Last month, I presented a paper about temporal decoupling in virtual platforms at the DVCon Europe 2018 conference. Temporal decoupling is a key technology in virtual platforms, and can speed up the execution of a system by several orders of magnitude. In my own experiments, I have seen it provide a speedup of more than 1000x. In this blog, I will dig a little deeper into temporal decoupling and its semantic effects.
Making a fast virtual platform
Performance is critical for virtual platforms (VPs). When using a VP, we simulate the hardware of a computer system so that we can run software without the hardware. VPs are used to develop software before hardware is available, perform hardware-software co-design, test networked systems, resolve tricky bugs, enable continuous integration, fault-injection testing, and many other applications.
The target hardware and workloads for virtual platforms are often rather large - including examples like running a thousand target machines in a single simulation, or big database benchmarks and distributed business systems. Thus, high simulation performance is crucial in getting value out of VPs.
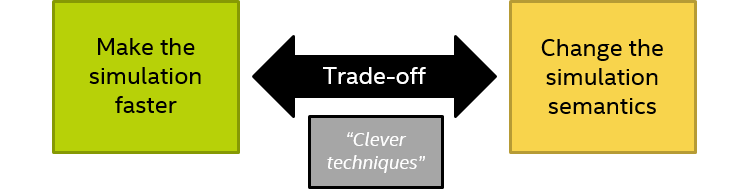
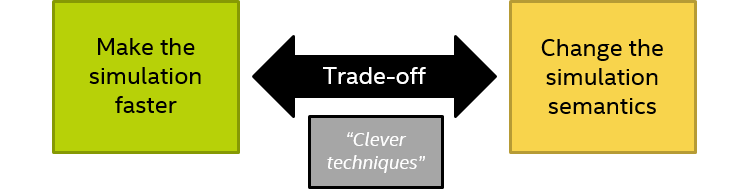
To make VPs fast, many techniques have been developed over the years, besides temporal decoupling. These include using loosely-timed models instead of cycle-detailed models, abstracting from the implementation details, implementing the functionality of the hardware only, transaction-level modeling (TLM) for interconnects, just-in-time (JIT) compilation from target to host, direct memory interfaces (DMI), idle loop detection (hypersimulation), and many others. However, there is no “free lunch,” and there is a fundamental trade-off here where speeding up the simulation might change the semantics of the simulation.
![The trade-off between making the simulation faster and changing the simulation semantics, with the “out” of using “clever techniques”]](/content/dam/developer/articles/technical/additional-notes-about-temporal-decoupling/temporal-decoupling1-799450.png) The trade-off between improving performance and maintaining semantics
The trade-off between improving performance and maintaining semantics
In my previous blog post, in my recent DVCon paper (the paper will be available for free in February of 2019), and in this blog post, I look at the trade-off for temporal decoupling – but there are trade-offs involved for all techniques. Often, the impact of trade-offs can be mitigated or minimized by clever techniques, as indicated in the illustration above. We will see some examples of this being presented below.
Temporal decoupling
With temporal decoupling, a system with multiple target processors (or other active units like accelerators) is simulated on a single host processor by letting each target processor run multiple simulation steps or cycles (its time quantum) before handing over to the next processor. The image below illustrates the idea, using five processors spread across three boards, and a time quantum of three cycles:
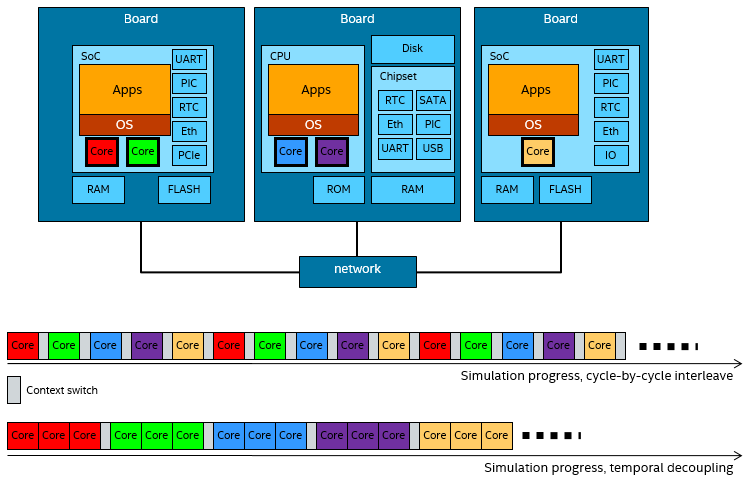 The core principle of temporal decoupling: running several instructions from one processor together, rather than switching on every cycle.
