Overview
AI Avatar chatbots are reshaping the business of various industries in today’s AI world. From reception desks of financial and educational institutions to public facilities such as airports and hospitals, ubiquitous digital human AIs assist in answering customer queries and providing personalized guidance.
To meet this need from enterprises of digital human AIs, we developed an “AI Avatar Audio Chatbot”. This article introduces how to leverage Open Platform for Enterprise AI (OPEA), an open, multi-provider, and robust framework of composable building blocks for state-of-the-art (SOTA) Generative AI (GenAI) systems to create an AI Avatar Chatbot on Intel® Xeon® Scalable Processors and Intel® Gaudi® Al Accelerators. It also highlights how Intel-optimized software such as Intel® Gaudi® Software Suite and PyTorch* can help accelerate the training and inference performance of these AI solutions. accelerate the training and inference performance of these AI solutions.

Open Platform for Enterprise AI (OPEA)
![]()
The OPEA platform includes:
- A framework of microservice building blocks for SOTA GenAI systems including LLM, data stores, and prompt engines
- Architectural blueprints of Retrieval-Augmented Generation (RAG) GenAI component stack structure
- Micro and Megaservices to get GenAI solutions into production and deployment
- A four-step assessment for grading GenAI systems around performance, features, trustworthiness, and enterprise-grade readiness
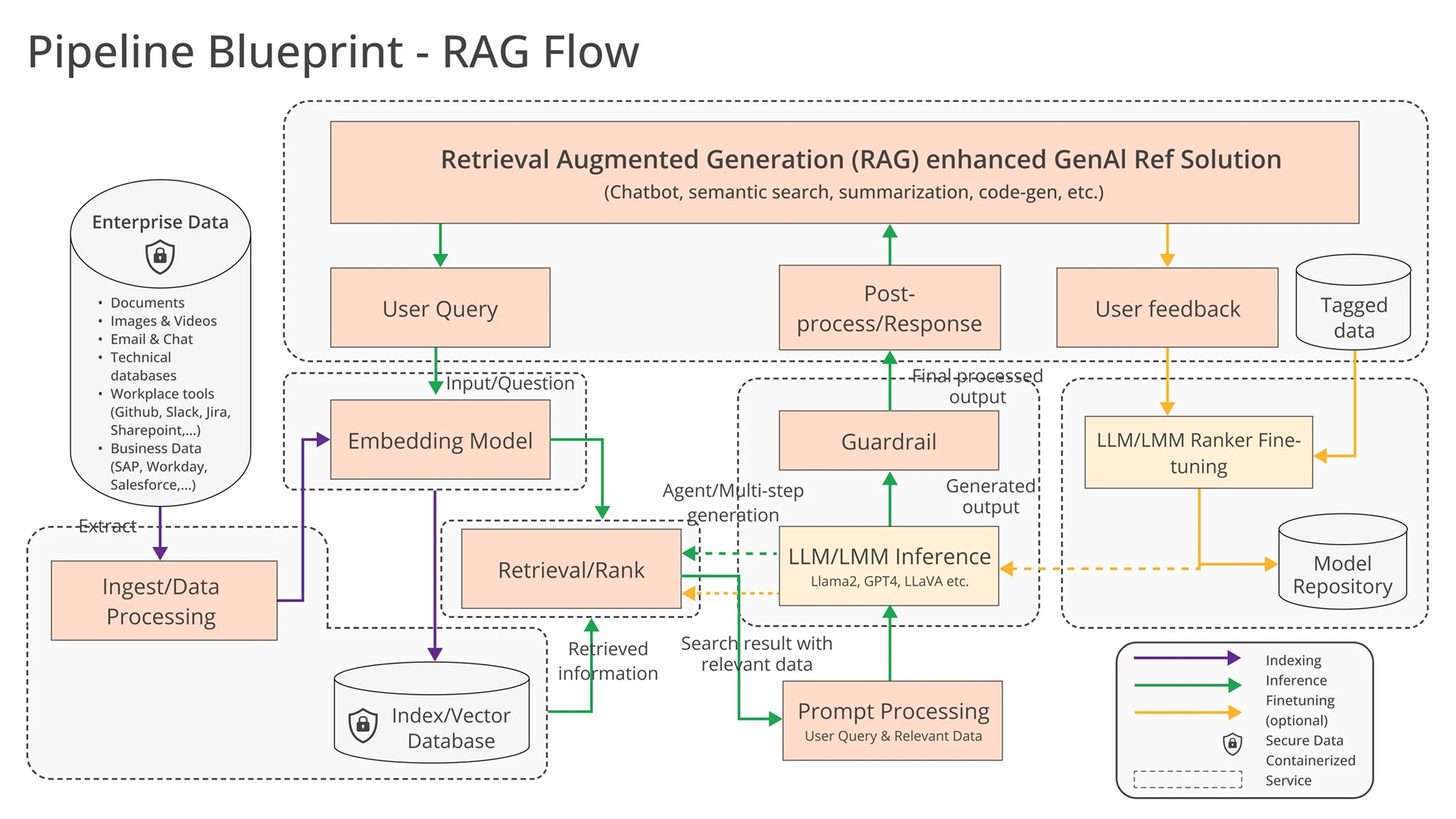
For any OPEA Enterprise AI solution, there are three major components:
- Microservices: Provides flexible and scalable solutions.
