Introduction
This guide is for users who are already familiar with LAMMPS. It provides recommendations for configuring hardware and software that will provide the best performance in most situations. However, please note that we rely on the users to carefully consider these settings for their specific scenarios, since LAMMPS can be deployed in multiple ways.
LAMMPS is open-source code for classical molecular dynamics simulation with a focus on materials modeling. The acronym stands for Large-scale Atomic/Molecular Massively Parallel Simulator. LAMMPS is used to simulate the physical movements of atoms and molecules. [1] There are many computations required to create these simulations, so LAMMPS was designed to run efficiently on parallel computers to speed up the calculations while maintaining accurate results. Read the official LAMMPS documentation for more details. The Intel package for LAMMPS provides methods for accelerating simulations using Intel® processors. This guide specifically addresses recommendations for tuning 3rd generation Intel® Xeon® scalable processors.
3rd generation Intel Xeon Scalable processors deliver industry-leading, workload-optimized platforms with built-in AI acceleration, providing a seamless performance foundation to help speed data’s transformative impact, from the multi-cloud to the intelligent edge and back. Improvements of particular interest when using LAMMPS include:
- Enhanced Performance
- More Intel® Ultra Path Interconnect
- Intel® Advanced Vector Extensions
Tested hardware and software environment for this tuning guide:
Server Configuration
Hardware
The configuration described in this article is based on 3rd generation Intel Xeon processor hardware. The server platform, memory, hard drives, and network interface cards can be determined according to your usage requirements.
| Hardware | Model |
|---|---|
| Server Platform Name/Brand/Model | Intel® Server M50CYP Family |
| CPU | Intel® Xeon® Platinum 8360Y processor at 2.20GHz |
| BIOS | SE5C6200.86B.0021.D40.2101090208 |
| Memory | 256GB 16*16GB 3200MT/s DDR4, Hynix HMA82GR7CJR8N-XN |
| Storage/Disks | SSDSC2KG96 960GB |
Software
| Software | Version |
|---|---|
| Operating System | CentOS* for Linux* release 8.3.2011 |
| Kernel | 4.18.0-240.22.1.el83.crt1.x8664 |
| LAMMPS | 29Oct2020 |
Tuning Hardware
BIOS Settings
Reset BIOS to the default settings, then follow these suggestions:
| Setting | Recommendation |
|---|---|
| Advanced/Power & Performance/CPU P State Control/CPU P State Control/Intel® Turbo Boost Technology | Enabled |
| Advanced/Processor Configuration/Intel® Hyper-Threading Tech | Enabled |
| SNC (Sub-Numa Cluster) | Enabled |
Description of BIOS Settings
Enable these settings to optimize the performance of LAMMPS:
- lntel® Turbo Boost Technology allows the processor to automatically increase its frequency if it is running below the current power or temperature specifications.
- lntel® Hyper-Threading Technology allows multithreaded software applications to execute two threads in parallel within each processor core. This results in being able to run threads on twice as many logical cores as physical cores.
- SNC (Sub-Numa Cluster) advances the Cluster-on-Die (COD) option that was available in Intel® Xeon® E5-2600 processors v3 and v4 by improving remote socket access when using 3rd generation Intel® Xeon® Scalable processors. At the operating system level, a dual socket server with SNC enabled will display four NUMA domains. Two of the domains will be on the same socket and the other two will be across the UPI to the remote socket. SNC should be enabled to attain better performance.
Memory Configuration/Settings
Typically, users scale to multiple nodes so the memory footprint per node may be smaller.
Storage/Disk Configuration/Settings
We highly recommend using an SSD as the primary drive for your operating system and LAMMPS installation so that I/O does not become a bottleneck. We also recommend using a larger secondary SSD for storage of past projects especially if you are using VMD to create videos, animations, or movies of your simulations.
Network Configuration/Settings
The best LAMMPS performance has been observed when the data sets are processed on multiple nodes using Intel® MPI Library, a popular library for parallelization in HPC.
