About the Decision Guide
This document provides guidance to determine if Intel® Optane™ persistent memory (PMem) in the memory mode can benefit the user workload. The document describes how to analyze telemetry and topology data of a workload on a DRAM-only system to identify if the system can benefit from the affordable cost and high capacity of PMem.
The guidance is largely agnostic of a tool or platform. It intends to present a growing list of use cases that are neither exclusive nor exhaustive. However, some metrics are only available through specific tools and platforms. They are indicated accordingly in Appendix B.
This article enumerates different situations under which PMem can be helpful for you. Each of these opportunities of benefiting from PMem are listed in this document as a scenario. Each scenario contains the high-level description, the potential value proposition and the steps to identify the scenario using the data from a DRAM-only workload run.
The use of this document requires some familiarity with PMem. You can get an overview of PMem technology on the Intel Optane Persistent Memory Page. The knowledge of persistent memory programming is not required to understand and apply the methodology defined in this document.
The efficiency of the analysis is not strictly governed solely by the metrics described in this document. Equivalent metrics that capture the same workload characteristics also can be used. For a comprehensive list of relevant metrics and their definitions, see Appendix A.
Evaluating PMem Benefits for Your Workload
PMem in the memory mode provides you with a cost-effective solution with a large byte-addressable main memory. Configured for the memory mode, an operating system and supported applications perceive a pool of volatile memory, not differing from the available memory on a DRAM-only system. The difference in the PMem Memory Mode is that PMem provides the main memory while the DRAM acts as a cache for the accessed frequently data.
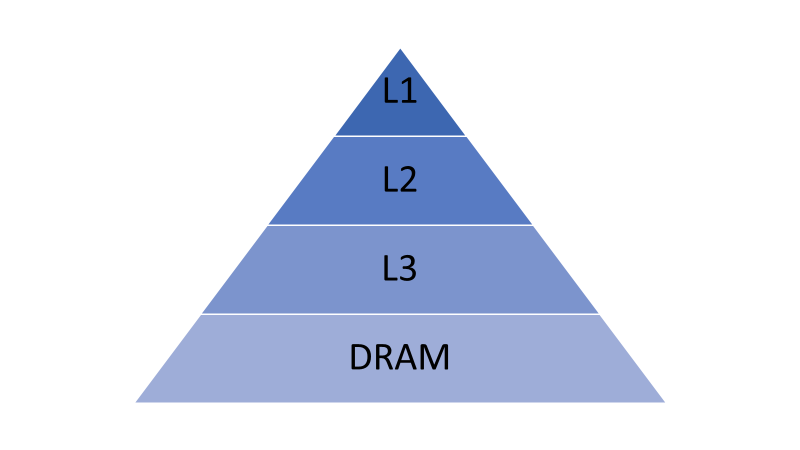
Figure 1 illustrates the memory hierarchy of a DRAM-only system. Elements that are faster, costlier, and smaller are at the top of the pyramid (L1 Cache) and sit closer to the core. Lower levels provide larger sizes and are less expensive, but slower.
PMem extends the memory hierarchy by adding another level below the DRAM (Figure 2). In the new hierarchy, PMem becomes the main addressable memory and the DRAM acts as a near memory cache for PMem.
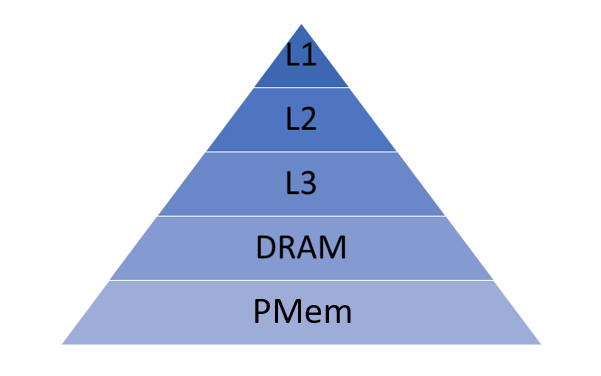
PMem enables you to build systems with large memory less expensive than DRAM-only systems. However, PMem has a relatively higher latency and a lower bandwidth. Using the DRAM as a cache allows the system to compensate for these deficits.PMem modules are available in 128GB, 256GB and 512GB capacities.