The GenAIComps repo hosts all the available microservices. Each microservice is designed to perform a specific function or task within the application architecture.
- Megaservices: Provides comprehensive solutions.
The GenAIExamples repo hosts a collection of use case-based applications. Unlike individual microservices that focus on specific tasks, a megaservice orchestrates multiple microservices to deliver a comprehensive solution
- Gateways: Provides communication.
The Gateway serves as the interface for users to access a megaservice and its underlying microservices. Gateways support API definition, versioning, rate limiting, request transformation, and data retrieval from microservices.
Additionally, for most AI solutions, there is a corresponding UI that allows the user to interact with OPEA megaservices in a more direct, interactive, and visualized manner.
How to build an AI Avatar Chatbot under the OPEA framework?
I. Flow Chart
The flow of the entire application is shown in the graph. The code sample is the “Avatar Chatbot” example [15] in the OPEA GenAIExamples repository. In the flowchart diagram we highlight the “AvatarChatbot” megaservice, which is the core of the application. The megaservice orchestrates four different microservices “Automatic Speech Recognition (ASR)”, “Large Language Model (LLM)”, “Text-to-Speech (TTS)”, and “Animation”, connected in the form of a Directed Acyclic Graph (DAG).
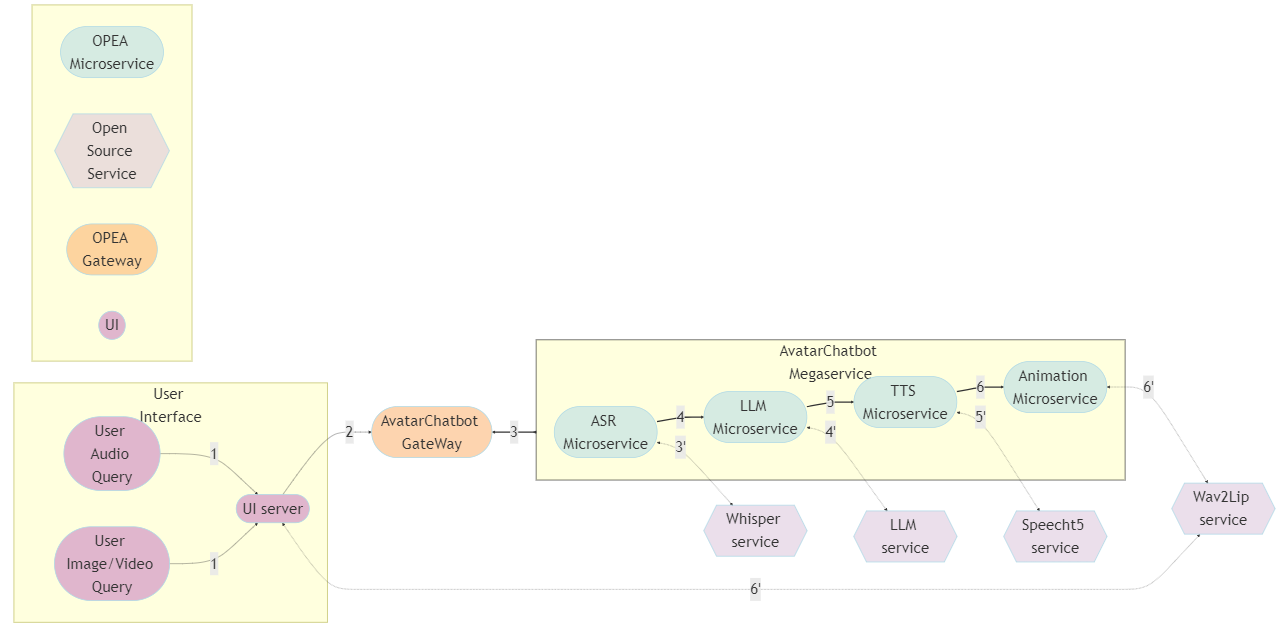
Each microservice handles a particular functionality of the avatar chatbot. For example:
- Automatic Speech Recognition (ASR) is a voice recognition software that converts human speech to text.
