Co-authored with: Jinhu Wu, Alibaba Corporation
Introduction
We are fast approaching a data-driven world, with the sensors in internet of things (IoT) devices, mobile devices, and cameras generating a multitude of data. International Data Corporation (IDC) reported that the global datasphere will grow to 163 zettabytes (ZB) by 2025, which is 10 times the 16 ZB data generated in 2016. The variety and velocity of data growth complicate this trend, continually changing the way data is collected, stored, processed and analyzed. New analytics solutions from machine learning, deep learning, artificial intelligence (AI), new architectures, and new tools are being developed to extract and deliver value from this huge datasphere. IDC predicted that the amount of analyzed data will grow by a factor of 100 to 1.4 ZB1 by 2025.
Widely used in big data analytics, Apache Hadoop*2 is a highly scalable system that allows distributed processing of large sets of data across computer clusters, scaling from a single server to thousands of nodes. Hadoop offers local computation and storage, storing data in the native Hadoop Distributed File Systems (HDFS) on hard drives that are locally attached to the Hadoop nodes. This architecture binds compute and storage to a physical node and thus is hard to scale independently.
Computation and storage requirements often grow at different rates; more often, storage is growing at an unprecedented rate without a similar growth in computation needs. This creates a discontinuity in big data infrastructure. Traditional approaches including building a single large cluster or multiple small clusters cannot resolve this problem as they lack isolation and elasticity, and costs increase significantly due to duplicated storage.
IDC indicates spending on cloud-based big data analytics technology will grow 4.5 times faster than expenditures for on-premises solutions3. Cloud-based big data services offer agility, flexibility, and simplicity as the number one priority consideration for big data investments. A survey from Forrester* commissioned by Oracle* and Intel concludes that “Companies that move more into the cloud for big data analytics achieve greater innovation, increased integration, and higher levels of security”4.
Alibaba Cloud* Object Storage Service (OSS) is a cloud object storage service provided by Alibaba, also known as Aliyun. It is an easy-to-use service that enables you to store, back up, and archive large amounts of data on the cloud. OSS acts as an encrypted central repository from where files can be securely accessed from around the globe. OSS guarantees up to 99.95% availability and is a perfect fit for global teams and international project management5. Starting with Hadoop 3.0, OSS is officially supported by the Hadoop community upstream through the close collaboration between Intel and Alibaba. Users can connect seamlessly to the OSS file system while using Hadoop, and offline, interactive, data warehousing, deep learning, and other applications in Hadoop can read and write OSS object storage without any code changes. This significantly simplifies big data processing on OSS and provides easy, fast, scalable, and cost-effective analytics solutions for end users.
This paper presents big data analytics on cloud architecture, introducing Hadoop on OSS disaggregated storage solution tunings, optimization, and results. We will first introduce challenges and motivations, followed by the Hadoop Compatible File System (HCFS) architecture, and Alibaba OSS. Then we will detail the optimizations of OSS object file upload and download actions which significantly increase performance. We will present some performance and cost comparison results obtained by Alibaba for sorting workloads on Hadoop with HDFS and OSS to demonstrate how OSS can reduce the total cost of ownership (TCO) for big data analytics workloads on Intel® platforms.
Alibaba’s tests show that when Intel® Xeon® processors and NVMe* technologies are used6, running big data analytics workloads on OSS delivers a 9% higher performance with a 12.8 times cost reduction.
Motivations
Discontinuity in Big Data Infrastructure
The storage and compute resources in Hadoop are bound together, as the data in HDFS is stored on hard drives that are locally attached to the Hadoop nodes. This architecture makes it hard to scale compute and storage separately. Several traditional approaches try to resolve this issue:
- Build a large cluster: When an organization purchases more storage for their on-premise Hadoop cluster, they might purchase more computing power than they necessarily need. This waste can be dramatic in capital expenditures, especially when data volume in today’s public cloud service provider might already be reaching the petabyte level.
- Building multiple small clusters: This does not resolve the problem as it lacks isolation; multiple teams competing for the same resources will likely result in missing service level agreement (SLA) deadlines. Costs do not scale and can have significant increases due to duplicated storage.