The performance of a workload on PMem memory mode is dependent on the memory access characteristics of the workload. There are scenarios where PMem can improve performance or provide a good tradeoff between system performance and its total cost of ownership (TCO). Some of these scenarios are:
- Workload performance is limited by the size of the addressable memory.
- Workload scalability depends on the availability of additional addressable memory.
- Workload performance is negligibly impacted when DRAM is replaced with less expensive PMem.
PMem Enabling Workflow
Use the following workflow to determine whether your workload can benefit from PMem in Memory Mode:
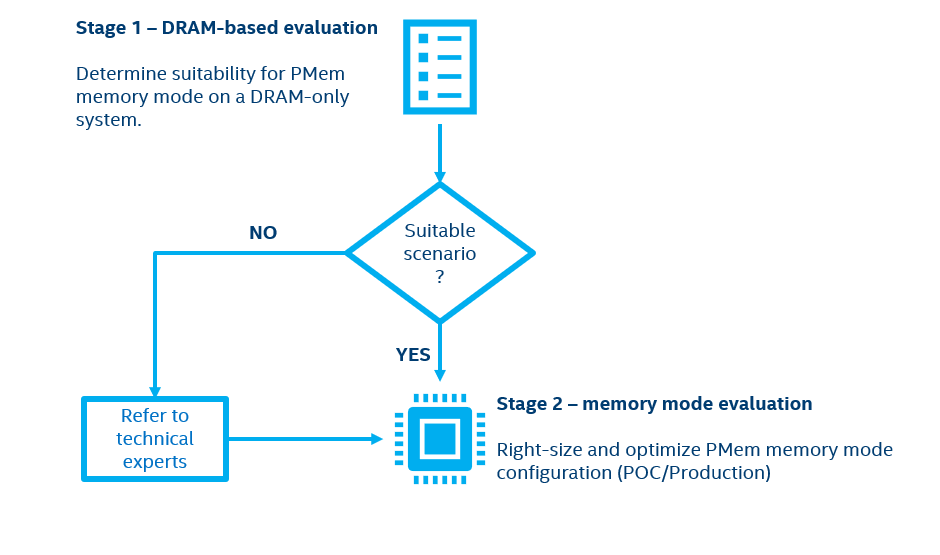
In the general workflow you need to perform the following steps:
1. Run a workload on your DRAM-only system.
2. Collect the metrics required for analysis.
3. Use the collected metrics to decide if the workload fits one or more of the scenarios where PMem in the memory mode can provide benefits.
NOTE: If the workload does not match any scenario, consult the Intel team.
4. Evaluate the performance characteristics of a system with PMem in the memory mode for each scenario that matches with the workload to determine the optimal system configuration.
NOTE: This guide focuses on steps 1-3 only. To complete step 4, contact the Intel team.
Caution: To determine optimal system configuration, you must characterize workloads for a target system in PMem in the memory mode. Without characterization, applications with consistent data retrieval patterns (that the memory controller can predict) are likely to have a higher cache hit rate as well as performance close to DRAM-only configurations. Similarly, workloads with highly random data access over a wide address range can show some performance difference versus the DRAM alone.
Structure of a Scenario
This guide describes typical workload scenarios that can benefit from PMem in the memory mode. Each scenario contains:
| Section | Description |
|---|---|
| Description | A description of the scenario and relevant workloads. |
| Potential Benefit | The potential benefit obtained by introducing PMem in memory mode in this scenario. |
| Requierd Metrics | Applicable performance metrics that can help evaluate whether a workload fits the scenario. |
| Evaluation | Instructions to evaluate the workload for the scenario. |
| Recommendations for Memory Mode Evaluation | High-level guidelines for an optimal PMem memory mode configuration. |
Scenario Evaluation Guidelines
Each scenario has an evaluation table with each row presenting a criterion. Review the criterion in the table, mark Yes if your workload meets the criterion, or No otherwise.

