Contributors:
Intel Corporation:
Esther John, Rahul Unnikrishnan Nair, Harshapriya N, Arvind Kumar, Barbara Hochgesang, Lavar Askew, Soethiha Soe, Mousumi M Hazra, Richard Winterton, Curt Jutzi, Anh V Nguyen, Ningxin Hu, Jianxun Zhang, Jonathan Ding, Jason V Le, Gabriel Briones Sayeg, Jose A Lamego, Geronimo Orozco, Hugo A Soto Lopez, Obed Munoz Reynoso
Abstract
Intel created the focus toward establishing the foundation and infrastructure to reliably track performance of video conferencing use cases on a recurring basis and to deliver measurable performance improvements through optimization projects.
The AI Acceleration dedicated hardware workgroup focused the discussion on the proposals for using AI accelerators and building blocks (containers/orchestration) on Intel’s Client platforms and Intel’s optimized intelligent collaboration offerings.
The Intelligent Collaboration technological initiative established helps independent professionals collaborate from anywhere with confidence. In this paper, we provide the open source end-to-end Intelligent Collaboration solution on Intel® Xeon® (2nd and 3rd Generation Intel® Xeon® Scalable Platform) and Client platforms (11th Gen Intel® Core™ mobile processor with Intel® Iris® Xe graphics and Intel® Evo ™ with Intel® Gaussian and Neural Accelerator (Intel® GNA ) 2.0).
1. Introduction
Intel established the goals for the AI Acceleration dedicated hardware workgroup: to define and discuss mechanisms for developers, Original Equipment Manufacturers (OEMs), and others to utilize Intel’s Client platform features effectively for Intelligent algorithms, and to create a product intercept plan.
This workgroup focused the discussion on the proposals for how to use AI accelerators and building blocks (containers/orchestration) on Intel’s Client platforms for AI algorithms, and discussed Intel’s optimized Intelligent Collaboration offerings and how these offerings could be used.
The Intelligent Collaboration architecture helps independent professionals collaborate from anywhere with confidence. The architecture is designed for Linux platforms and is scalable to Chrome and Windows platforms for AI accelerators. It provides flexibility to deploy Cloud AI functions on Client platforms.
The AI Acceleration dedicated hardware workgroup worked towards enabling AI algorithms including Deep Neural Nets, object detection, and face recognition. We focused the engagement on delivering measurable performance improvements through optimization projects with the Prototype AI algorithm optimization approach and improving ML performance for existing features such as face and body detection.
The AI Acceleration dedicated hardware architecture foundational building blocks include:
- Intel’s Deep Learning Reference Stack [1][2] [3]: The Deep Learning Reference Stack is an integrated, highly-performant open source stack optimized for Intel platforms. This open source community release is part of our effort to ensure AI developers have easy access to all of the relevant features and functionality in Intel platforms. The Deep Learning Reference Stack is highly-tuned and built for cloud native environments. With this stack, we are enabling developers to quickly prototype by reducing the complexity associated with integrating multiple software components, while still giving users the flexibility to customize their solutions. This includes additional components to provide enhanced flexibility and a more comprehensive take on the deep learning environment.
- Intel’s Media Reference Stack [4]: The Media Reference Stack maximizes performance of Video on Demand for live broadcasting, with container images tuned for hardware acceleration on Intel Platforms. The Media Reference Stack is designed to accelerate offline and live media processing, analytics, and inference recommendations for real-world use cases such as smart city applications, immersive media enhancement, video surveillance, and product placement.
These engagements focused on providing Intel platforms with optimized hardware accelerated solutions for features including Intel® Advanced Vector Extensions 512 (Intel® AVX-512), the Intel® DL Boost with Vector Neural Network Instructions (VNNI), Intel® Gaussian Network Accelerator (GNA), found on Intel® Xeon® (2nd and 3rd Generation Intel® Xeon® Scalable Platform) and Client (11th Gen Intel® Core™ mobile processor with Intel® Iris® Xe graphics and Intel® Evo ™).
2. Terms & Terminologies
App: Application.
API: Application Programming Interface.
AI: Artificial intelligence (AI) is a wide-ranging branch of computer science concerned with building smart machines capable of performing tasks that typically require human intelligence.
AVX-512: Intel® Advanced Vector Extensions 512 (Intel® AVX-512).
Background blur: A common technique used by photographers for years to keep the focus on their most important subject. The idea is to focus on the element in the foreground, by removing the hard lines and distracting detail in the background, to truly make the foreground element pop.
Container: A container is a standard unit of software that packages code and all its dependencies so that the application runs quickly and reliably from one computing environment to another.