- Large Language Model (LLM) processes the transcribed text from ASR by understanding the user’s query and generates the appropriate text response.
- Text-to-Speech (TTS) service converts the text response generated from the LLM into audio speech.
- Animation service combines both the audio response from TTS and the user-defined AI avatar image/video and ensures that the avatar figure’s lip movements will match the synchronized speech. It then generates a video featuring the avatar speaking back to the user.
The user inputs include an audio query and an image/video visual input. The output is a face-animated avatar video. Users will be able to get close to real-time feedback from the avatar chatbot, including hearing the audible answer and watching the chatbot talk naturally.
1. Build a new Microservice “Animation” in GenAIComps Repo
To add a new microservice such as “Animation”, we would need to register that microservice under comps/animation:
# Register the microservice
@register_microservice(
name="opea_service@animation",
service_type=ServiceType.ANIMATION,
endpoint="/v1/animation",
host="0.0.0.0",
port=9066,
input_datatype=Base64ByteStrDoc,
output_datatype=VideoPath,
)
@register_statistics(names=["opea_service@animation"])
After the registration process, we define the callback function when this microservice is executed. In the case of “Animation,” we will use the “animate” function that takes a “Base64ByteStrDoc” object as its input audio and generates an “VideoPath” object that contains the path to the generated avatar video. Within “animation.py” we post an API request to the “wav2lip” FastAPI’s endpoint and collect the response, both in json format.
Note Don’t forget to add “Base64ByteStrDoc” and “VideoPath” classes in comps/cores/proto/docarray.py and import it in comps/__init__.py!
It’s a FastAPI that has its post function specified to process the incoming audio Base64Str and user-specified avatar image or video, and to output an animated video and return its path.
The above steps help us create the functional block for our microservice. To allow the user to build the necessary dependencies and run the “Animation” microservice, we need to write a Dockerfile for “wav2lip” server API and another one for “Animation”. The Dockerfile.intel_hpu, for example, starts with the PyTorch* installer Docker image on Intel Gaudi, and ends with calling an “entrypoint” bash script.
2. Build a new Megaservice “AvatarChatbot” in GenAIExamples
In python “AvatarChatbot/docker/avatarchatbot.py” file, we will first define the megaservice class AvatarChatbotService. In the “add_remote_service” function, use the “add” function of the megaservice orchestrator to add “asr”, “llm”, “tts”, and “animation” microservices as nodes in a Directed Acyclic Graph (DAG), and use the flow_to function to connect the edges.