|
Value in range |
Evaluation |
Result |
|---|---|---|
| Green | Satisfied criterion. | YES |
| Yellow | Partially satisfied criterion. |
YES (Must complete memory mode evaluation to confirm) |
| Red | Does not satisfy the criterion. | NO |
NOTE: All conditions should be met throughout the entire program execution. Pay attention to “spikes” that cross the recommended thresholds for each metrics. Spike in metric values that violate the recommended threshold may lead to corresponding spikes in workload performance drops. These workload performance drop spikes might lead to violation of SLA.
Scenario for Memory Capacity Bound Applications - Single Node
In this scenario, your workload performance is taking a hit due to the limited size of addressable memory. Modifying your memory configuration to get additional memory capacity has the potential to improve workload performance.
The application is using all the available memory while showing a high disk or paging activity. The application is not bound by memory bandwidth or CPU saturation. This is an indicator that the application is bound by the capacity of the memory. Consider using the Memory Mode to increase memory capacity.
This scenario is less common in datacenter workloads as server admins usually make sure that the application has access to enough addressable memory.
Potential Benefit
Increase the performance of a single node.
Required Metrics
- System Configuration: Total Memory Size.
- Memory utilization.
- CPU utilization.
- CPU utilization in Kernel Mode.
- Major page faults.
- Storage throughput/IOPS.
- Maximum achievable DRAM bandwidth.
- Actual DRAM throughput (read and write).
- CPU I/O Wait (see Appendix B).
Evaluation
| Criterion |
Condition(s) |
Result |
| Workload is using all available memory and excess memory paged to the disk |
|
YES / NO |
| Memory paging negatively affects the CPU utilization and a memory throughput |
|
YES / NO |
If all steps are marked as Yes, your workload performance is bound by the capacity of available memory and will likely perform better if you increase the amount of available memory. Since the workload performance is not sensitive to the memory throughput, you can increase addressable memory using PMem Memory Mode to avoid swapping and achieve additional performance at an affordable cost.
If any of the above steps are marked as No, your workload performance is not strictly bound by the memory capacity. Therefore, increasing memory capacity may not necessarily improve performance. In this case, consider analyzing for scenarios 3 and 4.
Recommendations for the Memory Mode Evaluation
The memory mode system should be designed to satisfy the following criteria:
- The size of PMem should be larger than or equal to the addressable memory requirements of the workload which means that swapping to disk should not happen.
- The size of the near memory cache (DRAM) should be larger than the working set size of the workload.
Examples
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| Workload is using all available memory and excess memory paged to the disk |
|
YES |
| Memory paging negatively affects the CPU utilization and the memory throughput |

 |
YES |



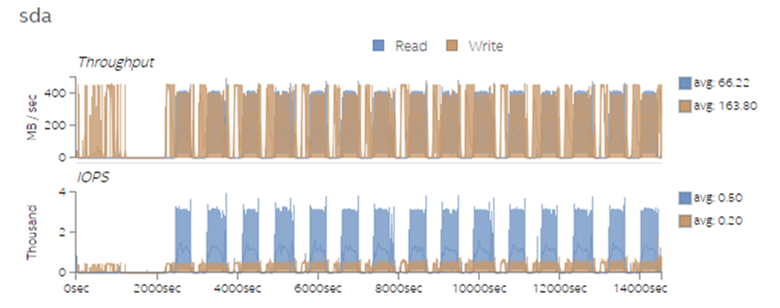
The workload where performance is bound by the memory capacity will likely benefit from the large and affordable memory capacity of PMem in the memory mode.
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| Workload is using all available memory and excess memory paged to the disk |
|
YES |
| Memory paging negatively affects the CPU utilization and the memory throughput |
 |
NO |



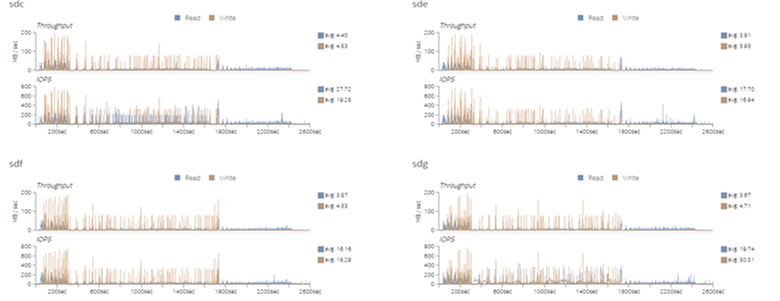
The high CPU utilization implies that the workload performance is not affected by the swapping going on due to the memory capacity limitation.
