Introduction
This blog highlights an exciting collaboration between IBM and Intel to accelerate the watsonx.ai* server for text embedding models. We showcased this joint research at IBM TechXchange 2024. The collaboration focused on using Intel® technologies to enhance retrieval augmented generation (RAG) within the IBM watsonx* platform, specifically improving the performance of text embedding services using Intel® Extension for PyTorch* on 4th gen Intel® Xeon® Scalable processors with Intel® Advanced Matrix Extensions (Intel® AMX), an AI accelerator for training and inference. For completeness, we will briefly revisit RAG and its typical operational implementation before exploring how we accelerated the embeddings service.
Understand RAG
RAG is a specialized technique that enhances large language models (LLM) by enabling them to access and use information from external knowledge sources beyond their original training data. This approach addresses the limitations of LLMs, such as hallucination (generating incorrect information) and outdated knowledge, by grounding their responses in relevant, real-world data.
RAG comprises three primary components:
- Retrieval: The retrieval component identifies and retrieves relevant information from an external knowledge base based on the user's query. This involves:
- Indexing: Documents are processed, segmented into smaller chunks, and transformed into vector representations (embeddings) for efficient storage and retrieval within a vector database. This is one of the major compute-intensive components of the overall RAG process.
- Query Processing: The user's query is transformed into a vector representation, enabling the system to calculate similarity scores between the query and the indexed chunks.
- Selection: The top-ranking chunks exhibiting the highest similarity to the query are selected and passed on to the generation component.
- Augmentation: Augmentation processes optimize the retrieval and generation stages, enhancing the overall effectiveness of the RAG system. These processes include:
- Iterative Retrieval: The knowledge base is repeatedly searched based on the evolving query and previously generated text, refining the retrieved context iteratively.
- Recursive Retrieval: The initial query is progressively refined by decomposing it into subqueries, enabling the system to tackle complex questions systematically.
- Adaptive Retrieval: LLMs dynamically determine the necessity and timing of retrieval, optimizing the information-gathering process based on the evolving context.
- Generation: The generation component uses the retrieved context, augmented with the user's query, to generate a comprehensive and informative response. This process takes advantage of the LLM's inherent language processing capabilities to synthesize a coherent and relevant answer.
A Typical RAG Pipeline
The operational implementation of a production-ready RAG pipeline has three parts:
Vectorize Data
This step involves converting text documents into numerical representations called embeddings, which capture the meaning of the text. This process is like creating meaning machines for text, where each sentence is transformed into a unique numerical vector representing its semantic meaning. A model based on sentence-transformer libraries is commonly used to compute these embeddings. Choosing the right sentence transformer model is crucial, considering factors like size, dimensions, maximum tokens, and task specificity.
The generated vectors are then stored in a vector database, a specialized database designed to store and retrieve information represented as vectors. Vector databases excel at similarity search, scalability, and dynamic updates. One popular open source vector database is Milvus*.
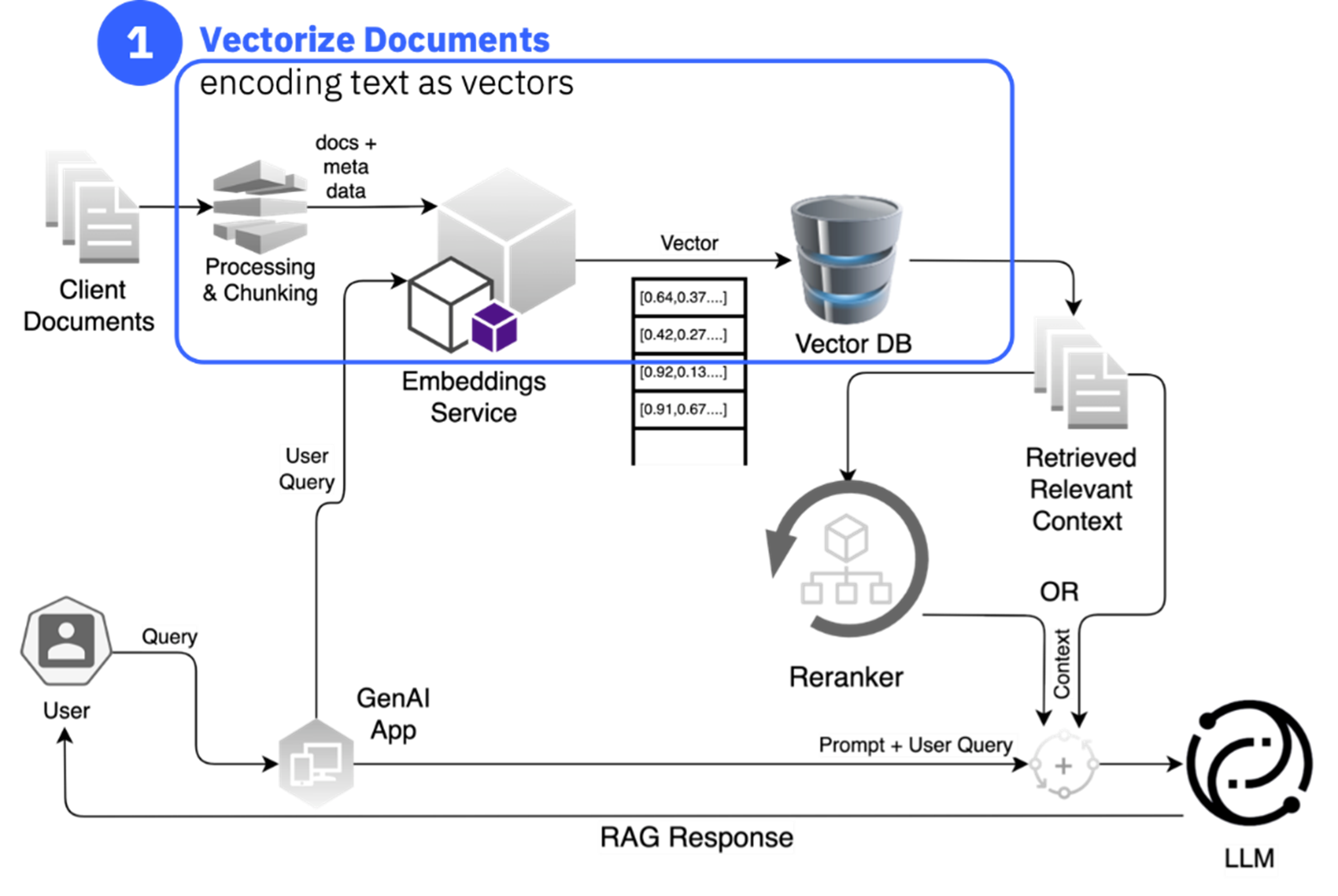
Figure 1: Vectorize data for knowledge augmentation
Retrieve Context
Once the data is vectorized, the system can retrieve relevant information based on a user's query. This involves calculating the cosine similarity between the query's embedding and the embeddings stored in the vector database. Documents with high cosine similarity to the query are considered most relevant and are retrieved for further processing.
