Accelerating Large Language Model Inference on Intel® Data Center GPUs using BigDL-LLM
By Wesley Du, Yang Y Wang
In the rapidly evolving field of Generative AI (GenAI), various performance improvement techniques have been developed to accelerate large language models (LLMs) inference. For example, techniques like low-bit (e.g., INT4) optimizations and Speculative Decoding present effective options to accelerate LLM inference. We have implemented both low bit optimizations and Self-Speculative Decoding in BigDL-LLM to accelerate LLM inference on Intel GPUs.
In this article, we cover two topics about inferencing the state-of-art LLM models on Intel® Data Center GPUs using BigDL-LLM:
- Self-Speculative Decoding in BigDL-LLM
- Performance data on Intel® Data Center GPUs
Self-Speculative Decoding in BigDL-LLM
In Speculative Decoding, a small (draft) model quickly generates multiple draft tokens, which are then verified in parallel by the large (target) model. While speculative decoding can effectively speed up the target model, in practice it is difficult to maintain or even obtain a proper draft model, especially when the target model is finetuned with customized data.
Built on top of the concept of Self-Speculative Decoding, BigDL-LLM can now accelerate the original FP16 (or BF16) model without the need of a separate draft model or model finetuning; instead, it automatically converts the original model to INT4, and uses the INT4 model as the draft model behind the scenes.
In practice, users can make use of Self-Speculative Decoding in BigDL-LLM by only specifying one additional parameter speculative=True when loading the model. The example code snippets as below:
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_path,
optimize_model=True,
torch_dtype=torch.float16, #use bfloat16 on cpu
load_in_low_bit="fp16", #use bf16 on cpu
speculative=True, #set speculative to true
trust_remote_code=True,
use_cache=True)
output = model.generate(input_ids,
max_new_tokens=args.n_predict,
do_sample=False)
Under the hood, BigDL-LLM leverage the INT4 draft model to produce a sequence of output tokens (step A), and the generated tokens are then feed into the target FP16 model for one inference iteration (step B). By comparing the output sequence of the draft model and target model, the final output tokens are determined.
|
A. draft model generates draft tokens |
B. target model inference using draft tokens |
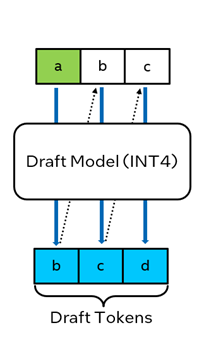
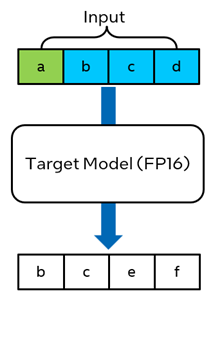
Figure 1. Self-Speculative Decoding in BigDL-LLM
In theory the FP16 inference using Self-Speculative Decoding is expected to produce same level of accuracy compared to FP16 inference without Self-Speculative Decoding. In practice, the Self-Speculative Decoding in BigDL-LLM brings about 35% to 40% improvements for FP16 LLM inference latency on Intel GPUs.
Performance data on Intel® Data Center GPUs
We have verified inference performance for various state-of-art large language models using BigDL-LLM on Intel GPUs, with both INT4 and FP16 (with Self-Speculative Decoding). The graphs below present the latency of the “next token” observed on these models, with 1K input token and batch size one.
The below graph shows the next token latency of inferencing the popular models from Hugging Face with INT4 on Intel Data Center GPUs including Flex 170, Max 1100 and Max 1550 (single tile).