The core principle of temporal decoupling: running several instructions from one processor together, rather than switching on every cycle.
In a naïve execution model, the simulator would run each processor for one cycle and then switch to the next. This would closely approximate the parallel behavior seen in the real world, but at a very high cost in terms of execution time. First, each context switch between processors would invoke the simulator kernel, leading to a very high overhead-to-useful-work ratio. Second, by only running a single cycle at a time, each processor gets very poor locality, and it is essentially meaningless to try to use faster techniques like JIT compilation to speed up the execution, since each basic unit of translation would be a single instruction.
The technique is known to have been used at least since the late 1960s, including the fundamental trade-off between the length of the time quanta and the performance of the simulator:
 Excerpt from the 1969 paper, showing the type-written style. From page 3 of “A Program Simulator by Partial Interpretation”, by Fuchi et al, in Proceedings of the second symposium on Operating systems principles (SOSP’69), 1969.
Excerpt from the 1969 paper, showing the type-written style. From page 3 of “A Program Simulator by Partial Interpretation”, by Fuchi et al, in Proceedings of the second symposium on Operating systems principles (SOSP’69), 1969.
Speed results
Keeping everything else constant, increasing the time quantum length can increase performance radically. The chart below shows the relative speed as the time quantum goes from one cycle to two million cycles. The target system is a four-core Intel® Core® processor-based PC running Linux* and running a threaded program that keeps all cores busy at close to 100%.
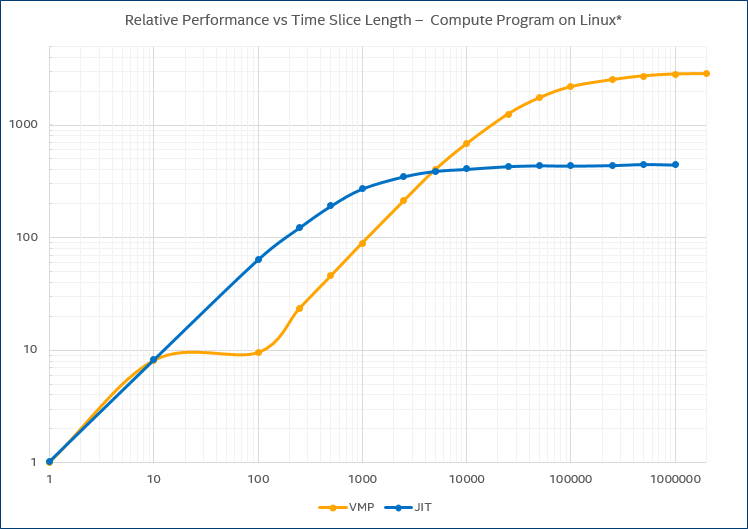
Example performance increase provided by temporal decoupling for a user-level program.
The curve labelled “JIT” indicates the speedup achieved using just-in-time compilation, and the curve labelled “VMP” indicates the speedup for Wind River Simics® VMP technology. VMP uses Intel® Virtualization Technology for Intel® 64 and IA-32 architectures (Intel® VT-x) to execute instructions directly on the host. For JIT, the speedup plateaus out at about 400x, and for VMP at around 2800x.
A speedup of “just” 100x is a big deal – it means the difference between a run that takes 1 minute and one that takes more than an hour and a half. It is the difference between “interactive” and “batch mode,” and between “nightly” and “weekly” tests.
Other workloads show similar performance curves. Booting Ubuntu Linux* on the same target system as used in the previous graph:
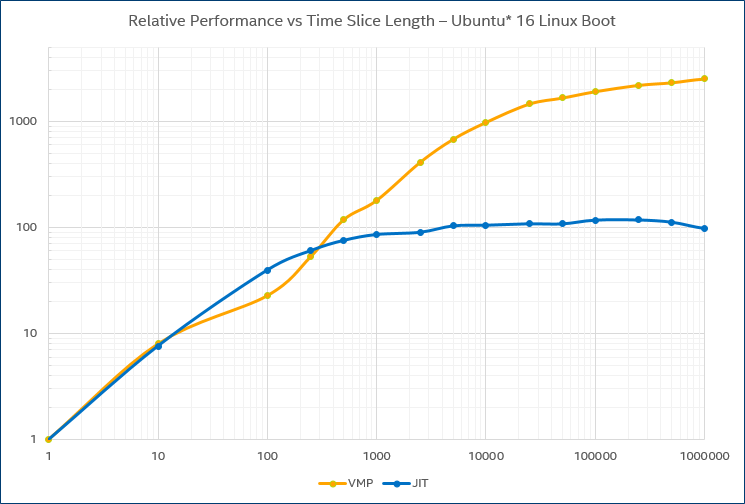 Example performance increase provided by temporal decoupling for an operating-system boot.