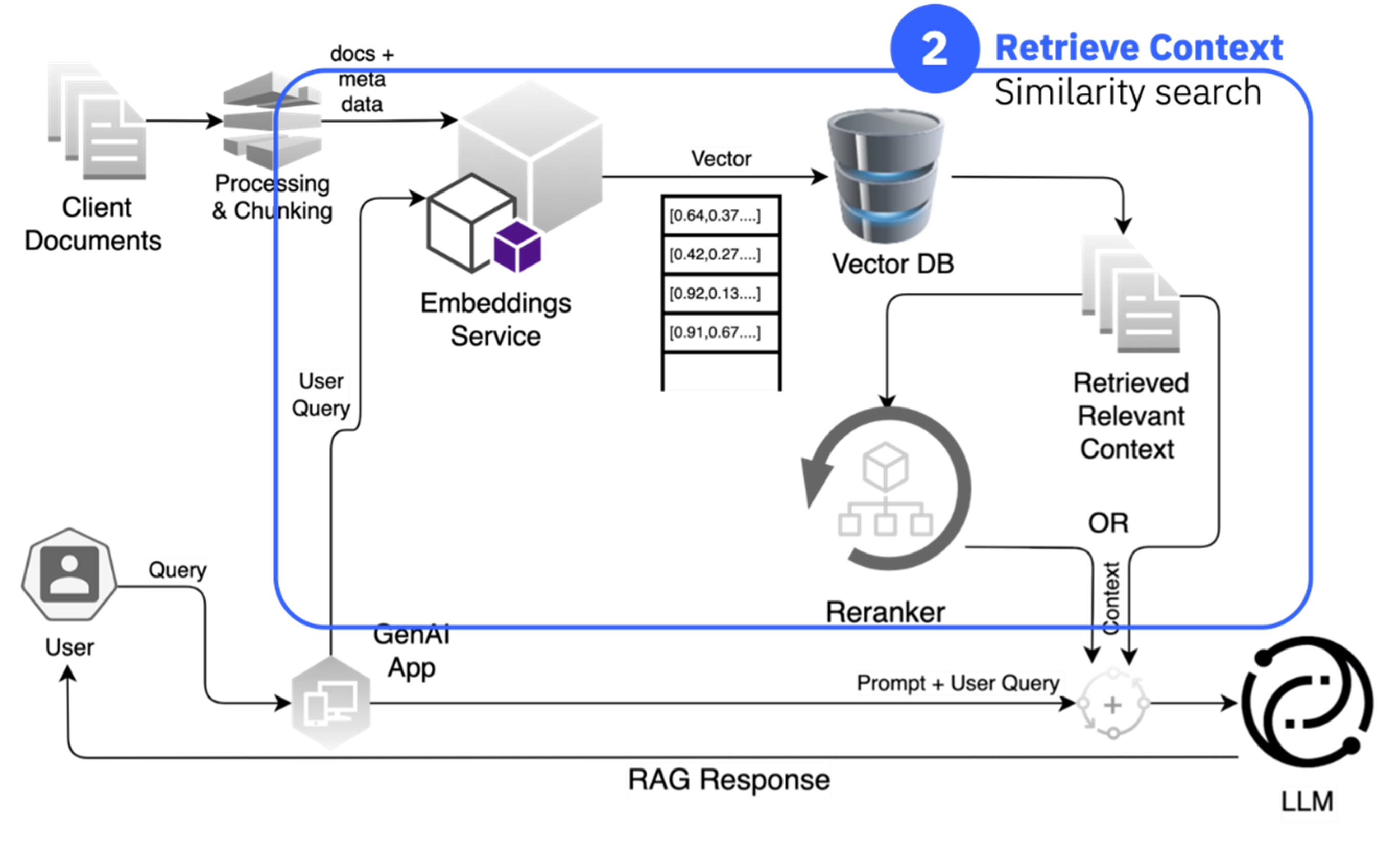
Figure 2: Retrieve context to augment the knowledge
Generate a RAG Response
The final step is to generate a response using the retrieved context. An LLM receives a prompt containing the user's query and the retrieved context. The LLM then generates a response based on this information, leveraging its knowledge and the provided context. This step combines the power of LLMs with the targeted knowledge from the retrieval process.

Figure 3: Generate RAG response
Advantages of RAG
RAG offers several advantages over fine-tuning LLMs. Here are some key advantages of RAG over LLM fine-tuning, as we presented at the IBM TechXchange 2024:
- Versatility and Adaptability Across Various Tasks: Due to its flexible nature, RAG can be applied with a single base model to a broader range of tasks, making it attractive for projects with diverse requirements or evolving use cases.