Big Data Analytics on the Cloud
It can be expensive to move data into or pull data from the public cloud. In response, many organizations tend to run big data analytics workloads directly on the cloud, where they build a shared “data lake” pouring raw, unfiltered, unprocessed data into a storage pool that can be shared by multiple applications and used in different scenarios. Meanwhile, big data analytics on the cloud offers all the same benefits associated with other public cloud services, including agility, flexibility, ability to access data from everywhere, easy provisioning and management, and cost benefits. Thus, big data on the cloud is becoming increasingly popular.
Apache Hadoop* with Disaggregated OSS Storage
Hadoop Compatible File System
Though Apache Hadoop is built on HDFS, it also works with other file systems, such as platform-specific local file systems, object stores such as Amazon* Simple Storage Service (Amazon S3) and Azure* Storage, as well as alternative distributed file systems. Hadoop Compatible File System (HCFS)5 provides the ability to run big data analytics on other storage systems. Since Hadoop 3.0, OSS is officially supported by the Hadoop community upstream through the close collaboration between Intel and Alibaba*, along with Amazon* S3, Microsoft Azure*, Data Lake, and Google* Cloud Platform. This makes OSS another good choice for Hadoop users, especially for users in China.
Alibaba Cloud* Object Storage Service (OSS) for Hadoop