Deep Learning (DL): Deep Learning is a subfield of machine learning concerned with algorithms called artificial neural networks, inspired by the structure and function of the brain.
Docker: Docker is a set of platform-as-a-service products that use operating system-level virtualization to deliver software in packages called containers.
Docker image: A Docker image is a read-only template that contains a set of instructions for creating a container that can run on the Docker platform.
DL Boost: Intel® DL Boost with Vector Neural Network Instructions (VNNI).
V4l2: Video4Linux driver - device drivers and API to interface with video capture devices.
Object Detection: Algorithms that produce a list of object categories present in the image along with an axis-aligned bounding box indicating the position and scale of every instance of each object category.
Neural Nets: A means of doing machine learning, in which a computer learns to perform some task by analyzing training examples.
Machine Learning Model: Machine learning models are downloadable packages with pretrained models and scripts needed for running a particular model workload on bare metal.
User Mode Driver (UMD): A driver is a small software program that allows your computer to communicate with hardware or connected devices. A driver operating in user mode generally does not require assistance from the operating system and has less privilege regarding system resources.
Unix socket: Inter process communication socket for exchanging data between processes.
UI: The user interface (UI) is the graphical layout of an application. It consists of the button users interact with, the text they read, the images, sliders, text entry fields, and all the rest of the visible objects the user can access. This includes screen layout, transitions, interface animations and every single micro-interaction.
Kernel Mode Driver (KMD): Kernel-mode drivers execute in kernel mode as part of the executive, which includes kernel-mode operating system components that manage I/O, Plug and Play memory, processes and threads, and more security.
Linux Module: Dynamically linkable code for device drivers / file systems for Linux kernel.
Integrated Graphics Processing Unit (IGP): An IGP is a graphics chip that is integrated into a computer's motherboard. The IGP serves the same purpose as a video card, which is to process the graphics displayed on the computer.
Intel’s Xeon Platform: 2nd and 3rd Generation Intel® Xeon® Scalable Platform.
Intel’s Client Platform: 11th Gen Intel® Core™ mobile processor with Intel® Iris® Xe graphics and Intel® Evo ™.
Intel’s Deep Learning Reference Stack (DLRS): An integrated, highly-performant open source stack optimized for Intel® Xeon® Scalable platforms and Intel Client platforms.
Intel’s Media Reference Stack (MeRS): A highly optimized software stack for Intel® Architecture Processors (the CPU) and Intel® Processor Graphics (the GPU) to enable media workloads like transcoding and analytics for Intel® Xeon® Scalable platforms and Intel Client platforms.
Iccam: Virtual Camera Device
Intelligent Collaboration: Architecture that helps independent professionals collaborate from anywhere with confidence.
Intelligent Collaboration (IC) feature: Object detection, Background blur, Super Resolution, eye correction are examples of IC features.
Intelligent Collaboration (IC) control: Primary controller, with ability to enable / disable, stream proxy (container), and IC features (effects container processes).
GNA 2.0: Intel® Gaussian Network Accelerator (GNA).
General-purpose computing on graphics processing units (GPGPU): A graphics processing unit (GPU), which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the central processing unit (CPU).
GStreamer: GStreamer is a library for constructing graphs of media-handling components. The applications it supports range from simple audio/video streaming to complex audio (mixing) and video (non-linear editing) processing.
Super Resolution: A class of techniques that enhance (increase) the resolution of an imaging system.
System Container: Container with Intel hardware accelerated frameworks.
FastAPI: FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.6+ based on standard Python type hints.
Function Containers: AI algorithms/use cases/workloads such as object detection, background blur and others, containerized.
V4l2loopback: A virtual camera module that can act as a camera for applications to select.
HTTP: A protocol which allows the fetching of resources, such as HTML documents. It is the foundation of any data exchange on the Web and it is a client-server protocol, which means requests are initiated by the recipient, usually the Web browser. A complete document is reconstructed from the different sub-documents fetched, for instance text, layout description, images, videos, scripts, and more.
REST API: An acronym for REpresentational State Transfer. It is an architectural style for distributed hypermedia systems.
REP/ REQ: Request-Reply is a zmq communication pattern for client / service rpc communication.
TensorFlow: TensorFlow is an end-to-end open source platform for machine learning
TensorFlow Hub: TensorFlow Hub is a repository of trained machine learning models ready for fine-tuning and deployable anywhere.
Torch Hub: PyTorch Hub is a pre-trained model repository designed to facilitate research reproducibility.
TCP: The Transmission Control Protocol (TCP) is one of the main protocols of the Internet protocol suite. It originated in the initial network implementation in which it complemented the Internet Protocol (IP).