- Reduced Reliance on an Expensive Fine-Tuning Process: This characteristic makes RAG less expensive and more agile to operate. RAG can use a readily available knowledge base.
- Improved Accuracy and Factual Grounding: RAG grounds responses in real-world information, reducing hallucinations and bias.
- Dynamic Adaptability: RAG offers continuous access to updated information through its external knowledge base.
- Transparency and Explainability: The retrieved information comes from identifiable sources.
The sources also explain that foundation models are generalists. To make them specialists, techniques like fine-tuning, prompt tuning, multitask prompt tuning, LoRA, and QLoRA are used. However, based on the information provided, RAG offers certain advantages, especially when dealing with diverse tasks, the need for real-time information updates, and the explainability of responses.
Text Embeddings Server
At this point, it must be obvious that the choice of text embeddings model and the efficiency of the embeddings model server are critical for a production-ready RAG pipeline. This is why we focused on accelerating the embeddings model server using Intel Extension for PyTorch on 4th gen Intel Xeon Scalable processors with Intel AMX. The following diagram captures the architecture of the watsonx.ai embeddings model server and its runtime based on caikit as presented during the IBM TechXchange 2024.
Note Due to continued improvement, this may not be the current operational stack.
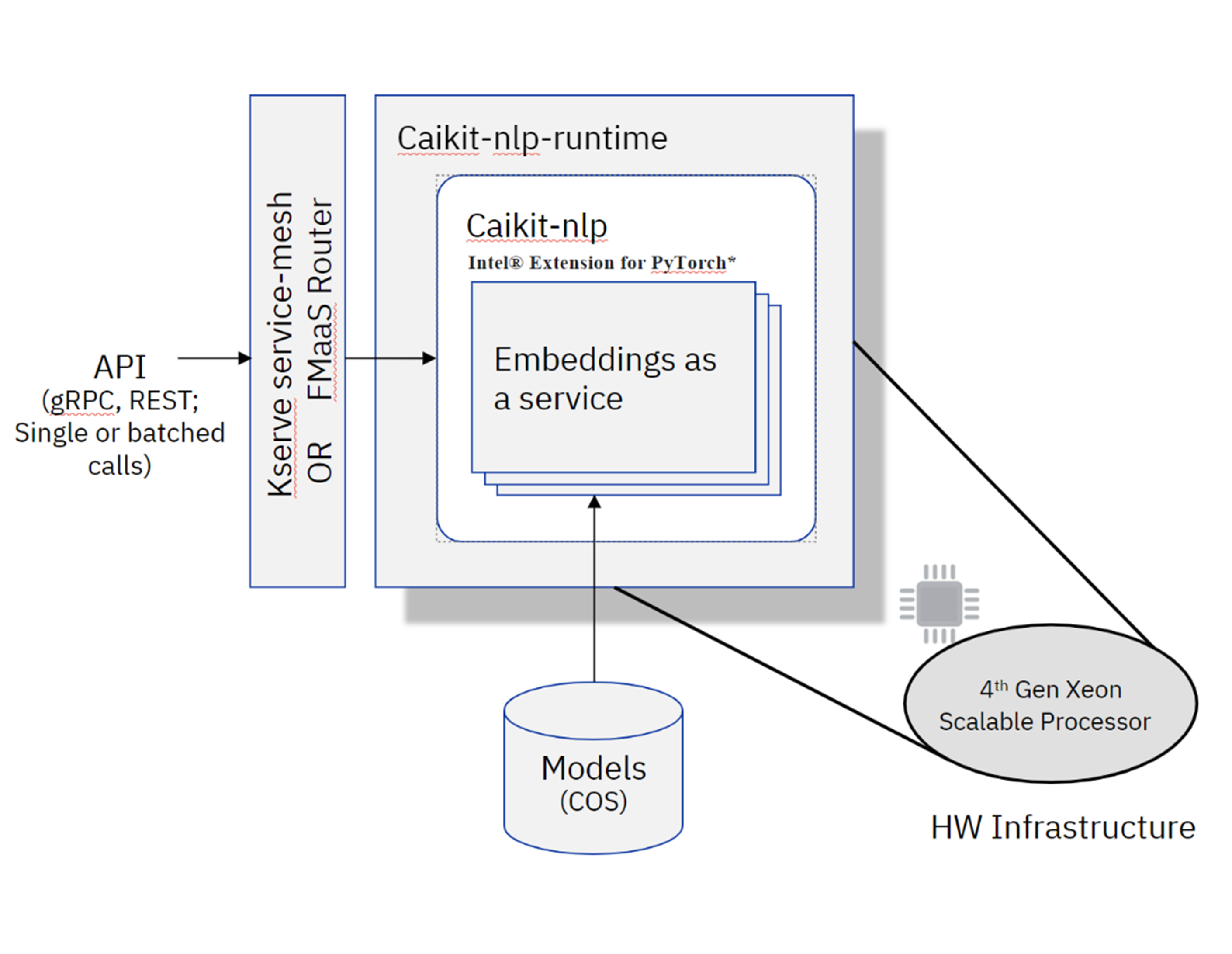
Figure 4. IBM embeddings models for serving runtime of watsonx.ai
Accelerate Embedding Generation with Intel® AMX
We've seen how powerful RAG is, but like any complex process, it has its bottlenecks. One of the most common is the embedding generation phase. In this section, we'll explore how Intel technologies, specifically Intel AMX, can dramatically speed up this process, allowing for faster and more efficient RAG applications.
The embedding generation step in RAG is where we convert raw text into numerical representations, often called embeddings or vectors. These vectors capture the semantic meaning of the text and enable the efficient semantic search that is core to RAG systems. However, generating these embeddings is a computationally intensive process, especially when dealing with large volumes of text or using complex embedding models. The calculations involved in this step rely heavily on matrix multiplications, a type of mathematical operation that is very demanding. This can become a significant bottleneck, leading to slower response times and overall poor user experience.