Scenario For Memory Capacity Bound Distributed Applications
In this scenario, you have an application that needs to process a large amount of data. The workload is distrusted across multiple worker nodes in a cluster such that the amount of data to be processed by each worker node fits entirely within the physical memory of the node. The number of nodes required for the workload depends on the total data and the size of memory available per node. There is a potential to decrease the number of nodes required for the workload by increasing the amount of per-node memory using Pmem in the memory mode. The use case finds out if the given workload is suitable for decreasing the number of required nodes by increasing the size of the workload chunk assigned to each node.
Potential Benefit
Node consolidation, reduce total cost of ownership
Required Metrics
- System Configuration: Total Memory Size.
- System Configuration: size and type of DRAM memory modules (DIMMs).
- Total in-memory data size across all nodes.
- Maximum memory footprint the application can allocate on a single node.
- Memory utilization.
- Percentage of processor pipeline stalls attributed to memory demand (Memory Bound (%)).
- Percentage of processor pipeline stalls attributed to the core (Core Bound (%)).
- CPU utilization.
- Storage throughput, IOPS and queue depth.
- Actual DRAM throughput (read and write).
Evaluation
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| General requirements | The amount of memory available on each worker node is the only factor limiting the size/chunk of work assigned to this node. | YES / NO |
| Worker node has headroom in Compute |
CPU utilization satisfies criterion:
Core_Bound(%) satisfies criterion if CPU utilization is above 90%: |
YES / NO |
| Worker node has headroom in Memory BW/Latency |
Memory_Bound(%) satisfies the criterion:
AND Write Bandwidth Ratio (DRAM write BW/DRAM total BW) satisfies the criterion:
|
YES / NO |
| Worker node has headroom in Network and Storage | Network utilization is less than 80%. Queue depth is less than 500. IOPS and throughput is less than 80% of the manufacturer’s specification. | YES / NO |
|
Overall workload performance can be somewhat reduced without violating key performance indicators (KPI) or service level agreement (SLA) |
It is OK for you to reduce the overall workload performance by 5% without violating the expected application’s KPI or SLA. | YES / NO |




If all steps are marked as Yes, you can increase the chunk of work assigned to each node by increasing the amount of available memory on the node. This will enable to either reduce the total number of workers nodes or increase the amount of data the application can process. Since the performance of each worker node is not highly sensitive to the memory throughput, using PMem Memory Mode is likely to provide an adequate performance at an affordable cost.
Recommendations for the Memory Mode Evaluation
The memory mode system should be designed to satisfy the following criteria:
- The size of the near memory cache (DRAM) should be larger than a “projected” working set size of the workload.
- All memory channels should be populated to maximize the available memory bandwidth.
Scenario for Applications with Large Memory Footprint and Small Working Set Size
In this scenario, you have an application that requires a large size main memory. Though the memory size requirements of the workload are high, it frequently operates on a comparatively smaller size of data. Such a workload can benefit from PMem in memory mode, where the application footprint (all data) resides in a PMem-based main memory while the smaller hot data fits in the DRAM cache. The workload footprint determines the PMem memory size requirements.
Workload footprint can also be derived from memory utilization of the workload on the system.
The hot data size of the application is measured by the working set size of the workload.
A special case related to this scenario is when your system is configured with high-capacity LRDIMM memory modules. LRDIMMs have higher latency and are more expensive than RDIMMs, which have limited capacity and are available in 8GB, 32GB and 64GB modules.
If the footprint of your workload is large enough to require LRDIMMs, but the working set size can fit in a near memory cache that is configured with RDIMMs, consider using a combination of PMem and RDIMMs instead.
