
With today’s ongoing explosion of technology and AI, AI tools can help supercharge and streamline several aspects of a manufacturing operation. This includes the development of AI solutions to help track flaws in production, supply-chain bottlenecks, and other trends faster in order to help reduce costs and increase production. With AI software optimizations and advanced development tools from Intel, developers can enhance manufacturing operations through the power of analytics and AI.
As an example, automated AI and data analytics solutions for internal use are improving production pipelines and reducing Intel manufacturing facilities' costs across the globe. By developing, running, and scaling AI workloads, further AI optimizations delivered efficiency, and even better and faster results. This was completed by using the power of Intel® AI tools such as Intel® Distribution of Modin* and Intel® Extension for Scikit-learn*. This way, Intel software engineers and manufacturers can operate and receive important insights and analytics on their products in a faster time frame–leading to significant reductions to costs and waste by using Intel's very own software and hardware optimizations.
Making pandas Workloads Run Even Faster with Intel® Distribution of Modin*
Let’s take a look at one of the tools used to help speed up manufacturing analytics workloads: Intel Distribution of Modin.
Intel Distribution of Modin is a drop-in replacement library for pandas that can accelerate the popular data analytics framework with a single line of code: import modin.pandas as pd (as opposed to import pandas as pd) and no further set up or effort is needed. Think of it as hitting a Nitro Boost in a car; it is already powerful compared to other cars, but to get ahead of other race cars, an accelerant is needed.
Intel Distribution of Modin parallelizes pandas, breaking away from the single-threaded limitations. It can even go so far as to scale seamlessly, such as through Ray and Dask clusters as well as oneAPI Heterogenous Data Kernels (oneHDK) back ends that Intel developed, while letting developers continue to use the popular pandas API. Modin takes advantage of these frameworks by smartly distributing data and computational processes across any and all available cores, unlike stand-alone pandas, which can only use a single core at a time.
Intel Distribution of Modin clearly provides users simplicity in configuring and running over pandas. It is the ideal tool for many scenarios, and with a variety of powerful back ends supported, any developer can take advantage of this simple yet powerful tool to witness similar speedups in their own projects. (See: Getting Started Guide, Introductory Blog.)
This was the case with the OPEDAWEB platform. When looking for opportunities to improve its platform performance on ETL (data extract, transfer, and load) workloads, the simple drop-in nature of Intel Distribution of Modin provided an easily implemented, optimized solution. Developers could focus on improving and creating more workloads on the OPEDAWEB platform instead of expending more resources on overhauling its existing software architecture to scale better with the data requirements.
Accelerating ETL Workloads
