Introduction
This guide is for users who are already familiar with the BERT model. It provides recommendations for configuring hardware and software that provide the best performance in most situations. However, note that we rely on the users to carefully consider these settings for their specific scenarios, since the workload can be deployed in multiple ways.
In this tuning guide, we use the Light Model Transformer as main optimization tool. Light Model Transformer is a lightweight software tool that transforms a trained TensorFlow* model into C++ code. The generated code is based on Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) and provides interface to do inference without any framework, intent to accelerate the inference performance.
4th generation Intel® Xeon® Scalable processors deliver workload-optimized performance with built-in acceleration for AI, encryption, HPC, storage, database systems, and networking. They feature unique security technologies to help protect data on-premises or in the cloud.
- New built-in accelerators for AI, HPC, networking, security, storage and analytics
- Intel® Ultra Path Interconnect (Intel® UPI)
- Intel® Speed Select
- Hardware-enhanced security
- New flex bus I/O interface (PCIe* 5.0 and CXL)
- New flexible I/O interface up to 20 high-speed I/O (HSIO) lanes (PCI 3.0)
- Increased I/O bandwidth with PCIe 5.0 (up to 80 lanes)
- Increased memory bandwidth with DDR5
- Increased multisocket bandwidth with Intel UPI 2.0 (up to 16 GT/s)
- Support for Intel® Optane™ PMem 300 series
Intel® Advanced Matrix Extensions (Intel® AMX) architecture is shown in Figure 1.
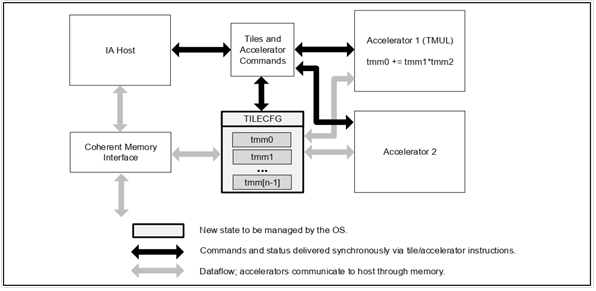
Figure 1.
Tiles are two-dimensional registers, and Tile Matrix Multiply Unite (TMUL) is an accelerator, which carries out operations on the tiles. Specifically, TMUL is a grid of fused multiply-add units that can read and write tiles. TMUL reads from two source tiles, multiplies their values in a systolic pattern, and adds the result into a destination tile.
For more information on Intel AMX, see LWN.net.
Server Configuration
Hardware
The configuration described in this article is based on 4th generation Intel Xeon processors. The server platform, memory, hard drives, and network interface cards can be determined according to your usage requirements.
|
Hardware |
Model |
|
CPU |
4th generation Intel Xeon Scalable processors, base frequency 1.9 GHz |
|
BIOS |
EGSDCRB1.SYS.0090.D03.2210040200 |
|
Memory |
512 GB (16x32 GB 4800 MT/s [4800 MT/s]) |
|
Storage/Disks |
1x 349.3G Intel SSDPE21K375GA |
|
NIC |
1x Ethernet controller I225-LM |
Software
|
Software |
Version |
|
Operating System |
CentOS* Stream release 8 |
|
Kernel |
5.16.0+ |
|
Workload |
BERT model |
|
GNU Compiler Collection (GCC)* |
8.5+ |
|
Intel® oneAPI Deep Neural Network Library (oneDNN) |
2.6+ |
Hardware Tuning
This guide targets using BERT optimizations on 4th gen Intel Xeon Scalable processors with Intel® Advanced Matrix Extensions (Intel® AMX).
BIOS Settings
Download BIOS binaries from Intel or ODM-released BKC matched firmware binaries and flush them to the board. This document is based on BKC#57.
Software Tuning
Software configuration tuning is essential. From the operating system to workload configuration settings, they are all designed for general purpose applications and default settings are almost never tuned for best performance.
