
However, most of the current hardware accelerators only provide support for C/C++ APIs, which is not conducive for Rust applications to directly call. Developers who use Rust to write applications must exert extra efforts to leverage different IA accelerators in their applications for better performance. Teams or BUs who own the hardware accelerators usually work with software engineers to develop related software components in firmware, kernel, or other languages--but mostly, they are written in C/C++. There is limited support for them to enable those IA accelerators for cloud native applications written in Rust. Though we have Intel oneAPI[1], it has the similar issue that there is no high-level language support, and currently it may just support GPU-related offloading work. Therefore, there are several roadblocks to adopt Intel’s IA accelerators, especially for cloud native applications written in other languages (e.g., Golang or Rust).
There are several solutions that are often adopted to leverage accelerators by some high-level languages (e.g., JAVA, Golang, or Rust):
• Client-server solution relied on (G)PRC framework: the applications written in high-level programming languages (such as JAVA, Golang, or Rust) can use RPC to invoke the offloading device integrated in the RPC server side. In this way, applications do not to directly integrate accelerated devices but communicate with the service. Though we can still use the accelerators, we need additional communication channels based on the network type (e.g., http/TCP/RDMA/Unix domain socket). If data is also exchanged by the RPC channel, it may lose the acceleration effect though the RPC servers with accelerators because of the communication overhead brought by RPC.
• C-->GO or Rust--> C approaches: high-level programming languages can directly use the functions written in C, and it is easier to use C libraries to invoke those hardware accelerators. Additional effort is required to enable hardware-based accelerators. Currently in Rust, we only see some wrapper libraries to leverage iouring in C language, i.e., tokio-uring[2].
• Some advanced languages, such as Python, developed separate libraries that can access hardware resources, such as MMIO (memory mapped io) and perform DMA directly, e.g. pynq.lib.dma[3]. For solutions like pynq.lib.dma, the module relies on the device driver’s implementation mode; the device driver should expose all interfaces via the MMIO interface. It introduces potential device driver rework efforts. In this mode, it’s difficult to control the access privileges from the user space applications. Thus, it could introduce potential security vulnerabilities. It means the applications still need to deal with different device drivers.
Therefore, we propose and design a Rust-based wrapper library to provide various hardware acceleration functions. Projects written in Rust can be called directly; this makes it convenient to use with various hardware accelerators and hardware acceleration functions that produce safer and faster code that uses less CPU. This article illustrates the design and implementation of the wrapper library to leverage the IA accelerators (e.g., QAT/DSA) for RUST. To demonstrate that our idea is practical, we also illustrate an example on how to implement our ideas in containerd related areas.
Design
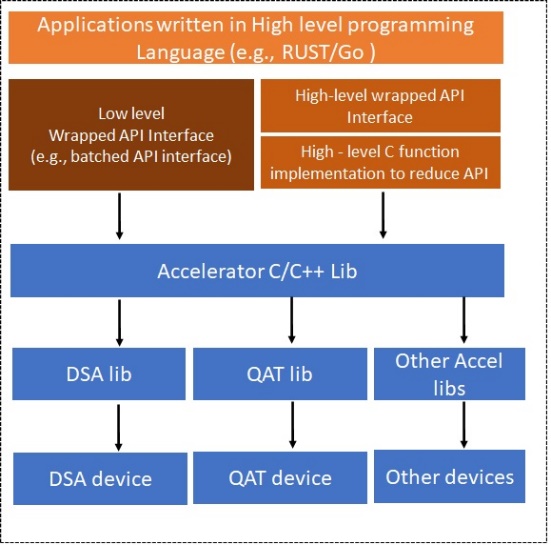
Figure 1 illustrates how to leverage existing C/C++ libraries to drive hardware offloading devices in high level programming language. We provide two methods to leverage existing C/C++ libraries:
- Low-level wrapped API interface (for performance purposes):, this means that applications can use the low-level accelerator library with our wrapped API. This wrapped API can still use the threading mode or framework provided by high-level programming languages. For example, in the scenario to integrate Intel QAT [4] in RUST, Intel QAT provides a low-level data plane library with batched API, but without using any thread mode. We can wrap the API and still use the threading and scheduling model provided in RUST.
- High-level wrapped API interface (forease of use and reducing complexity): this means that we generate some C implementations and shrink the API interfaces given by accelerators’ libraries. We will wrap our C implementations with reduced APIs. This usage can make the applications written in high level programming languages easier to leverage.
Implementation
This section describes an example to implement our proposal in Nydus[5] written in Rust[6].
First, a brief technical background. Containers are an element in cloud-native infrastructures, which have the advantages of flexible development, efficient operation, and the ability to run anywhere. A container is a standard unit of software that packages up code and all its dependencies, so the application runs quickly and reliably from one computing environment to another. However, there are also some problems in container operation: for example, 1) slow startup of containers: Newly deployed containers spend 76% of startup time pulling images; 2). high local storage costs: on average, only 6.4% of the data is used; The data between layers has redundant content during transmission and storage.
