Co-author: Suqiang (Jack) Song of Mastercard*.
Introduction
“AI at Scale” is a significant driving force to create high value from data through Big Data AI technology at Mastercard*. Building on top of BigDL (an open-source Big Data AI project from Intel), “AI at Scale” allows data scientists, data engineers and ML engineers at Mastercard* to develop distributed AI applications (such as TensorFlow* and PyTorch*) directly on Enterprise Data Warehouse platform. As a result, Mastercard* has successfully harnessed AI for many different applications (by supporting up to 2.2 billion users, hundreds of billions of records, and distributed training on several hundred Intel Xeon servers).
BigDL: End-to-End Distributed Big Data AI Pipelines
BigDL is a Big Data AI project open-sourced by Intel. Latest BigDL 2.0 combines the original Analytics Zoo and BigDL projects, making it easy for data scientists and data engineers to develop distributed AI applications.

Figure 1. End-to-End Distributed AI Pipelines using BigDL
Most AI projects start with a Python notebook running on a single laptop; however, one usually needs to go through a mountain of pains to scale it to handle larger data set in a distributed fashion. The Orca library in BigDL seamlessly scales out the end-to-end AI pipeline (from data loading, to preprocessing, to feature engineering, to model training and inference) from local laptops to distributed clusters, as illustrated in Figure 1.
- The user first installs BigDL and all the Python libraries (such as TensorFlow* or PyTorch*) in the local development machine (using pip or conda). Then the user simply initializes the application by calling init_orca_contex (this is the only place where one needs to specify local or distributed mode; otherwise, the code will be the exact same whether running on a local laptop or a distributed cluster
- The user then loads the processes the data using a standard big data library (such as Spark DataFrames) or deep learning library (such as TensorFlow Dataset or PyTorch DataLoader); the Orca library runs these data processing pipelines in a data-parallel and distributed fashion.
- After that, the user defines the deep learning models using standard deep learning APIs (that is, directly writing TensorFlow or PyTorch code inline with Spark program to build the model).
- Finally, the user uses the sklearn-style Estimator APIs in the Orca library for transparent distributed training, inference and/or tuning (with AutoML) directly on Spark DataFrames using Spark or RayOnSpark (e.g., running TensorFlow models, tuning hyper-parameters with AutoML to get best model and configuration, etc.)
Architecture of “AI at Scale” in Mastercard
Mastercard has adopted “AI at scale” approach to a couple of mission critical insight products, developed deep learning models and ran them on existing big data infrastructure at production.
Top challenges to address include:
- Existing ML algorithms cannot gain good performance, then the deep learning approach was considered and adopted, but it’s often harder to gain access to a large GPU cluster and lack of convenient facilities in popular DL frameworks for distributed training. Applying deep learning to the existing production spark environment can improve accuracy and share the multi-tenancy data platform and infrastructure without investing extra money and effort on new GPU clusters.
- To transfer lots of data to additional specific infrastructure such as a standalone GPU cluster will require lots of efforts and bottlenecks at data privacy, regulation, and compliance (such as PCI/PII compliance and GDPR)
- Align to Mastercard's strategy to increase revenue from data-driven businesses, to scale up data products and serve more customers with greater efficiency and scale and deploy AI algorithms that require more powerful computation resources, Data/ ML platform was required to support heterogeneous infrastructure and deployment environment, such as on cloud, on-premise and on soil, but we need a “unified AI at Scale” approach to keep the consistent and seamless user experiences and governance policies for multiple parties and ML lifecycle
Building on top of BigDL, Mastercard Data platform and Engineering Service teams have adopted an “AI at Scale” approach to accelerate the entire machine learning lifecycle (including data analysis, experimentation, model training, deployment, resource optimizations, monitoring, etc.). This is accomplished by building a unified Big Data AI architecture with BigDL on Hybrid data/ML infrastructures (which automates AI/ML pipelines and model lifecycle management), as illustrated in Figure 2.
