Examining the impact of the ADCX, ADOX, and MULX instructions on haproxy performance
One of the key components of a large datacenter or cloud deployment is the load balancer. When it’s a service provider’s goal to establish high availability and low latencies, they will require multiple redundant servers, a transparent failover mechanism between them, and some form of performance monitoring in order to direct traffic to the best available server. This infrastructure must present itself as a single server to the outside world.
This is the role that the SSL-terminating load balancer is designed to fill in a secure web service deployment: every incoming session must be accepted, SSL-terminated, and transparently handed off to a back-end server system as quickly as possible. Unfortunately, this means that the load balancer is a concentration point, and potential bottleneck, for incoming traffic.
This case study examines the impact of the Intel® Xeon® E5 v4 processor family and the ADCX, ADOX, and MULX instructions on the SSL handshake. By using the optimized algorithms inside OpenSSL*, this processor can significantly increase the load capacity of the Open Source load balancer, haproxy*.
Background
The goal of this case study is to examine the impact of code optimized for the Intel Xeon v4 line of processors on the performance of the haproxy load balancer.
The Xeon v4 line of processors adds two new instructions, ADCX and ADOX. These are extensions of the ADC instruction but are designed to support two separate carry chains. They are defined as follows:
adcx dest/src1, src2
adox dest/src1, src2
They differ from the ADC instruction in how they make use of the flags. Both instructions compute the sum of src1 and src2 plus a carry-in, and generate an output sum dest and a carry-out, however the ADCX instruction uses the CF flag for carry-in and carry-out (leaving the OF unchanged), and the ADOX instruction uses the OF flag for carry-in and carry-out (leaving the CF flag unchanged).
These instructions allow the developer to maintain two independent carry chains, which the CPU can process and optimize within a single hardware thread in order to increase instruction-level parallelism.
Combined with the MULX instruction, which was introduced with the Xeon v3 line of processors, certain algorithms for large integer arithmetic can be greatly accelerated. For more information, see the white paper “New Instructions Supporting Large Integer Arithmetic on Intel® Architecture Processors”.
Public key cryptography is one application that benefits significantly from these enhancements. This case study looks at the impact on the RSA and ECDSA algorithms in the SSL/TLS handshake: the faster the handshake can be performed, the more handshakes the server can handle, and the more connections per second that can be SSL-terminated and handed off to back-end servers.
The Test Environment
The performance limits of haproxy were tested for various TLS cipher suites by generating a large number of parallel connection requests, and repeating those connections as fast as possible for a total of two minutes. At the end of those two minutes, the maximum latency across all requests was examined, as was the resulting connection rate to the haproxy server. The number of simultaneous connections was adjusted between runs to find the maximum connection rate that haproxy could sustain for the duration without session latencies exceeding 2 seconds. This latency limit was taken from the research paper “A Study on tolerable waiting time: how long are Web users willing to wait?”, which concluded that two seconds is the maximum acceptable delay in loading a small web page.
In order to make a comparison between the current and previous generation of Xeon processors, haproxy v1.6.3 was installed on the following server systems:
Table 1. Test server configurations
| Server 1 | Server 2 | |
| CPU | Intel® Xeon® E5-2697 v3 | Intel® Xeon® E5-2699 v4 |
| Sockets | 2 | 2 |
| Cores/Socket | 14 | 22 |
| Frequency | 2.10 GHz | 2.10 GHz |
| Memory | 64 GB | 64 GB |
| Hyper-Threading | Off | Off |
| Turbo Boost | Off | Off |
haproxy is a popular, feature-rich, and high-performance Open Source load balancer and reverse proxy for TCP applications, with specific features designed for handling HTTP sessions. More information on haproxy can be found at HAProxy.
The SSL capabilities for haproxy were provided by the OpenSSL library. OpenSSL is an Open Source library that implements the SSL and TLS protocols in addition to general purpose cryptographic functions. The 1.0.2 branch is enabled for the Intel Xeon v4 processor and supports the ADCX, ADOX, and MULX instructions in selected public key cryptographic algorithms. More information on OpenSSL can be found at OpenSSL.
The server load was generated by up to six client systems as needed, on a mixture of Xeon E5 v2 and Xeon E5 v3 class hardware. All systems were connected together using a 40 Gbps switch.
The high-level network diagram for the test environment is shown in Figure 1.
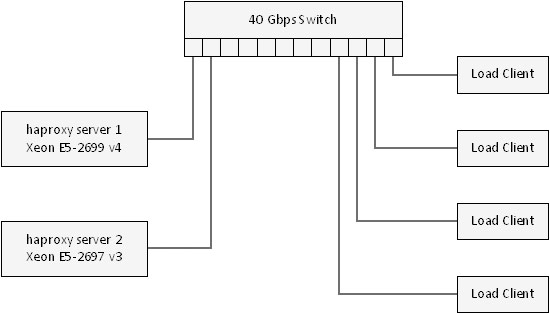
Figure 1. Test network diagram.