By integrating Intel Distribution of Modin with a Ray back end into the data loading and preprocessing phases of ETL workloads on the OPEDAWEB tool, workloads can see significant performance gains. For example, the optimized yield ETL workload showed significant speedups of up to 4.16x relative speed-up compared to the original pandas workload. Even more optimizations are in progress to accelerate more ETL workloads on the platform.
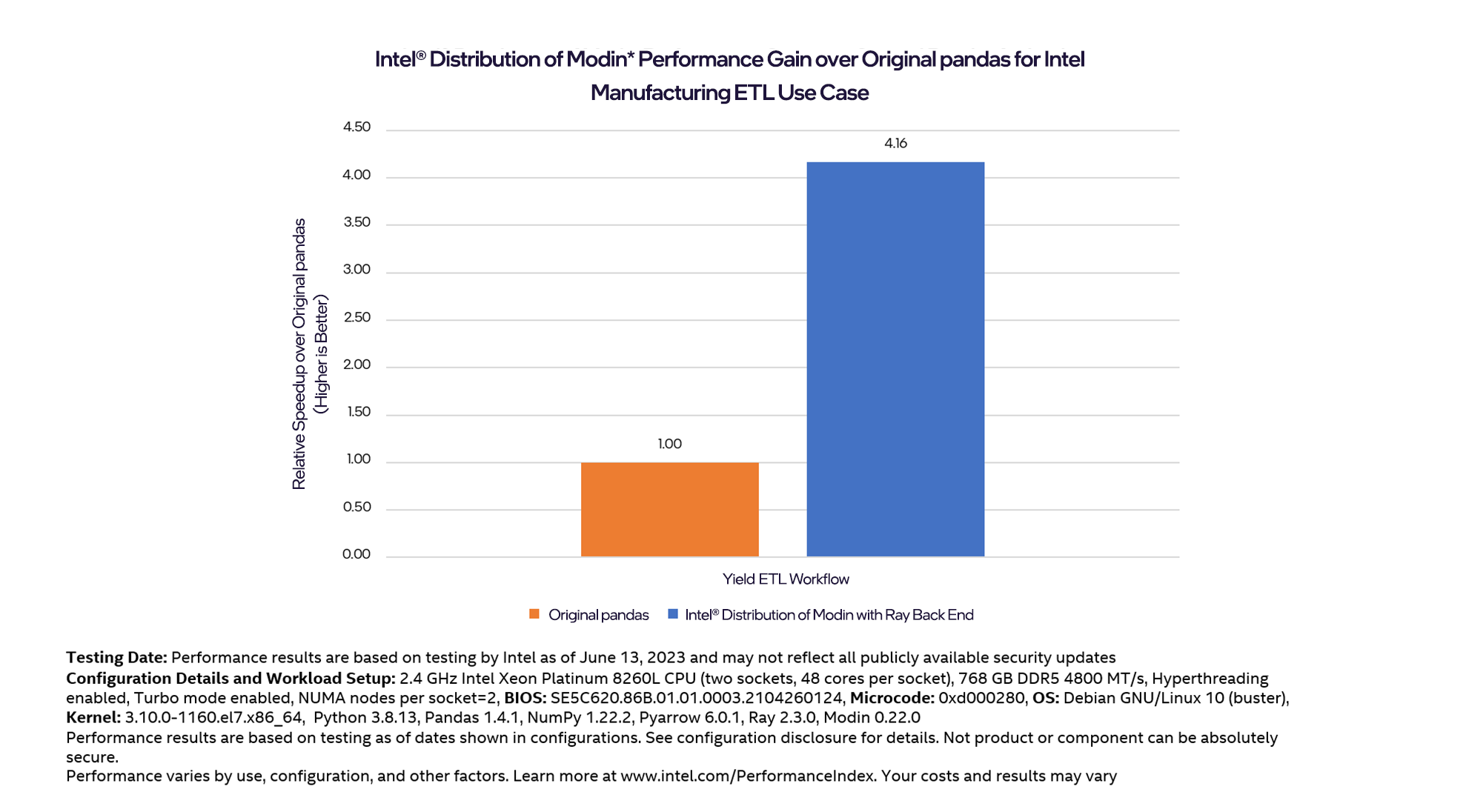
Image 1. Intel Manufacturing, Supply, and Operations Advanced Analytics (MSOA) yields an ETL workflow performance gain
The results: Manufacturing customers can process their data even faster, meaning they can spend less time waiting on their analytics workloads to run and instead focus on identifying key insights and patterns from manufacturing data to improve processes and results.
Creating Custom Manufacturing AI Models Using scikit-learn*
Another Intel AI technology delivering performance gains is Intel Extension for Scikit-learn. scikit-learn is a Python* module for machine learning tasks. The Intel Extension for Scikit-learn effortlessly speeds up scikit-learn applications for Intel CPUs and GPUs across single- and multi-node configurations. The extension package dynamically patches scikit-learn estimators (no code changes required) while improving performance across compatible machine learning algorithms. Patching is the key to this accelerated performance as it replaces the default scikit-learn algorithms with their optimized variants that come with the extension.
One way to easily patch scikit-learn is by importing the additional Intel Extension for Scikit-learn for Python package (sklearnex), enabling optimizations via the sklearnex.patch_sklearn() method, and then simply importing scikit-learn estimators.
The optimizations for Intel CPUs can be enabled as follows:
import numpy as np
from sklearnex import patch_sklearn
patch_sklearn()
from sklearn.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
The Intel GPU optimizations can be enabled as follows:
import numpy as np
import dpctl
from sklearnex import patch_sklearn, config_context
patch_sklearn()
from sklearn.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
with config_context(target_offload="gpu:0"):
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
Overall, the software acceleration achieved is derived from the use of vector instructions, Intel® architecture hardware-specific memory optimizations, and threading optimizations enabled through the oneAPI Data Analytics Library (oneDAL). It's a clean, efficient, powerful, user-friendly library that truly requires almost no deeper understanding to make it work in existing codebases and produce substantial results.
Accelerating MLOps Models
By using Intel Extension for Scikit-learn, Intel accelerated its MLOps platform where customers in the factories can create and deploy their own custom machine learning models to do yield analysis, root-cause analysis, manufacturing process control, and more, all with little to no machine learning experience. Optimization results achieved up to 4.5x relative speed-up with simple, intuitive changes of only a few lines of code. Specifically, random forest algorithms were used most in MLOps workloads, but Intel Extension for Scikit-learn was also used for other algorithms, such as logistic regression and linear regression. Over 400% performance gains were seen on random forest algorithm during both model training and inference workloads.