Alibaba Cloud Object Storage Service (OSS) features massive capacity, security, low cost, and high reliability. OSS provides storage services through a RESTFUL web service interface. In practice, users can upload and download data on any application anytime and anywhere by calling APIs or perform simple management of data through the Web Management Console. OSS can store any type of files, with no maximum total storage limitation (individual objects can be as large as 48.8 TB). Therefore, it applies to various scenarios, including big data analytics workloads, machine learning, enterprise applications, and more. Figure 1 shows the OSS ecosystem, which is widely used in Alibaba Cloud.
Figure 1. OSS ecosystem
Hadoop OSS File System Optimization
By following the official Hadoop guide for the hadoop-aliyun module, you can implement a new Hadoop OSS File System class which supports access to OSS in Hadoop through the org.apache.hadoop.fs.FileSystem interface. We implemented this class, then conducted a quick performance evaluation on Alibaba Cloud. We identified several performance bottlenecks, including object file upload, object file read, and renaming a directory which has thousands of files under it. Alibaba and Intel engineers collaborated and worked out several optimization proposals. With these optimizations, Hadoop on OSS performance is remarkably improved. Figure 2 shows the optimizations for the Hadoop OSS file system. Detailed Hadoop Jira* are listed as follow:
- HADOOP-15027: Support multi-thread pre-read to improve sequential read performance from OSS
- HADOOP-15262: Move files under a directory in parallel when a directory is renamed
- HADOOP-14999: Upload files in parallel and asynchronously
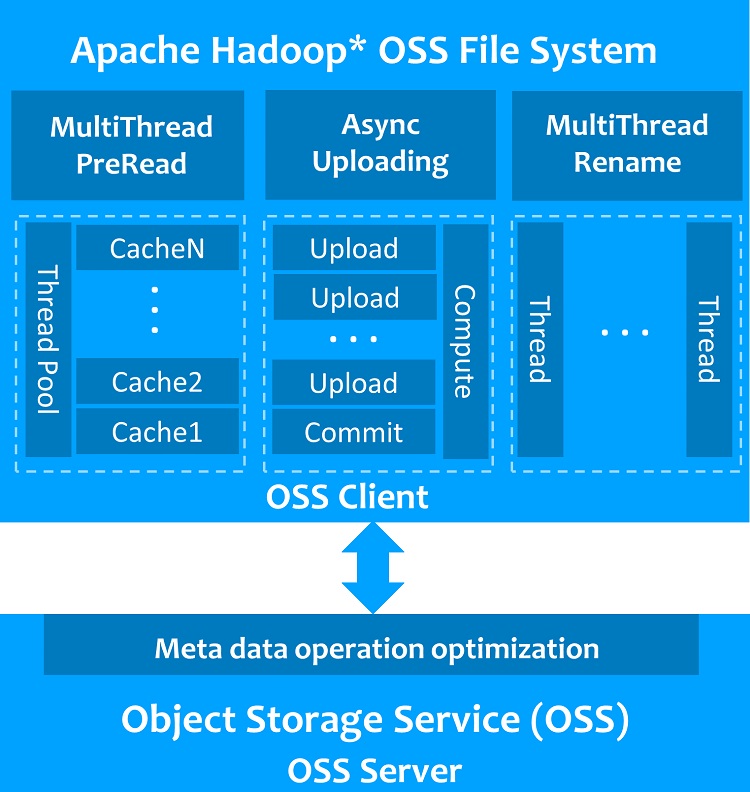
Figure 2. Hadoop OSS file system optimization
Hadoop on OSS Performance on Intel Platforms