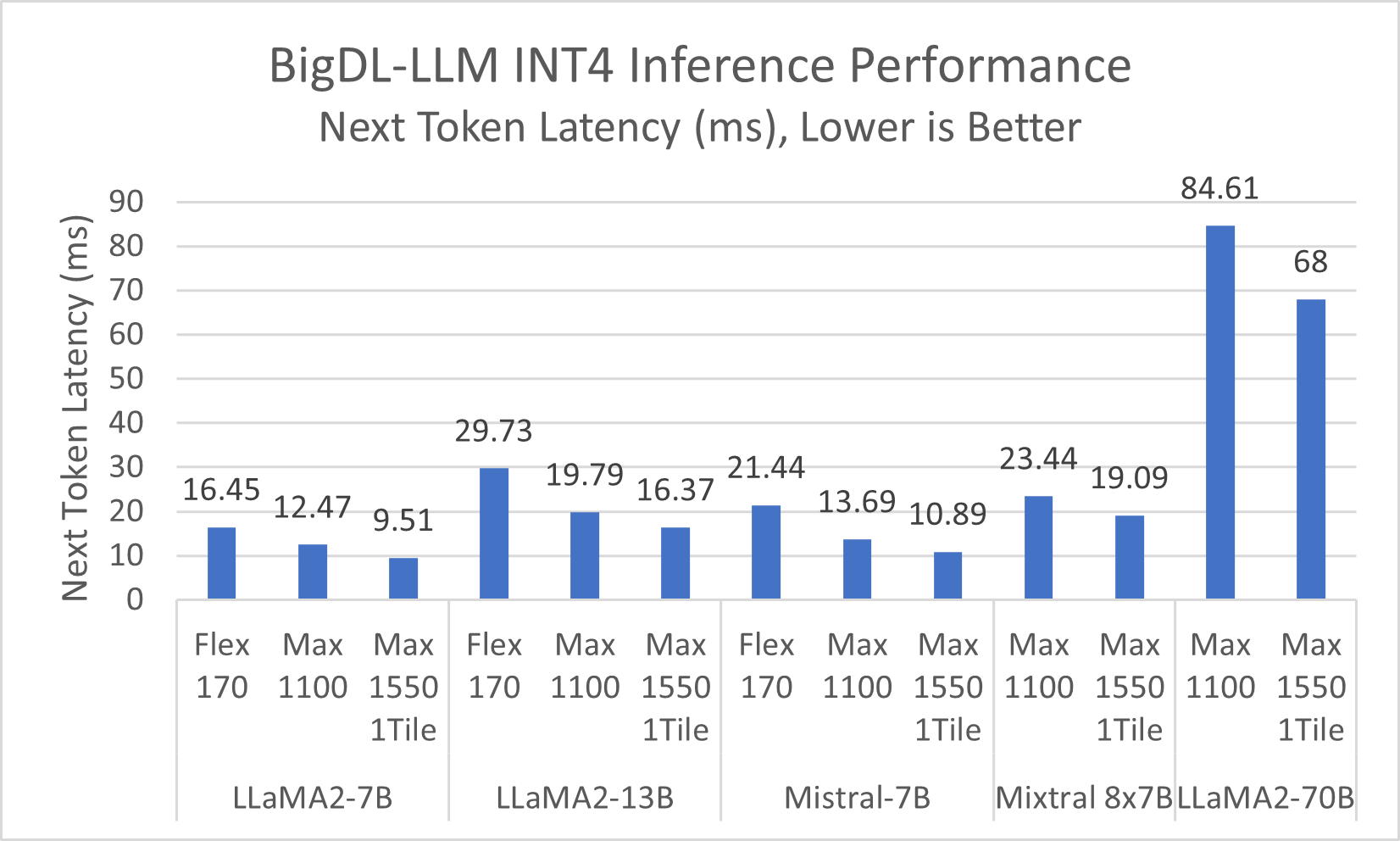
Figure 2. INT4 Inference Performance on Intel® Data Center GPUs
Refer to Configurations and Disclaimers for configurations.
With Self-Speculative Decoding, we observed significant latency improvement for FP16 inference (compared to without Self-Speculative Decoding). The graph below compares the inference latency for Llama2 7B/13B and Mistral 7B on Intel Data Center GPU Max 1550, under INT4 and FP16 using BigDL-LLM. In average, Self-Speculative Decoding brings about 35% improvements for FP16 on next token latency.