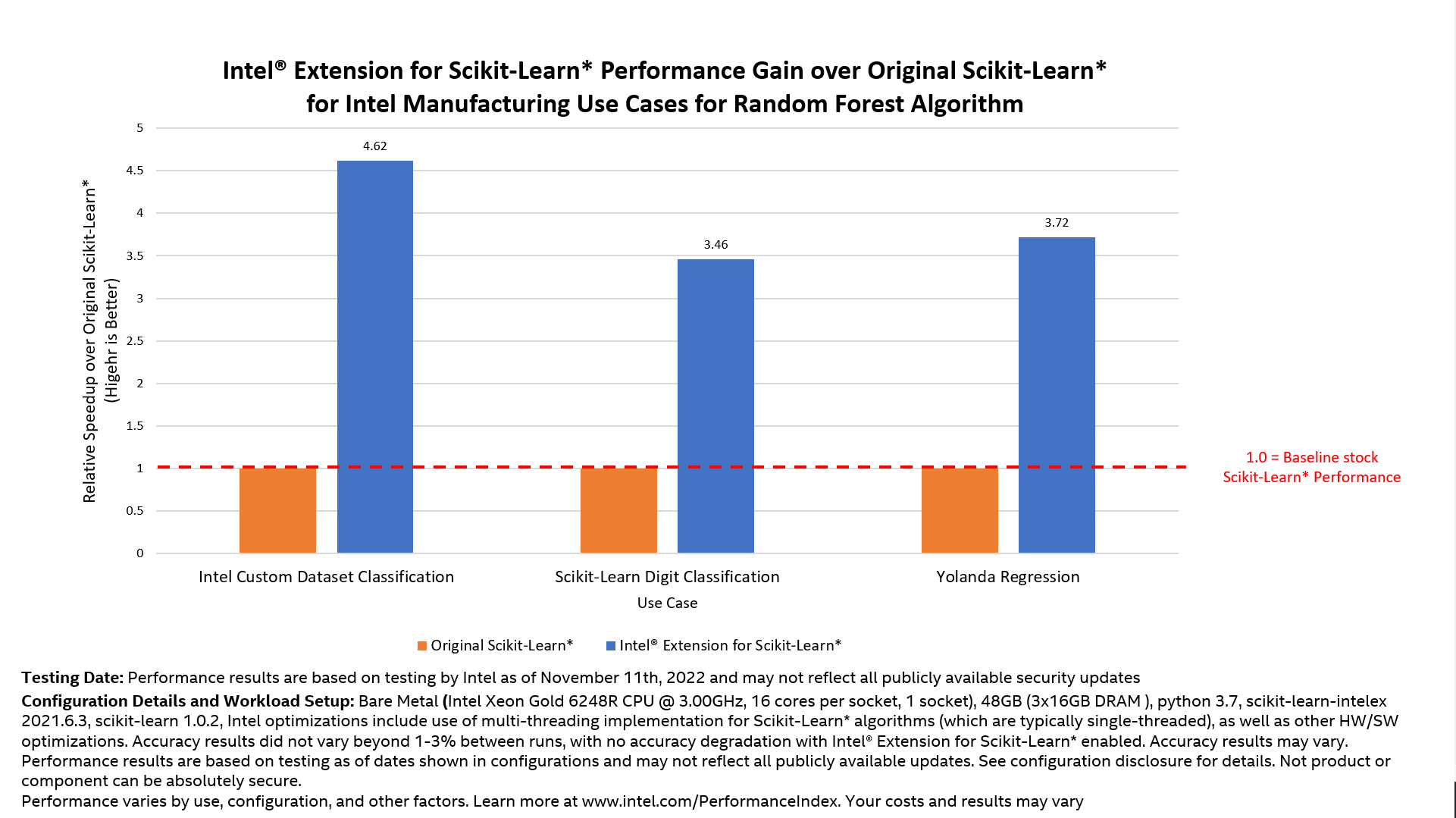
Figure 2. Intel Manufacturing, Supply, and Operations Advanced Analytics (MSOA) MLOps platform performance gain with the random forest algorithm
By adding these performance optimizations to the MLOps platform, internal manufacturing customers and decision-makers within Intel's manufacturing facilities across the globe can use these optimizations to speed up their machine learning models, achieve greater results, and detect manufacturing problems (such as flaws) even faster. This means less time spent waiting for MLOps platform models to train and run, and instead, more time is focused on improving the hardware manufacturing pipeline.
Conclusions and Next Steps
Intel AI technologies are simple to implement and can result in clear performance gains for AI workloads targeted for manufacturing. We are eager to see more results by those in the industry using Intel's AI hardware and software tools to help reduce costs and speed up manufacturing processes.
Try out Intel Distribution of Modin and Intel Extension for Scikit-learn and see for yourself. Check out Intel's other AI Tools and framework optimizations, as well as learn about the unified, open, standards-based oneAPI programming model that forms the foundation of the Intel AI software portfolio.