
Background
Utility companies need to manage and maintain the energy infrastructure for efficient and economical delivery of utilities. Maintaining the engineering integrity of their assets (power lines and utility poles) can be a challenge because engineering data is stored in documents, drawings, and models. This data can be structured, semi-structured, and unstructured, and most often paper based.
AI-powered intelligent document processing solutions provide data-driven insights of the assets, which can extend an asset's useful lifetime by several years, minimize service disruptions, and reduce operational costs.
Using AI technology to digitize engineering information is critical for utility companies to scale and maintain their infrastructure. This reference kit may assist you in developing a deep learning model to perform text extraction from scanned documents, such as those containing engineering-related details for utility company assets.
Solution
In collaboration with Accenture*, Intel developed this AI reference kit to extract text from images such as scanned documents. Paired with Intel® software, this kit may help utility companies identify text (for example, date, time, address, price, and dimensions) in engineering documentation that is image based. This reference kit includes:
- Training data
- An open source, trained model
- Libraries
- User guides
- Intel® AI software products
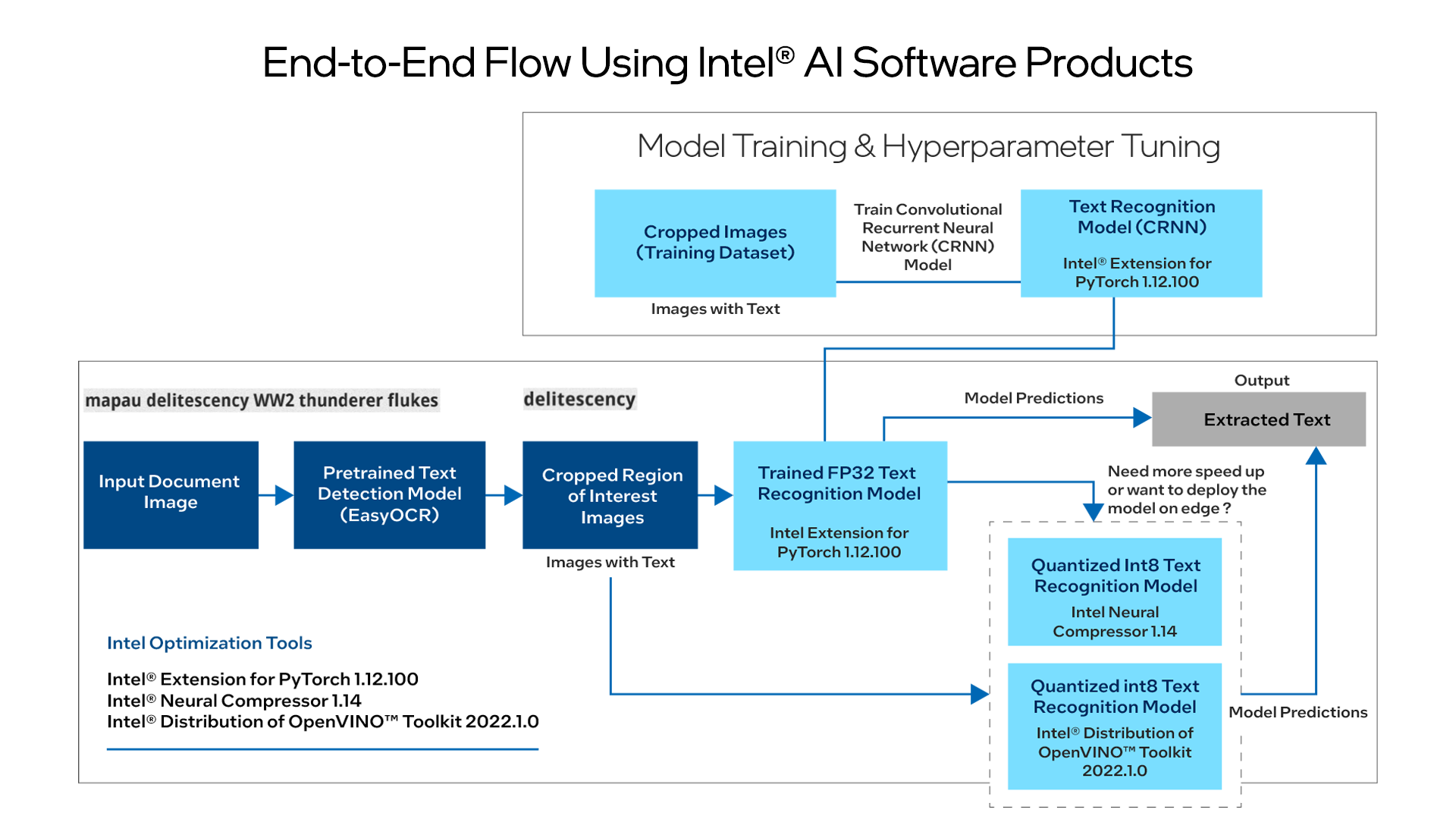
Intelligent document processing requires the processing of structured, semi-structured, and unstructured content in documents. This requires image preprocessing, analysis, text region detection and text extraction using OCR and named-entity recognition using natural language processing (NLP) techniques. OCR is used to automatically scan document images, identify the regions of interest (ROI) with text, and extract the different letters from the text detected.
The process is as follows:
- A document image is input and passed through any text detector (such as Keras OCR) to extract ROIs.
- The ROIs are then sent to the text extraction module (CRNN architecture) to accurately recognize entities such as date, time, location, or dimensions.
This reference kit may help with optimizing the extraction and detection of key information from a scanned document using the Intel® AI Analytics Toolkit (AI Kit).
At a Glance
- Industry: Energy and utilities
- Task: Extract text from images of words
- Dataset: Synthetic random words dataset (labelled images of words)
- Type of Learning: Supervised learning
- Models: Convolutional recurrent neural network (CRNN)
- Output: Text extracted from the image of a word
- Intel® AI Software Portfolio:
- AI Tools
- Intel® Optimization for PyTorch*
- Intel® Neural Compressor
- Intel® Distribution of OpenVINO™ Toolkit
Technology
Performance was tested on Microsoft Azure* Standard_D8_v5 using 3rd generation Intel® Xeon® processors to optimize the kit.
Benefits
To build a successful OCR text extraction solution using CRNN at scale, data scientists need to train models using substantial datasets and run inference more frequently. The ability to accelerate training allows data scientists to train more frequently and improve accuracy. A data scientist also reviews text extraction from documents and categorizes the results so that it can be better understood and analyzed. This task requires a lot of training and retraining, thus making the job tedious. Besides training, faster speed during inference allows the data scientists to run these models in real-time scenarios. This reference kit implementation provides performance-optimized guidance for named-entity OCR text extraction use cases, which can be scaled across similar use cases that require CRNNs.