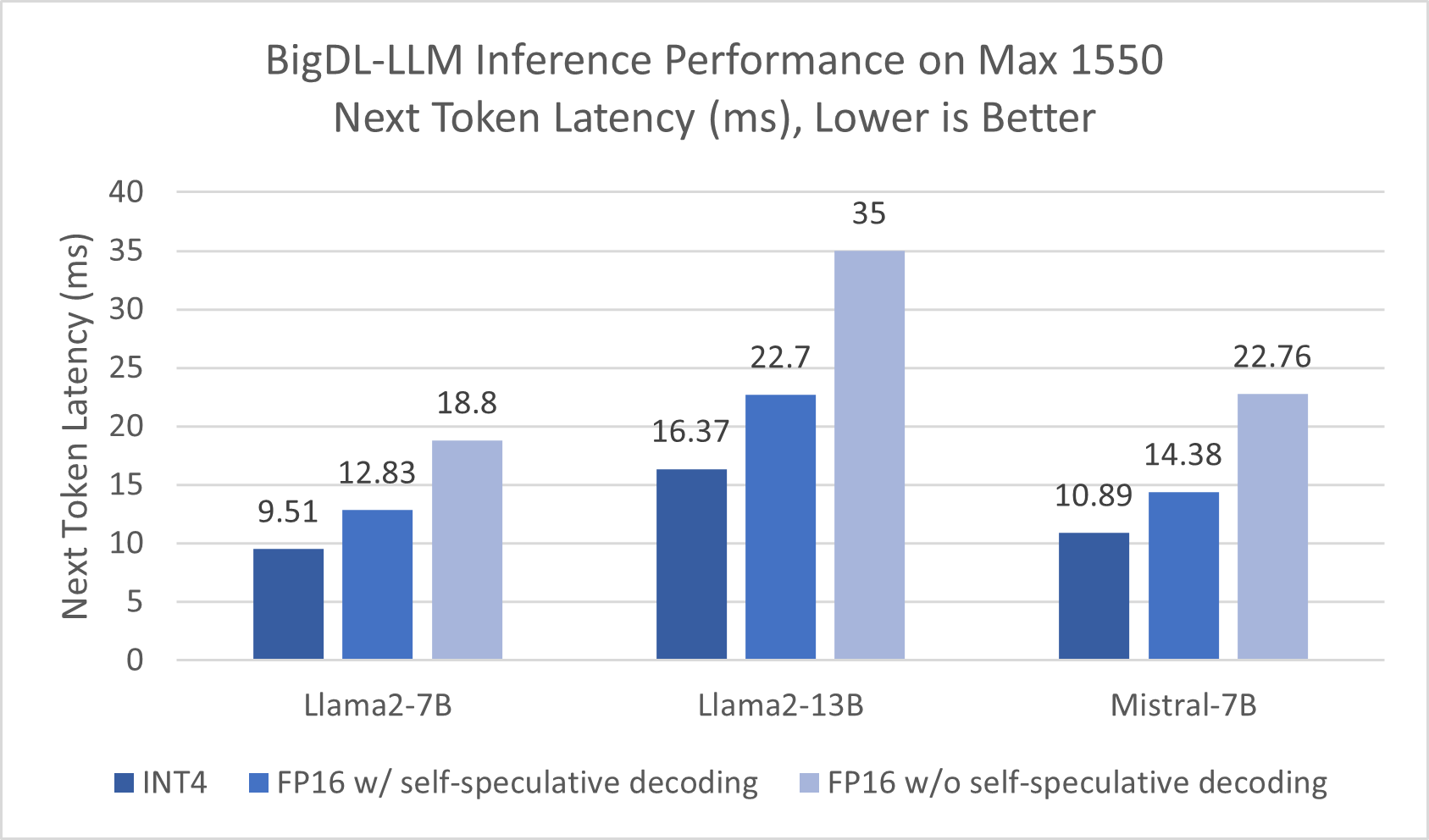
Figure 3. Inference Performance on Intel® Data Center GPU Max 1550 (single tile)
Refer to Configurations and Disclaimers for configurations.
The benefits from Self-Speculative Decoding were also observed on Intel Data Center GPU Max 1100. The graph below shows that over 40% latency improvements were achieved on Intel Data Center GPU Max 1100 compared to FP16 without Self-Speculative Decoding using BigDL-LLM.
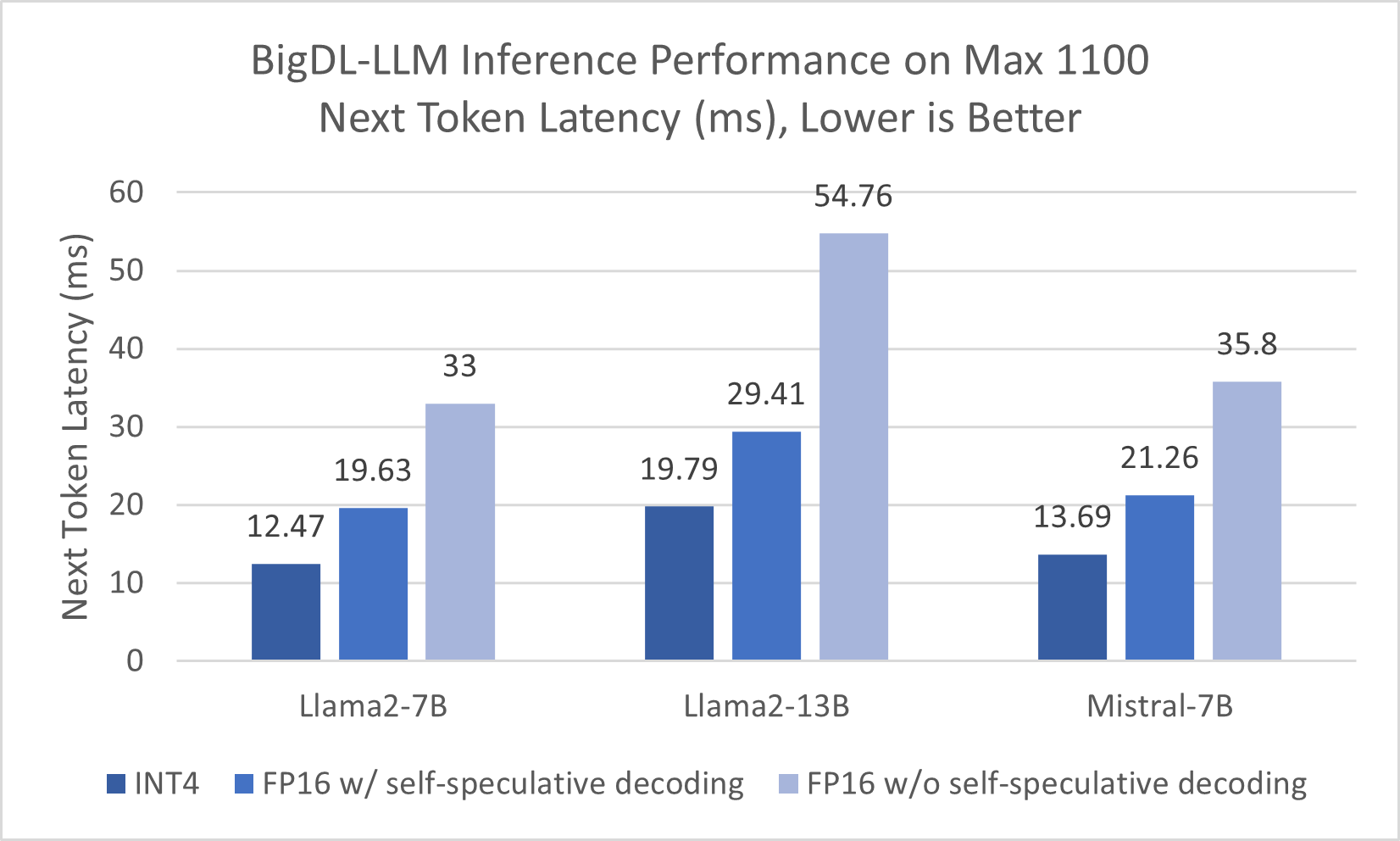
Figure 4. Inference Performance on Intel® Data Center GPU Max 1100
Refer to Configurations and Disclaimers for configurations.
Get Started
To get started on large language model using BigDL on Intel Data Center GPUs, please visit the project Github, and check out the LLM inference examples we developed for Self-Speculative Decoding for models such as Llama2, Mistral, ChatGLM3, Baichuan2, Qwen etc.
Summary
Our exploration in large language model inference using BigDL-LLM INT4 and FP16 with Self-Speculative Decoding on Intel® Data Center GPUs sheds light on efficient strategies to overcome the large computational and memory challenges inherent in Generative AI models. Through performance data analysis and the quick start examples, we've demonstrated the effectiveness of INT4 and FP16 (with Self-Speculative Decoding) in improving the inference latency for state-of-the-art LLMs on Intel Data Center GPUs.