The actual server load was generated using multiple instances of the Apache* Benchmark tool, ab, an Open Source utility that is included in the Apache server distribution. A single instance of Apache Benchmark was not able to create a load sufficient to reach the server’s limits, so it had to be split across multiple processors and, due to client CPU demands, across multiple hosts.
Because each Apache Benchmark instance is completely self-contained, however, there is no built-in mechanism for distributed execution. A synchronization server and client wrapper were written to coordinate the launching of multiple instances of ab across the load clients, their CPU’s, and their network interfaces, and then collate the results.
The Test Plan
The goal of the test was to determine the maximum load in connections per second that haproxy could sustain over 2-minutes of repeated, incoming connection requests, and to compare the Xeon v4 optimized code (which makes use of the ADCX, ADOX, and MULX instructions) against previous generation code that used a pure AVX2 implementation, running on Xeon v3.
To eliminate as many outside variables as possible, all incoming requests to haproxy were for its internal status page, as configured by the monitor-uri parameter in its configuration file. This meant haproxy did not have to depend on any external servers, networks or processes to handle the client requests. This also resulted in very small page fetches so that the TLS handshake dominated the session time.
To further stress the server, the keep-alive function was left off in Apache Benchmark, forcing all requests to establish a new connection to the server and negotiate their own sessions.
The key exchange algorithms that were tested are given in Table 2.
Table 2. Selected key exchange algorithms
| Key Exchange | Certificate Type |
| ECDHE-RSA-2048 | RSA, 2048-bit |
| ECDHE-RSA-4096 | RSA, 4096 bit |
| ECDHE-ECDSA | ECC, NIST P-256 |
Since the bulk encryption and cryptographic signing were not a significant part of the session, they were fixed at AES with a 128-bit key and SHA-1, respectively. Varying AES key size, AES encryption mode, or SHA hashing scheme would not have an impact on the results.
Tests for each cipher were run with only one active core per socket (two cores active per server). Reducing the systems in this manner, the minimum configuration allowed in the test systems, effectively simulates low-core-count systems and ensures that haproxy performance is limited by the CPU rather than other system resources. These measurements can be used to estimate the overall performance per core, as well as estimate the performance of a system with many cores.
The ECDHE-ECDSA cipher was tested both at 2 cores and with multiple cores, doubling the core count at the conclusion of each test, topping out at 44 cores (the maximum core count supported by the system). This tested the full capabilities of the system, examining how well the performance scaled to a many-core deployment and also introduced the possibility of system resource limits beyond just CPU utilization.
System Configuration and Tuning
Haproxy was configured to operate in multi-process mode, with one worker for each physical thread on the system.
An excerpt from the configuration file, haproxy.conf, is shown in Figure 2.
global
daemon
pidfile /var/run/haproxy.pid
user haproxy
group haproxy
crt-base /etc/haproxy/crt
# Adjust to match the physical number of threads
# including threads available via Hyper-Threading
nbproc 44
tune.ssl.default-dh-param 2048
defaults
mode http
timeout connect 10000ms
timeout client 30000ms
timeout server 30000ms
frontend http-in
bind :443 ssl crt combined-rsa_4096.crt
# Uncomment to use the ECC certificate
# bind :443 ssl crt combined-ecc.crt
monitor-uri /test
default_backend servers
Figure 2. Excerpt from haproxy configuration
To support the large number of simultaneous connections, some system and kernel tuning was necessary. First, the number of file descriptors was increased via /etc/security/limits.conf:
* soft nofile 200000
* hard nofile 300000
Figure 3. Excerpt from /etc/security/limits.conf
And several kernel parameters were adjusted (some of these settings are more relevant to bulk encryption):
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
# Increase system IP port limits to allow for more connections
net.ipv4.ip_local_port_range = 2000 65535
net.ipv4.tcp_window_scaling = 1
# number of packets to keep in backlog before the kernel starts
# dropping them
net.ipv4.tcp_max_syn_backlog = 3240000
# increase socket listen backlog
net.ipv4.tcp_max_tw_buckets = 1440000
# Increase TCP buffer sizes
net.core.rmem_default = 8388608
net.core.wmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_mem = 16777216 16777216 16777216
net.ipv4.tcp_rmem = 16777216 16777216 16777216
net.ipv4.tcp_wmem = 16777216 16777216 16777216
Figure 4. Excerpt from /etc/sysctl.conf
Some of these parameters are very aggressive, but the assumption is that this system is a dedicated load-balancer and SSL/TLS terminator.