ZMQ: ZeroMQ is an asynchronous messaging library, aimed at use in distributed or concurrent applications. It provides a message queue, but unlike message-oriented middleware, a ZeroMQ system can run without a dedicated message broker.
3. The Intelligent Collaboration on Linux Platforms Scalable to Chrome & Windows Platforms
Intel define the mechanism for developers, OEMs, and others to utilize Intel’s Client platform features effectively for intelligent algorithms, and to create a product intercept plan. The Intelligent Collaboration architecture helps independent professionals collaborate from anywhere with confidence.
The Intelligent Collaboration architecture, designed on the Linux platform and scalable to Chrome and Windows Platforms, is enabled on Intel hardware. It utilizes Intel hardware features {CPU, GPU, GNA} with the system containers (Deep Learning Reference Stack [1][2] [3]) and Media Reference Stack [4]), and function containers (Intel’s [8] AI algorithms such as object detection, and others), the incoming stream container, the video stream proxy container, and other architectural building blocks (As shown in Figure 1).
The system containers are hardware accelerated containers optimized for the Intel platform features. Intel provides the necessary abstraction, enabling the developer and customer to get access to the latest Intel platform feature optimizations. The software components in the system container are optimized for specific Intel platform features across generations of Intel platforms.
The function containers are use cases and AI algorithms such as Intel’s object detection AI algorithm [8]. The AI Acceleration dedicated hardware workgroup focuses on delivering measurable performance improvements through optimizations projects on Linux and Chrome Platforms.
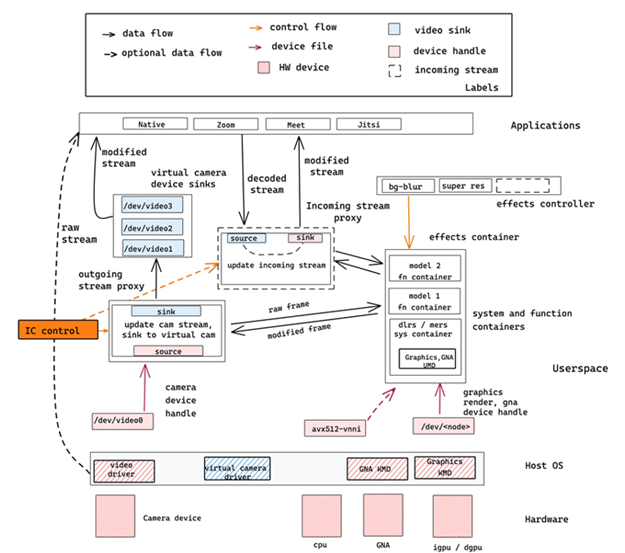
Figure 1: Intel’s Intelligent Collaboration Architecture on Linux Platforms
4. The End-to-End Open Source Implementation of the Intelligent Collaboration on Linux Platforms
In this release, the End-to-End open source implementation of the Intelligent Collaboration technology is built on Intel’s Client platforms (11th Gen Intel® Core™ mobile processor with Intel® Iris® Xe graphics and Intel® Evo ™ with Intel® Gaussian and Neural Accelerator (Intel® GNA ) 2.0).
The Intelligent Collaboration architectural software building blocks on Linux platforms are as follows:
- The Deep Learning Reference Stack [1][2] [3]) and Media Reference Stack [4].
- Intel’s AI Algorithm [8](For object detection).
- Video Streaming Pipeline: GStreamer based video pipeline for proxying video (takes the raw camera output from the hardware, interacts with the AI function containers, and sinks the modified stream to a virtual camera device). This solution is written as a Python wrapper.
- Virtual Camera Device Manager: Creates and manages the virtual camera device (Video Loopback V4L).AI service discovery: Catalogs and publishes the available AI services utilizing HTTP technology.
- Effect Service: Web server for serving the REST API. This is a generic web server with the ability to take multiple inputs including image and text. This service is the queuing system for the Intelligent Collaboration architecture.
- Intelligent Collaboration Controller: Activates and deactivates the Intelligent Collaboration Service. This is the main controller that activates and deactivates the Intelligent Collaboration service. This serves as the power button for the architecture.
Architecture in detail
Let’s discuss how the solution modifies the outgoing stream, applying effects that an end-user application can access from a camera handle.