Linux* Kernel Settings
Typically, a CentOS 8 Stream is chosen for the POC environment, but to enable AMX, you need to update its kernel. At the current stage, you can use public version 5.16. In version 5.16 or the newer version, the Intel AMX feature is enabled by default. No other specific settings are needed.
To check the kernel version after rebooting, use the uname command.
oneDNN Settings
In this tool, use oneDNN to call a function related to Intel AMX. For the Linux* kernel version 5.16 and higher, only oneDNN version 2.6 and higher can support Intel AMX instructions.
You can install oneDNN according to this reference. Only oneDNN needs to be installed. No other components are needed.
BERT Tuning with Intel AMX
BERT is a widely used machine learning technique for natural language processing (NLP) that has refreshed lots of records in NLP tasks since its inception. BERT has also shown extremely strong performance in practical applications. For search, machine translation, man-machine interaction, and other NLP services, BERT has been widely adopted across multiple user scenarios. As the performance of BERT directly affects the user experience of applications, engineers have thought about all kinds of ways to optimize the model to improve its performance.
BERT includes large amount of matrix computing that can be accelerated with Intel AMX features. Theoretically, Intel AMX can improve performance by eight times compared with Vector Neural Network Instructions (VNNI) for int8 or bf16 vector computing. If you can make full use of the Intel AMX feature in the workload, you can greatly improve the business performance.
Download the Tool and Compile
git clone https://github.com/intel/light-model-transformer
cd light-model-transformer/BERT
mkdir build
cd build
source /opt/intel/oneapi/setvars.sh # Make sure CMake can find oneDNN
cmake ..
cmake --build . -j 8
Run Benchmark
Run benchmark to prove that this tool can work normally:
tests/benchmark/benchmark
A Tuning BERT Model Based on TensorFlow* Version 2.x
How It Works
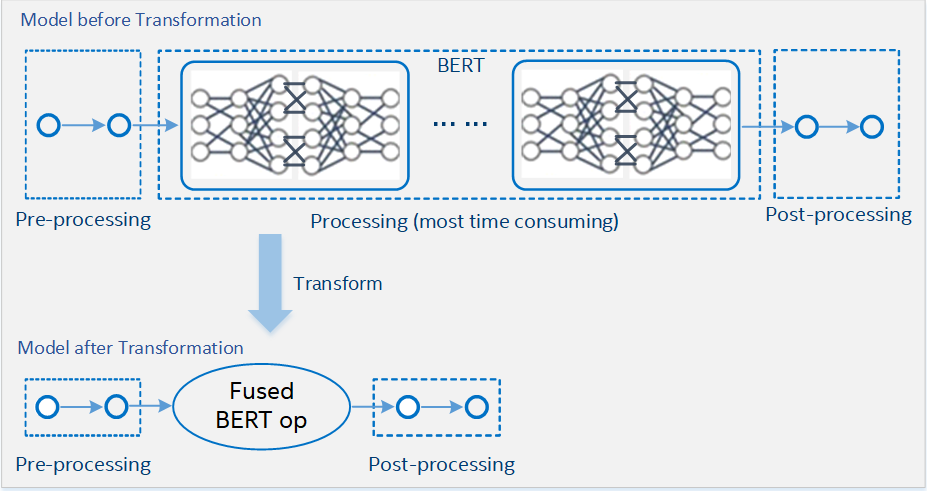
Figure 2.
In Figure 2, the BERT model is fused into a big operation based on a TensorFlow wrapper. In this big operation, reimplement all operations by oneDNN primitives or intrinsic instructions. In these operations, functions that are related to Intel AMX are called for matmul operations based on oneDNN on 4th generation Intel Xeon Scalable processors.
Requirements
- Dataset for testing (to download MRPC, see the following section)
- Google* BERT-Based Model
- Python* version 3.x (3.8 is verified)
- TensorFlow version 2.x (2.9 is verified)
- tensorflow-text
- tensorflow-datasets
- tensorflow-hub
- pandas
- pytest
Fine Tuning a Model
To download MRPC and fine tune a BERT-based model, follow the tutorial in Fine-Tune a Script for a BERT Model.