Intel AMX is a specialized hardware accelerator designed to address the bottleneck of matrix operations. Intel AMX is not just a new set of CPU instructions, it's a dedicated processing unit built into the newer generations of Intel Xeon Scalable processors (such as those from the 4th gen Intel Xeon Scalable processors). This hardware acceleration significantly improves the speed at which matrix multiplications are performed. This is particularly helpful for embedding generation.
The key to Intel AMX performance lies in a few core architectural features:
- Faster Matrix Multiplication: At the heart of Intel AMX lies the Matrix Multiply Accelerator (MMA) unit, which is designed to execute matrix multiplication operations at a much higher speed compared to general-purpose CPU cores. This directly targets the bottleneck in the embedding generation process. It's important to note that Intel AMX achieves this peak performance when using BF16 or int8 data types. While standard FP32 data types are still supported through Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions as found in 3rd gen Intel Xeon Scalable processors and later, Intel AMX provides significant speed advantages for supported data types.
- Optimized Data Handling: Intel AMX uses what are called tile registers to efficiently store and process large blocks of data, or tiles, that can hold the matrices that are used to generate your embeddings. This reduces the time it takes to access data in the main memory, speeding up the whole process. Moreover, Intel AMX provides a specialized instruction, Tile Matrix Multiply (TMUL), which operates directly on the data within the tile registers. This TMUL instruction is highly optimized for the type of matrix computations performed in embedding models, leading to significant acceleration compared to instructions that aren't from Intel AMX, especially when leveraging BF16 or int8 data types.
Intel AMX is designed to perform the matrix computations of the embedding generation in a much faster and optimized way when using BF16 or int8 data types. This allows you to scale your RAG solution further and reduce costs.
Use Intel AMX in PyTorch* for Embedding Acceleration
The great news is that you don’t have to be a hardware engineer to benefit from Intel AMX. It's easily accessible through popular machine learning frameworks like PyTorch. By using the Intel AMX hardware acceleration, you can substantially speed up your embedding generation process and, thus, the speed of your RAG system.
Here's how you can tap into this power:
- Bfloat16 Data Type: Intel AMX is optimized for bfloat16 and int8 data types. By using torch.cpu.amp.autocast or torch.autocast ("cpu") you can enable calculations to happen using this data type. This helps to maximize the performance of the Intel AMX hardware accelerator. For more information on using bfloat16 on PyTorch, see Leverage Intel Advanced Matrix Extensions.
- Intel Extension for PyTorch: Intel also provides its own extension for PyTorch, which can be used to further optimize models and use the full potential of Intel AMX when using bfloat16 data types.
The next section explores the practicalities of enabling Intel AMX and optimizing your embedding generation process using Intel Extension for PyTorch. We show exactly the type of code changes that are necessary with some practical examples.
How to Use Intel® Extension for PyTorch*
Intel Extension for PyTorch extends PyTorch with the latest performance optimizations for Intel hardware. Optimizations take advantage of Vector Neural Network Instructions (VNNI) for Intel AVX-512 and Intel AMX on Intel CPUs.
Intel works closely with the open source PyTorch project to upstream optimizations by default into the framework. This extension enables the users to apply the newest performance optimizations that are not yet in PyTorch with minimal code changes. Learn how to install it. The extension can be loaded as a Python module or linked as a C++ library. Python users can enable it dynamically by importing intel_extension_for_pytorch.
The CPU tutorial gives detailed information of Intel Extension for PyTorch for Intel CPUs. The source code is available at the main branch.
BF16 data type mentioned previously is a floating-point format that occupies 16 bits of computer memory but represents the approximate dynamic range of 32-bit floating-point numbers. 4th gen Intel Xeon Scalable processors and later support acceleration for the BF16 data format, which offers a balance between the precision of FP32 and the computational efficiency of lower precision formats. This balance makes BF16 particularly well-suited for embedding generation tasks.
Intel® Optimization for PyTorch* provides enhanced performance through kernel optimizations, graph optimization, and support for BF16. By using Intel Extension for PyTorch in conjunction with BF16 optimizations, sentence-transformer models can achieve faster inference times and reduced memory usage, making them ideal for deployment on Intel's latest processors.
By using Intel Extension for PyTorch, you are not only making it easier to use bfloat16 but also to use Intel's optimized kernels and operators. Using this along with Intel AMX can significantly increase performance in your embedding generation.
For a complete and detailed guide with working examples, refer to the official Intel Extension for PyTorch bfloat16 documentation. This documentation provides a step-by-step guide, including the necessary code changes, to effectively convert your models to bfloat16 using Intel Extension for PyTorch to use Intel AMX. This resource is ideal for users who want a comprehensive walk-through of the API for Intel Extension for PyTorch and how to apply it in their projects.
Optimize Sentence-Transformer Embedding Models with PyTorch provides information on how sentence transformer embedding models can be optimized using Intel AMX and bfloat16. This example focuses specifically on sentence transformer models, showing a real-world case of how to accelerate your embedding generation. It highlights the performance gains that can be achieved with Intel AMX and bfloat16 along with Graph Mode.
Optimize Embedding Generation on Caikit-NLP with Intel Extension for PyTorch
As seen earlier, IBM embeddings models serving runtime with watsonx are provided by Caikit-NLP. Caikit-NLP uses sentence-transformers models to generate embeddings. To enhance performance, Caikit-NLP is optimized with Intel Extension for PyTorch to take full advantage of Intel AMX and bfloat16 for faster embeddings.