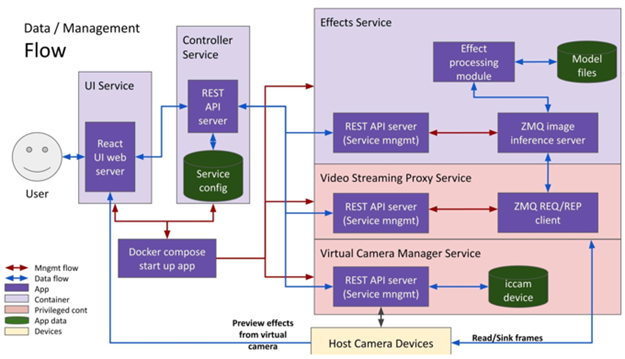
Figure 2: Intel’s Intelligent Collaboration Architecture on Linux Platform Outgoing Stream
All services otherwise specified are containerized microservices managed over REST. We utilize the FastAPI Python library to implement the API. All APIs are self-documented and are developer accessible. State management between services is done using an SQLite database in the controller service.
As shown in Figure 2, the video frames from the raw camera device are obtained by the Video Streaming Proxy Service. The Effects Service uses pre-trained TensorFlow models that wait for a frame from the video proxy service. Once an effect is applied, the frame is sent back to the video proxy service, and the service stitches together the modified frames. These modified frames are then sunk into a virtual camera device which is managed by the virtual camera manager service.
The communication stack between the Effects Service and Video Streaming Proxy Service is implemented using ZeroMQ (ZMQ) [13], a lightweight and fast network library that runs over TCP using a REQ/REP pattern. Let’s go into each component in more detail.
Startup and initialization
The startup script is a wrapper on top of docker-compose, used to initialize and startup the Intelligent Collaboration service. Internally the tasks the startup script handles are:
1. Download and setup up models
2. Start the controller service
3. Spin up the Effects, Virtual Camera Manager, Video Stream Proxy, and the UI
4. Populate the State database
5. Present a URL to the user on the CLI, to access the Intelligent Collaboration UI service
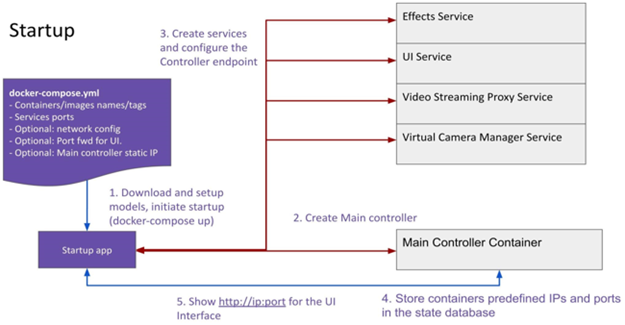
Figure 3: Intelligent Collaboration Architecture on Linux Platform Initialization Sequence
Virtual Camera Manager Service
This service is used to create, enumerate, and delete virtual camera devices. The current implementation uses a python wrapper that exposes the v4l2loopback library over a REST interface. Because this service interacts with the host device files, the container needs to have privileged access. The default virtual camera created by the solution is named: `iccam`.
Video Streaming Proxy Service
This service captures raw frames from a hardware camera device, converts them into tensors, serializes them and a client sends the data over ZMQ to the Effects Service. The ZMQ client waits for the modified frame from the Effects Service. Once it obtains the frame it is sunk to the virtual device `iccam` created above.
Effects Service
An effect could be any modification that is done on the frame. The examples of effects include object detection, where the modification applies bounding boxes on the frame for identified objects. Another example includes Flipping the frame, which is generally used for debugging the effects service.
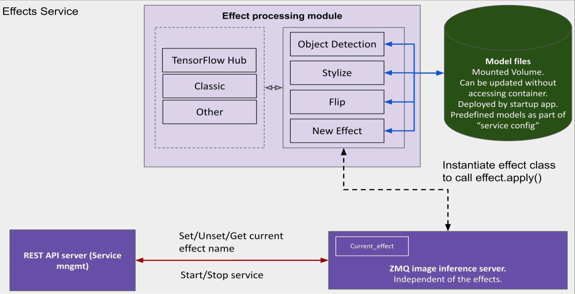
Figure 4: Intelligent Collaboration Architecture on Linux Platform Effects Service
Effects such as object detection are done using TensorFlow models; specifically, we support TensorFlow Hub. In the future, we plan to support classic TensorFlow, PyTorch, and Torch Hub as well. The effect applying module and serving are decoupled and serving of the modified frames is done using a ZMQ server. Model files and other artifacts required by the Effects are downloaded to a mounted volume by the initialization step.
Choice of ZMQ for the communication stack
We chose ZMQ primarily for the ease of use of the library and the framework’s flexibility.
For example, as seen in Code 0 below, a simple REQ-REP (Request-Reply) server could be implemented using pyzmq as below:

Code 0: REQ-REP communication pattern using ZMQ
This enables the project to choose the needed communication patterns depending on where the Effects server is hosted, latency, and throughput requirements to migrate to simple patterns described in the ZMQ guide when required.