Example performance increase provided by temporal decoupling for an operating-system boot.
The graph for the boot shows the same general trend as for the user-level program, but with different specifics. The JIT line peaks at about 100x, while VMP speeds up to around 2400x – this shows that different workloads scale differently for different execution techniques. Still, it demonstrates the usefulness of stretching the time quantum out from 10k to 100k cycles or more. Overall, it seems that 10000 cycles or instructions is a good basic time quantum for a JIT-based virtual platform, and 100k cycles or more for one based on direct execution.
Changed semantics?
The general effect of temporal decoupling is to add a latency to when event or state changes from one processor becomes visible to another processor. For example, if software on one processor writes a value to memory, software on another processor will not see it until it gets to its time quantum. This effect means that software might see time differences between processors that are different from what they would be on hardware (and often larger).
Precisely what happens depends on the scheduling and design of the VP being used. In the DVCon paper, I make a distinction between two different ways to implement temporal decoupling with respect to how device models are handled (where “device model” means something that is not a processor).
In the first main variant, devices are run between processor time quanta – basically, they run in their own time quantum:
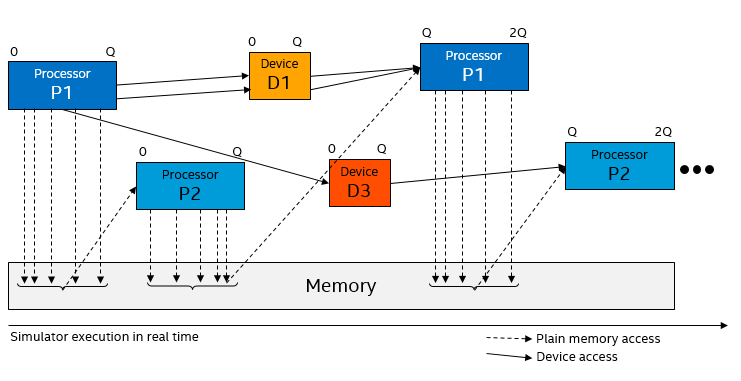 The data flow between processors and devices in temporal decoupling variant 1.
The data flow between processors and devices in temporal decoupling variant 1.
This means that information propagation from one processor to another over a device will take at least one time quantum: the first processor accesses the device, the device does its processing, and then notifies the second processor (like the flow from P1 to D3 to P2 in the illustration). It also means that if a device is interacting with a processor, the processor will see all device actions at the start of its time quantum. There is no way for a device to break into the middle of the time quantum of a processor. In particular, any interrupts from a device to a processor will only be visible at quantum boundaries.
Note that memory is handled differently than devices - for performance reasons, most VPs simply write values to shared memory as soon as the writes happen (using DMI). This means that memory updates are visible immediately to any processors that come later in the round-robin schedule, and that updates can appear to go backwards in time (a write done late in the time quantum on processor P1 will appear to have happened early in the time quantum on processor P2).
The second variant of temporal decoupling lets devices execute within the time slice of a processor when the processor accesses them, and lets them post events on a queue in the processor itself. This means that an interrupt from a device can come at any point during a time quantum, and that a device can send multiple interrupts to one processor during a time quantum and have them appear at different points in time within the time quantum. This variant is used in Simics, as it makes it easier to use long time slices with standard operating systems.
