Introduction
Intel® Integrated Performance Primitives (Intel® IPP) provides optimization for LZ4 - open source lossless data compression library. LZ4 features an extremely fast decoder, with speed. The data compression domain of the Intel® IPP library contains several functions which could speed up LZ4 data compression method for both data compression and decompression operations. In this article, the benefits of using LZ4 with Intel® IPP patched library will be discussed. An example is also provided to use Intel® IPP library for LZ4 compression/decompression functions.
Intel® IPP library is available as part of the Intel® oneAPI Base Toolkit.
Below is a simplified list of Intel® IPP LZ4 functions and their short description. Please refer to the developer reference guide for more details and examples.
| Intel® IPP LZ4 Functions | Description |
|---|---|
| EncodeLZ4HashTableGetSize | Calculates the size of the LZ4 hash table. |
| EncodeLZ4HashTableInit EncodeLZ4DictHashTableInit |
Initializes the LZ4 hash table. |
| EncodeLZ4LoadDict | Initializes the LZ4 hash table that uses dictionary. |
| EncodeLZ4 | Performs LZ4 encoding. |
| EncodeLZ4Safe | Performs LZ4 encoding. |
| DecodeLZ4 | Performs LZ4 decoding. |
Please refer to this article for Building a faster LZ4 with Intel® IPP.
Benefits of using Intel® IPP LZ4 APIs
There are two major advantages of using Intel® IPP LZ4 APIs. First is the simplicity of using these APIs as it has no state and provides all necessary functions to perform data compression and decompression. Just minimal neccessary function subset with almost no service functions unlike open-source to make compression and decompression. Secondly, but mainly is the performance. Intel® IPP implementation of LZ4 provides significant performance speed up in comparison with open source implementation.
Supported Modes
Intel® IPP LZ4 has three major modes of compression. Standard mode allows to compress the data from source pointer to destination and provides access to hash table.
Fast mode which was introduced in Intel® IPP 2020 Update 3 Release allows to select acceleration factor. It changes default steps throw stream in the algorithm and allows to increase compression speed at the cost of decreasing compression ratio. If the user have predefined subset of literals for input stream it could be used in Dictionary mode of Intel® IPP LZ4 implementation. It extends API of basic compression function with additional arguments (pointer to data and size) for Dictionary. This mode allows to increase compression ratio and speed in case of efficient dictionary.
High compression mode shows significantly better compression ratio in comparison with standard mode, but the price of ratio increase is compression speed.
Finally, Standard and Dictionary modes have safe modification which guarantee correct behavior in case of “malicious" data. It will never read out of bounds source data and write more than what destination buffer provides.
Examples
Basic description on using Intel® IPP LZ4 APIs:
1. Prepare buffers for source and compressed data.
int srcSize = 1024;
int comprSize = 1024;
Ipp8u *pSrcData = ippsMalloc_8u(srcSize);
Ipp8u *pComprData = ippsMalloc_8u(comprSize);
2. Get the hash table size and allocate buffer. It is required due to Intel® IPP has no allocation into the functions and all the buffers should be allocated separately.
int hashTableSize;
status = ippsEncodeLZ4HashTableGetSize_8u(&hashTableSize);
Ipp8u * pHashTable = ippsMalloc_8u(hashTableSize);
3. Perform compression before function call comprSize which contains size of buffer, function updates during execution and the output it equal to real size of compressed data.
status = ippsEncodeLZ4_8u(pSrcData, srcSize, pComprData, &comprSize, pHashTable);
printf("Compression: %d bytes compressed into %d bytes\n", srcSize, comprSize);
4. Perform decompression, allocate buffer and call ippsDecodeLZ4_8u() and provide pointer to buffer and its size. At the end size will be updated with the real size of decompressed data.
int decomprSize = 1024;
Ipp8u *pDecomprData = ippsMalloc_8u(dstSize);
status = ippsDecodeLZ4_8u(pComprData, comprSize, pDecomprData, &decomprSize);
To enable fast mode of compression, call ippsEncodeLZ4Fast_8u() and provide additional value to set acceleration factor that can be [1;MAX_INT]. Default mode is the same as fast with acceleration factor equal to 1.
status = ippsEncodeLZ4Fast_8u(pSrcData, srcSize, pComprData, &comprSize, pHashTable, 11);
To use dictionary, you need to extend previous example with some code. Create buffer for dictionary and initialize it with some data. It could be part of source data or specially created subset for most frequent sequences (dictionary of HTML tags for example).
