Intel® Extension for OpenXLA*
OpenXLA is an open-source Machine Learning compiler ecosystem co-developed by AI/ML industry leaders that lets developers compile and optimize models from all popular ML frameworks on a wide variety of hardware. We are pleased to announce Intel® Extension for OpenXLA*, which seamlessly runs AI/ML models on Intel GPUs. Intel® Extension for OpenXLA* is a high-performance deep learning extension implementing the OpenXLA PJRT C API (see RFC for details), allowing multiple AI frameworks to compile StableHLO, an operation set for high-level operations for numeric computation, as well as dispatching the executable to Intel GPUs.

Figure 1: Intel® Data Center GPU Max Series 1100 PCIe Card
The PJRT plugin for Intel GPU is based on LLVM + SPIR-V IR code-gen technique. It integrates with optimizations in oneAPI-powered libraries, such as Intel® oneAPI Deep Neural Network Library (oneDNN) and Intel® oneAPI Math Kernel Library (oneMKL). With optimizations on linear algebra, operator fusion, layout propagation, etc., developers can speed up their workloads without any device-specific codes. JAX is the first supported front-end. Intel® Extension for OpenXLA* enables and accelerates training and inference of different scales workloads on Intel GPUs, including Large Language Models (LLMs) or multi-modal models, etc., such as Stable Diffusion.
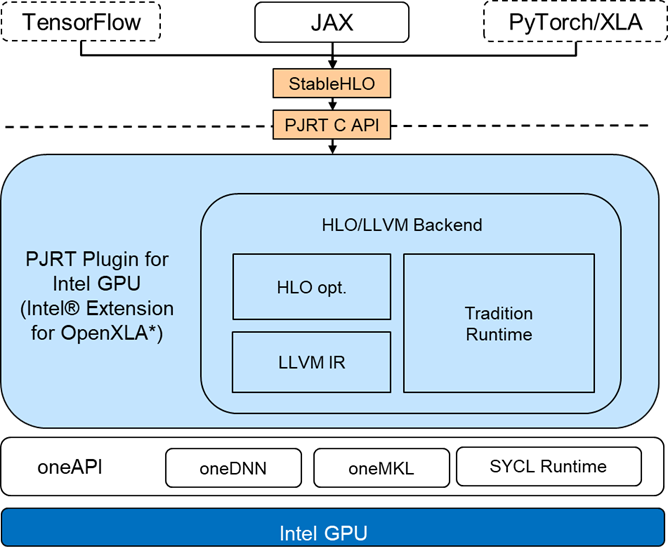
Figure 2: Intel® Extension for OpenXLA* Architecture
Enabling Intel® Extension for OpenXLA*
In this section, we show how to enable JAX applications on Intel GPUs with Intel® Extension for OpenXLA*.
Installation
- Preinstallation Requirements
-
Install Ubuntu* 22.04 OS
-
Install Intel GPU driver
Intel® Data Center GPU Max Series 682.14 driver
-
Install Intel® oneAPI Base Toolkit
Install oneAPI Base Toolkit Packages 2023.2
-
Setup environment variables
source /opt/intel/oneapi/setvars.sh # Modify based on your oneAPI installation directory
- Install bazel
wget https://github.com/bazelbuild/bazel/releases/download/5.3.0/bazel-5.3.0-installer-linux-x86_64.sh
bash bazel-5.3.0-installer-linux-x86_64.sh --user
bazel –-version # Verify bazel version is 5.3.0
- Create a Python* Virtual Environment (using Miniconda)
-
Install Miniconda*
-
Create and activate virtual running environment
conda create -n jax python=3.9
conda activate jax
pip install --upgrade pip
- Build and install JAX and Intel® Extension for OpenXLA*
- Option 1: Build from source (recommend)
git clone https://github.com/intel/intel-extension-for-openxla.git
cd intel-extension-for-openxla
pip install jax==0.4.13 jaxlib==0.4.13
./configure
bazel build //xla/tools/pip_package:build_pip_package
./bazel-bin/xla/tools/pip_package/build_pip_package ./
pip install intel_extension_for_openxla*.whl
- Option 2: Install via PyPI wheel
pip install jax==0.4.13 jaxlib==0.4.13
pip install --upgrade intel-extension-for-openxla
Check That PJRT Intel GPU Plugin Is Loaded
Use a Python call to jax.local_devices() to check all available XPU devices:
python -c "import jax;print(jax.local_devices())"
Sample output: on Intel® Data Center GPU Max 1550 GPU (with 2 stacks):
[xpu(id=0), xpu(id=1)]
In this case of a server with single Intel® Data Center GPU Max 1550 GPU installed, there are two XPU devices, representing 2 stacks loaded into the current process.
