A GitHub* project offers many benchmark source codes written in oneAPI for independent software vendors (ISVs).
Challenge
New ideas need methods to evaluate their effectiveness and value. Different parallel programming models have emerged over the last several years, including OpenMP*, OpenCL™ standard, Heterogeneous-Computing Interface for Portability (HIP), SYCL*, and most recently oneAPI.
oneAPI is gaining traction across the software ecosystem, both with individual developers1 and with ISVs who build compilers and tools to deploy SYCL and Data Parallel C++ (DPC++) code to targeted devices. Besides oneAPI support for Intel® XPUs, the ecosystem is expanding to other accelerators. There’s the Intel® DPC++ Compatibility Tool used to assist migrating CUDA* to DPC++. Recent contributions from Codeplay* to the open source DPC++ with LLVM* project allow developers to target NVIDIA* GPUs using SYCL code without intermediate layers.2 Work at Heidelberg University3 is underway to create a SYCL and DPC++ compiler for AMD* GPUs. As more ISVs develop products to the oneAPI standard, they need benchmarks written in different ways to measure and compare their performance and productivity.
Solution
Zheming Jin, formerly a postdoctoral researcher at Argonne National Laboratory and now at Oak Ridge National Laboratory, has created a rich repository of such benchmarks. The project specifically evaluates oneAPI direct programming based on SYCL and DPC++ and OpenMP (see Table 1). His project is posted on Intel® DevMesh.
“oneAPI is an interesting model worth studying,” explained Zheming. “But we don’t have a lot of open source programs to study SYCL and DPC++ implementations. We have many CUDA and OpenMP programs targeting different devices, like NVIDIA GPUs, but not enough that can be used to compare against SYCL and DPC++.”
Currently, his GitHub project contains more than 90 different codes (see Table 1) written in SYCL, DPC++, CUDA, and OpenMP. Some of these come from the Rodinia benchmark suite, including Kmeans, Heart Wall, Particle Filter, and Back Propagation, among others. Refer to the full GitHub list for sources and other information important to the repository.
Table 1. List of test codes at oneAPI-DirectProgramming
| affine | Affine transformation |
| all-pairs-distance | All-pairs distance calculation |
| amgmk | The relax kernel in the AMGmk benchmark |
| aobench | A lightweight ambient occlusion renderer |
| atomicIntrinsics | Atomic add, subtract, min, max, AND, OR, and XOR |
| axhelm | Helmholtz matrix-vector product |
| backprop | Train weights of connecting nodes on a layered neural network |
| bezier-surface | Bezier surface |
| bfs | Breadth-first search |
| bitonic-sort | Bitonic sorting |
| black-scholes | Black-Scholes simulation |
| bsearch | Classic and vectorizable binary search algorithms |
| bspline-vgh | Bspline value gradient hessian |
| b+tree | B+Tree search |
| ccsd-trpdrv | The CCSD tengy kernel in NWChem |
| cfd | Solver for the 3D Euler equations for compressible flow |
| chi2 | Chi-square 2-df test |
| clenergy | Direct coulomb summation kernel |
| clink | Compact LSTM inference kernel |
| cobahh | Simulation of random network of Hodgkin and Huxley neurons with exponential synaptic conductances |
| compute-score | Document filtering |
| diamond | Mask sequences kernel in Diamond |
| divergence | Divergence comparison between a CPU and a GPU |
| easyWave | Simulation of tsunami generation and propagation in the context of early warning |
| extend2 | Smith-Waterman extension in Burrow-wheeler aligner for short-read alignment |
| filter | Filtering by a predicate |
| fft | Fast Fourier transform |
| floydwarshall | Floyd-Warshall pathfinding sample |
| fpc | Frequent-pattern compression |
| gamma-correction | Gamma correction |
| gaussian | Gaussian elimination |
| geodesic | Geodesic distance |
| haccmk | The HACC microkernel |
| heartwall | Track the movement of a mouse heart over a sequence of ultrasound images |
| heat | A heat equation solver |
| heat2d | Discrete 2D Laplacian operations on a given vector |