class AvatarChatbotService:
def __init__(self, host="0.0.0.0", port=8000):
self.host = host
self.port = port
self.megaservice = ServiceOrchestrator()
def add_remote_service(self):
asr = MicroService(
name="asr",
host=ASR_SERVICE_HOST_IP,
port=ASR_SERVICE_PORT,
endpoint="/v1/audio/transcriptions",
use_remote_service=True,
service_type=ServiceType.ASR,
)
llm = MicroService(
name="llm",
host=LLM_SERVICE_HOST_IP,
port=LLM_SERVICE_PORT,
endpoint="/v1/chat/completions",
use_remote_service=True,
service_type=ServiceType.LLM,
)
tts = MicroService(
name="tts",
host=TTS_SERVICE_HOST_IP,
port=TTS_SERVICE_PORT,
endpoint="/v1/audio/speech",
use_remote_service=True,
service_type=ServiceType.TTS,
)
animation = MicroService(
name="animation",
host=ANIMATION_SERVICE_HOST_IP,
port=ANIMATION_SERVICE_PORT,
endpoint="/v1/animation",
use_remote_service=True,
service_type=ServiceType.ANIMATION,
)
self.megaservice.add(asr).add(llm).add(tts).add(animation)
self.megaservice.flow_to(asr, llm)
self.megaservice.flow_to(llm, tts)
self.megaservice.flow_to(tts, animation)
self.gateway = AvatarChatbotGateway(megaservice=self.megaservice, host="0.0.0.0", port=self.port)
3. Define Gateway for our megaservice
A gateway is an interface for users to access the Megaservice. We define the AvatarChatbotGateway class in the python file - GenAIComps/comps/cores/mega/gateway.py. The AvatarChatbotGateway contains the megaservice orchestrator, host, port, endpoint, and input and output datatype information. It also has a handle_request function that schedules passing the initial input with parameters to the first microservice and collects response from the last microservice.
Finally, we need to write a Dockerfile for users to easily build the AvatarChatbot backend Docker image and deploy the “AvatarChatbot” examples. The Dockerfile includes scripts to install necessary GenAI components and dependencies.
II. Lip Synchronization and Face Animation Models
1. Wav2Lip + GFPGAN
Wav2Lip [2] is a cutting-edge lip-synchronization technique that leverages deep learning to accurately align audio with video. Wav2Lip includes:
- A pre-trained expert lip-sync discriminator that is accurate in detecting sync in real videos
- A modified LipGAN [6] model to generate a talking face video frame-by-frame
The pretraining stage includes training an expert lip-sync discriminator on the LRS2 [4] dataset. The lip-sync expert is pre-trained to output the probability that the input video-audio pair is in sync.
During Wav2Lip training, a similar architecture to LipGAN is used. The generator contains a speech encoder, a visual encoder, and a face decoder. All three are stacks of convolutional layers. The discriminator is also a convolutional block. The modified LipGAN is trained like any other GANs: the generator is trained to minimize the adversarial loss, based on the discriminator’s score; the discriminator is trained to distinguish between frames generated by the generator versus the ground-truth frames. Overall, the generator is trained by minimizing a weighted sum of the following loss components:
- An L1 reconstruction loss between generated and ground-truth frames
- A synchronization loss between generated video frames and input audio from the lip-sync expert
- An adversarial loss between the generated and ground-truth frames, based on the discriminator score
Upon inference, we feed the Wav2Lip model with the audio speech from the preceding TTS block, along with the video frames that contain the avatar figure. The trained Wav2Lip model outputs a lip-synced video featuring the avatar speaking out the speech.