Note: If there is no XPU devices detected, the output would be as below:
RuntimeError: Unable to initialize backend 'xpu'.
...
(you may need to uninstall the failing plugin package, or set JAX_PLATFORMS=cpu to skip this backend.)
In this case, make sure both the environment variable for oneAPI has been set as described in the above "Installation" section.
Running Stable Diffusion in JAX on Intel GPUs
Install Required Packages
pip install flax==0.7.0 transformers==4.27.4 diffusers==0.16.1 datasets==2.12.0 msgpack==1.0.7
sudo apt install numactl
Run Stable Diffusion Inference
Image generation with Stable Diffusion is used for a wide range of use cases, including content creation, product design, gaming, architecture, etc. We provide the code file jax_sd.py below that you can copy and execute directly. The script is based on the official guide Stable Diffusion in JAX / Flax. It generates images based on a text prompt, such as Wildlife photography of a cute bunny in the wood, particles, soft-focus, DSLR. For benchmarking purpose, we do warmup for one-time costs for model creation and JIT compilation. Then we execute actual inference with 10 iterations and print out the average latency, for 1 image with 512 x 512 pixels generated, in a step count of 20 for each iteration. The hyper-parameters are listed in Table 1: the maximum sequence length for the prompt is set as default 77 with 768 embedding dimensions each, the guidance scale is 7.5, and the scheduler is Multistep DPM-Solver (Fast Solver for Guided Sampling of Diffusion Probabilistic Models, multistep-dpm-solver API in Diffusers).
Table 1: Text-to-images Generation Configurations in Stable Diffusion
| Model | CompVis/stable-diffusion-v1-4 |
| Image Resolution | 512x512 |
| Batch Size | 1 |
| Inference Iterations | 10 |
| Steps Count in Each Iteration | 20 |
| Maximum Sequence Length for Prompt | 77 |
| Text Embedding Dimensions | 768 |
| Guidance_scale | 7.5 |
| Scheduler | DPMSolverMultistepScheduler |
The generated image img.png is saved in the current directory on the last run.
Script: jax_sd.py
import jax
import sys
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline, FlaxDPMSolverMultistepScheduler
import time
from PIL import Image
# Change this prompt to describe the image you’d like to generate
prompt = "Wildlife photography of a cute bunny in the wood, particles, soft-focus, DSLR"
scheduler, scheduler_state = FlaxDPMSolverMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, revision="bf16", dtype=jax.numpy.bfloat16)
params["scheduler"] = scheduler_state
prng_seed = jax.random.PRNGKey(0)
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = pipeline.prepare_inputs(prompt)
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
def elapsed_time(nb_pass=10, num_inference_steps=20):
# warmup
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
start = time.time()
for _ in range(nb_pass):
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
end = time.time()
return (end - start) / nb_pass, images
latency, images = elapsed_time(nb_pass=10, num_inference_steps=20)
print("Latency per image is: {:.3f}s".format(latency), file=sys.stderr)
images = images.reshape((images.shape[0],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
images[0].save("img.png")
Execute the Benchmark on Intel GPUs
Set up the environment variable for affinity mask to utilize 1 stack of the GPU (only for 2-stacks GPU, such as Max 1550 GPU) and use numactl to bind the process with GPU affinity NUMA node.
export ZE_AFFINITY_MASK=0.0
numactl -N 0 -m 0 python jax_sd.py
Performance Data
Based on the above steps, we measured and collected the Stable Diffusion performance data as demonstrated in Table 2 on 2 SKUs of Intel® Data Center GPU Max Series, Max 1550 GPU (600W OAM) and Max 1100 GPU (300W PCIe), respectively. Check out the Intel® Data Center GPU Max Series Product Brief for details. On both GPUs, we could generate attractive images in less than 1 second with 20 steps! Figure 3 shows the images generated on Intel® Data Center GPU Max Series.
These benchmarks could be re-run with the above procedures or referring to Stable Diffusion example to reproduce the results.