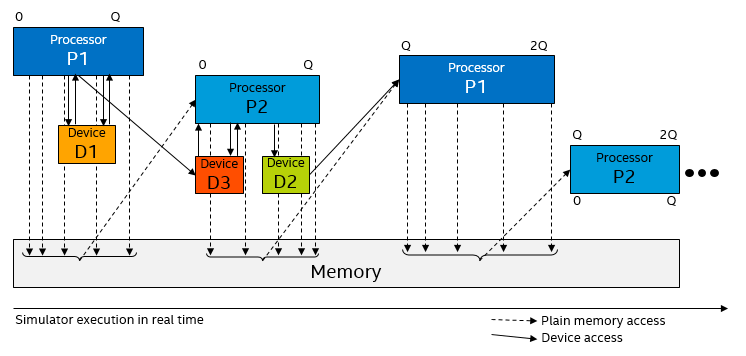 The data flow between processors and devices in temporal decoupling variant 2.
The data flow between processors and devices in temporal decoupling variant 2.
Variant two can be considered a “clever technique” that mitigates some of the drawbacks of temporal decoupling when it comes to processor-device interaction. Still, when events cross between processors and devices belonging to different processors, temporal decoupling will affect the timing of events.
This might sounds scary… but it is worth noting that in practice, in VPs, temporal decoupling has worked very well for most workloads for a very long time. It has enabled VPs to scale to very large workloads like networks of many machines (like this and this), and software that takes hours to run on real hardware.
However, “most” is not “all.” In the following, we will look at a few examples of where temporal decoupling has been observed to have an interesting effect on simulation semantics, and what can be done to mitigate these effects.
The Linux boot slow-down
In the early days of multicore computing in the mid-2000s, we were experimenting with booting Linux on a simulated dual-core Simics target, and optimizing the performance using longer time quanta. Initially, as the time quantum length was increased, the boot time decreased – as would be expected, since the simulator ran faster. But from 100k cycle time quanta, the boot time, as observed on the host, started to increase. That is shown by the yellow line in the graph below:
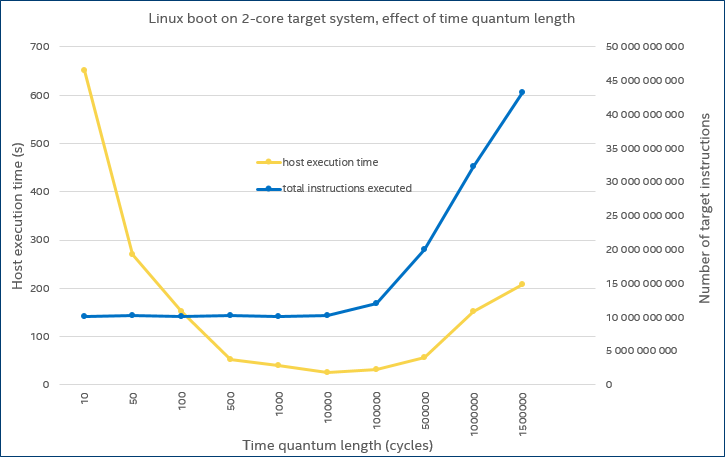 The host time and target virtual time for a Linux boot on a simulated dual-core processor.
The host time and target virtual time for a Linux boot on a simulated dual-core processor.
The reason for this loss of performance at longer time slices is shown by the blue line in the graph. When the time quantum was set to 100k cycles or more, the target system started to execute many more target instructions during the boot. From a performance perspective, the benefit of a longer time quantum was negated by the additional instructions executed. From a functionality perspective, the system timing started to become sufficiently different that the software behavior underwent a noticeable change.
The culprit was a piece of code in the Linux kernel that tried to calibrate the time difference between cores: when the time quantum got large, this code started to see large time differences between cores, which in turn made it loop many times to find a stable time difference. It always terminated in the end, but it took more and more target time as the time quantum increased. Note that in later versions of the Linux kernel, this particular algorithm was removed, so we do not see the same effect today when booting Linux on temporally decoupled VPs.
Locking in multicore software
One “obvious” effect of temporal decoupling is to reduce the number of interaction points between processors. A processor will only see actions taken by other processors at the end or beginning of a time quantum – or in general, any active unit that runs temporally decoupled will see actions only from other units at time quantum boundaries.
Consider the case of locking in a concurrent multithreaded program running on a multicore processor. If code that is running on one processor core is waiting for a lock that is being held by code running on another processor core, it will not see the lock state change until the other processor core has had time to run. This could result in certain threads spending a lot of time just waiting for a lock instead of processing, and thus software execution being less parallel that it would be on hardware.
It is also the case that it will not see interference and contention for the lock or shared memory location from another processor core since it is running alone during its time slice. A processor core that starts a time quantum unlocked will be able to rapidly take it many times over within its time slice, since it is uncontested for the duration. On real hardware, it might see more locking failures (assuming we have intense competition for the lock). This does not affect the correctness of the software per se, but it might affect the load balance of a concurrent multicore program.