The key to this optimization is the seamless integration of Intel Extension for PyTorch that facilitates converting and managing the model's data types. The primary methods of enabling this within the Caikit-NLP server were done by using ipex.optimize() to convert the model and torch.cpu.amp.autocast() for dynamic handling of operations with bf16. To see how ipex.optimize was used in practice to accelerate embedding generation for watsonx, you can refer to this code example. This link leads to a snippet from the larger Caikit-NLP project where you can observe a working example of how the ipex.optimize function is used to optimize a model for BF16 for use with Intel AMX. It's a great resource to see the function called in context. Similarly, to see how torch.cpu.amp.autocast was used in practice, you can refer to this embedding example. This link shows how autocast is used to automatically use bfloat16 for operations in a specific part of the code. This is a great resource if you want a deeper look into how this context manager is implemented in a real-world use case to accelerate embedding generation.
The ipex.optimize() optimization process to accelerate sentence transformers embedding generation that happens on Caikit-NLP can be broken down into the following steps:

Figure 5. Illustration of the optimization process
- The Sentence Transformers model is loaded in PyTorch, establishing a baseline model for the embedding task using PyTorch as the primary framework.
- The model is then optimized with Intel Extension for PyTorch, which introduces CPU-specific optimizations to enhance performance on Intel hardware.
- The model precision is converted to bfloat16 format. This reduces memory use and increases computational throughput while maintaining comparable accuracy to FP32, making it well-suited for large-scale inference.
- Weight prepacking is applied to the model. This optimization restructures the weights in memory to align better with the underlying hardware, accelerating operations like matrix multiplications and improving overall inference speed.
- Optionally, the model can be converted to Graph Mode using TorchScript, a mechanism that compiles the model into an intermediate representation, enabling faster execution and reducing runtime overhead.
- Finally, the optimized model is run on 4th gen Intel Xeon Scalable processors with Intel AMX. This hardware capability further accelerates deep learning operations by providing efficient support for matrix multiplications, a key component of transformer-based models.
Performance and Benchmarks
We evaluated the optimized Sentence Transformers models using two open source models on Hugging Face* that are also part of watsonx: BAAI/bge-large-en-v1.5 and all-MiniLM-L12-v2. The optimizations use Intel Extension for PyTorch, BF16 precision, and AMX acceleration on a 4th gen Intel® Xeon® Platinum 8474C processor. The results were compared against the baseline 2nd gen Intel Xeon Platinum 8260 processor.
Datasets Used for Benchmarking
Sentences – mteb/stsbenchmark-sts
This dataset focuses on sentence pairs for semantic similarity tasks, with a mean sentence length of 9.95 words. It highlights performance in low-token, high-throughput scenarios.
Sentences – mteb/imdb
This dataset, derived from Internet Movie Database (IMDB*) movie reviews, contains longer texts with a mean sentence length of 233.78 words. It tests embedding generation efficiency for high-token, document-level tasks.
Benchmarking Results
BAAI/bge-large-en-v1.5 (Short Sentences)
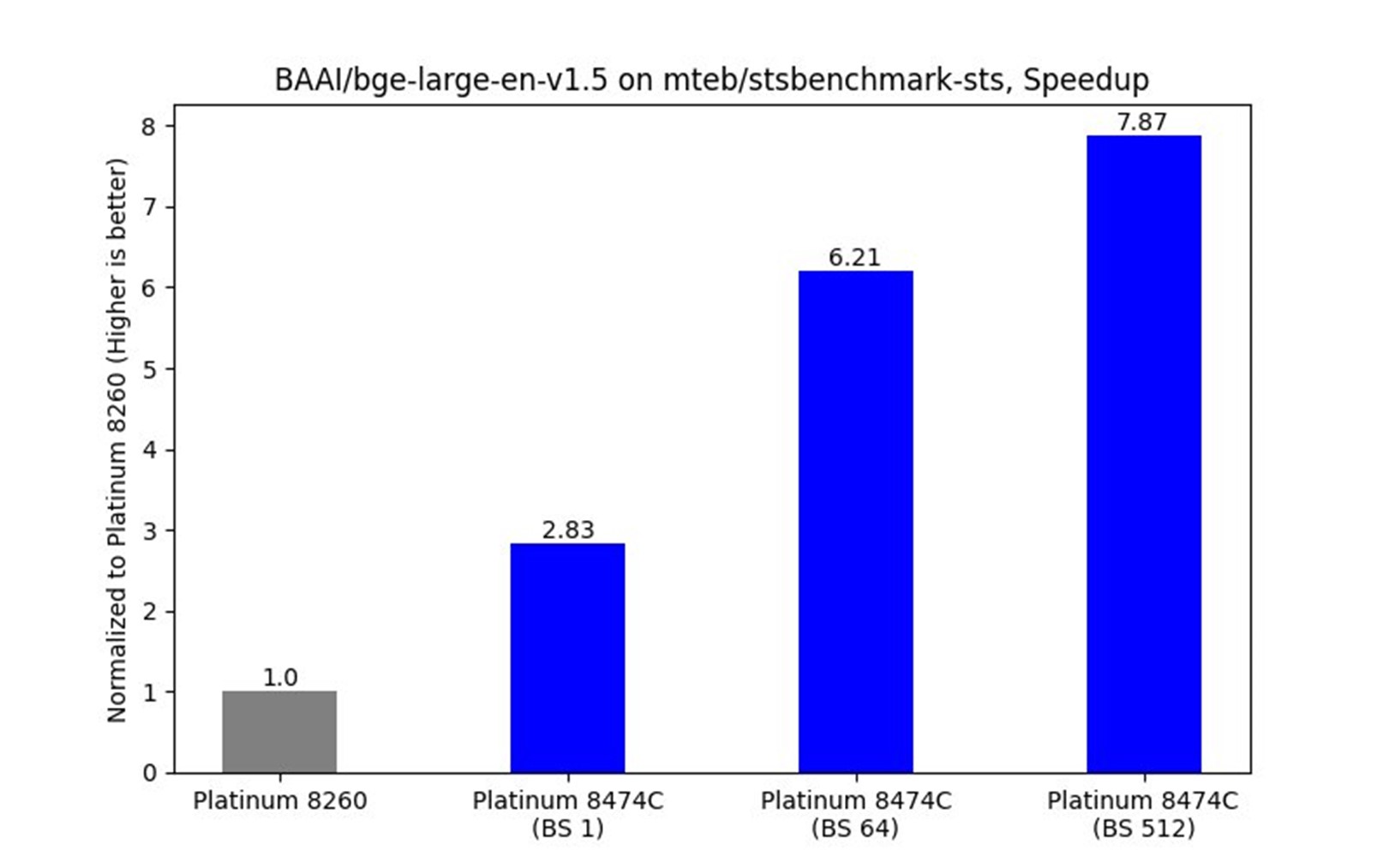
Figure 6. Benchmarks for various processors
The optimized model demonstrated a 7.8x speedup in embedding throughput compared to the baseline.