Table 2: Stable Diffusion Inference Performance on Intel® Data Center GPU Max Series
| Model | Precision | Batch Size | Diffusion Steps | Latency (s) on 1 stack of Max 1550 GPU (600W OAM) | Latency (s) on Single Max 1100 GPU (300W PCIe) |
| CompVis/stable-diffusion-v1-4 | BF16 | 1 | 20 | 0.79 | 0.92 |
| 50 | 1.84 | 2.15 |

Figure 3: AI-Generated Content via Intel® Data Center GPU Max Series
Summary and Future Work
Intel® Extension for OpenXLA* leverages the PJRT interface, which simplifies ML hardware and framework integration with a unified API. It enables the Intel GPU backend for diverse AI frameworks (JAX is available, while TensorFlow and PyTorch via PyTorch-XLA are on the way). With the optimization in Intel® Extension for OpenXLA*, JAX Stable Diffusion with BF16 archives 0.79 seconds per image latency on Intel® Data Center GPU Max 1550 and 0.92 seconds per image latency on Intel® Data Center GPU Max 1100.
As a next step, Intel will continue working with Google to adopt the NextPluggableDevice API (see RFC for details) to implement non-XLA ops on Intel GPUs to support all TensorFlow models. When available, TensorFlow support for Intel® Extension for OpenXLA* on Intel GPUs will be in the Intel® Extension for TensorFlow* GitHub* repository.
Resources
Intel® Extension for OpenXLA* GitHub* repository
More Examples Running on Intel GPUs with Intel® Extension for OpenXLA*
Stable Diffusion in JAX / Flax
Accelerate JAX models on Intel GPUs via PJRT
OpenXLA Support on GPU via PJRT
Acknowledgement
We would like to thank Yiqiang Li, Zhoulong Jiang, Guizi Li, Yang Sheng, River Liu from the Intel® Extension for TensorFlow* development team, Ying Hu, Kai Wang, Jianyu Zhang, Huiyan Cao, Feng Ding, Zhaoqiong Zheng, Xigui Wang, etc. from AI support team, and Zhen Han from Linux Engineering & AI enabling team for their contributions to Intel® Extension for OpenXLA*. We also offer special thanks to Sophie Chen, Eric Lin, and Jian Hui Li for their technical discussions and insights, and to collaborators from Google for their professional support and guidance. Finally, we would like to extend our gratitude to Wei Li and Fan Zhao for their great support.
Benchmarking Hardware and Software Configuration
Measured on June 21, 2023
- Hardware configuration for Intel® Data Center GPU Max 1550: 128 Xe®-Cores in total 2 stacks, 64 Xe®-cores in 1 stack are used, ECC ON, Intel® ArcherCity server platform, 1-socket 52-cores Intel® Xeon® Platinum 8469 CPU@2.00GHz, 1 x 64 GB DDR5 4800 memory, 1 x 931.5G SanDisk SDSSDA-1700 disk, operating system: Ubuntu* 22.04.2 LTS, 5.15.0-64-generic kernel, using Intel® Xe® Matrix Extensions (Intel® XMX) BF16 with Intel® oneAPI Deep Neural Network Library (oneDNN) v3.2 optimized kernels integrated into Intel® Extension for OpenXLA v0.1.0, JAX v0.4.7 and jaxlib v0.4.7, flax v0.6.6, diffusers v0.16.1, Intel® 627.7 GPU driver, and Intel® oneAPI Base Toolkit 2023.1. Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
- Hardware configuration for Intel® Data Center GPU Max 1100: 56 Xe®-Cores in total 1 stack, ECC ON, Supermicro® SYS-420GP-TNR server platform, 2-sockets 32-cores Intel® Xeon® Platinum 8352Y CPU@2.20GHz, 4 x 64 GB DDR4 3200 memory, 1 x 894.3G Samsung® MZ1LB960HAJQ-00007 disk, operating system: SUSE* Linux Enterprise Server 15 SP4, 5.14.21-150400.24.46-default kernel, using Intel® Xe® Matrix Extensions (Intel® XMX) BF16 with Intel® oneAPI Deep Neural Network Library (oneDNN) v3.2 optimized kernels integrated into Intel® Extension for OpenXLA v0.1.0, JAX v0.4.7 and jaxlib v0.4.7, flax v0.6.6, diffusers v0.16.1, Intel® 627.7 GPU driver, and Intel® oneAPI Base Toolkit 2023.1.