| histogram | Histogram computation |
| hmm | Hidden Markov model |
| hotspot3D | Simulate microprocessor temperature on a 3D input grid |
| hybridsort | A combination of bucketsort and mergesort |
| interleave | Interleaved and non-interleaved global memory accesses |
| inversek2j | The inverse kinematics for 2-joint arm |
| ising | Monte-Carlo simulations of 2D Ising model |
| iso2dfd | A finite difference stencil kernel for solving the 2D acoustic isotropic wave equation |
| jenkins-hash | Bob Jenkins lookup3 hash function |
| keccaktreehash | A Keccak tree hash function |
| kmeans | Fuzzy k-means clustering |
| knn | Fast k-nearest neighbor search |
| laplace | A Laplace solver using red-black Gaussian Seidel with SOR solver |
| lavaMD | Calculate particle potential and relocation between particles within a large 3D space |
| leukocyte | Detect and track rolling leukocytes |
| lid-driven-cavity | A GPU solver for a 2D lid-driven cavity problem |
| lombscargle | Lomb-Scargle periodogram |
| lud | LU decomposition |
| mandelbrot | Calculate the Mandelbrot set |
| matrix-mul | Single-precision floating-point matrix multiply |
| matrix-rotate | In-place matrix rotation |
| maxpool3d | 3D maxpooling |
| md | Computation of Lennard-Jones potential using a neighbor-list algorithm |
| md5hash | MD5 hash function |
| memcpy | Memory copies from a host to a device |
| miniFE | A proxy application for unstructured implicit finite element codes |
| mixbench | A read-only version of Mixbench |
| mkl-sgemm | Single-precision floating-point matrix multiply using Intel® Math Kernel Library |
| murmurhash3 | MurmurHash3 yields a 128-bit hash value |
| myocyte | Model cardiac myocyte and simulate its behavior |
| nbody | N-body simulation |
| nn | k-nearest neighbors from an unstructured data set of coordinates |
| nw | A nonlinear global optimization method for DNA sequence alignments |
| page-rank | PageRank |
| particle-diffusion | Monte-Carlo simulation of the diffusion of water molecules in tissue |
| particlefilter | Statistical estimator of the location of a target object |
| pathfinder | Find a path on a 2D grid with the smallest accumulated weights |
| projectile | Projectile motion is a program that implements a ballistic equation |
| qtclustering | Quality-threshold clustering |
| quicksort | Quicksort |
| randomAccess | Random memory accesses |
| reduction | Integer sum reduction using atomics |
| reverse | Reverse an input array of size 256 using shared memory |
| rng-wallace | Random number generation using the Wallace algorithm |
| rsbench | A proxy application for full neutron transport application that supports multipole cross-section representations |
| rtm8 | A structured grid application in the oil and gas industry |
| s3d | Chemical rates computation used in the simulation of combustion |
| scan | A block-level scan using shared memory |
| simplemoc | The attenuation of neutron fluxes across an individual geometrical segment |
| softmax | Softmax function |
| sort | Radix sort |
| sph | The simple n2 SPH simulation |
| srad | Speckle reducing anisotropic diffusion |
| sssp | The single-source shortest path |
| stencil | 1D stencil using shared memory |
| streamcluster | Online clustering of an input stream |
| su3 | Lattice QCD SU(3) matrix-matrix multiply microbenchmark |
| transpose | Tensor transpose example |
| xsbench | A proxy application for full neutron transport application like OpenMC |
History
“Rodinia is a popular benchmark suite used by researchers that target accelerators. Most codes in Rodinia include OpenMP, CUDA, and OpenCL [code] implementations,” added Zheming. “But codes within the Rodinia suite didn’t have SYCL implementations to compare performance or productivity across different programming models. I started with some codes from Rodinia.”
Zheming wanted benchmarks between different implementations to be as fair as possible. So, his goal was to create codes that are as functionally equivalent as possible, that is, without special optimizations that might cater to a particular manufacturer’s device.