A significant performance boost is observed as the batch size increases:
- 2.83x speedup at batch size 1 (BS 1)
- 6.21x speedup at batch size 64 (BS 64)
- 7.87x speedup at batch size 512 (BS 512)
The optimizations benefit larger batch sizes, enabling efficient utilization of the Intel AMX instruction set, larger cache sizes, and increased memory bandwidth on the 4th gen Intel Xeon Platinum 8474C processor.
BAAI/bge-large-en-v1.5 (Long Sentences)
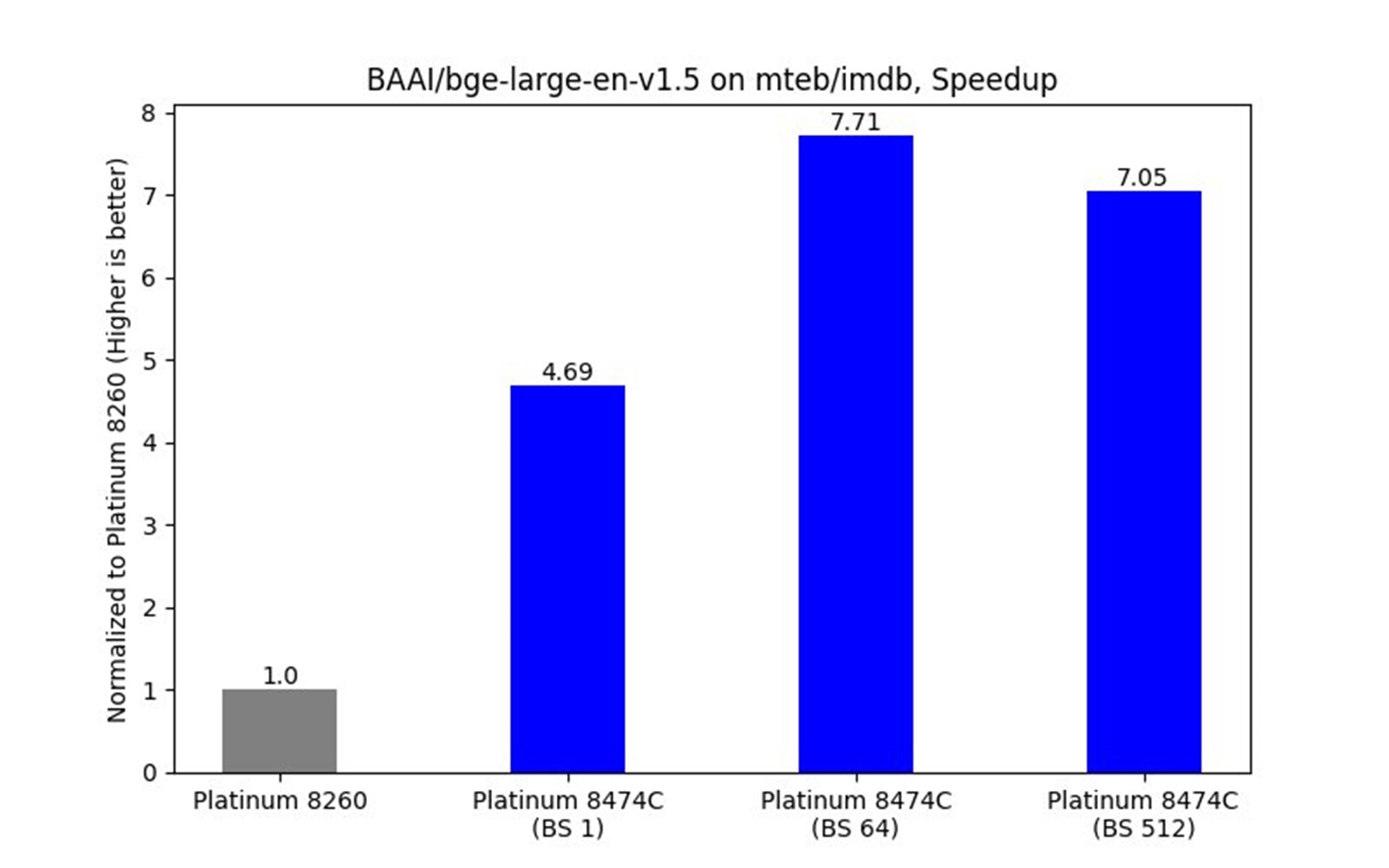
Figure 7. Benchmarks for various processors
For longer sentences, the model achieved up to 7.71x speedup, demonstrating consistent improvements:
- 4.69x speedup at batch size 1 (BS 1)
- 7.71x speedup at batch size 64 (BS 64)
- 7.05x speedup at batch size 512 (BS 512)
The optimizations scale well for longer sentence embeddings, with higher gains seen at moderate and large batch sizes due to better hardware use.