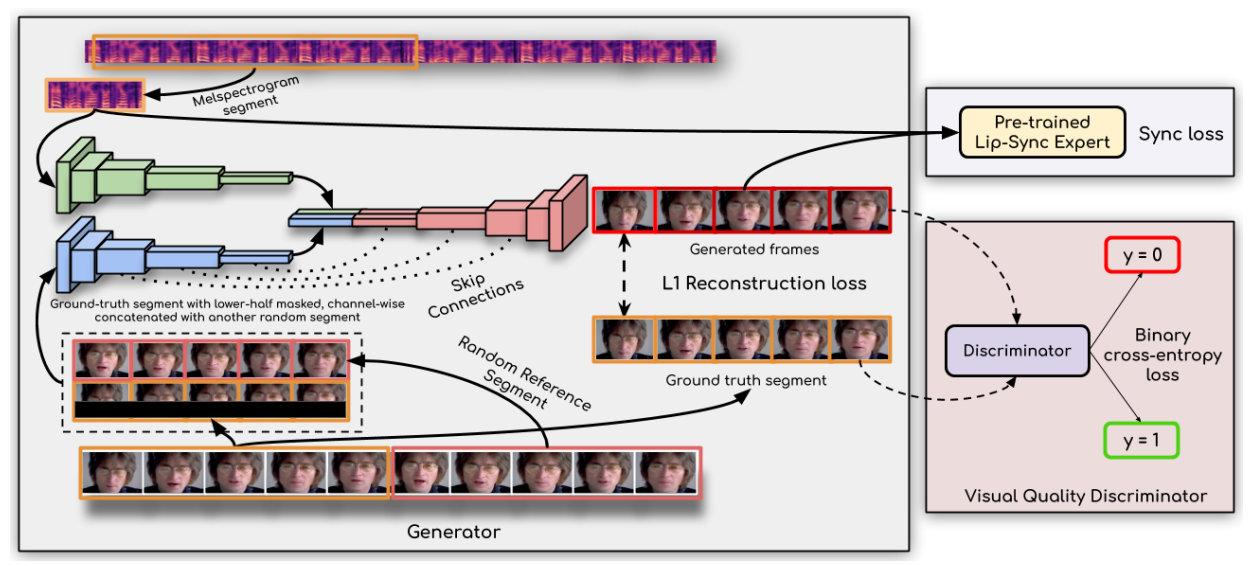
The video generated from Wav2Lip features lip synchronization, but the resolution around the mouth area is lowered. Optionally, we could append a GFPGAN [7] model after Wav2Lip to improve the face quality within the generated video frames. The GFPGAN model estimates a high-quality image from an input facial image suffering from unknown degradation through face restoration. It is a U-Net [8] degradation removal module that uses a pretrained face GAN (such as Style-GAN2 [3]) as a prior. The GFPGAN model is pretrained to restore high-quality face details in its output frames, leaving us with a more vivid and realistic avatar representation.
2. SadTalker
In addition to Wav2Lip, we offer another state-of-the-art model choice to perform face animation. Stylized Audio-Driven Talking-head video generation, SadTalker [5], generates 3D motion coefficients (head, pose, expression) of a 3D Morphable Model (3DMM) [1] from audio. These coefficients are mapped to 3D key points, and further used to drive the input image through a 3D-aware face renderer. The output is a realistic talking head video.
We enabled the deployment of both Wav2Lip and SadTalker models on Intel® Xeon® Scalable processors, and Wav2Lip model on Intel® Gaudi® Al accelerators.
How to deploy on Intel® Xeon® scalable processors and Intel® Gaudi® AI Accelerators
Based on your intended deployment environment, the required Docker images for the same FastAPI service/microservice/megaservice could vary. For example, “wav2lip” service container uses an image named “opea/wav2lip:latest” when deployed on Intel® Xeon® CPUs and another image named “opea/wav2lip-gaudi:latest” when deployed on Intel® Gaudi® AI Accelerators. These images use separate versions of Dockerfiles, to include their respective dependencies.
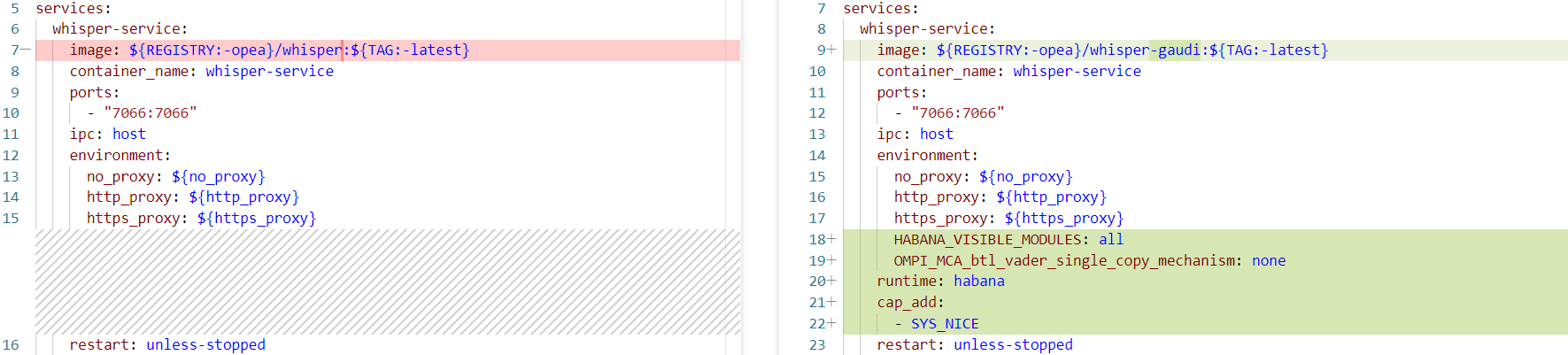
The above difference calls for a YAML file to explicitly set for each service container. The “compose.yaml” file enables OPEA users to customize the following key elements:
- Service image: the specific Docker image to use for each service
- Ports: mapping external ports to the container’s internal port
- Environment variables: ensuring that each service has the necessary context and configs (Ex., LLM model name, Device, Inference mode, Additional inputs, etc.)