OpenMP is widely used across the ecosystem for shared-memory parallelism. The OpenMP standard continues to evolve. Since 2015, it has added support for targeted device offloading to GPUs, and ISVs, including Intel, continue to enhance their compilers for it.
For his repository, Zheming created CUDA versions from open source files, and then ported those codes to DPC++ using the Intel DPC++ Compatibility Tool. The tool helps developers migrate CUDA code to DPC++ with 80 to 90 percent of the code automatically transitioning to DPC++. CUDA language kernels and library API calls are also ported over.
“There are many CUDA programs for parallel computation,” added Zheming. “It’s important that we have a tool to help port them to SYCL/DPC++ so they can be run across different architectures.”
The Intel DPC++ Compatibility Tool is part of the Intel® oneAPI Base Toolkit, which Zheming used. Because different CUDA implementations can access data either through device buffers or shared memory, Zheming produced two versions of the converted code. For codes in the repository with “‑dpct” suffixes, memory management migration was implemented using both the explicit and restricted Unified Shared Memory extension. Codes with the “-dpct-h” suffix use Intel DPC++ Compatibility Tool header files.
Additionally, he wrote SYCL versions using SYCL buffers. Then he ran the codes on Intel® processor-based platforms.
Evaluating the Codes on Intel® CPUs and GPUs
Zheming evaluated the four codes (SYCL, both DPCT-generated device buffer or shared memory versions, and OpenMP) on two different Intel processor-based platforms with Intel integrated graphics:
- Intel® Xeon® E3-1284L processor with Intel® P6300 graphics (Gen8)
- Intel® Xeon® E2176G processor with Intel® UHD630 graphics (Gen9.5)
He used the OpenCL standard intercept layer to monitor the following using the OpenCL standard plug-in interface:
- Total enqueue—indicates the total number of low-level OpenCL standard enqueue commands called by a parallel program. These enqueue commands include clEnqueueNDRangeKernel, clEnqueueReadBuffer, and clEnqueueWriteBuffer.
- Host timing—the total elapsed time of executing OpenCL API functions on a CPU host.
- Device timing—the total elapsed time of executing OpenCL API functions on a GPU device.
The results from both platforms are listed in the repository starting at Results on Platform 1.
