Challenge
AI is rapidly becoming a vital ingredient of many business applications, as well as a fixture in everyday life for millions of computer users around the world. However, considerable baggage accompanies much of AI technology and the deployment of optimized, targeted solutions. Frameworks, such as TensorFlow* and PyTorch*, typically provide the building blocks for creating the deep learning models that power AI solutions. These frameworks, unfortunately, are generally unwieldy, complex, and ultimately inefficient. Unnecessary code ported along with the solution affects performance, code transparency, and solution maintainability.
Many of today’s deep learning solutions are characterized by extreme fragmentation of hardware and software ecosystems, resulting in deployed models that require elaborate software stacks. To operate effectively in heterogeneous systems, collections of software, hardware, and exchange formats are necessary. This creates ongoing interoperability issues as the enabling solution components—including hardware platforms, software frameworks, platform-specific tools and libraries—continue to evolve at a rapid pace. The need for a more unified, streamlined approach to embedded deep learning is evident.
The industry trends toward edge computing, embedded AI-powered IoT applications, and disaggregated architectures connected over the cloud have amplified the need for compact, portable solutions that can be ported to diverse targets from a single code source. In an article posted on LinkedIn*1, Richard Gaechter, entrepreneur and international business leader, said, “As technology firms begin to get their arms around solutions to questions in our everyday life, it is becoming increasingly clear that AI will be at the core of many of these. It is its flexibility that is so alluring, and its ability to mold itself to the vagaries of the real world that makes it so useful. Add to this the speed and power of modern computers and AI is a very formidable tool indeed.”
He poses that central challenge in these terms: “But how do you—efficiently—get that power onto a microchip?”1
Solution
Alexey Gokhberg, a software engineer based in Switzerland, has expertise in deep learning, high-performance computing, the construction of programming languages, and computational geophysics. Alexey has launched a project in coordination with Intel® DevMesh, known as Arhat2. His work involves developing techniques for delivering fast, efficient solutions for running deep learning in the cloud or at the network edge, optimized for the hardware architecture and devices included in each solution.
“The biggest technical challenge in my current projects,” Alexey said, “is building a lean solution for cross-platform deployment of DL models that eliminates the need for deploying cumbersome software stacks along with the user applications. I’ve approached this challenge by using automated code generation that produces lean, executable code implementing a specified DL workflow on a specified target platform.”
“Arhat is lean by design,” Alexey continued, “producing only the code necessary to run the solution. As a result, it runs fewer computation cycles, produces less heat, and requires less space. The leaner code incurs smaller deployment costs and is potentially more reliable. Since Arhat is integrally designed with the target hardware in mind, porting it rapidly to the correct chip is a design feature.”
Development Notes and Enabling Technologies
Reference Architecture
Arhat, a cross-platform, deep learning framework, is focused on Intel® hardware. It has been designed to interoperate with the oneAPI deep learning libraries, including the Intel® oneAPI Deep Neural Network Library (oneDNN) and the Intel® Distribution of OpenVINO™ toolkit. The reference architecture features an orchestration engine that builds platform-specific code for a range of replaceable back ends (Figure 1). External machine learning frameworks are routed through bridges that support open formats, including:
- NNEF – Neural Network Exchange Format reduces machine learning deployment fragmentation by enabling a rich mix of neural network training tools and inference engines to be used by applications across a diverse range of devices and platforms.
- ONNX* – Open Neural Network Exchange is an open format built to represent machine learning models and enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers.
- TF Lite – TensorFlow* Lite is an open source, deep learning framework for inference on multiple devices, such as mobile, desktops, and other edge systems.
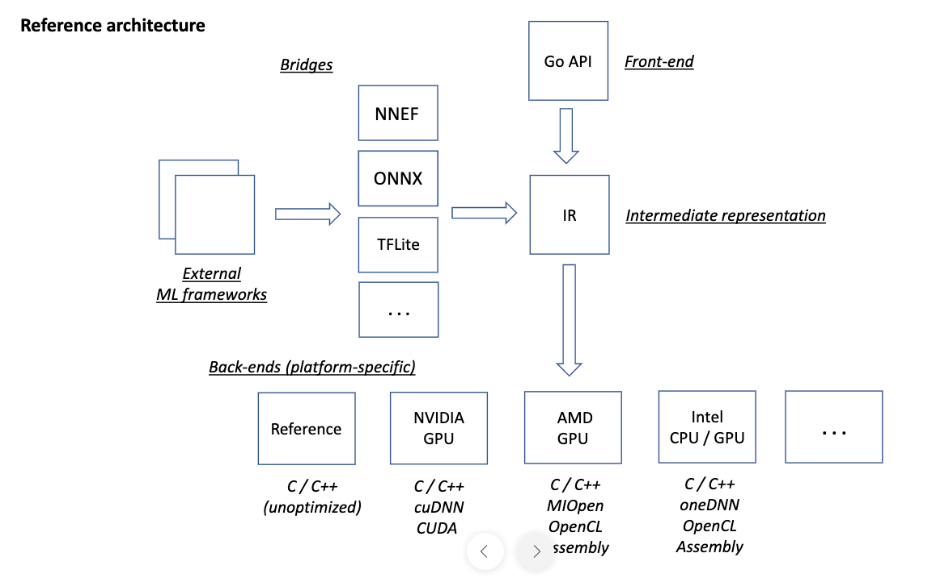
Figure 1. Arhat reference architecture
Models can be acquired from two different sources: a front-end API based on the Google Go* programming language provides a description of the model topology, and the bridges, set up for importing models into the Arhat network that can be generated by different external frameworks and parameters. The back ends are tailored to different platforms that can use exchanges on demand. The extensible architecture supports new formats and exchange formats that can be added as they are developed and introduced to the market.