Usage of run_classifier.py
python run_classifier.py -b $encoder_handle -p $preprocessor_handle -e $epochs -l $learning_rate $output_dir
The tool builds a model consisting of the specified preprocessor and a BERT encoder, adds a classification head to it, and fine-tunes it using the GLUE/MRPC dataset.
Default Model
- Run the run_classifier.py tool.
All arguments except output_dir have defaults and are optional. The default BERT model is downloaded, fine-tuned, and saved in output_dir.
Select a Different Model (Model Modification May Not Work)
For details, see Modify the Model.
- Pick a BERT encoder.
- Find a compatible preprocessor model for your BERT encoder.
- (Optional) Download the models.
- Run the run_classifier.py tool. All arguments except output_dir have defaults and are optional, but you want to use your selected models, you must provide handles for the TensorFlow Hub:
- If you downloaded the models, the handles are the download paths.
- Otherwise, provide the TensorFlow Hub URL. (TensorFlow Hub caches the downloads between runs.)
Modify the Model
Modifying the model to use the monolithic BertOp is done using the model modifier tool. Rather than calling the tool directly, it’s easier to use a script preconfigured for a specific BERT model. Those scripts are available in the util directory. Currently only the default model is supported.
The steps to modify the model are:
- (If not done previously) Compile the model modifier protos :
$ cd <repo_root>/python/proto
$ ./compile_proto.sh $tensorflow_include_dir
For TensorFlow2.x, tensorflow_include_dir will be <...>/site-packages/tensorflow/include
TensorFlow1.x does not seem to include .proto files with the package. In this case, TensorFlow sources can be used. tensorflow_include_dir is the root of the TensorFlow repository.
- Put the model modifier on PYTHONPATH:
export PYTHONPATH=<repo_root/python>:$PYTHONPATH
- Run the preconfigured script:
$ cd <repo_root>/util/tf2/bert_en_uncased_L-12_H-768_A-12_4
$ ./replace_full_bert.sh $path_to_bert_encoder $path_to_fine_tuned_model
The path_to_bert_encoder should be the BERT encoder model, as downloaded from TF Hub.
The path_to_fine_tuned_model is the path to the output model of run_classifier.py
The preconfigured script uses the model modifier tools to generate a BERT pattern.pb from the original encoder model, combine it with the fused_bert_node_def.pb included with the script to create a recipe.pb, then use that recipe to locate the BERT pattern in the fine-tuned model and replace it with the fused BERT operation. The intermediate pattern.pb and recipe.pb are created in a temporary directory and removed when finished.
This requires the original BERT encoder model to be available, which is not ideal and may be changed in the future. For example, the recipe.pb can be stored in the repository.
- Enable the modified model graph.
The previous tool creates a modified_saved_model.pb next to the saved_model.pb of the fine-tuned model. To use the modified graph, do:
$ cd $path_to_model
$ mv saved_model.pb original_saved_model.pb
$ ln -s modified_saved_model.pb saved_model.pb
This will preserve the original model graph, but calls to tf.saved_model.load(...) do not use the modified version.
Configure BERT Operations
Users are required to configure BERT operations. A full tutorial on all possible options can be found here.
However to launch this particular model with no quantization and no bfloat16, you can do the following:
export PYTHONPATH=$PYTHONPATH:$<repo_root>/python
python -m model_modifier.configure_bert_op --no-quantization --no-bfloat16 $path_to_fine_tuned_model
Accuracy Checking and Performance Evaluating
Accuracy checking and performance evaluating can be done using the accuracy.py script.
python accuracy.py $model_dir $op_library
Conclusion
According to this test, the 4th generation Intel Xeon Scalable processors can improve the performance in some use cases using the VNNI instructions or Intel AMX instructions. Intel AMX instruction, can greatly promote the competitiveness of Intel CPUs in AI.
Feedback
We value your feedback. If you have comments (positive or negative) on this guide or are seeking something that is not part of this guide, reach out and let us know what you think.