Tuning LAMMPS Software
Software configuration tuning is essential because the default settings on all software, from the operating system to LAMMPS, are designed for general purpose applications. It is important to tune the LAMMPS settings in order to achieve the best performance on your system.
Linux* Kernel Optimization Settings CentOS* 8.
(No specific workload setting)
LAMMPS Architecture
LAMMPS supports many different simulation models. The following diagram shows an example timestep for molecular systems with long-range electrostatics:
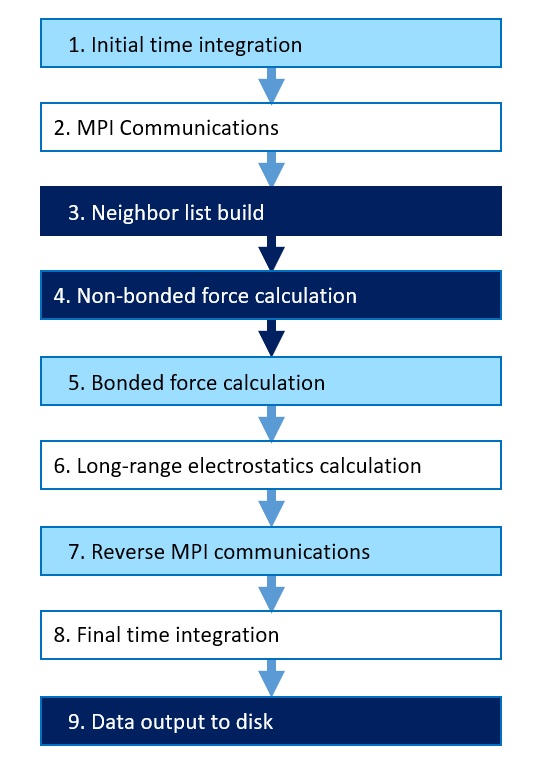
Figure 1: Example timestep for molecular systems with long-range electrostatics
Typically, steps 3 Neighbor list build, 9 Data output to disk, and optionally 6 Long-range electrostatics calculation, don’t happen every timestep.
The “newton off” setting referred to in Section 3.5 eliminates step 7, Reverse MPI communications, in trade for increased computation. The LRT setting also referred to in Section 3.5 runs step 6, Long-range electrostatics calculation, on a separate hyperthread in parallel with steps 4, Non-bonded force calculation, and 5, Bonded force calculation. This can improve performance.
Building LAMMPS with Optimizations for Intel® Processors
The INTEL package for LAMMPS is included in the official source code, but the package must be installed at build time along with other packages that will be used in LAMMPS simulations. The INTEL package can speed up simulations running on Intel® processors.
Download LAMMPS from this Git repository. There are also additional downloading instructions at that site.
git clone -b stable https://github.com/lammps/lammps.git lammps
To install the Intel package:
cd lammps/src
make yes-intel
To build with Intel oneAPI (complier and linker settings are in the src/MAKE/OPTIONS/Makefile.intel_cpu_intelmpi file):
source /opt/intel/oneapi/setvars.sh
make intel_cpu_intelmpi -j
After compiling an lmp_intel_cpu_intelmpi binary will be created.
Executing LAMMPS
The simplest way to take advantage of the Intel package optimizations is to add the -sf intel switch to the LAMMPS command line. This will automatically use any optimizations available for the simulation. The number of OpenMP* threads used can be controlled with either the OMP_NUM_THREADS environment variable or by adding:
-pk intel 0 omp $N” for N OpenMP threads.
mpirun -np 72 -ppn 36 lmp_intel_cpu_intelmpi -sf intel -in in.script
# 2 nodes, 36 MPI tasks/node, $OMP_NUM_THREADS OpenMP Threads
mpirun -np 72 -ppn 36 lmp_intel_cpu_intelmpi -sf intel -in in.script -pk intel 0 omp 2 mode double
# Use 2 OpenMP threads for each MPI task, use double precision
Tuning for Performance
LAMMPS typically performs best when running one MPI* task per physical core and often performs better with two OpenMP threads to take advantage of hyperthreading on the core.