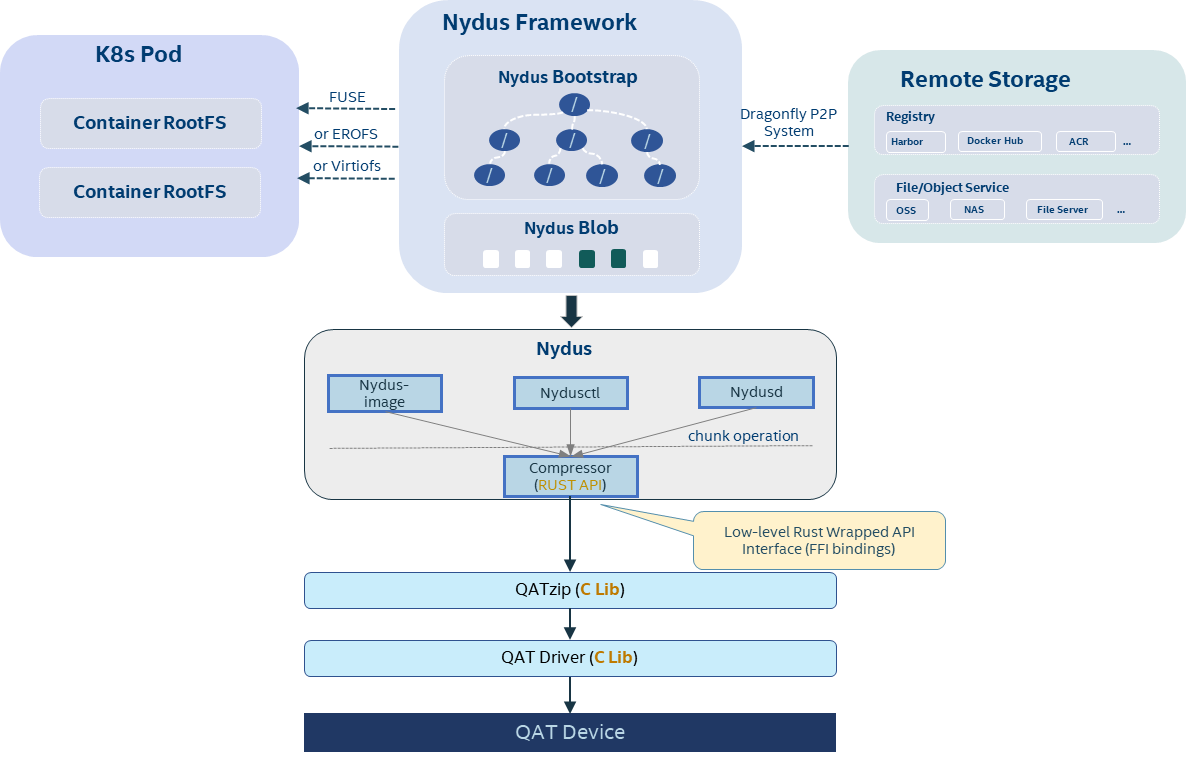
Nydus, a Dragonfly sub-project, is a powerful opensource filesystem solution to form a high-efficiency image distribution system for Cloud Native workloads. By leveraging Nydus, container images are downloaded on demand; users can configure the chunk size to achieve the chunk level data duplication. Firstly, Nydus supports pulling container image data from a container image registry. Then, Nydus takes in either FUSE or virtiofs protocol to service pods created by conventional Runc containers or VM-based Kata Containers. In short, the Nydus image acceleration service optimizes the OCI container image architecture and presents it as an image acceleration implementation of the container image format of the file system. And its runtime is written in Rust.
However, underlying hardware accelerators such as Intel QAT and Intel® Data Streaming Accelerator (Intel® DSA) are mainly based on C/C++. Nydus cannot directly invoke those accelerators’ libraries due to different language.
In our project, Nydus can directly call the RUST-based wrapper library to call Intel QAT to achieve hardware acceleration. Figure 2 shows the workflow on how to implement our wrapped API to Nydus.
There are many advantages. This acceleration library can be used directly as a plug-in for easy calling. And from the perspective of performance improvement, we only need to optimize the wrapper library to achieve the optimal hardware acceleration solution.
Configuration
After our wrapper library has been integrated into Nydus’s compressor, the basic steps of how to leverage the Intel QAT accelerator in Nydus are as follows:
- Make sure the platform has integrated with the Intel QAT acceleration devices, and Intel QAT drivers has been installed[7].
- Compile[6] the Nydus that integrates our wrapped library to leverage Intel QAT. Copy those binaries nydusify, nydus-image, nydusd, nydusctl, nydus-overlayfs, and ctr-remote into the dictionary /usr/local/bin.
