Intel is engaged with over 700 open source groups and standards bodies, giving us a unique view on the evolution of open source initiatives. Arun Gupta, Intel vice president and general manager of Open Ecosystem, delved into this history in a panel discussion with Java* experts from several open source language initiatives, including Intel principal engineer Sandhya Viswanathan and software architect Steve Dohrmann.
Together, they discussed how languages have evolved to simplify the developer's job, the pressures that emerging technologies like AI and machine learning have put on these languages, and the additional impact of new hardware capabilities.
Watch [19:00]
Since time was short, we decided to spend some additional time with our Java* experts to provide more depth and texture to their panel discussion contributions, specifically:
- The history and future direction of Java
- The language's contribution to heterogeneous compute
- Its use of the oneAPI Programming Model framework as a path to the future
Here is that conversation, formatted for brevity.
Java* and the TornadoVM Project
Don/Rob: Arun asked how languages, in this case Java, are growing to handle heterogeneous computing and mixed hardware device availability (for example, CPUs, GPUs, and FPGAs). You mentioned the TornadoVM project. Can you say a bit more about that? Maybe give a code snippet and where to get it?
Sandhya/Steve: In a nutshell, TornadoVM is an open source add-in to Java virtual machines that allows programmers to automatically run Java programs on heterogeneous hardware. The project was started by the University of Manchester. There are two required elements needed to run Java code with TornadoVM:
- A special Java "task" method describes a computation to be run on a targeted device. TornadoVM supports two styles in which developers can write task methods.
- One uses @Parallel annotations on loops to indicate loops that have independent iterations that can be run in parallel by TornadoVM.
- An alternate style uses the TornadoVM kernel API and may be more familiar to users with previous GPU programming experience. An example of a @Parallel annotated task method is shown in figure 1.
- A TornadoVM TaskGraph object specifies task methods to run and arguments to pass to the methods. The task graph can also contain commands to move data between the host and a device. This allows input data to be transferred to the device and the resulting data to be fully transferred back to the host. The code for an example TaskGraph is shown figure 1. It’s a matrix multiplication task method with @Parallel loop annotations.
public static void matrixMult(float[] a, float[] b, float[] c, int size) {
for (@Parallel int i = 0; i < size; i++) {
for (@Parallel int j = 0; j < size; j++) {
float sum = 0.0f;
for (int k = 0; k < size; k++) {
sum += a[(i * size) + k] * b[(k * size) + j];
}
c[(i * size) + j] = sum;
}
}
}
Figure 1. Matrix multiplication task method
Except for the annotations and the fact that TornadoVM only supports a subset of Java features inside these task methods, this code is idiomatic Java.
The code in figure 2 shows an example TaskGraph instance for running the task method in figure 1.
public class MMTest {
public static void main(String[] args) {
// … a, b, and c are size x size float[] matrices
TaskGraph taskGraph = new TaskGraph("g0")
.transferToDevice(DataTransferMode.FIRST_EXECUTION, a, b)
.task("t0", MMTest::matrixMult, a, b, c, size)
.transferToHost(c)
taskGraph.execute();
}
}
Figure 2. Example TaskGraph for matrix multiplication task method
The TaskGraph::execute() call in the last line will start running the task method and block until the graph’s work is completed. The device that runs the code can be specified either on the TornadoVM command line or in the source code.
A more complete overview of TornadoVM, including use of a Kernel API-style task method, is available here: TornadoVM and its use of oneAPI Level Zero. Note that a few TornadoVM class and method names have changed since that article was published. Other than that, the article is still accurate.
Khronos Group* SPIR-V and oneAPI Level Zero
Don/Rob: Earlier, you mentioned that for GPU offload, Java methods get translated to the Khronos Group* Standard, Portable, Intermediate Representation -V (SPIR-V), taking advantage of oneAPI Level Zero to deploy onto the specific platform. Can you sketch for us, how this translation works?
Sandhya/Steve: TornadoVM plugs into a JVM via Java's compiler interface [JVMCI]. This lets the add-in customize compilation to Java bytecode, analyze the user's task methods and, if targeting a GPU, translate selected method bytecode to the SPIR-V abstract assembly language.
SPIR-V is a standard intermediate language that is very good at representing parallel computations such as those we want to run on GPUs. To go along with the SPIR-V code, TornadoVM uses the TaskGraph object to drive calls to the oneAPI Level Zero library. These calls submit the SPIR-V code for running and specify the target device, task arguments, and data movement operations. The library then sends the work to the graphics runtime for compilation and running. A diagram depicting this flow is shown in figure 3.