However, in practice, the impact of this effect appears to be limited as long as the time quantum is smaller than the typical interval of interaction between parallel threads (or parallel units in general). In the literature on computer architecture simulation, this is seen quite often: dialing down the time quantum to the time for a level 2 cache miss is sufficient to get good results – there is no need to use a single-cycle time quantum in most cases.
Here is one example of an experiment demonstrating the effect. We ran the radiosity program from the splash-3 open-source parallel benchmark suite on a simulated 32-core IA machine running Ubuntu Linux 16.04. The number of threads used was varied from 1 to 32, and the resulting speedup compared to the single-thread case measured. The experiment was repeated three times for each of five different time quantum settings, ranging from 100 to 400k cycles.
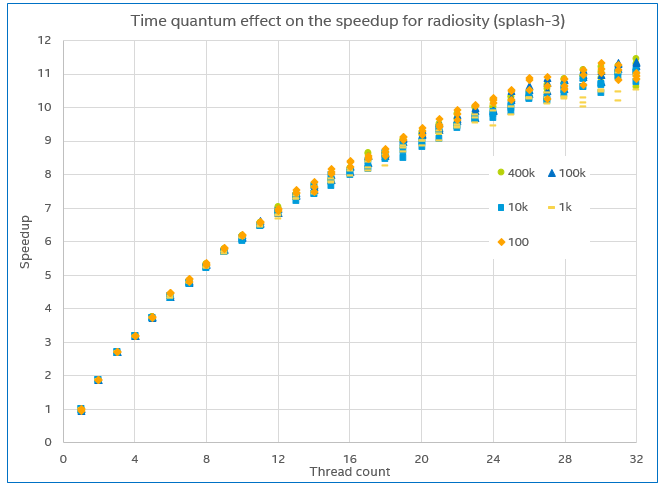 The measured speedup for the radiosity program, varying the time quantum length and thread count..
The measured speedup for the radiosity program, varying the time quantum length and thread count..
The resulting plot is shown above. The scaling observed is basically the same regardless of the time quantum. If temporal decoupling were to seriously skew the results, we would have expected to see the trend for 100 cycles diverge from the other time quantum settings, but no such trend can be seen.
Debugging tightly-synchronized code
The debugging and analysis of the locking code itself is a use case that is also affected by temporal decoupling. In the previous section, the software uses existing locking and synchronization mechanisms, and just assume that they work. However, at some point the code for the locks has to be created, tested, and debugged. If you want to do that on a virtual platform (which you should), some care has to be exercised.
Typically, in an operating system (OS), locks are implemented using various hardware mechanisms that provide atomic operations in user space, as well as falling back to the OS kernel (for example, Linux futexes). To debug this code, we really want to see the cycle-by-cycle interaction between cores. Thus, a time quantum of 1 cycle is what makes sense… But if we set the time quantum to one, it is going to take a very long time to boot the system to the point where the debug is going to happen.
The solution is to cleverly change the time quantum on fly. To support this kind of debug, the OS kernel developer would set up tests that start locking operations across multiple cores, making sure to stop the simulator right before the tests are about to start. When this happens, the simulator dials down the time quantum on the fly, and debug, trace, and analysis can proceed.
 Dialing down the time quantum as a critical point in the execution to facilitate detailed analysis.
Dialing down the time quantum as a critical point in the execution to facilitate detailed analysis.
The key insight is that the time quantum can be varied during a run in order to achieve performance for positioning along with detailed insights. It is conceptually similar (but a lot lighter weight) to the “gear shifting” or “mode change” used for positioning computer architecture workloads for detailed simulation.
Those pesky time-outs
We have also seen temporal decoupling trigger time-outs in software that uses time-out periods shorter than a time quantum. In a typical case, a processor would send a message to another processor (or other active unit), and wait a short while for a reply, and time-out if a reply is not received before the wait time is up.
On physical hardware, both processors run concurrently, and unless a real problem developed, the other processor would reply before the time-out:
 Processor 1 and Processor 2 are running concurrently. Processor 1 sends a ping to Processor 2 and then goes on to wait. Immediately on getting the ping, Processor 2 processes it and sends a pong back to Processor 1. Processor 1 is happy with the reply and does not time out.