- Download the Nydus Snapshotter[8], and copy the binary containerd-nydus-grpc into the dictionary /usr/local/bin.
- Install Containerd[9] and Nerdctl[10].
- Configure containerd to use the nydus-snapshotter plugin.
- Change the configuration of containerd in /etc/containerd/config.toml:
[proxy_plugins]
[proxy_plugins.nydus]
type = "snapshot"
address = "/run/containerd-nydus/containerd-nydus-grpc.sock"
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "nydus"
disable_snapshot_annotations = false
- Restart containerd service
- Systemd starts the Nydus Snapshotter service.
- Prepare a nydusd configuration in /etc/nydus/nydusd-config.fusedev.json. Here is an example[11]:
{
"device": {
"backend": {
"type": "registry",
"config": {
"skip_verify": false,
"timeout": 5,
"connect_timeout": 5,
"retry_limit": 4
}
},
"cache": {
"type": "blobcache",
"config": {
"work_dir": "cache"
}
}
},
"mode": "direct",
"digest_validate": false,
"iostats_files": false,
"enable_xattr": true,
"fs_prefetch": {
"enable": true,
"threads_count": 4
}
}
- Create the systemd configuration file for the nydus snapshotter file /etc/systemd/system/nydus-snapshotter.service with the following content::
[Unit]
Description=nydus snapshotter
After=network.target
Before=containerd.service
[Service]
Type=simple
Environment=HOME=/root
ExecStart=/usr/local/bin/containerd-nydus-grpc --config /etc/nydus/config.toml
Restart=always
RestartSec=1
KillMode=process
OOMScoreAdjust=-999
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target
- Create the configuration file /etc/nydus/config.toml with the following content:
version = 1
root = "/var/lib/containerd-nydus"
address = "/run/containerd-nydus/containerd-nydus-grpc.sock"
daemon_mode = "multiple"
cleanup_on_close = false
[system]
enable = true
address = "/var/run/containerd-nydus/system.sock"
[system.debug]
daemon_cpu_profile_duration_secs = 5
pprof_address = ""
[daemon]
nydusd_path = "/usr/local/bin/nydusd"
nydusimage_path = "/usr/local/bin/nydus-image"
fs_driver = "fusedev"
log_level = "info"
recover_policy = "restart"
nydusd_config = "/etc/nydus/nydusd-config.fusedev.json"
threads_number = 4
[log]
log_to_stdout = false
level = "info"
log_rotation_compress = true
log_rotation_local_time = true
log_rotation_max_age = 7
log_rotation_max_backups = 5
log_rotation_max_size = 1
[metrics]
address = ":9110"
[remote]
convert_vpc_registry = false
[remote.mirrors_config]
dir = "/etc/nydus/certs.d"
[remote.auth]
enable_kubeconfig_keychain = false
kubeconfig_path = ""
enable_cri_keychain = false
image_service_address = ""
[snapshot]
enable_nydus_overlayfs = false
sync_remove = false
[cache_manager]
disable = false
gc_period = "24h"
cache_dir = ""
[image]
public_key_file = ""
validate_signature = false
[experimental]
enable_stargz = false
- Systemd starts the nydus snapshotter service
- Start a Local Registry Container with the following command:
sudo docker run -d --restart=always -p 5000:5000 registry
- Convert an image to Nydus format
sudo nydusify convert --source nginx --target localhost:5000/nginx-nydus
- Run Nydus with nerdctl
sudo nerdctl –snapshotter=nydus run --rm -it localhost:5000/nginx-nydus:latest bash
You should get the following result:

Conclusion
With our wrapped library, customers can get the performance benefits for their cloud native applications written in high level programming languages (e.g., by Golang/Rust) on Intel platforms. Especially for cloud service providers, they can efficiently utilize the IA accelerators with Intel’s platforms in different software components in the stack.
With our approach, Intel platforms easily support IA-based accelerators to run cloud native applications that are written in high-level programming languages.
In summary, we proposed and designed a Rust-based wrapper library to provide various hardware acceleration functions. Projects written based in Rust can be called directly, and this makes it convenient to use with various hardware accelerators and hardware acceleration functions that produce safer and faster code that uses less CPU.
Reference:
[1] https://www.intel.com/content/www/us/en/developer/tools/oneapi/overview.html\
[2] https://github.com/tokio-rs/tokio-uring
[3] https://pynq.readthedocs.io/en/v2.3/pynq_package/pynq.lib/pynq.lib.dma.html#pynq-lib-dma
[6] https://github.com/dragonflyoss/image-service
[8] https://github.com/containerd/nydus-snapshotter
[9] https://github.com/containerd/containerd
[10] https://github.com/containerd/nerdctl
[11] https://github.com/dragonflyoss/image-service/blob/master/docs/containerd-env-setup.md