Contributors:
● RunwayML: Cristobal Valenzuela, Anastasis Germanidis, Brannon Dorsey
● Intel Corporation: Esther John, Rahul Unnikrishnan Nair, Geronimo Orozco, Daniela Plascencia, Cord Meados, Jose A Lamego, Gabriel Briones Sayeg, Ali R Khan
For the past few months, Runway has been collaborating with Intel to optimize and accelerate high-performance models using Intel’s Deep learning reference stack.
I. Intro to Runway’s Research
Runway is building a next-generation content creation tool using the latest advancements in generative machine learning, computer vision, and computer graphics research. Through its web and desktop applications, Runway provides an easy way for creators of all kinds to use a variety of machine learning models over the cloud through an intuitive drag-and-drop interface.
As Runway's user base has grown, it has faced the challenge of managing the costs of running a variety of computationally intense models on its cloud infrastructure. To tackle this challenge, Runway collaborated with Intel to explore a series of optimizations to one of its most popular use-cases, focusing on a person segmentation model. The model performs the task of removing the background from a collection of images or videos with people. Using Intel's Deep Learning Reference Stack, Runway applied a series of optimizations to the model, including model architecture changes and INT8 quantization. Runway was able to improve the performance of the model by more than 4x, significantly reducing the costs of inference serving on its platform.
For workloads and configurations visit www.Intel.com/PerformanceIndex. Results may vary.

Figure 1: Using the Person Segmentation model on Runway’s web platform
II. Intro to Intel’s Deep Learning Reference Stack
Throughout the collaboration, Intel and RunwayML have partnered on combining Intel’s Deep Learning Reference Stack and RunwayML’s deep learning applications to bring the power of artificial intelligence to creative projects with an intuitive and simple visual interface on Intel platforms.
RunwayML’s application containers run on Intel’s Deep Learning Reference Stack to solve developer use cases like this one. The Deep Learning Reference Stack (DLRS) features Code Sample: Intel® Deep Learning Boost New Deep Learning Instruction bfloat16 - Intrinsic Functions. Intel® DL Boost accelerates AI training and inference performance. The stack offers an enhanced user experience with support for the 3rd Gen Intel® Xeon® Scalable processor, the 10th Gen Intel® Core™ processor, the Intel® Iris® Plus graphics, and the Intel® Gaussian & Neural Accelerator (Intel® GNA).
The Deep Learning Reference Stack supports AI workloads, allowing developers to focus on software and workload differentiation. As a platform for building and deploying portable, scalable, machine learning (ML) workflows, Kubeflow* Pipelines easily support deployment of DLRS images. This enables orchestration of machine learning pipelines, simplifying ML Ops, and enabling the management of numerous deep learning use cases and applications. DLRS v7.0 also incorporates Transformers [3], a state-of-the-art general-purpose library that includes a number of pretrained models for Natural Language Understanding (NLU) and Natural Language Generation (NLG). The library helps to seamlessly move from pre-trained or fine-tuned models to productization. DLRS v7.0 incorporates Natural Language Processing (NLP) libraries to demonstrate that pretrained language models can be used to achieve state-of-the-art results [4] with ease. The included NLP libraries can be used for natural language processing, machine translation, and building embedded layers for transfer learning. The PyTorch-based DLRS extends support for Flair [5], which includes the ability of Transformers, to apply natural language processing (NLP) models to text, such as named entity recognition (NER), part-of-speech tagging (PoS), sense disambiguation, and classification.
In addition, Intel defined the application layer interface to enable RunwayML to run application containers on Intel platform optimized containers. The oneContainer API is a platform to enable unified RESTful interfaces for containerized solutions, providing developers and Independent Software Vendor (ISVs) an extensible template across multiple segments such as AI, Media, HPC, Data Services and others. Developers and ISVs can leverage the oneContainer API to enable self-documenting APIs for varied backends by expanding and implementing templates provided with the project. The backends can be deployed as docker services and are orchestration solution agnostic. Each segment has independent service queues and workers to cater to requests from API calls.
We encourage developers to contribute to the solution and extend as needed for specific use cases. In addition, visit Intel’s oneContainer Portal to learn more, to download the Deep Learning Reference Stack and the oneContainer API code, and contribute feedback.