When planning a big data analytics workload on the cloud, people always want to know how to choose between HDFS and object storage for persistent data storage. Generally, the opinion is Hadoop on HDFS will have better performance since HDFS has better throughput and lower latency compared with OSS, while Hadoop on OSS will be much more economical from a cost point of view. After completing the major Hadoop OSS performance optimizations mentioned above, we conducted a TPC-DS* (Apache Hive* testbench) test with selected 64 queries on both HDFS (Alibaba Ultra Cloud Disk) and OSS on Intel platforms to see if the general opinion still stands. Figures 3-5 show detailed performance and cost comparison results.
The Alibaba OSS system is built on Intel platforms, using servers equipped with 2x Intel® Xeon® Platinum 8168 processors, 2x 75 0GB Intel® Optane™ SSD DC P4800X SSDs, 256 GB Memory, and two 25 Gb Ethernet. Performance tests conducted by Alibaba on this platform showed Hadoop on OSS delivers 9% better performance (Figure 3) than on Ultra cloud disk-based remote HDFS after optimizations in the Hadoop OSS file system plugin (OSS client) and on the OSS server side while reducing the TeraSort cost by 12.8 times (Figure 4).
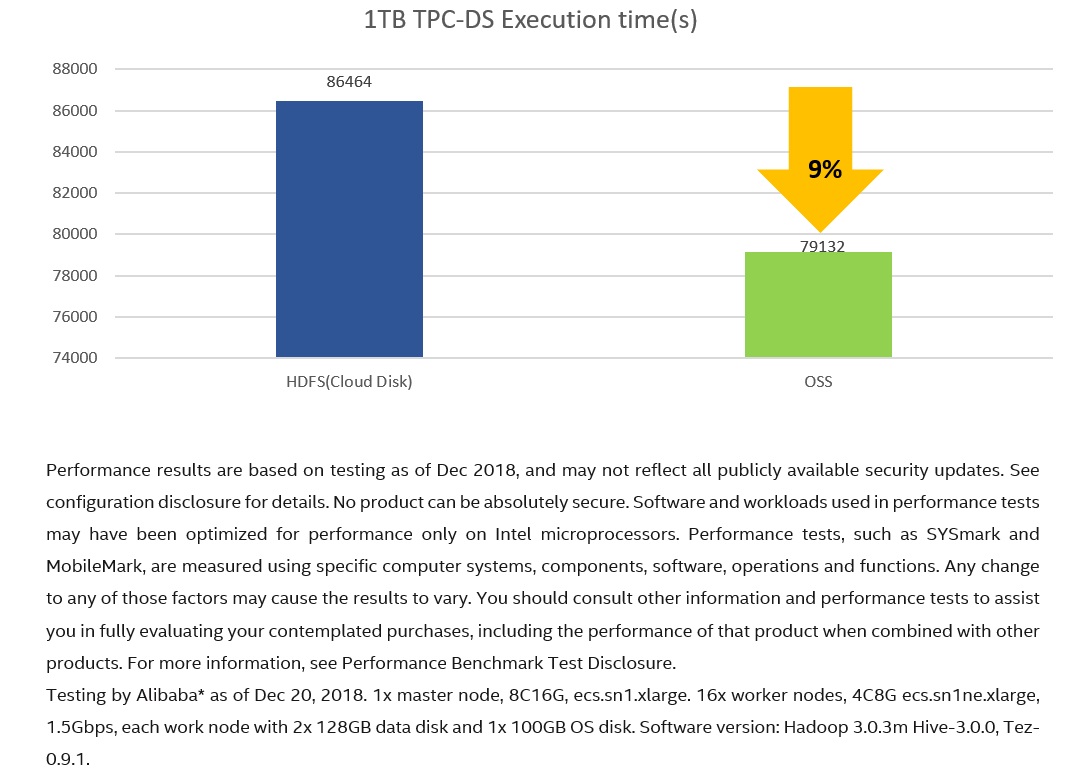
Figure 3. TPC-DS overall performance
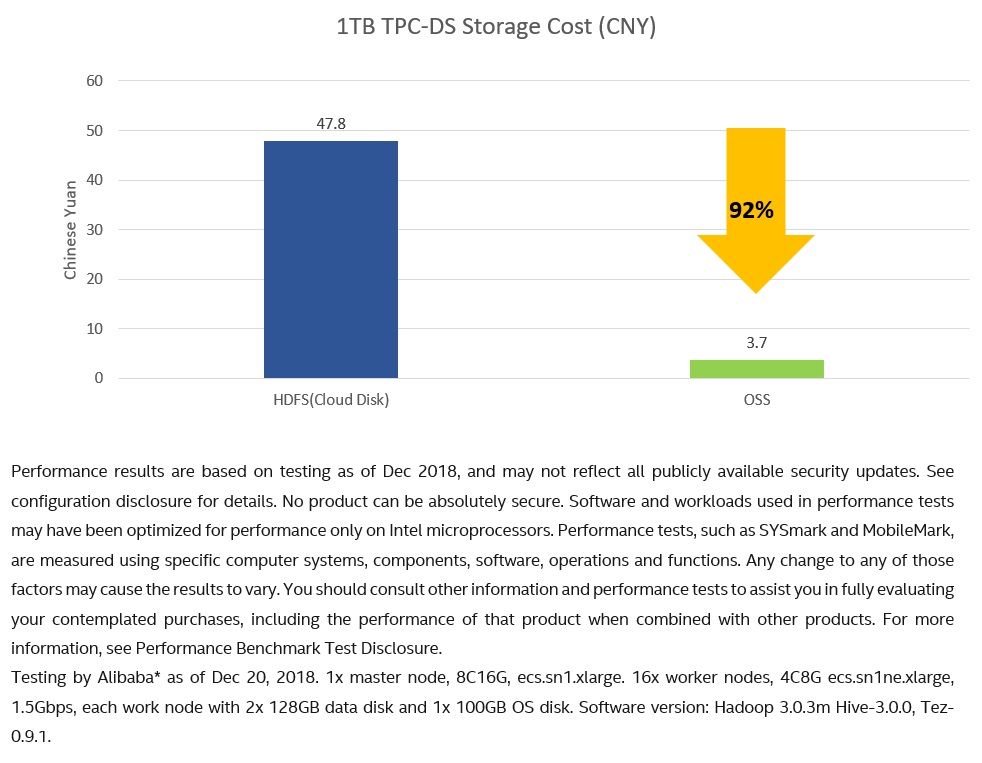
Figure 4. TPC-DS storage cost
Here’s how the cost shown in Figure 4 was calculated:
OSS cost = 0.12 * 1024 * 78615 / 3600 / 24 / 30 = 3.727 Chinese Yuan
HDFS cost (High efficiency cloud disk) = 0.35 * (1024 * 3 / (1 - 0.25)) * 86464 / 3600 / 24 / 30 = 47.822 Chinese Yuan,
- OSS standard price 0.12 Chinese Yuan per GB per month.
- High-efficiency cloud disk price is 0. 35 Chinese Yuan per GB per month.
- HDFS space is calculated based on using three replicas and reserving 25% space.