Potential Benefit
Decreasing the cost of a single node.
Required Metrics
- System Configuration: Total size of available memory.
- System Configuration: Memory topology and module placement.
- System Configuration: Size and type of DRAM memory modules (DIMMs).
- Workload footprint or memory utilization. (footprint = memory utilization (%) * memory size / 100).
- Working set size of the workload (size of hot/frequently accessed data).
Evaluation
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| Workload has a large footprint |
|
YES / NO |
| Workload working set size can fit into a smaller near memory cache |
|
YES / NO |
Recommendations for the Memory Mode Evaluation
The memory mode system should be designed to satisfy the following criteria:
- The size of addressable memory (PMem) should be comparable to the size of the addressable memory of the DRAM-only system.
- The size of the near memory cache (DRAM) should be larger than the working set size of the workload.
Example
The workload is run on a system with 1.5GB memory, 64GBx24 DRAM memory modules, populating 12 channels with 2 memory modules slots per channel.
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| Workload has a large footprint |
|
YES |
| Workload working set size can fit into a smaller near memory cache |
|
YES |
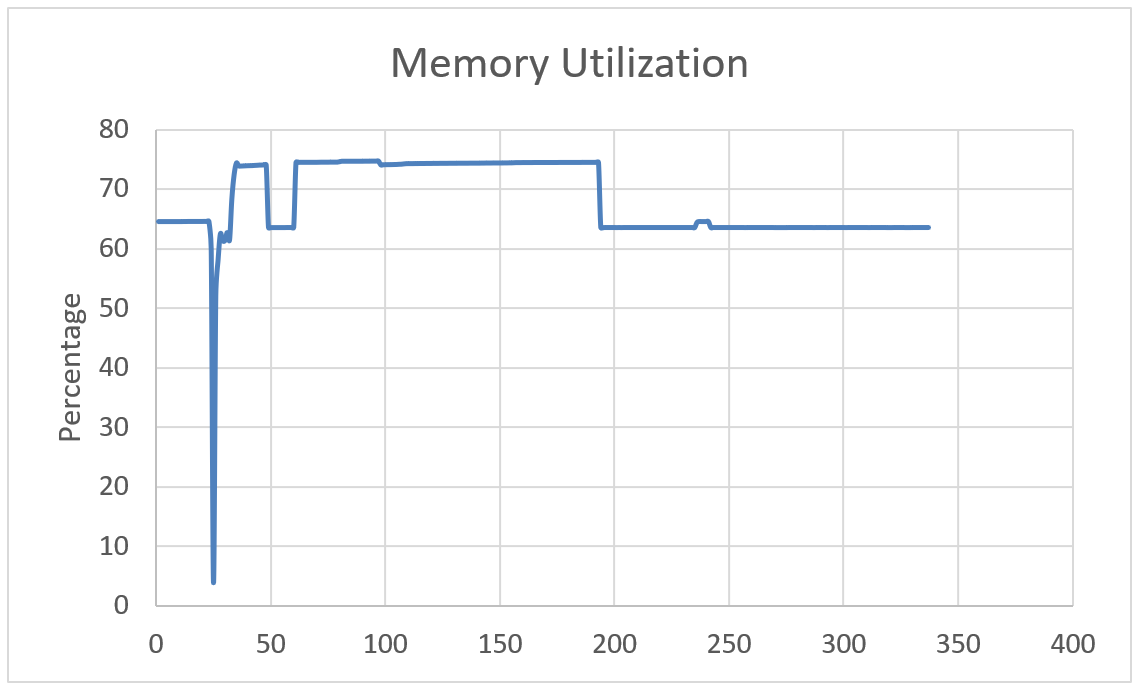
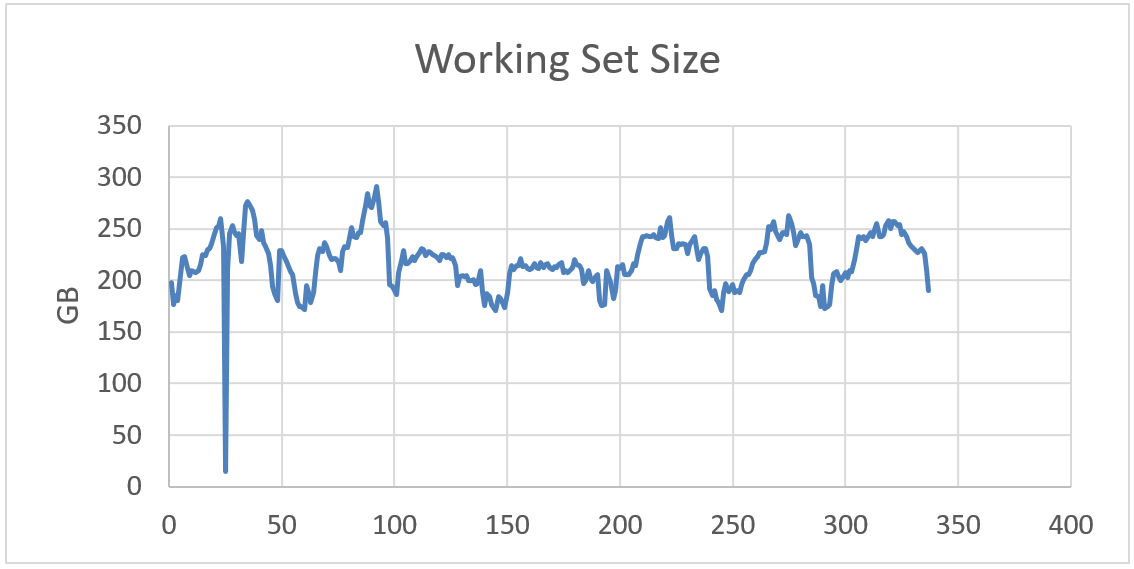
Scenario For Applications Less Sensitive To Memory Bandwidth and Latency
In this scenario, the memory bandwidth or latency do not limit workload performance. Therefore, switching to PMem for the main memory will not have a significant impact on performance.
Potential Benefits
Decreasing the cost of a single node.
Required Metrics
- System Configuration: Total size of available memory.
- System Configuration: Memory topology and module placement.
- System Configuration: Size and type of DRAM memory modules (DIMMs).
- Workload footprint or memory utilization (footprint = memory utilization (%) * size of memory / 100).
- Working set size of the workload (size of hot/frequently accessed data).
- Percentage of processor pipeline stalls attributed to memory demand (Memory Bound (%)).
- Actual DRAM throughput (read and write).
Evaluation
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| Workload is not Memory BW/Latency bound |
Memory_Bound(%) satisfies criterion:
AND Write Bandwidth Ratio (DRAM write BW/DRAM total BW) satisfies criterion:
|
YES / NO |


Recommendations for the Memory Mode Evaluation
The memory mode system should be designed to satisfy the following criteria:
- The size of addressable memory (PMem) should be comparable to the size of the addressable memory of the DRAM-only system.
- The size of the near memory cache (DRAM) should be larger than the working set size of the workload.
- All memory channels should be populated to maximize the available memory bandwidth.
