Introducing a Novel Diffusion Architecture to Transform Text into Captivating 3D Content
Stable Diffusion* is rapidly transforming the field of computer vision with its ability to generate high-resolution photorealistic images from text. Introduced in 2022, Stable Diffusion is an open source diffusion model that uses the latent space, a lower-dimensional representation of an image, to more efficiently generate RGB images, graphics, and videos.
Intel's latest advancements, Latent Diffusion Model for 3D (LDM3D) and Latent Diffusion Model for 3D VR (LDM3D-VR), extend this capability further by generating images and depth maps from text prompts. With this technology, you can create vivid RGBD representations and immersive 360-degree views, as shown in Figure 1.
This article provides an overview of the different models in the LDM3D model suite and its virtual reality counterpart, LDM3D-VR. In addition, it demonstrates how you can implement these models and generate your own creative visual graphics on high-performance CPUs, like the Intel® Core™ Ultra processor on your AI PC.
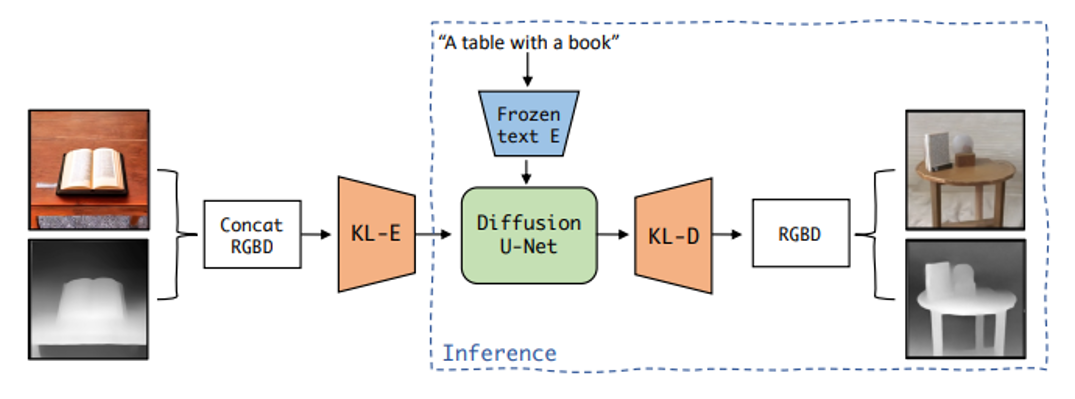
Figure 1. Overview of the LDM3D model architecture.
LDM3D
LDM3D is a state-of-the-art diffusion model with 1.6 billion parameters, derived from Stable Diffusion v1.4 but tailored to generate images and depth maps concurrently from textual input. It employs a variational autoencoder (VAE) architecture with KL divergence loss, modified for efficient text conditioning by adjusting key Conv2D layers to accommodate concatenated RGB images and depth maps.
The model's generative diffusion component uses a U-Net backbone architecture predominantly comprising 2D convolutional layers. Trained on a low-dimensional KL-regularized latent space, it enables more precise reconstructions and efficient high-resolution synthesis compared to transformer-based models operating in pixel space.
Text conditioning is facilitated by a frozen CLIP-text encoder, with encoded text prompts mapped across various U-Net layers using cross-attention. This approach adeptly handles complex natural language prompts, yielding high-quality image and depth map outputs in a single pass, with only a slight increase of 9,600 parameters compared to the original Stable Diffusion model.
The model was fine-tuned using a subset of the LAION-400M dataset, comprising image-caption pairs. Depth maps, essential for fine-tuning the LDM3D model, were generated by the DPT-Large depth estimation model at a resolution of 384 × 384. These maps were converted into three-channel RGB-like arrays to match the input requirements of the Stable Diffusion model. This conversion involved unpacking the 16-bit depth data into three 8-bit channels, with one channel typically zero for 16-bit depth data but structured for compatibility with potential 24-bit depth maps.
Normalization of both original RGB images and generated RGB-like depth maps was done to constrain values within the [0, 1] range. Concatenating these normalized RGB images and RGB-like depth maps along the channel dimension resulted in an input image size of 512 x 512 x 6. This concatenated input facilitated the LDM3D model in learning a joint representation of RGB images and depth maps, improving its capability to produce immersive and compelling RGBD outputs.
The model was built using the PyTorch* framework and can be loaded with the Hugging Face* diffusers library. The following code demonstrates how to use this model to generate the RGBD features of an input prompt on a CPU:
from diffusers import StableDiffusionLDM3DPipeline
pipe = StableDiffusionLDM3DPipeline.from_pretrained("Intel/ldm3d")
pipe.to("cpu")
prompt = "A picture of lemons on a table"
name = "Lemons"
output = pipe(prompt)
rgb_image, depth_image = output.rgb, output.depth
rgb_image[0].save(name+"_ldm3d_rgb.jpg")
depth_image[0].save(name+"_ldm3d_depth.png")
Here are the results:

Figure 2. RGB Image and depth map generated by the LDM3D.
For further details about this model and how to use it on other architectures, see the LDM3D Model Card on Hugging Face.
LDM3D-4C
A new checkpoint called LDM3D-4C was developed by enhancing the LDM3D architecture to incorporate depth as a channel alongside RGB. This modification involves adapting the initial and final Conv2D layers of the KL autoencoder to handle a four-channel input (RGB combined with a depth map). These changes enable the LDM3D-4C model to generate better-quality RGBD images than its predecessor.
To generate the RGBD features of a text prompt using the LDM3D-4C on a CPU, you can use the following code:
from diffusers import StableDiffusionLDM3DPipeline
pipe = StableDiffusionLDM3DPipeline.from_pretrained("Intel/ldm3d-4c")
pipe.to("cpu")
prompt = "A picture of lemons on a table"
name = "Lemons"
output = pipe(prompt)
rgb_image, depth_image = output.rgb, output.depth
rgb_image[0].save(name+"_ldm3d_4c_rgb.jpg")
depth_image[0].save(name+"_ldm3d_4c_depth.png")
Below are the results:

Figure 3. RGB Image and Depth Map generated by the LDM3D-4C.
For further details about this model and how to use it on other architectures, please see the LDM3D-4C Model Card on Hugging Face.
LDM3D-Pano
Designed for panoramic image generation, LDM3D-Pano was introduced as part of the LDM3D-VR suite, a dual set of models for virtual reality development. Expanding upon the original framework, the LDM3D-Pano employs a two-stage fine-tuning process. Initially, the refined version of the LDM3D-4c KL autoencoder is fine-tuned using approximately 10,000 samples sourced from the LAION-400M dataset with depth map labels generated by DPT-BEiT-L-512. Subsequently, the U-Net backbone undergoes fine-tuning based on Stable Diffusion v1.5, using nearly 20,000 tuples from the LAION Aesthetics 6+ subset, which includes captions, images, and depth maps produced using DPT-BEiT-L-512.
The following code demonstrates how to use this model to generate a panoramic RGB image from a text input prompt on a CPU:
from diffusers import StableDiffusionLDM3DPipeline
pipe = StableDiffusionLDM3DPipeline.from_pretrained("Intel/ldm3d-pano")
pipe.to("cpu")
prompt = "360 view of a large bedroom"
name = "bedroom_pano"
output = pipe(
prompt,
width=1024,
height=512,
guidance_scale=7.0,
num_inference_steps=50)
rgb_image, depth_image = output.rgb, output.depth
rgb_image[0].save(name+"_ldm3d_pano_rgb.jpg")
depth_image[0].save(name+"_ldm3d_pano_depth.png")
Here are the results:

Figure 4. RGB Image and depth map generated by the LDM3D-Pano.
For further details about this model and how to use it on other architectures, see the LDM3D-Pano Model Card on Hugging Face. You can also try out this model on the LDM3D-Pano Hugging Face Space.
LDM3D-SR
The LDM3D-SR focuses on super-resolution (SR) using the KL-AE developed for LDM3D-4c to encode low-resolution (LR) images into a 64 x 64 x 4 dimensional latent space. The diffusion model used is an adapted version of the U-Net with an 8-channel input, allowing conditioning on LR latent during training and on noise during inference. Text conditioning is enabled through cross attention with a CLIP text encoder. The U-Net in LDM3D-SR is fine-tuned from sd-superres, using high-resolution (HR) and LR sets with 261,045 samples each. HR samples are from a subset of LAION Aesthetics 6+ with tuples (captions, 512 x 512-sized images, and depth maps from DPT-BEiT-L-512). LR images are generated using a lightweight BSR-image-degradation method. Three methods are explored for generating LR depth maps: depth estimation on LR depth maps (LDM3D-SR-D), using the original HR depth map for LR conditioning (LDM3D-SR-O), and applying bicubic degradation to the depth map (LDM3D-SR-B).
Here are the upscaled RGB and depth map generated by the LDM3D-SR:

Figure 5a. Upscaled RBD image generated by the LDM3D-SR

Figure 5b. Upscaled depth map generated by the LDM3D-SR
For further details about this model, see the LDM3D-SR Model Card on Hugging Face.
Next Steps
- Learn more about the LDM3D, LDM3D-4C, LDM3D-Pano, and LDM3D-SR models on Hugging Face.
- Try out the LDM3D-Pano on the LDM3D-Pano Hugging Face Space.
- Read the complete papers on the LDM3D and the LDM3D-VR.
- Chat with us on the Intel® DevHub on Discord* server to keep interacting with fellow developers.
We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of the Intel® AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
References
Gabriela Ben Melech Stan, Diana Wofk, Estelle Aflalo, Shao-Yen Tseng, Zhipeng Cai, Michael Paulitsch, and Vasudev Lal, "LDM3D: Latent Diffusion Model for 3D VR," arXiv:2311.03226 (2023).
Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, and Vasudev Lal, "LDM3D: Latent Diffusion Model for 3D," arXiv:2305.10853, (2023).