III. Results and what to expect
The first step to optimizing the Person Segmentation Model for Intel hardware was migrating the application containers to enable the model to use the Deep Learning Reference Stack optimized container with PyTorch. The DLRS container offers a variety of optimizations for Intel Architecture, including using Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN), a highly optimized math library. Using the Deep Learning Reference Stack led to a 1.25x improvement in inference time for the model compared to non-optimized PyTorch*.
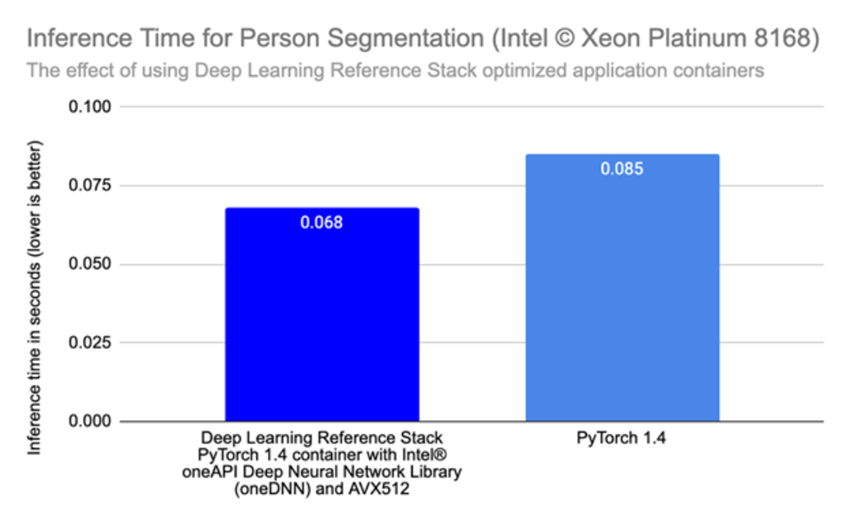
Figure 2: Inference Time for Person Segmentation, DLRS vs. Non-optimized PyTorch. Specifications: Intel(R) Xeon(R) Platinum 8168 CPU (2.70GHz, 16 cores), Memory 65.86 GB, Ubuntu 18.04.4 LTS, Kernel 5.4.0-1031-azure, Deep Learning Framework: Deep Learning Reference Stack with PyTorch, Compiler: gcc v.9.3.1, BS=8, Datatype: FP32.
Next, Intel and Runway discovered inefficiencies in the Person Segmentation’s model architecture. Runway’s Person Segmentation model is using the U-Net model architecture, a standard convolutional network for image segmentation. In Runway’s model, bilinear up sampling operations were used in the decoder blocks of the model instead of the transposed convolutions of the original model. Runway identified that using transposed convolutions led to a 1.7x performance gain in terms of inference time on the Deep Learning Reference Stack. Finally, converting the model weights from the FP32 precision to INT8 precision led to an additional 2.2x improvement in inference, leading to an overall speedup of 4.72x after all optimizations were in place.
See backup for workloads and configurations. Results may vary.
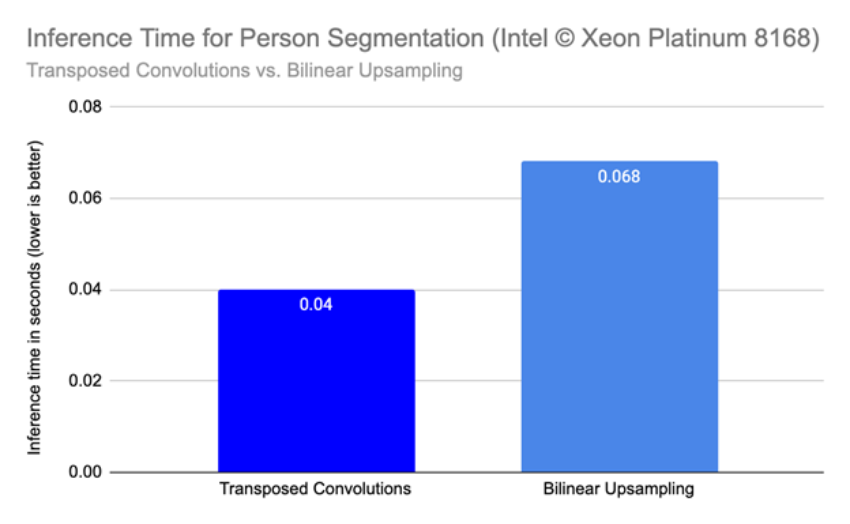
Figure 3: Inference Time for Person Segmentation, Transposed Convolutions vs. Bilinear up sampling. Specifications: Intel(R) Xeon(R) Platinum 8168 CPU (2.70GHz, 16 cores), Memory 65.86 GB, Ubuntu 18.04.4 LTS, Kernel 5.4.0-1031-azure, Deep Learning Framework: Deep Learning Reference Stack with PyTorch, Compiler: gcc v.9.3.1, BS=8, Datatype: FP32.