The results show that for most of these codes, performance across the Intel DPC++ Compatibility Tool and SYCL implementations differs only slightly. This is not surprising considering they are similar in approach. However, compared to OpenMP code, the oneAPI codes had fewer calls and ran faster.
Figure 1 compares results of a few of these benchmark codes. Because the measurements differ in units (number of calls, seconds, and milliseconds), the table is normalized to the OpenMP standard implementation.
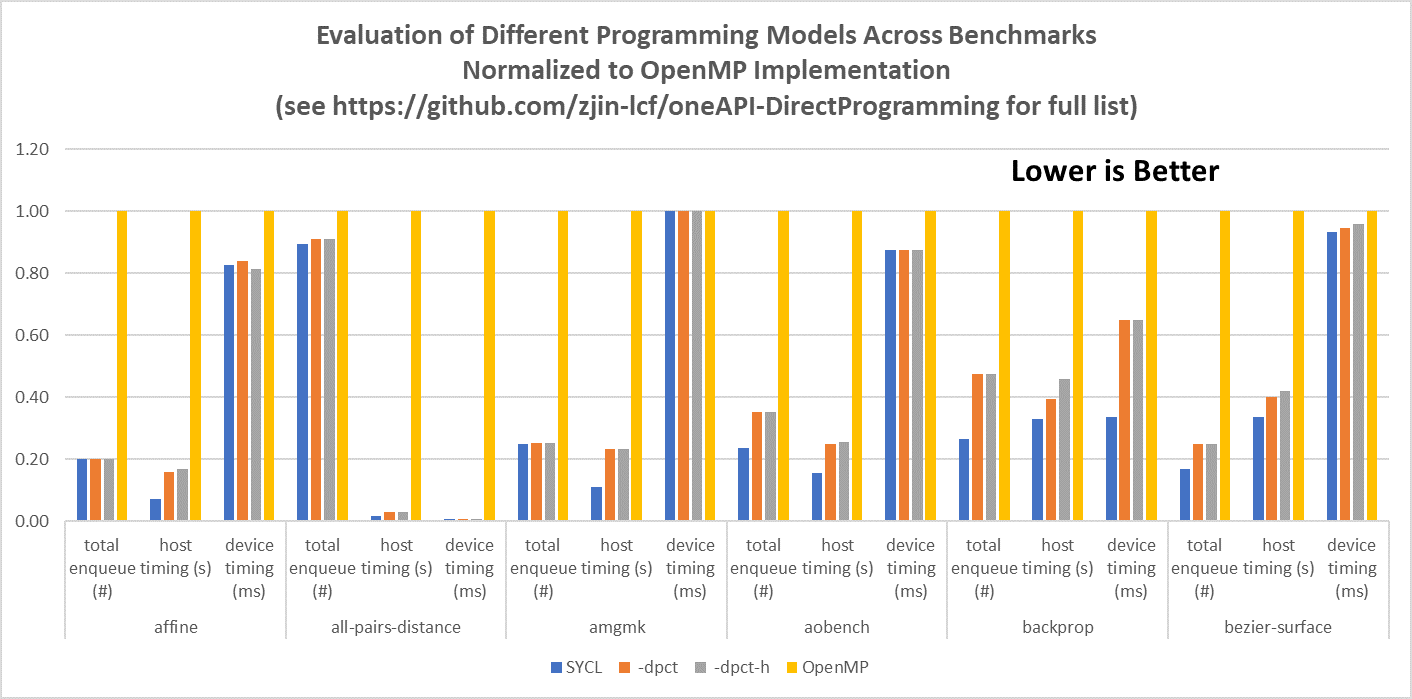
Figure 1. Partial benchmark results from repository codes normalized to OpenMP code. See the full list at GitHub.
Zheming’s repository is an ongoing work that began with studying the Rodinia benchmark to understand how to migrate programs to oneAPI and evaluate the benefit of the new programming model on Intel architectures. These studies are documented in several reports,4 which show improved performance using SYCL on Intel xPUs and higher coding productivity. For example, comparing SYCL and OpenCL standard implementations of Heart Wall and Particle Filter, a SYCL implementation of Heart Wall ran 15 percent faster on Intel® Iris® Plus graphics than an OpenCL standard implementation, while the Particle Filter SYCL code ran 4.5X faster on an Intel® Xeon® processor with four cores.4 Both programs required 52 percent (for Heart Wall) and 38 percent (for Particle Filter) fewer lines of code, making actual programming more productive.4
Zheming encourages other developers creating similar benchmarks to consider merging GitHub projects for the community.
Enabling Technologies
Zheming used the following tools and technologies to help build his repository.
Software:
- Intel® oneAPI Base Toolkit
- Intel® oneAPI HPC Toolkit
- Intercept Layer for OpenCL™ Applications
- Intel® Parallel Studio and Intel® VTune™ Profiler tools
Hardware:
- Intel Xeon E3-1284L processor and Intel Xeon E2176G processor
- P6300 graphics (Gen8) from Intel and Intel® UHD Graphics 630 (Gen9.5)
- Intel® DevCloud
Resources and Recommendations
- Develop, test, and run your solution with access to the latest Intel® hardware and oneAPI software on Intel DevCloud for oneAPI
- SYCL Overview
Footnotes
1. See projects at Intel DevMesh
2. Codeplay Contribution Brings NVIDIA Support For SYCL Developers
3. Intel oneAPI Is Coming to AMD Radeon* GPUs
4. Improve the Performance of Medical Imaging Applications Using SYCL. Also see A Case Study with the HACCmk Kernel in SYCL and A Case Study of k-means Clustering Using SYCL