- Volumes: shared data between host and containers
- Other elements such as IPC, Network, Runtime, cap_add, etc.
By default, on Intel® Gaudi® AI accelerators, the OPEA-based AI Avatar Audio Chatbot example distributes its workload on four Intel® Gaudi® cards on a single Intel® Gaudi® 2 AI accelerator node. Each microservice is assigned to one card. This can be verified in the “compose.yaml” config file, where “asr”, “llm”, “tts”, and “animation” microservice’s Docker containers are each associated with a dedicated Intel Gaudi card by setting the “HABANA_VISIBLE_MODULES” environment variable to values 0, 1, 2, 3, respectively. This is referred to as “Multiple Dockers Each With a Single Workload” [10].
A deeper dive into the Intel® Gaudi® 2 node gives a clearer picture of Intel® Gaudi® card layouts. First, we find the mapping between the index and module ID of the Intel Gaudi® processors through the “hl-smi” System Management Interface tool [9] and sample output of the mapping.
Similarly, we can use another “hl-smi” command to figure out NUMA Affinity [9]. NUMA (Non-Uniform Memory Access) affinity for devices refers to the alignment of devices with a specific region of memory to optimize performance. In multi-card systems like Intel Gaudi®, NUMA affinity provides Intel Gaudi® cards with fast access to the memory controlled by the CPU nearest to it. In this example, Intel Gaudi® cards with module IDs 0-3 correspond to memory controlled by CPUs 0 and 1.
Deep Learning Optimizations
Mode of Operation: Eager mode vs. Lazy mode
The mode of operation is controlled by the environment variable “PT_HPU_LAZY_MODE” that can have values 0 and 1 (0 for Eager mode and 1 for Lazy mode).
In “GenAIComps/comps/animation/entrypoint.sh”, we set this variable to 0 to use Eager mode. At the same time, we extend the Eager mode with torch.compile, wrapping the face detector, Wav2Lip, and GFPGAN models into corresponding graphs. Unlike Lazy mode, Eager mode with torch.compile does not require building a graph in each iteration which reduces host computation overhead. In addition, the backend parameter for torch.compile must be set as hpu_backend for both training and inference. A list of common models that support Eager mode + torch.compile can be found here [11].
# Load Wav2Lip, BG sampler, GFPGAN models
model = load_model(args)
model = torch.compile(model, backend="hpu_backend")
print("Wav2Lip Model loaded")
On the other hand, Lazy mode helps users retain the flexibility and benefits that come with the PyTorch define-by-run approach. The execution of the ops in the accumulated graph is triggered only when a tensor value is required. This allows the Intel Gaudi graph to be constructed with multiple ops, providing the graph compiler opportunity to optimize the device execution for these ops. A more detailed discussion over PyTorch Gaudi Theory of Operations can be found at [16].
Run Inference Using BF16 & FP8 with PyTorch Autocast and Intel® Neural Compressor
Mixed-precision quantization allows deep learning neural networks operations to be executed faster while reducing model weight’s size on memory. In this example, we enabled quantization of the face detector and the Wav2Lip model through 2 methods.