Processor 1 and Processor 2 are running concurrently. Processor 1 sends a ping to Processor 2 and then goes on to wait. Immediately on getting the ping, Processor 2 processes it and sends a pong back to Processor 1. Processor 1 is happy with the reply and does not time out.
In a temporally decoupled virtual platform, this code might result in a time-out if the wait period ends before the other processor is scheduled to run. Processor 2 sees the ping message only at the start of its time quantum, and it computes and sends a result just as quickly as it would on hardware... as seen from its local time perspective. However, from the perspective of Processor 1, it is too late, since it completed the time-out waiting code in its own time quantum, before Processor 2 could reply.
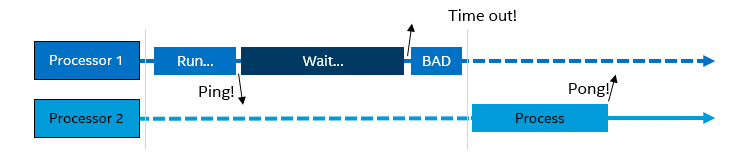 Processor 1 sends a ping to Processor 2 and then goes on to wait, in its own time quantum. The waiting period ends before time quantum ends, and Processor 1 decides it is a time-out and goes on to a bad state. Then, Processor 2 gets to start its time quantum, sees the ping, processes it, and sends a pong back to Processor 1. But Processor 1 does not care: it has already timed out.
Processor 1 sends a ping to Processor 2 and then goes on to wait, in its own time quantum. The waiting period ends before time quantum ends, and Processor 1 decides it is a time-out and goes on to a bad state. Then, Processor 2 gets to start its time quantum, sees the ping, processes it, and sends a pong back to Processor 1. But Processor 1 does not care: it has already timed out.
This kind of issue can be solved in a few different ways.
The most obvious is to dial down the time quantum, as discussed above for debugging locks. However, this is potentially bad for the system overall: there might be 50 other processors in the system at the same time which are not running the problematic software, and dialing down the time quantum globally would hurt performance too much. It is also not obvious how short the time quantum has to be to make a particular case work.
One solution is to simply change the software to make time-outs longer when running on a virtual platform. The software would either be compiled in a special way for use on the VP, or it would dynamically detect that it runs on a VP and change its behavior. This is not generally considered a good option, since we want to run unmodified binaries on a VP – and maintaining a special variant of the code just for VP usage is not a good workflow. Still, it is an easy way to get through some tricky cases.
Another solution is to stall the sending processor so that it does not begin to wait and count down to the time-out before the replying processor has time to run. This leaves the rest of the system undisturbed, and should be more robust than guessing a short time quantum. Typically, when the ping is sent, the processor sending it is stalled for one time quantum. This should leave other processors time to see the message and reply, with a flow as shown below:
 Processor 1 sends a ping to Processor 2 and is then stalled for the rest of its time quantum. Then, Processor 2 gets to run, processes the ping and sends a pong back to Processor 1. Processor 1 then starts its next time quantum, sees the pong reply, and is happy.
Processor 1 sends a ping to Processor 2 and is then stalled for the rest of its time quantum. Then, Processor 2 gets to run, processes the ping and sends a pong back to Processor 1. Processor 1 then starts its next time quantum, sees the pong reply, and is happy.
If possible, it might be good to delay the delivery of messages so that the ping and pong are seen some distance into the receiving processors’ time quanta. This avoids messages appearing to travel backwards in time, and it gives a correct relative time between request and reply from the perspective of the sending processor. If messages are sent via shared memory, this is hard to do, but for mechanisms mediated by devices like interrupts, it can be usually be incorporated into the hardware model.
Empty performance
The previous example dealt with ping-pong protocols, with very short time-outs, and with the primary problem being to avoid timing out. For target systems that do not suffer from time outs, temporal decoupling can still cause interesting behaviors. When the two units communicating are in separate time domains, the end-to-end time for a ping-pong exchange would be at least two time quanta. This can affect the speed at which jobs complete in the VP, compared to hardware.
In the diagram below, the blue line (virtual time) illustrates this effect for the case of a simulated network inside a VP. As network latency (time quantum length) gets bigger, the virtual time needed to complete a particular network transfer grows in a way very similar to what happened with the Linux boot discussed above.