all-MiniLM-L12-v2 (Long Sentences)
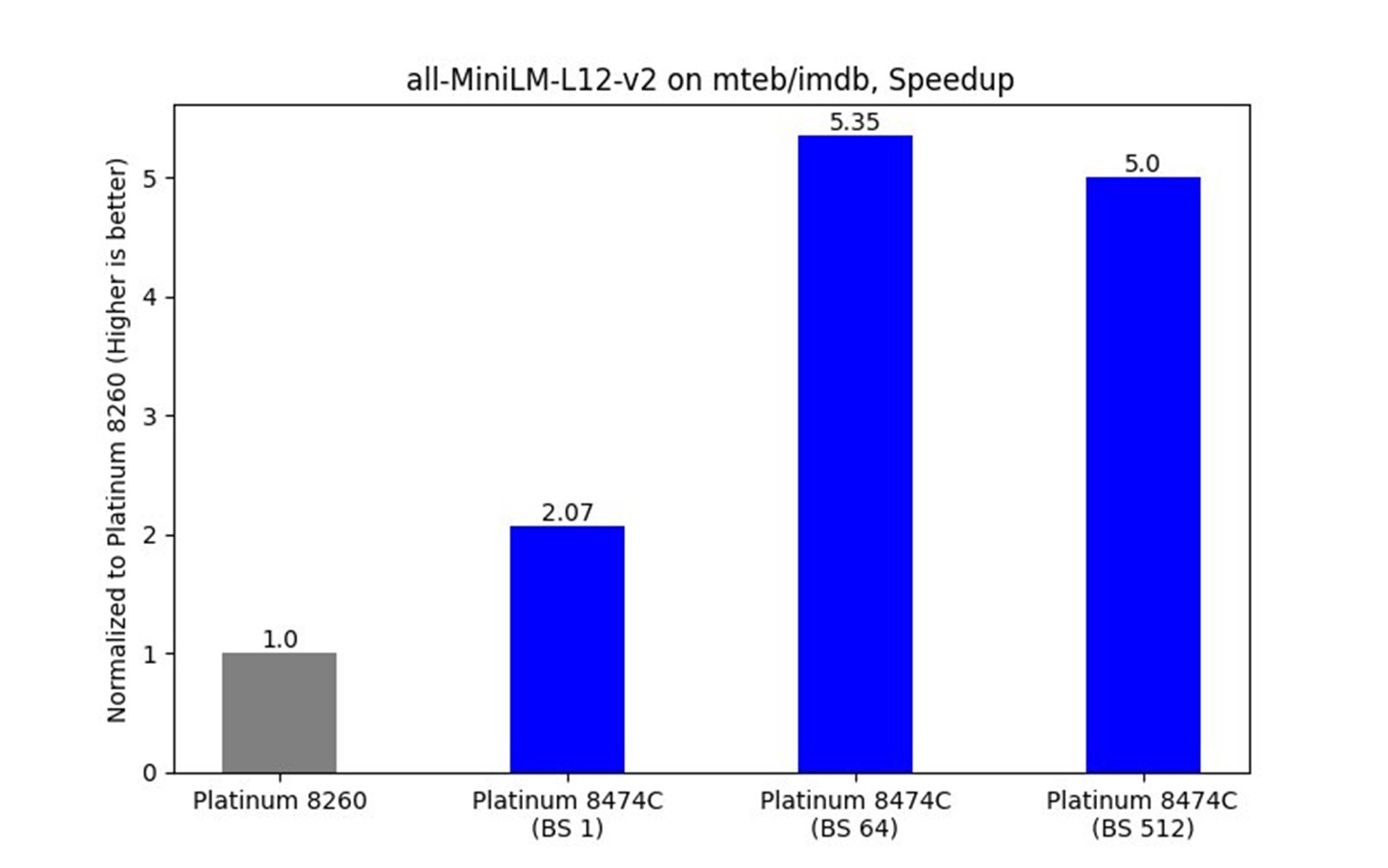
Figure 8. Benchmarks for various processors
The smaller all-MiniLM-L12-v2 model exhibited a 5.35x speedup for long sentences:
- 2.07x speedup at batch size 1 (BS 1)
- 5.35x speedup at batch size 64 (BS 64)
- 5.0x speedup at batch size 512 (BS 512)
While the gains are relatively lower compared to larger models, optimizations still deliver a notable improvement, particularly for batch sizes optimized for throughput.