Example
|
Criterion |
Condition(s) |
Result |
|---|---|---|
| Workload is not Memory BW/Latency bound |
Memory_Bound(%) is smaller than 30%:
AND Write Bandwidth Ratio is smaller than 40%:
|
YES |


Appendix A: Metrics for PMem Memory Mode Suitability Analysis
|
Metric |
Description |
|---|---|
| Total Memory Size | Total addressable memory available on the system. |
| DRAM DIMM size and type |
The size and type of the DRAM memory module (DIMM) used on the system. |
| Memory topology and memory modules placement | A number of sockets, memory controllers, memory channels and populated memory slots in each channel. |
|
Metric |
Description |
|---|---|
| Memory Utilization | A fraction of physical memory present on the system being used by the workload. |
|
CPU utilization (user/system) (OS view) |
These are percentages of total CPU time. User: time spent running non-kernel code (user time). System: time spent running kernel code (system time). |
|
CPU I/O wait |
Percentages of total CPU time spent waiting for IO. |
|
Major/Minor page faults (Linux) |
A page request triggered by page fault from user-space, if the page fault handler would satisfy this request without incurring disk I/O, it is treated as a minor page fault. But if the page fault handler must incur disk I/O to satisfy the page request, it is treated as a major page fault. |
| Storage Throughput | Throughput measures the data transfer rate to and from the storage media in megabytes per second. |
| Storage IOPS | IOPS stands for input/output operations per second. It’s a measurement of performance for the drive. |
| Storage queue depth | An average number of requests on the disk that are in the queue. |
| Network throughput | The rate at which data is sent and received on the network adaptor. |
| Network Utilization |
The ratio of the network throughput to the maximum available network throughput (network speed). |
|
Working set size (hot data size) of the workload |
Working Set Size is a measurement of the “hot data” an application uses during its execution. Hot data is data that is frequently needed. Warm/cold data is data that is less frequently needed. |
|
Metric |
Description |
|---|---|
|
CPU Utilization (Hardware view) |
Percentage of time spent in the active C0 state over all cores. |
|
CPU utilization in kernel mode (Hardware View) |
CPU utilization percentage used by the operating system averaged over all cores. |
|
DRAM bandwidth (read/write) |
The rate at which data was read from or stored to the attached DRAM. |
| NUMA read addressed to local/remote DRAM | Percentage of read accesses going to local/remote socket. |
| NUMA RFOs addressed to local/remote DRAM |
Percentage of from (read for ownership) accesses going to local/remote socket. |
|
Memory Bound (%) |
Percentage of pipeline slots stalled waiting for memory. A higher value represents that the workload performance is more sensitive to memort bandwidth and latency. Learn more about the Memory Bound Metric. |
|
Core Bound (%) |
Percentage of pipeline slots stalled waiting for core. A higher value represents that the workload performance is more sensitive to compute resources available on the system. Learn more about the Core Bound Metric. |
|
IO_bandwidth_disk_or_network_reads (MB/sec) |
Total read traffic going to either to storage or network. Note: A different set of metrics which computes disk and network separately works as well. |
|
IO_bandwidth_disk_or_network_writes (MB/sec) |
Total write traffic going to either to storage or network. Note: A different set of metrics which computes disk and network separately works as well. |
|
Metric |
Description |
|---|---|
|
Persistent Memory Read Throughput (MB/sec) |
The rate at which data is read from the PMem memory module. |
|
Persistent Memory Write Throughput (MB/sec) |
The rate at which data is written to the PMem memory module. |
| Memory mode near memory cache read miss rate percentage |
This metric gives the ratio (in percentage) of read traffic directed to the far memory (PMem) compared to the combined traffic hitting the near memory cache (DRAM) and the traffic directed to the far memory (PMem). |
|
Persistent Memory per-DIMM read hit ratio (available thought IPMWatch) |
Read hit ratio measures the efficiency of the PMem buffer in the read path. Range of 0.0 - 0.75. |
|
Persistent Memory per-DIMM write hit ratio (available through IPMWatch) |
Write hit ratio measures the efficiency of the PMem buffer in the write path. Range of 0.0 - 0.1. |
|
Persistent Memory Read Queue Latency (ns) |
Time spent in the queues by read operations before they are dispatched to PMem. |
Appendix B: Tools
|
Platform |
Tool |
Metrics |
|---|---|---|
| ESXi Host | EXSi Web Interface | Total addressable memory available on the system. |
| Esxtop |
Memory Utilization, CPU utilization (user/system) (OS view), CPU I/O wait, Storage Throughput, Page faults, Storage Throughput, Storage IOPS, Storage queue depth, Network throughput, Network Utilization, Active memory. |
|
| Linux | Intel® VTune™ Profiler - Platform Profiler For more information see the documentation for Platform Profiler Analysis | Most of the metrics are presented in Appendix A. |
| Windows | Intel® VTune™ Profiler - Platform Profiler For more information see the documentation for Platform Profiler Analysis | Most of the metrics are presented in Appendix A. |
Notices and Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.