Controller Service
The controller service manages the state of the service, sets the default configs, and orchestrates the service.
UI Service
The UI Service, as shown in Figure 6, provides a user interface based on React for the Intelligent Collaboration Service. A user can enable effects like object detection, stylize for outgoing or incoming streams.
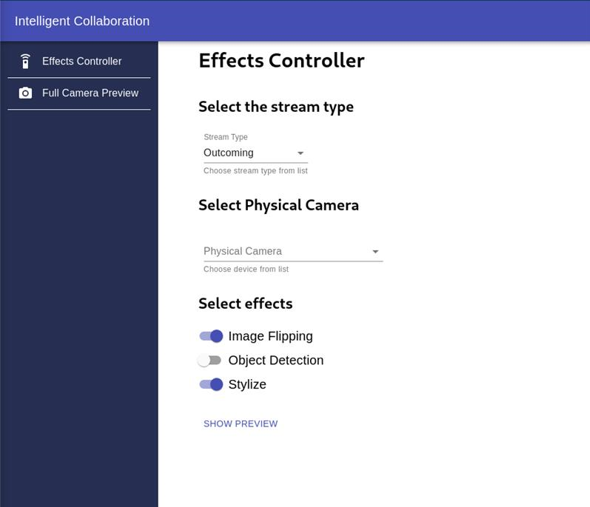
Figure 5: Intel’s Intelligent Collaboration Architecture on Linux Platform UI service
Code
Source code can be found on GitHub: https://github.com/intel/stacks-usecase/tree/master/client/intelligent_collab
Using Intel’s Intelligent Collaboration
To apply effects to your outgoing camera stream, clone the repo and run the startup script as stated in the project Readme, after installing the v4l2loopback module for your operating system.
Once the service starts successfully, a new camera device with the label `iccam` will be created on the host device. The service will also print the URL where a user can get access to the Intelligent Collaboration UI. The UI has options to select the stream direction (outgoing/incoming), see effects, and preview the applied effect.
Developer Contribution
The solution has been designed to be modular to make it easy to extend the Effect Service to include additional features. Any new effect needs only implement an interface that is used to `apply` the effect. To add a new effect, reference the example in Code 1. Developers can implement the apply method, load the necessary model by implementing the load method, and implement any preprocessing and postprocessing steps required.
Code 1: Implementing a new Effect
An example implementation can be found in the source code repository.
We presently support TensorFlow Hub based models, and we plan to include other frameworks such as PyTorch and others in the future.
5. Intelligent Collaboration Path Forward
Intel embarked on the journey to enable the Intelligent Collaboration architecture on the Linux platform, scalable to Chrome and Windows platforms. The AI Acceleration dedicated hardware workgroup focused on the performance benchmarks and engineering effort to make the engagement successful for developers, OEMs, and others.
We look forward to future enhancements to Intel’s containerized solutions, container orchestration, cross-platform enablement across Linux, Chrome, and Windows platforms all on Intel’s Xeon and Client Platforms.
Additional Resources
[1] https://software.intel.com/content/www/us/en/develop/articles/deep-learning-reference-stack-v7-0-now-available.html
[2] https://software.intel.com/content/www/us/en/develop/articles/deep-learning-reference-stack-v8-0-now-available.html
[3] https://software.intel.com/content/www/us/en/develop/articles/deep-learning-reference-stack-v9-0-now-available.html
[4] https://software.intel.com/content/www/us/en/develop/articles/media-reference-stack-v3-0-now-available.html
[5] https://software.intel.com/content/www/us/en/develop/tools/containers.html
[6] https://software.intel.com/content/www/us/en/develop/articles/containers/dl-reference-stack-tensorflow-2-ubuntu.html
[7] https://github.com/IntelAI/models/tree/master/benchmarks/object_detection/tensorflow/ssd-mobilenet#int8-inference-instructions
[8] https://intel.github.io/stacks/dlrs/dlrs.html
[9] https://github.com/intel/stacks/tree/master/mers
[10] https://software.intel.com/content/www/us/en/develop/articles/containers/dl-reference-stack-tensorflow-ubuntu.html
[11] https://software.intel.com/content/www/us/en/develop/articles/containers/dl-reference-stack-pytorch-ubuntu.html
[12] https://software.intel.com/content/www/us/en/develop/articles/containers/dlrs-tensorflow-serving.html
[13] https://zeromq.org
[14] github.com/intel/stacks-usecase/tree/master/client/intelligent_collab
Notices and Disclaimers
Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel technologies may require enabled hardware, software, or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.