See backup for workloads and configurations. Results may vary.
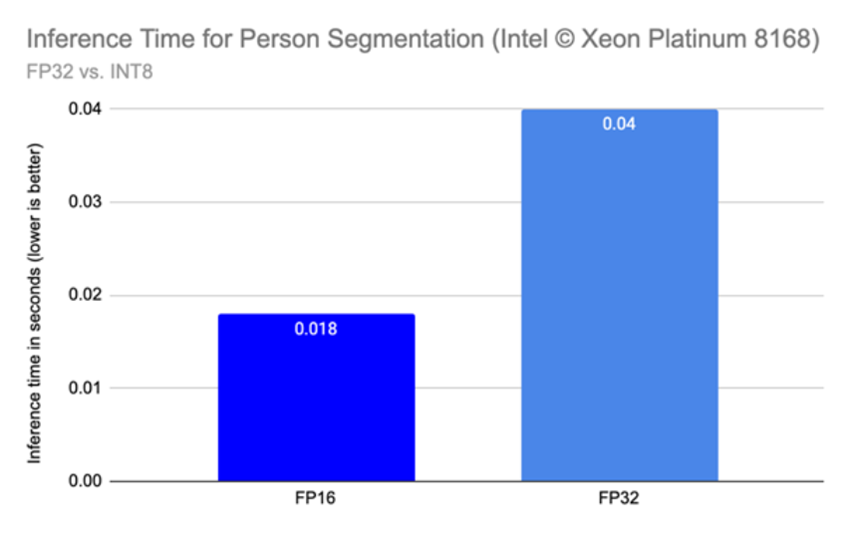
Figure 4: Inference Time for Person Segmentation, FP32 vs. INT8. Specifications: Intel(R) Xeon(R) Platinum 8168 CPU (2.70GHz, 16 cores), Memory 65.86 GB, Ubuntu 18.04.4 LTS, Kernel 5.4.0-1031-azure, Deep Learning Framework: Deep Learning Reference Stack with PyTorch, Compiler: gcc v.9.3.1, BS=8, Datatype: FP32 and INT8.
IV. Impact on Product
The improvements in inference time have two primary implications on Runway’s product. The first is a significant reduction in the infrastructure costs of running the inference server for the Person Segmentation model. A higher throughput-per-dollar allows Runway’s cloud infrastructure to serve more inference requests with the same number of application containers. The second product-level benefit is a smoother and more interactive user experience for users of the model in Runway’s platform. Improvements in the performance of Runway’s models directly translate to a tighter feedback loop when using the tool, which is critical for faster experimentation and expressivity.
