | 68 | |
Person detection for original image:

Detected image:

Inception-ResNet v2
Inception-ResNet v2 is a convolutional neural network (CNN) that achieves a new state of the art in terms of accuracy on the ILSVRC image-classification benchmark. It is a variation of Inception V3 model. The network is considerably deeper than Inception v3.
Inception-ResNet v2 was tried to see if it suited the dataset better than the ones tested so far for classification. As per an article on the Google research blog, “Improving Inception and Image Classification in TensorFlow,” the accuracy of Inception-ResNet v2 is higher than that of Inception v3. Our observations matched the insights there. A higher accuracy was recorded for Inception-ResNet v2 compared with Inception v3.
| Comparison Table - Inception v3 vs Inception Resnet v2, TensorFlow Slim | |||||||
|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Test Accuracy | Recall |
| TensorFlow | Inception v3 | 24 | 50000 | 0.001 | RMSProp | 55.85 | 94.05 |
| Inception Resnet v2 | 24 | 50000 | 0.001 | RMSProp | 58.4 | 93.55 | |
The maximum accuracy that we got was 59.8%, when the number of iterations was 72,638.
k-Nearest Neighbors
From the basket of machine-learning algorithms, another attempt was made with k-nearest neighbors. The images were resized and padded.
| Observations Recorded for k-Nearest Neighbors | ||||
|---|---|---|---|---|
| Framework | Algorithm | k | Preprocessing | Test Accuracy |
| Scikit-learn | KNN | 7 | resize = 150X150 and padding | 36.87% |
| 9 | resize = 200X200, padding and grayscale conversion | 37.19% | ||
Regularization, ftrl Optimizer
Explicit L1 regularization with the ftrl optimizer was added to Inception v3 to curb overfitting. An increase in test accuracy on the manually labeled dataset by a little over 1% was observed.
| Comparison Table - Inception v3 - L1 Regularization vs No Regularization, TensorFlow Slim | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Preprocessing | Loss | Test Accuracy | Recall |
| TensorFlow | Inception v3 | 16 | 50000 | 0.01 | RMSProp | Default | 2.5 | 52.28% | 89 |
| 16 | 50000 | 0.01 | RMSProp | Regularization, optimizer = ftrl | 1.6 | 53.70% | 93.8 | ||
Ensemble Model
In an attempt to get better accuracy, we created an ensemble of models trained on different topologies. The topologies that we used for this purpose were Inception v3, Inception v4, and Onception-ResNet-v2. The models had a test accuracy of 55.85%, 52.21%, and 58.4% respectively.
The accuracies of all the checkpoints for comparison were recorded on 100 images per class, randomly sampled from the manually created dataset.
The analysis showed that, for the class c2 and c5, Inception v4 gave better results. For class c7 and c8, Inception v3 gave better results compared to the other two model checkpoints. For the rest, Inception ResNet v2 gave better results. We incorporated this knowledge while building the ensemble model to arrive at the final label.
For the ensemble, three pb (protocol buffers) files converted from the checkpoints of the best obtained models were taken and class predicted best by each model was taken into consideration. For instance, Inception v4 was considered for c2 and c5. A default weightage of 1 was given for each class prediction. In case the class had previously been evaluated to give the best accuracy in predicting the class it predicted, an additional weightage of 1 was awarded to that class. Eventually, the class with the highest score was assigned as the output label for the image evaluated.
The final accuracy obtained by this framework was 52.9, which was only slightly greater than the model with the lowest accuracy in the ensemble considered for the experiment.
| Observations Recorded for Ensemble - Inception v3, Inception v4 and Inception Resnet v2, TensorFlow Native |
|||||||
|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Optimizer | Test Accuracy | Recall |
| TensorFlow* | Inception v3 | 16 | 50000 | 0.01 | RMSProp | 55.85 | 94.05 |
| Inception v4 | 64 | 6784 | 0.01 | RMSProp | 52.21 | 92.056 | |
| Inception Resnet v2 | 24 | 50000 | 0.001 | RMSProp | 58.4 | 93.55 | |
| Ensemble accuracy - 52.9 | |||||||
Color Quantization
Color quantization is a process to reduce the number of distinct colors present in an image. The aim is for the image to be as visually similar as possible to the original image.
In our experiments, this was an attempt at reducing the overfitting in the network. Each image was processed to give four color-quantized images. The quantization was done for k values 3, 13, 31, and 61. A k value of 13 results in a grouping of similar colors into 13 clusters. The centroid of each cluster represents the 3D color vectors (RGB) falling in that cluster. All the color vectors are replaced by their respective centroid. Eventual output is an image reconstructed by k color combinations of the image.
Original image:

Image obtained with k=13:

Image obtained with k=31:

Image obtained with k=3:

Image obtained with k=61:

The obtained dataset, combined with the original training dataset, was then trained on Inception v3 model. An accuracy of 65.13% was observed for 15,000 iterations.
| Observations Recorded for Color Quantization - Inception v3, TensorFlow Native | ||||||||
|---|---|---|---|---|---|---|---|---|
| Framework | Model | Batch Size | Iterations | Learning Rate | Train Accuracy | Validation Accuracy | Cross Entropy | Test Accuracy |
| TensorFlow* | Inception v3 | 16 | 50000 | 0.001 | 93.80% | 91% | 0.329047 | 66.51% |
| 16 | 15000 | 0.001 | 100.00% | 89.00% | 0.34 | 65.13% | ||
Providing Inputs to the Productization Team
Web Portal
We also developed a web interface to showcase our work. The eventual goal of a use case is to monitor and alert a driver in real time if a distraction is detected. Keeping this in mind, we developed the web portal using Django*, a high-level Python* web framework that ensures rapid development with clean and pragmatic design. Django offers a robust internationalization and localization framework to assist in the development of applications for multiple languages as well. We also developed an environment which has some Python utilities predominantly intended for classification using TensorFlow.
The web portal mainly offers two functionalities:
- Live inferencing from a camera (wired/wireless)
- Offline inferencing with the help of a saved video file that can be uploaded in the portal
Live inferencing is a tedious task if we consider the normal processing speed where an end user may feel a lag on getting the processed videos on the fly back on their machines. Since we have the Intel® Movidius™ Neural Compute Stick (NCS), we use the same as the backbone support for the live inferencing with its unique capability to predict faster using the low-power, high-performance Intel® Movidius™ Vision Processing Unit (VPU). Movidius technology, in turn, uses the .ckpt files trained using TF-Slim models. It does not accept .pb files.
Offline inferencing can be done with both Movidius technology and an in-house implementation to classify using the .pb file. As you could infer from the results, we got better accuracy for the model (.pb file) trained with the help of retrain.py, compared to the model (.ckpt file) trained with TF-Slim models. Hence, we primarily used in-house implementation with retrain.py for offline inferencing.
Here’s the web portal’s basic architecture:
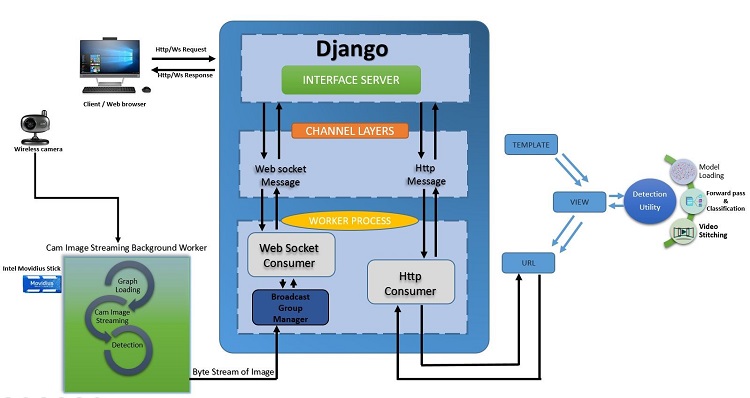
As we mentioned earlier, we have two functionalities. The first one is for live inferencing from a camera (wired/wireless) whereas the second one is for offline inferencing. The first one needs to stream images from the connected camera and do a forward pass on the streamed image to get the classification outcome, which should be rendered at the client-side browser.
As we know, traditional browsing was based around the simple concept of HTTP requests and responses service and that is usually rendered by a browser. Our approach to render the classified images on a web page is little different from usual HTTP requests and response service. We need to operate on the same request until we explicitly close the request. While the HTTP request response allows relatively quick and simple development to see real time information, we had to refresh the page or set up something like AJAX. Modern web technologies, such as WebSockets, enable us to create interactive and engaging functionality within our applications by allowing the client interface of a web application to communicate continuously with the corresponding real-time server, with either able to send data at any time. Since we have the two functionalities mentioned, we would prefer a usual HTTP request –response service for the offline inferencing—whereas we use WebSockets service for real-time inferencing.
Django* Channels allows Django to handle WebSockets. Since we are dealing with multiple protocols now, all the requests are managed using the interface server. This interface server knows how to handle requests using different protocols. The interface server accepts the request and transforms it into a message. It then passes the message on to a channel. Channels also allow for background tasks that run on the same servers as the rest of Django.
When there is a request initiated from the end user, it will get redirected to the associated consumer. If it is a WebSocket request, the WebSocket consumer takes care of live inferencing with the Movidius NCS, or else the http consumer takes care of offline inferencing with a pre-trained model.
For live inferencing, once the WebSocket handshake is done with successful connection establishment, camera—either wired or wireless (within same network of server)—connection will get enabled and the successful streamed images inside the queue will be undergoing a forward pass inside the Movidius NCS–enabled Python background worker. This ensures the broadcasting of processed images back to the client/browser as byte streams, and the same will be converted back to render as images in the respective portal UI.
For offline inferencing, the end user is given an option to upload the saved video either by browsing or by drag and drop. The HTTP consumer takes care of the request. After the video is uploaded to the server, frames are uniquely identified, and it transforms the request to the predefined utility to process the request by loading the pre-trained model to memory and predicting the class labels with the help of that. Successful frames are then stitched back with labels embedded as a video, and the same will be rendered back to the UI.
Some of the outputs obtained from the web portal are outlined below.
Classification - drinking:

Intel® Movidius™ Neural Compute Stick UI
The time taken to classify a frame, detect driver distraction, and alert the driver in real time is a major challenge. A standard high-definition format can record and play about 24 frames per second. Time for inferencing a single frame, on the other hand, could take more than two seconds. We could get the results but not fast enough to alert the passenger in time to avert potential dangers posed by distractions.
The next in-line option to GPUs was to use the Intel® Movidius™ Neural Compute Stick (NCS). The stick enables rapid prototyping, validation, and deployment of deep-neural-network inference applications at the edge. We can also leverage multiple Intel Movidius Neural Compute Sticks to achieve better speed.
A few tutorials readily available online helped us to get started. The Intel® Movidius™ Software Development Kit (SDK) was downloaded and installed. The SDK is a compiler for the NCS that helps in compiling checkpoints obtained from the model developed to the native format of NCS. The checkpoint file obtained from training the model using slim is then compiled, producing a graph file in the native format. The API here is the bridge between the graph and the stick. For inferencing, all the contiguous frames being received from the video are put in an input queue. Upon receiving a new frame in the queue, the image is processed in a worker method that loads the frame in LoadTensor. This is how each frame is inferred. The results are then appended to an output queue along with the respective labels. The final results are then fetched from the queue and displayed to the user, giving the user a sense of real-time inference.
Challenges faced with Intel Movidius Neural Compute Stick:
- It supports only TensorFlow 1.3 version models.
- It supports only Inception v1, Inception v2, Inception v3, Inception v4, and Inception-ResNet v2.
- It only accepts .ckpt files.
Resources
- State Farm Distracted Driver Detection
- TensorFlow Models GitHub
- Transfer Learning Using Keras*
- Train the Model with Cloud ML
- An Analysis of Deep Neural Network Models for Practical Applications
- Let’s Keep It Simple, Using Simple Architectures to Outperform Deeper and More Complex Architectures
- Intel® Neural Compute Stick 2
- Improving Inception and Image Classification in TensorFlow
- Image compression using K-means clustering : Colour Quantization
- Introduction to Django Channels
- Building Real Time Web Apps with Django Channels
- A Brief Introduction to Django Channels
- The 7 Software Ilities You Need to Know
Next Steps
In the final article of this five-part Combating Distracted-Driver Behavior series, Overview of Productization for This AI Project, we will move to the final step: productization, with a focus to the final product that would be delivered to the end customer based on the previous design-thinking experiments set of features. Refer back to the third article for more information on Training and Evaluation of a Distracted-Driver AI Model.
For reference on AI Developer Project: Combating Distracted-Driver Behavior ›
Part 1: Overview of a Use Case: Combating Distracted-Driver Behavior
Part 2: Experimental Design and Data Preparation for a Distracted-Driver AI Project
Part 3: Training and Evaluation of a Distracted-Driver AI Model
Part 4: Designing and Fine-tuning a Distracted-Driver AI Model
Part 5: Overview of Productization for This AI Project
Join the Intel® AI Developer Program
Sign up for the Intel® AI Developer Program and access essential learning materials, community, tools and technology to boost your AI development. Apply to become an Intel® Student Ambassador and share your expertise with other student data scientists and developers.