int dictionarySize = 256;
Ipp8u *pDictionary = ippsMalloc_8u(dictionarySize);
//TODO initialize pDictionary with some data
Update the compression API call. In addition to dictionary pointer and size, one more parameter srcIdx is added. It contains the size of previously collected history in hash table. For the first run, in case of empty hash table, it’s zero. If we initialized dictionary using ippsEncodeLZ4LoadDict_8u function right before compression, the srcIdx variable should be equal to dictionary size.
int fullCompressedSize = 0;
for (int i = 0; i < CHUNKCOUNT, status == ippStsNoErr; i++){
status = ippsEncodeLZ4Dict_8u(pSrcData + i * CHUNKSIZE, i * CHUNKSIZE, CHUNKSIZE, pComprData, &comprSize, pHashTable, pDictionary, dictionarySize);
fullCompressedSize += comprSize;
pComprData += comprSize;
}
It’s important not to change the HashTable between calls of compression functions for serial chunks. As, it contains information about the literals from the previous chunk.
For the compression in chunks to improve compression ratio, the previous chunks can be used as dictionary. In this case srcIndx i, the counts of bytes between the beginning of input data and the begging of current chunk. Also, pSrcData should be increased with chunk size.
int fullCompressedSize = 0;
pDictionary = pSrcData;
for (int i = 0; i < CHUNKCOUNT, status == ippStsNoErr; i++){
int offset = i * CHUNKSIZE;
status = ippsEncodeLZ4Dict_8u(pSrcData + offset, offset, CHUNKSIZE, pComprData, &comprSize, pHashTable, pDictionary, offset);
fullCompressedSize += comprSize;
pComprData += comprSize;
}
Now pSrcData always start exactly after the dictionary and for each chunk srcIdx is equal to offset between original pSrcData and beginning of the current chunk.
In case you need to make decompression with dictionary, just pass ippsDecodeLZ4Dict_8u function pointer to dictionary and its size.
status = ippsDecodeLZ4Dict_8u(pComprData, comprSize, pDecomprData, &decomprSize, pDictionary, dictionarySize);
Performance Results
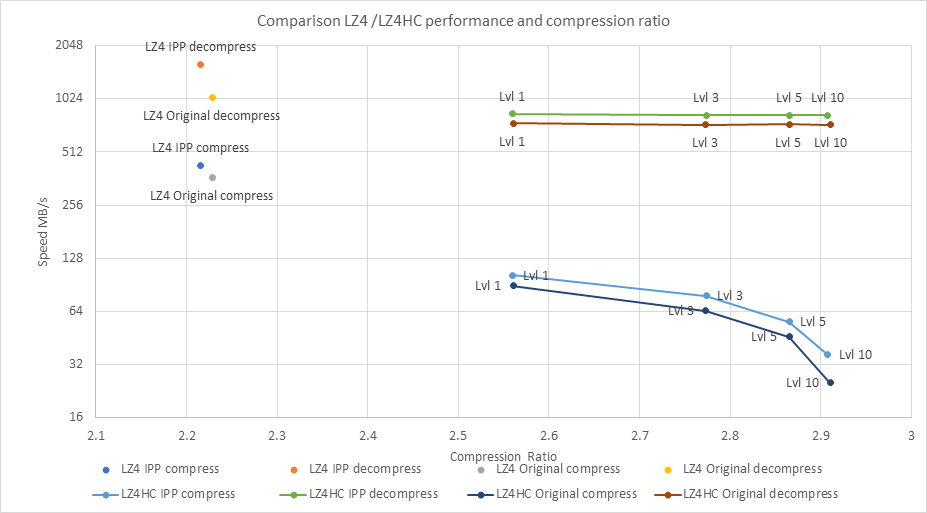
We calculated average compression speed and compression ratio for each case(point on graph) over all corpuses. In the graph, the Y axis is not linear.
Configuration: Testing by Intel as of 11/24/2020. Intel® Xeon® Platinum 8260M CPU @ 2.40GHz, 64 GB RAM, Intel HyperThreading Technology OFF. Software: Intel® C++ Compiler 18.0.0, GCC 4.8.2. Linux OS: Red Hat Enterprise Linux* 8.1, Kernel 3.10.0-693.11.6.el7.x86_64. Intel® Integrated Performance Primitives v.2020 Update 3. LZ4 version 1.7.5. Compiler flags: Intel C++ 18.0.0: '-O3 –fstack-protector -ffreestanding -xCORE-AVX512’. GCC 4.8.2 ‘-O2. Data corpuses: Calgary, Canterbury and Silesia
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.