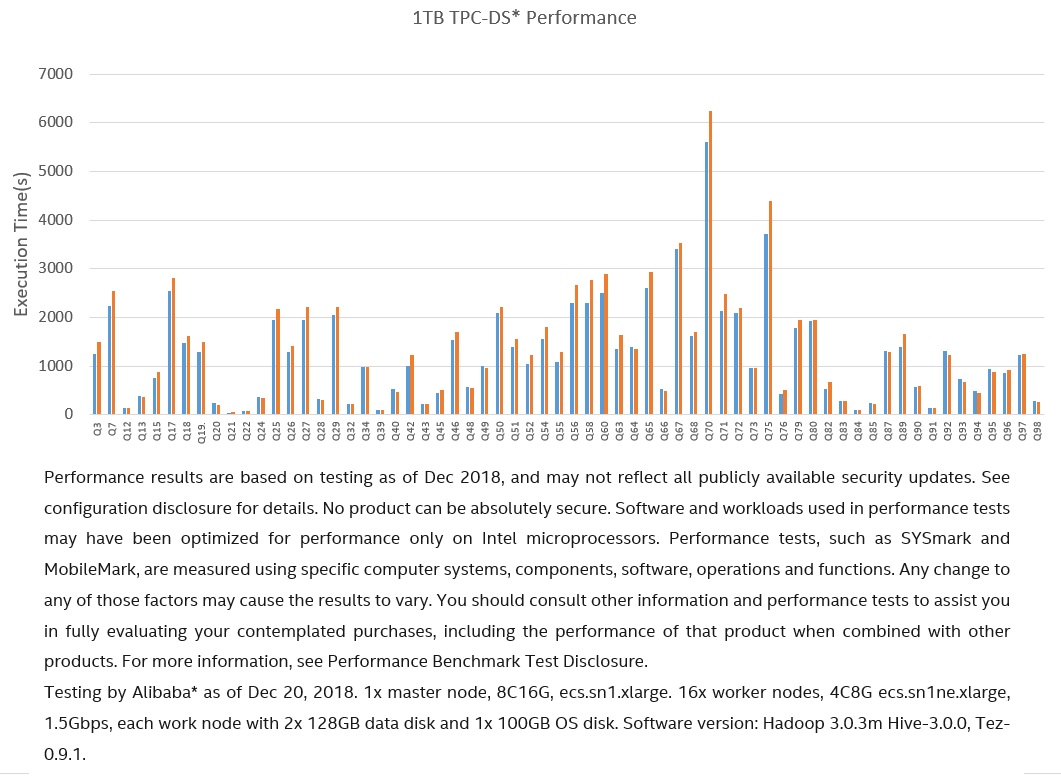
Figure 5. TPC-DS* per query performance
Table 1. Configuration table
| Configuration | Compute node | Storage | Hadoop |
|---|---|---|---|
| HDFS (High-performance cloud disk, 3 replicas) | primary:1 node,8C16G, ecs.sn1.xlarge secondary:16 nodes,4C8G ecs.sn1ne.xlarge, 1.5Gbps |
16 nodes, each with 2 x 12 8 GB + 16 x 100 GB(OS disk) | Hadoop 3.0.3 Hive-3.0.0. Tez-0.9.1 |
| OSS | 16 nodes, each with 100 GB OS disk | ||
Next steps
Although the Hadoop OSS File System released in Hadoop 3.0 has good performance in most read and write cases, there are still a lot of optimization opportunities, such as improvement of the random read performance for columnar format files. Alibaba and Intel will continue to work to deliver a high performance, cost-efficient Hadoop on OSS solution for the Intel platform for Alibaba users. This work proves that migrating your big data workloads to the OSS cloud not only reduces the cost significantly but also provides improved performance through tunings and optimizations.
Summary
Big data on the Cloud is becoming increasingly popular. In this joint study, we present big data analytics on cloud architecture, introduce Hadoop on OSS disaggregated storage solution tunings, optimizations, and show results. With optimizations based on platforms using Intel® Xeon® processors and NVMe* technologies6, running big data analytics workloads on OSS delivers a 9% higher performance with 12.8 times cost reductions.
References
- International Data Corporation (IDC): Data Age 2025
- Apache Hadoop*
- Source: IDC FutureScape: Worldwide Big Data and Analytics 2016 Predictions
- Alibaba Cloud* Object Storage Service (OSS)
- Intel® Optane™ Technology
- Filesystem Compatibility with Apache Hadoop
Notices
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.