The framework for Arhat is implemented in the Google Go programming language. Thin platform-specific runtime libraries required to run the generated code are implemented in C++. Arhat generates code that can be used on any modern Intel® computing hardware, including Intel® Xeon® CPUs and Intel® Iris® Xe MAX GPUs. Arhat relies on the oneDNN library for efficient cross-platform implementation of DL operations on Intel hardware.
Interoperability with OpenVINO™
Arhat includes the OpenVINO interoperability layer that consumes models produced by the Model Optimizer, enabling the use of Model Zoo for Intel® Architecture through Arhat. This approach integrates Arhat into Intel's deep learning ecosystem and opens a path for using Intel® tools for the native deployment of neural networks on third-party platforms. In particular, Arhat can deploy OpenVINO models on NVIDIA* GPUs using cuDNN and TensorRT inference libraries (Figure 2).
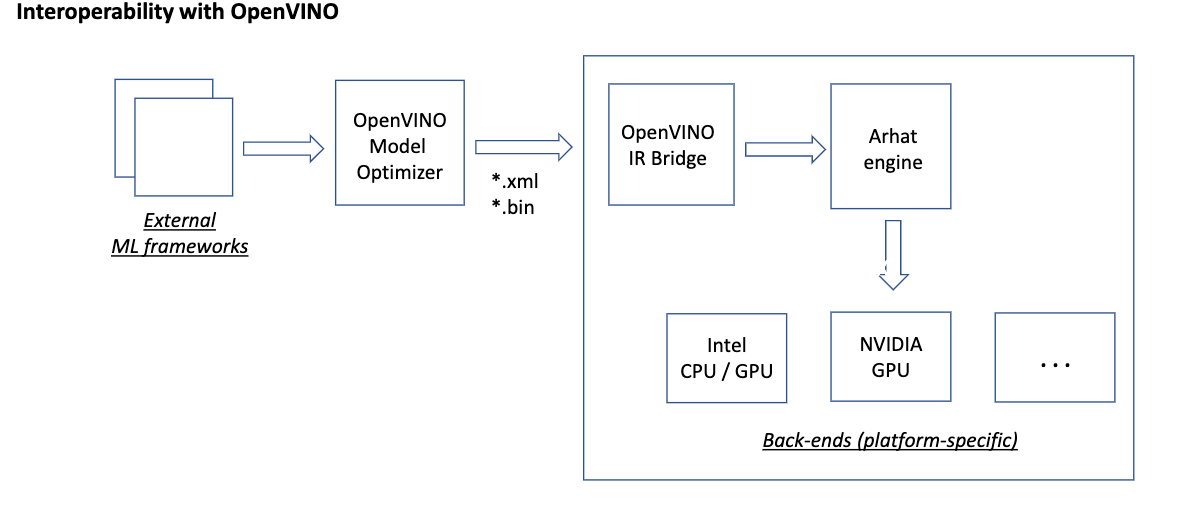
Figure 2. Interoperability with OpenVINO
“By implementing this component, Arhat can support all the exchange formats that are supported by the OpenVINO Model Optimizer,” Alexey said. “Beyond effectively integrating Arhat into the Intel DL ecosystem, this approach extends the capabilities of OpenVINO by allowing OpenVINO into all the platforms that are not otherwise supported.”
Benefits of Collaborating with Intel
Alexey noted these distinct benefits: “Intel has an excellent software engineering culture that pursues systematic software architecture design, transparent open source code, functional extensibility, and good documentation. There is an open and dynamic communication culture, including accessibility of Intel employees at various levels (up to directors and VPs) and lending support in networking within the company. This sets Intel apart from other companies.”
Next Steps
Alexey is taking steps to productize Arhat, and actively exploring consulting projects that combine deep learning with Arhat capabilities and take advantage of the oneAPI ecosystem to build efficient, small-footprint solutions for edge and cloud deployment. Sectors in which Arhat could prove extremely useful include computer vision and natural language processing.
Asked about the outcome and achievements of the project, Alexey replied: “Arhat can now be used for streamlined, on-demand benchmarking of models on various platforms. Using Arhat for performance evaluation eliminates overhead that might be caused by external DL frameworks because code generated by Arhat directly interacts with the optimized platform-specific DL libraries.”
The solution name, Arhat, is derived from the Sanskrit term signifying a being who has reached a high state of enlightenment and gained insight into the nature of existence. The artwork in Figure 3 was created by Utagawa Kuniyoshi in the 19th century and shows an Arhat with a tame tiger. The tiger can be viewed as an allegory for the complexity of the modern deep learning world.

Figure 3. Hattara Sonja with his white tiger. The original 1830 work was sourced from Wikimedia Commons; it is in the public domain.
{kind=link}

Figure 4. Alexey Gokhberg
Resources and Recommendations
- Gaechter, Richard. How to Pack the Power of AI into a Product: Arhat Redefines the Concept of Lean. LinkedIn.
- Intel DevMesh Project Page for Arhat
- Arhat SDK Preview Repository
Provides documentation, tutorials, and sample code. - Intel DevCloud
Get free access to code from home with cutting-edge Intel® CPUs, GPUs, FPGAs, and preinstalled Intel® oneAPI toolkits including tools, frameworks, and libraries. Register - Intel Distribution for OpenVINO Toolkit
Discover techniques for optimizing models for deep learning inference in embedded applications.