First, we can utilize the native PyTorch autocast to automatically run a default list of registered operators (ops) in the lower precision bfloat16 data type. The list of ops can be found at [12]. This enables inference of the face animation module in BF16.
with torch.no_grad():
with torch.autocast(device_type="hpu", dtype=torch.bfloat16):
pred = model(mel_batch, img_batch)
In a second method, we can take advantage of the Intel Neural Compressor package to enable FP8 inference on Intel® Gaudi® accelerator [18]. Using FP8 data type for inference halves the required memory bandwidth of the model. Further, the computation speed of FP8 is twice as fast as BF16. We need to first write a JSON config file, and then use the “convert” API to quantize the model.
Feature Improvements
Text-to-Speech (TTS) Service
We used a SOTA model “microsoft/SpeechT5” [17] as the default TTS model to use in OPEA. Instead of letting it transform the entire length of the text tokens to audio, we apply the code in the file “speecht5_model.py” to automatically detect the last punctuation in the last token chunk, during batch splitting of the long text. This modification allows the TTS service to output text that’s integral and continuous, without abrupt stopping.
Animation Service
In Wav2Lip [2] animation, we allow tunable frames-per-second (fps) for the video frame generation and the code is in the link here. This is controlled by the user-specified “fps” parameter. When the visual input to Wav2Lip is an image containing the avatar face, we have the freedom to define the frame rate for the final video. Based on the frame rate, a variable number of audio Mel spectrogram chunks are fused together with a single frame. Although fps=30 endows slightly better video render smoothness, setting fps=10 leads to 1/3 video frames to generate, and thus 1/3 neural network iterations and computation. Making the frame rate tunable is ideal for low-latency, high-throughput animation scenarios.
if not os.path.isfile(args.face):
raise ValueError("--face argument must be a valid path to video/image file")
elif args.face.split(".")[-1] in ["jpg", "jpeg", "png"]:
full_frames = [cv2.imread(args.face)]
fps = args.fps
else:
video_stream = cv2.VideoCapture(args.face)
fps = video_stream.get(cv2.CAP_PROP_FPS)
.............
.............
# one single video frame corresponds to 80/25*0.01 = 0.032 seconds (or 32 milliseconds) of audio
mel_chunks = []
mel_idx_multiplier = 80.0 / fps
Instructions to Run the AI Avatar Chatbot – Try on your own!
Follow the instructions in AvatarChatbot Microservice and Avatar Animation Microservice to:
- Build required Docker images for all microservices (“asr”, “llm”, “tts”, “animation”) and the AvatarChatbot megaservice
- Set the necessary environment variables with export commands
- Start the Docker services on Intel® Xeon® scalable processors / Intel® Gaudi® AI accelerators, using Docker compose
- Validate the Docker services with curl commands or Python files
- Interact with the AI Avatar application in the Gradio UI on your local browser
Watch the short demo on how to run this AI Avatar Application.
Future Work
Real-time streaming of LLM and TTS outputs and animated frames
Hugging Face LLM model API [19] enables setting the streaming mode for LLMs, allowing the generation of a stream of tokens asynchronously and the code will be available in the python file. By setting “streaming=True” in the LLM params and enabling streaming in TTS, we can expect text tokens and their corresponding audio waveform to be generated at a faster pace. Then, we apply techniques such as frame buffering, to accumulate frames processed by the “Animation” microservice. We start streaming the output video once the number buffered frames surpass a checkpoint, for example 1/3, of the total number of expected frames. Then, the users will soon experience the avatar video animation.
Useful Resources
- Overview - Intel® Gaudi® Al Accelerators
- Overview - Intel® Xeon® Scalable Processors
- Introducing The Open Platform for Enterprise AI
- OPEA Project GitHub repo
- Sign up on Intel® Tiber™ Developer Cloud
- Official documentation - PyTorch* Optimizations from Intel
- Intel® Extension for PyTorch* - Documentation
References
[1] B. Egger et al., “3D Morphable Face Models -- Past, Present and Future,” Apr. 16, 2020, arXiv: arXiv:1909.01815. Accessed: Sep. 12, 2024. [Online]. Available: http://arxiv.org/abs/1909.01815
[2] K. R. Prajwal, R. Mukhopadhyay, V. Namboodiri, and C. V. Jawahar, “A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild,” in Proceedings of the 28th ACM International Conference on Multimedia, Oct. 2020, pp. 484–492. doi: 10.1145/3394171.3413532.