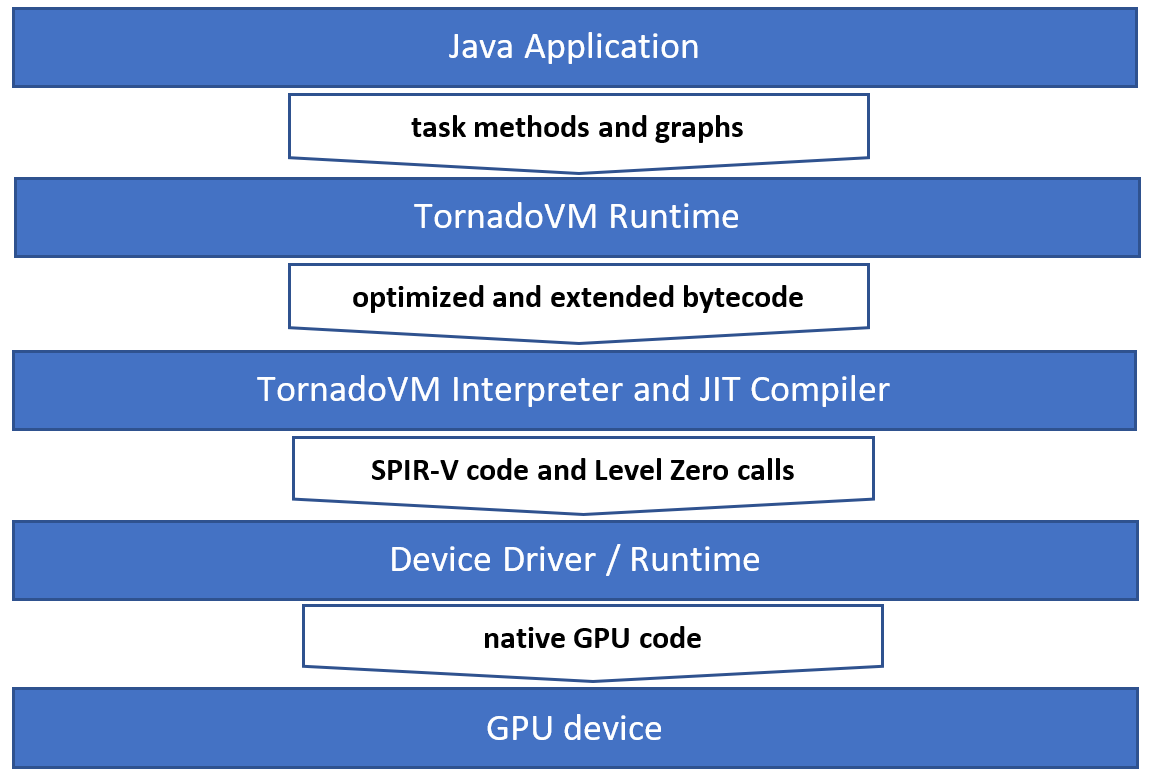
Figure 3. Java application access to GPU devices
Alternative Frameworks to oneAPI Level Zero
Don/Rob: So, TornadoVM uses SPIR-V and oneAPI Level Zero to target GPUs. Are there other frameworks they could have used? Can you give an example?
Sandhya/Steve: There are others. For example, the OpenCL™ framework is a well-known C language framework for heterogeneous programming. In fact, TornadoVM implements an OpenCL framework back end in addition to the SPIR-V back end. This backend also works with Intel GPUs. When compared to the OpenCL framework, Level Zero offers additional control and functionality such as support for virtual functions, function pointers, unified shared memory, device partitioning, instrumentation, debugging, and hardware diagnostics. It also offers control of things like power management and operating frequency. Direct generation of the low-level SPIR-V code gives more control over the code to be run, and using the Level Zero API gives more control over its running on the target device.
Native Code Interconnect for OpenJDK*
Don/Rob: During the panel discussion you mentioned briefly how emerging technologies that require an interconnect between JVM and native code roll into Project Panama for OpenJDK*. Could you elaborate a bit on the nature of Project Panama and how it maps to/connects with accelerated computing?
Sandhya/Steve: The Panama project has two subprojects. The first, the Vector API, lets Java developers write SIMD code directly in Java. While most compilers will attempt to autovectorize portions of an application, the analysis the compiler must do is complex, and it must know that the vectorized code it would generate exactly preserves the non-vectorized program behavior. This leads to cases where the compiler must conservatively fail to vectorize. The Panama Vector API gives developers the ability to use application knowledge to explicitly vectorize computations and memory operations, accelerating more of their code with SIMD hardware.
The second is the Java foreign package [java.lang.foreign, preview in JDK 19] which provides low-level access to functions and memory outside of the Java runtime. This lets developers call external C libraries, such as TensorFlow*, directly from Java without writing a C-code binding library. This means they can program in a single language and potentially simplify their project because they no longer need to distribute an OS-specific native binding library.
The foreign package has extensive memory-handling features in support of making foreign function calls and for programming with external memory in general. These memory features form a base for direct Java access to memory technologies such as Unified Shared Memory [USM, a memory standard developed by the Khronos Group*]. USM can simplify heterogeneous programming because it automatically transfers pages of memory between the host and a compatible device, such as a GPU, as the memory is accessed; explicit copy operations aren't required. Intel's implementation of oneAPI supports the USM standard.
Next Steps
Don/Rob: Thank you for your valuable insights. This was most enlightening. Our curiosity has been peaked. I hope all of our readers are ready to check out how they can take advantage of oneAPI to use Java for heterogeneous computing.