No other adjustments were made to the stock SLES 12 server image.
Results
The results for the 2-core case are shown in Figure 5 and Figure 6.
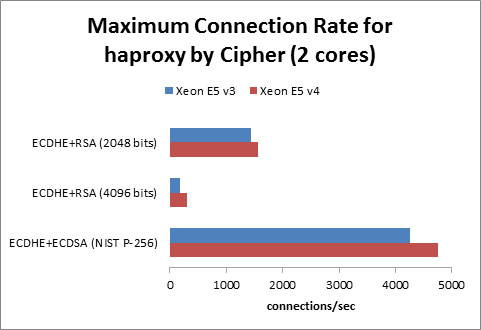
Figure 5. Maximum connection rate for haproxy by cipher (2 cores)
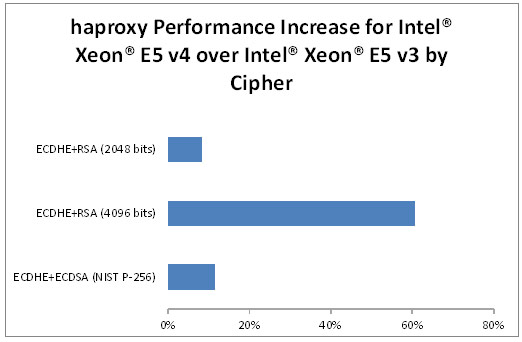
Figure 6. haproxy performance increase for Intel® Xeon® E5 v4 over Intel® Xeon® E5 v3 by cipher
All three of these ciphers show significant gains over the previous generation of Xeon processors. The largest increase comes from using RSA signatures with 4096-bit keys. This is because the AVX algorithm for RSA in OpenSSL contains a special-case code path when the key size is 2048 bits. At other key sizes, a generic algorithm is used, and the 4096 bit key results in an over 60% gain in performance when moving from the Xeon v3 family to the Xeon v4 family of processors.
The ECDSA-signed cipher sees a performance boost of over 11%.
In Figure 7, which uses logarithmic scales (base 2), we see how the performance of haproxy scales with the number of CPU cores when using the ECDHE-ECDSA cipher.
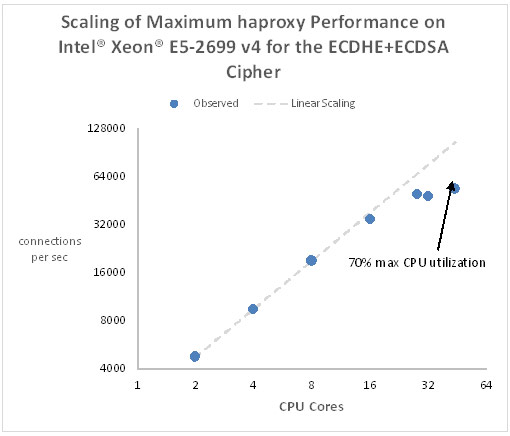
Figure 7. Scaling of maximum haproxy performance on Intel® Xeon® E5-2699 v4 for the ECDHE+ECDSA cipher
Performance scales linearly with the core count up to about 16 cores, and starts leveling off shortly after that. Above 16 cores, the CPU’s are no longer 100% utilized indicating that our overall system performance is not CPU-limited. With this many cores active, we have exceeded the performance limits of the interrupt-based network stack. The maximum, sustainable connection rate reached with all 44 cores active is just under 54,000 connections/sec, but the maximum CPU utilization never exceeds 70%.
Conclusions
The optimizations for the Xeon E5 v4 processor result in significant performance gains for the haproxy load balancer using the selected ciphers. Each key exchange algorithm realized some benefit, ranging from 9% to over 60%.
Arguably most impressive, however, is the raw performance achieved by the ECDHE-ECDSA cipher. Since it provides perfect forward secrecy, there is simply no reason for a Xeon E5 v4 server to use a straight RSA key exchange. The ECDHE cipher not only offers this added security, but it adds significantly higher performance. This does come at the cost of added load on the client, but the key exchange in TLS only takes place at session setup time so this is not a significant burden for the client to bear.
On a massively parallel scale, haproxy can maintain connection rates exceeding 53,000 connections/second using the ECDHE-ECDSA cipher, and do so without fully utilizing the CPU. This is on an out-of-the-box Linux distribution with only minimal system and kernel tuning. It is conceivable that even higher connection rates could be achieved if the system could be optimized to remove the non-CPU bottlenecks, a task beyond the scope of this study.
Additional Resources
Accelerating SSL Load Balancers with Intel® Xeon® v3 Processors
About the Author
John Machalas has worked for Intel since 1994 and spent most of those years as a UNIX systems administrator and systems programmer. He is now an application engineer working primarily with security technologies.