[3] T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “Analyzing and Improving the Image Quality of StyleGAN,” Mar. 23, 2020, arXiv: arXiv:1912.04958. doi: 10.48550/arXiv.1912.04958.
[4] “Lip Reading Sentences 2 (LRS2) dataset.” Accessed: Sep. 12, 2024. [Online]. Available: https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrs2.html
[5] W. Zhang et al., “SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation,” arXiv.org. Accessed: Sep. 12, 2024. [Online]. Available: https://arxiv.org/abs/2211.12194v2
[6] P. K. R, R. Mukhopadhyay, J. Philip, A. Jha, V. Namboodiri, and C. V. Jawahar, “Towards Automatic Face-to-Face Translation,” in Proceedings of the 27th ACM International Conference on Multimedia, Oct. 2019, pp. 1428–1436. doi: 10.1145/3343031.3351066.
[7] X. Wang, Y. Li, H. Zhang, and Y. Shan, “Towards Real-World Blind Face Restoration with Generative Facial Prior,” Jun. 10, 2021, arXiv: arXiv:2101.04061. doi: 10.48550/arXiv.2101.04061.
[8] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation,” May 18, 2015, arXiv: arXiv:1505.04597. doi: 10.48550/arXiv.1505.04597.
[9] “System Management Interface Tool (hl-smi) — Gaudi Documentation 1.17.1 documentation.” Accessed: Oct. 03, 2024. [Online]. Available: https://docs.habana.ai/en/latest/Management_and_Monitoring/Embedded_System_Tools_Guide/System_Management_Interface_Tool.html?highlight=numa#hl-smi-utility-options
[10] “Multiple Dockers Each with a Single Workload — Gaudi Documentation 1.17.1 documentation.” Accessed: Oct. 03, 2024. [Online]. Available: https://docs.habana.ai/en/latest/Orchestration/Multiple_Tenants_on_HPU/Multiple_Dockers_each_with_Single_Workload.html
[11] HabanaAI/Model-References. (Oct. 02, 2024). Jupyter Notebook. Intel® Gaudi® AI Accelerator. Accessed: Oct. 04, 2024. [Online]. Available: https://github.com/HabanaAI/Model-References
[12] “Mixed Precision Training with PyTorch Autocast — Gaudi Documentation 1.17.1 documentation.” Accessed: Oct. 04, 2024. [Online]. Available: https://docs.habana.ai/en/latest/PyTorch/PyTorch_Mixed_Precision/index.html
[13] “Stable Diffusion 3 Medium - a Hugging Face Space by stabilityai.” Accessed: Oct. 20, 2024. [Online]. Available: https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium
[14] “Open Platform For Enterprise AI,” Open Platform for Enterprise AI (OPEA). Accessed: Oct. 20, 2024. [Online]. Available: https://opea.dev/
[15] “AvatarChatbot · opea-project/GenAIExamples,” GitHub. Accessed: Oct. 20, 2024. [Online]. Available: https://github.com/opea-project/GenAIExamples/tree/main/AvatarChatbot
[16] “PyTorch Gaudi Theory of Operations — Gaudi Documentation 1.18.0 documentation.” Accessed: Oct. 20, 2024. [Online]. Available: https://docs.habana.ai/en/latest/PyTorch/Reference/PyTorch_Gaudi_Theory_of_Operations.html
[17] J. Ao et al., “SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing,” May 24, 2022, arXiv: arXiv:2110.07205. Accessed: Oct. 20, 2024. [Online]. Available: http://arxiv.org/abs/2110.07205
[18] “Run Inference Using FP8 — Gaudi Documentation 1.18.0 documentation.” Accessed: Oct. 20, 2024. [Online].
[19] “langchain_community.llms.huggingface_endpoint.HuggingFaceEndpoint — 🦜🔗 LangChain 0.2.16.” Accessed: Oct. 20, 2024. [Online]. Available: https://api.python.langchain.com/en/latest/llms/langchain_community.llms.huggingface_endpoint.HuggingFaceEndpoint.html