Throughput Comparison Gen-on-Gen
Performance of 4th Gen Intel Xeon Scalable processors yielded about 10x better performance at max load compared to 2nd Gen Intel Xeon Scalable processors, as shown:
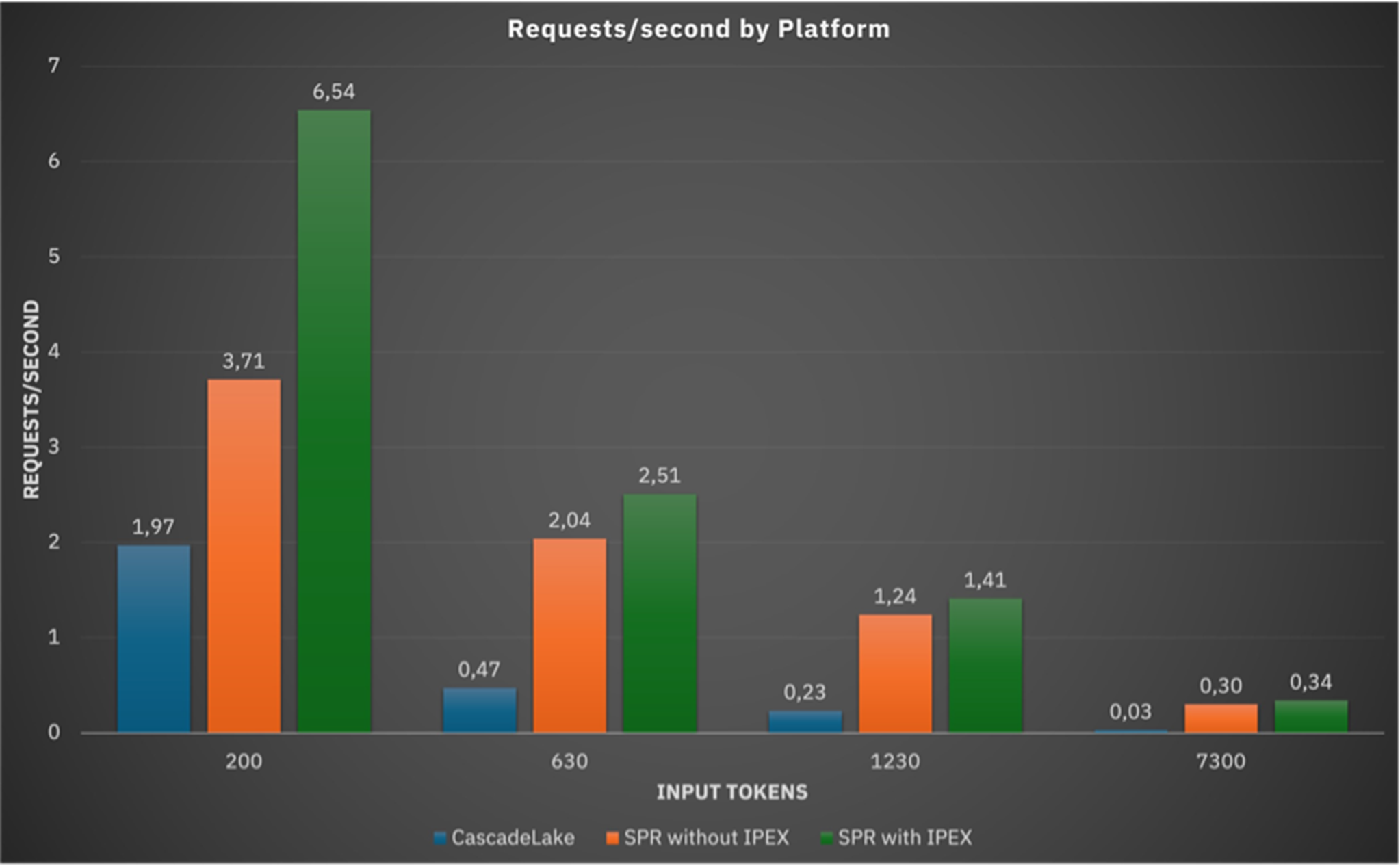
Figure 9. Benchmarks for various platforms
Note In the previous chart, higher is better.
Conclusion
The research collaboration between IBM and Intel marks a significant achievement in optimizing RAG for real-world applications using readily available CPU resources. By accelerating the text embeddings model server with technologies like Intel Extension for PyTorch and 4th gen Intel Xeon Scalable processors with Intel AMX, the collaboration achieves comparable performance to GPUs, but with the added benefit of using more cost-effective CPUs. This approach allows enterprises to reserve their more expensive GPU compute resources for other critical AI operations, making RAG deployments more accessible and economically viable.
Specifically, the integration of Intel AMX, a built-in AI accelerator on the 4th gen Intel Xeon Scalable processors, significantly enhances the performance of matrix operations, which are fundamental to embedding generation. This hardware acceleration, coupled with software optimizations like bfloat16 data type and IPEX’s optimized kernels, results in faster and more efficient embedding generation, even for complex models and large datasets.
Benchmarks conducted as part of the collaboration demonstrate impressive speedups in embedding throughput, reaching up to 7.8x for short sentences and 7.71x for long sentences compared to baseline systems78. These performance gains directly translate to faster query processing and lower latency in RAG applications, contributing to a seamless user experience.
Acknowledgments
- Mark Sturdevant: As senior open source developer, lead the development of the text embeddings model server based on caikit.
- Michael Desimone: As architecture and integration lead of AI platform enablement, supported infrastructure and regression testing.
- Flavia Janine Rosante Beo: A research software engineer who worked as a core member of the collaboration team for this project.
- Alan Braz: As IBM senior research developer, supported the collaboration throughout with his Red Hat OpenShift* AI expertise.
Product and Performance Information
Baseline Intel® Xeon® Platinum 8260 CPU: 1-node, 1x Intel Xeon Platinum 8260 CPU at 2.40 GHz, 96 cores, hyperthreading on, turbo on, NUMA 2, integrated accelerators available (used): DLB 0 [0], DSA 0 [0], IAA 0 [0], QAT 0 [0], total memory 384 GB (12x32 GB, DDR4, 2933 MT/s [Unknown]), BIOS (IVE184E-4.12), microcode 0x5003605, 1x 100 G network interface, Ubuntu* 22.04.5 LTS, 5.14.0-508.el9.x86_64. Tested by Intel as of September 23, 2024.
BAAI/bge-large-en-v1.5, all-MiniLM-L12-v2 intelopenmp libstdc++ tcmalloc PyTorch 2.4, Docker* for Ubuntu 22.04
Intel Xeon Platinum 8474C CPU: 1-node, 1x Intel Xeon Platinum 8474C CPU 2.5 GHz, 96 cores (48 physical with hyperthreading on), turbo on, NUMA 2, integrated accelerators available (used): DLB 2 (n/a), DSA 2 (none), IAA 2 (none), QAT on CPU 2 (n/a), QAT on chipset 0 (n/a), total memory 512 GB (16x32 GB DDR5 4800 MT/s), BIOS ESE124Y-3.11, microcode 0x2b0005c0, 1x network interface (details not provided), no instance storage specified, Ubuntu 22.04.5 LTS, kernel 6.8.0-45-generic. Tested by Intel as of September 23, 2024.
BAAI/bge-large-en-v1.5, all-MiniLM-L12-v2 intelopenmp, libstdc++ tcmalloc PyTorch 2.4, Intel Extension for PyTorch 2.4.0 plus CPU, Docker for Ubuntu 22.04