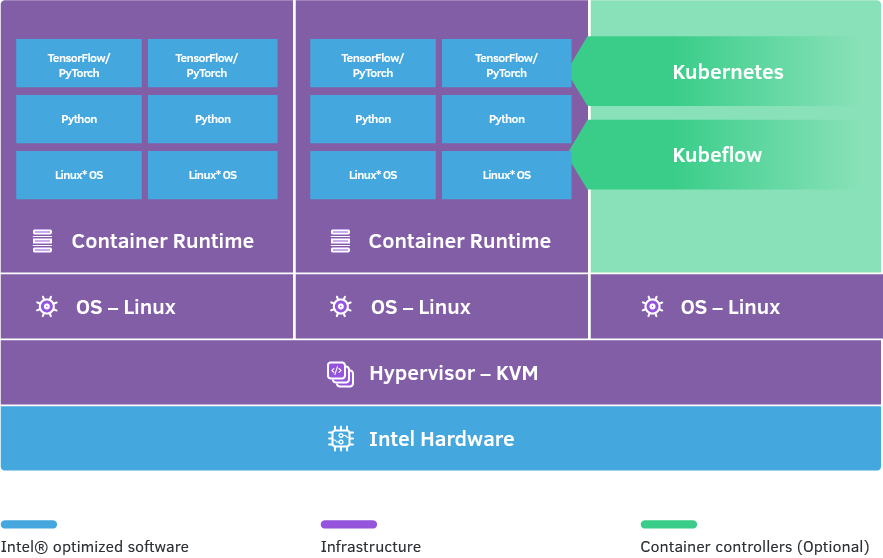
Figure 5: Architectural diagram of Intel’s Deep Learning Reference Stack
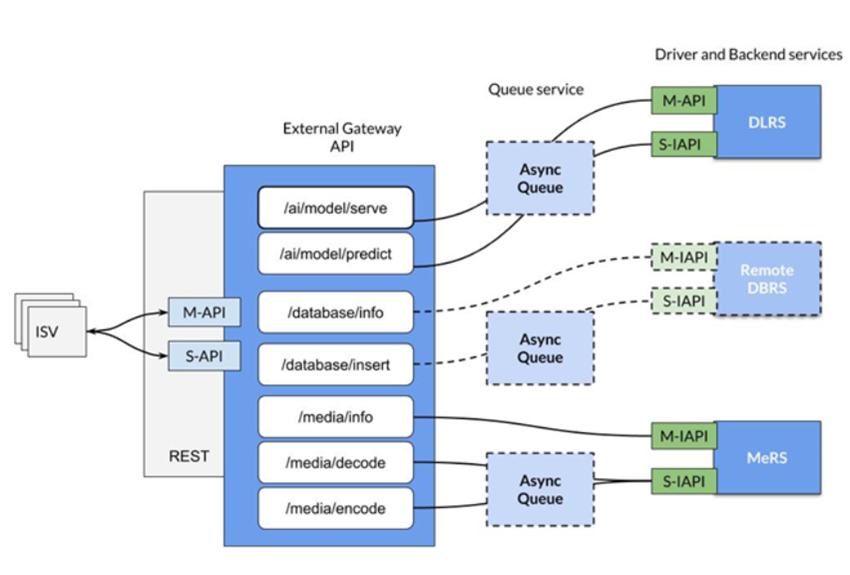
Figure 6: Architectural Diagram of Intel’s oneContainer API, an extensible solution for ISVs. DLRS: Intel’s Deep Learning Reference Stack; DBRS: Intel’s Database Reference Stack; MeRS: Intel’s Media Reference Stack; M-API: Management API; S-API: Service API; REST: Representational State Transfer; ISVs: Independent Software Vendors.
The developer or Independent Software Vendor (ISV) interacts with the external gateway REST API to deploy and consume the backend services. Each of the verticals/segments such as Deep Learning, Data Services, Media, HPC or others contain independent service queues and workers that periodically schedule the queued jobs. As shown in Figure 6, a worker interacts with the backend service using a driver client; any functionality exposed by the backend will have a corresponding client interface. APIs are separated logically as Management APIs (M-API) and Service APIs (S-API). M-APIs are used to deploy/start a service, while S-APIs are used to consume the deployed service.
Sign up for Runway [9] to try out the Person Segmentation model, or any other of more than 100 machine learning models for image, video, and text synthesis available on the platform.
V. Resources
[1] Intel® Distribution of OpenVINO™ Toolkit Release Notes
[2] Jump-start AI Development
[3] Using Transformers* for Natural Language Processing
[4] NLP ImageNet
[5] flairNLP
[6] fn
[7] openfaas
[8] Deep Learning Reference Stack v7.0 Now Available
[9] Runway
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, Xeon, Iris and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.