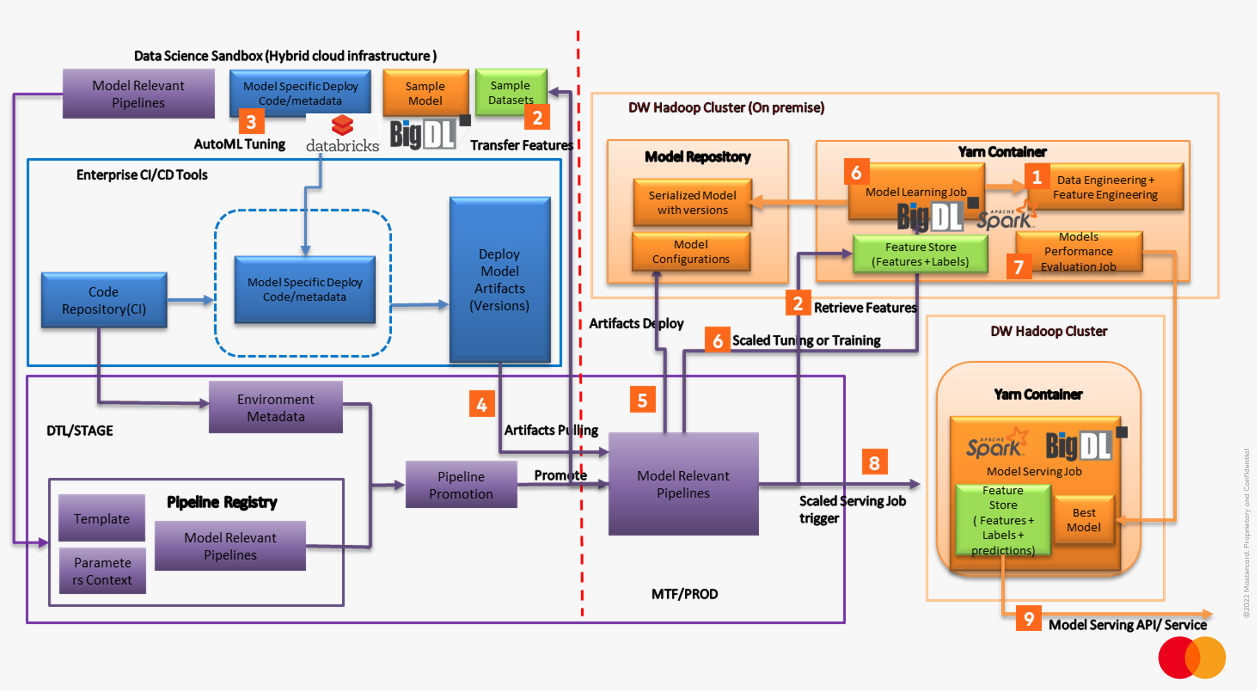
Figure 2. Unified Big Data AI architecture for “AI at Scale” in Mastercard
- Automated Data Engineering pipelines trigger large-scale Data Engineering Job at Datawarehouse Hadoop cluster to build curated data sets
- Automated Feature Engineering pipelines trigger large-scale Feature Engineering job at Datawarehouse Hadoop cluster to extract normalized features and build unified feature store based on curated data sets.
- Data Scientists execute sampling job to extract sampled feature store for Sandbox experimental learning, with hybrid cloud Sandbox integrated with BigDL and Spark (Or Databricks), data scientists can develop, and tune initialized models with AutoML feature from BigDL
- Automated ML pipelines integrate with existing CI/CD tools and environment to adopt model lifecycle management and automation
- Automated ML pipelines pull models and configurations from Enterprise Artifactory, deploy to a Model repository at distributed storage
- Automated ML pipelines trigger large-scale distributed tuning and training jobs associated large-scale feature store and compatible with modern Deep Learning frameworks such as Tensor Flow, PyTorch etc. based on BigDL on Spark.
- Automated ML pipelines generate Best Models based on large-scale AutoML tuning and Model performance evaluation results
- Automated Serving pipelines trigger large-scale model serving job BigDL on Spark and produced prediction results load into feature store for serving
- Model Serving API/Services delivery the model enablement and applications integration
Conclusion
With a playbook for AI at Scale solution development and implementation, Mastercard AI-powered business innovation follows a typical life cycle from an idea or proof of concept to a tested prototype, MVP and eventually production-grade solution that is implemented. A proven approach to doing this repeatedly enables to gradually develop and scale new AI opportunity areas and become a truly AI-powered organization.
Mastercard enabled a technology platform that supports AI at scale. AI solutions pose new requirements for technology architecture, and managing to scale AI have developed standardized platforms that allow rapid development of AI solutions in a robust and sustainable manner.
Using BigDL, Mastercard engineers have seamlessly integrated big data analysis (Spark ecosystem) and deep learning (using TensorFlow and Keras) into end-to-end AI applications, which seamlessly scale to distributed Intel Xeon clusters for distributed training and serving. As a result, Mastercard can avoid the additional cost and complexity of special-purpose processors, while their AI training jobs can complete within only 5 hours on average (running on several hundred Intel Xeon servers to support up to 2.2 billion users and hundreds of billions of records).