Acknowledgement
We would like to thank Yina Chen, Ruonan Wang, Qiyuan Gong, Jian Wang, Heyang Sun, Dongjie Shi, Yabai Hu and Jason Dai for BigDL-LLM Self-Speculative Decoding development on Intel Data Center GPUs and article content contribution, and special thanks to Brian Golembiewski, Kristina Kermanshahche, Swetha Bhendigeri and David Kinder for their great support.
Configurations and Disclaimers
The benchmark uses next token latency to measure the inference performance. Batch size 1, greedy search, input tokens 1024, output tokens 128, data type INT4/FP16. The measurements used BigDL-LLM 2.5.0b20240111 for INT4 benchmark and 2.5.0b20240123 for FP16 benchmark, PyTorch 2.1.0a0+cxx11.abi, Intel® Extension for PyTorch* 2.1.10+xpu, Transformers 4.31.0 for llama2 and 4.36.0 for mistral, and Intel oneAPI Base Toolkit 2024.0. Ubuntu 22.04.2 LTS with kernel 5.15.0. Intel GPU Driver 775_20. Tests performed by Intel in January 2024.
Intel® Data Center GPU Flex 170 results were measured on a system with 2S Intel® Xeon® 8480+ and 256 GB DDR5-4800, Intel® Data Center GPU Max 1100 results were measured on a system with 2S Intel® Xeon® 8480+ and 512 GB DDR5-4800. Intel® Data Center GPU Max 1550 results were measured on a system with 2S Intel® Xeon® 8480+ and 1024 GB DDR5-4800.
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.