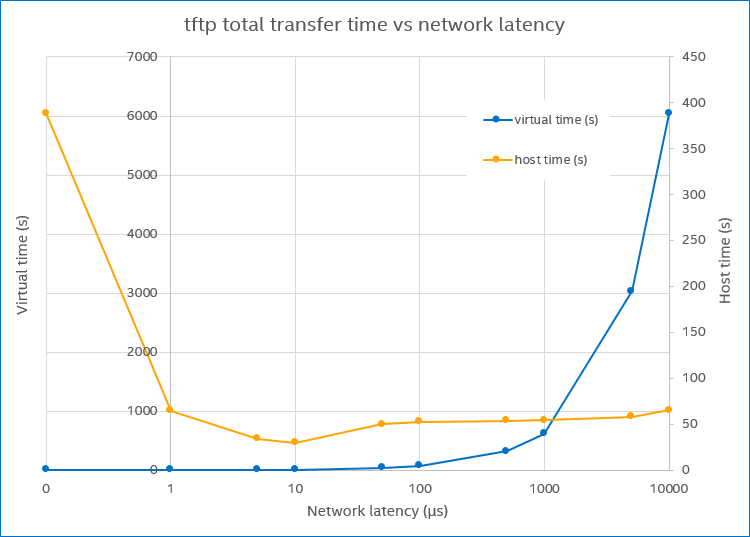 The host time and target virtual time needed to complete a tftp transfer, as the network latency changes.
The host time and target virtual time needed to complete a tftp transfer, as the network latency changes.
The target system contains two separate machines: a tftp client and a tftp server. The network latency indicates the time it takes for a single Ethernet packet to go from one to the other, in virtual time. Since tftp waits for an acknowledgement for each packet before sending the next, the time to transfer a certain amount of data (a file) will be essentially linear to the network latency, which is what is shown on the blue line (note the log scale on the x axis).
However, unlike the Linux kernel case above, the simulator execution time on the host stays essentially constant as the virtual time goes up. This means that the apparent speed of the simulator is increasing as the latency increases. Between 10 µs and 10000µs, we see a speed-up of about 150x when considering how much virtual time is executed for each host second. Some of this is thanks to temporal decoupling, but from about 100 µs it basically peaks. The following performance increase comes from the fact that the system is mostly idle: both the client and server spend most of their time waiting for a packet from the other side. Thus, hypersimulation through idle time dominates the execution. Doing nothing can be done very quickly in a VP.
In this case, dialing up the latency to ludicrous levels creates a VP that appears to run at a speed more than 100x faster than real time: each target minute takes less than a single second to simulate. That is impressively fast on paper, but it achieves nothing useful. It is just “empty performance.”
It’s not a bug, it’s a feature
It is also possible to consider the behavior change induced by temporal decoupling not as a bug but as a feature. Or more precisely, as a de-bug feature. Temporal decoupling provides an easily controllable lever to change the behavior of a system, especially when running parallel software on a multicore and multi-machine system. By running the same software test with different temporal decoupling settings, different executions paths will result, since events on parallel processors will happen in different order and the execution of different pieces of code will interleave in different ways. This gives us a way to provoke and find intermittent and rare timing-dependent bugs such as race conditions and order-dependent bugs.
The idea is to run a test case several times over with different time quantum lengths. This will produce a set of different executions, and eventually one will hit a timing-dependent bug. Given that a simulator such as Simics is perfectly deterministic and repeatable, the bug can be reproduced any number of times for tracing, analysis, and debug. One example of this method is to debug Simics itself using Simics, as chronicled in my blog post at Wind River. Indeed, this shows how a simulator can be used for more than just trying to imitate the real world. It also can be used to expand the set of achievable test variations for system tests.
Full speed ahead!
If we go back to where we started this blog, talking about temporal decoupling as a trade-off between performance and sematic change…
…we can see that temporal decoupling has definite performance benefits, and it is pretty much mandatory in order to run large software workloads on a VP. That also means the simulation semantics will change, but this effect is usually not a problem. Software today typically does not expect precise timing on events and is written to run on hardware with widely varying execution times, which also makes it robust to the kind of disturbances introduced by temporal decoupling.
Still, there are examples where temporal decoupling does produce noticeable effects, and we presented some of these and discussed ways to deal with the issues. Sometimes, it is necessary to reduce the time quantum to a single cycle or a small value to achieve the desired results from the VP. In other cases, it is possible to run with long time quanta by modifying the timing of events or the execution of code on a single processor.