Newton
Changing the newton setting to “off” can improve performance and/or scalability for simple 2-body potentials such as lj/cut. It can also improve performance when using LRT mode on processors supporting AVX-512.
LRT
Long-Range Thread (LRT) mode is an option in the Intel package for LAMMPS that can improve performance when using PPPM for long-range electrostatics on processors with hyperthreading. It generates an extra pthread for each MPI task. The thread is dedicated to performing some of the PPPM calculations and the MPI communications. This feature requires setting the pre-processor flag -DLMPINTELUSELRT in the makefile when compiling LAMMPS (default for Makefile.intelcpuintelmpi).
When using LRT, set the environment variable “KMP_AFFINITY=none”.
To enable LRT mode, specify that the number of OpenMP threads to be one less than would normally be used for the run. Then, add the “lrt yes” option:
Running without LRT mode: -pk intel 0 omp 4
Running with LRT mode: -pk intel 0 omp 3 lrt yes
Running Standard LAMMPS Benchmarks
Benchmarks covering a variety of different simulation models are included with LAMMPS. The following steps will run benchmarks for 1) an atomic fluid, 2) a protein, 3) copper with the embedded-atom method, 4) dissipative particle dynamics, 5) polyethylene with the AIREBO force-field, 6) silicon with 3-body Tersoff model, 7) silicon with 3-body Stillinger-Weber potential, 8) coarse grain water using a 3-body potential, and 9) a liquid crystal simulation.
To run the benchmarks, the following packages must be installed for LAMMPS before building:
make yes-asphere yes-class2 yes-dpd-basic yes-kspace yes-manybody yes-misc yes-molecule yes-mpiio yes-opt yes-replica yes-rigid yes-intel
Switch the benchmark directory:
cd lammps/src/INTEL/TEST
Set PCORES to be the number of physical cores on the system and run the benchmarks (summary performance numbers – higher is better - from the log files reporting timesteps/sec is printed at the end):
PCORES=`lscpu | awk '$1=="Core(s)"{t=NF; cores=$t}$1=="Socket(s):"{t=NF; sockets=$t}END{print cores*sockets}'`;
sed -i "s/36/$PCORES/g" run_benchmarks.sh; sed -i 's/"2"/"1 2"/g' run_benchmarks.sh
./run_benchmarks.sh
Download, Build, and Benchmark with a Single Line
On some systems with standard oneAPI installations, the following single line will follow the steps in this document to download, build, and benchmark with LAMMPS (modifications may be needed for some configurations):
source /opt/intel/oneapi/setvars.sh; git clone -b stable https://github.com/lammps/lammps.git lammps; cd lammps/src; make yes-asphere yes-class2 yes-dpd-basic yes-kspace yes-manybody yes-misc yes-molecule yes-mpiio yes-opt yes-replica yes-rigid yes-openmp yes-intel; make intel_cpu_intelmpi -j; cd INTEL/TEST; PCORES=`lscpu | awk '$1=="Core(s)"{t=NF; cores=$t}$1=="Socket(s):"{t=NF;
sockets=$t}END{print cores*sockets}'`; sed -i "s/36/$PCORES/g" run_benchmarks.sh; sed -i
's/"2"/"1 2"/g' run_benchmarks.sh; ./run_benchmarks.sh
Best Practices for Testing and Verification
(No specific workload setting)
Conclusion
LAMMPS includes optimizations for Intel® AVX-512 on Intel Xeon Scalable Processors that can significantly speed up simulations. These optimizations must be enabled with appropriate build and run options as described in this document.
References
[1] Molecular Dynamics as of August 23, 2021
[2] LAMMPS documentation as of August 23, 2021
Notices & Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not "commercial" names and not intended to function as trademarks
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.