Machine learning heavily relies on model optimization techniques to enhance performance and efficiency. This blog post will delve into a curated comparative analysis of four popular model optimization techniques: Optimum Intel, AIMET (AI Model Efficiency Toolkit), ONNXRuntime Quantizer, and PyTorch Quantization. Examining the strengths and limitations of each, we aim to provide you with a comprehensive understanding of their capabilities and help you make informed decisions when selecting the suitable optimization technique for your machine learning projects.
Optimum Intel is a cutting-edge tool developed jointly by Intel and Hugging Face to optimize model quantization, a critical aspect of machine learning. Model quantization involves reducing the size and complexity of neural network models while maintaining their accuracy, enabling efficient deployment on resource-constrained devices. Optimum Intel makes this process seamless and effective, offering substantial benefits to developers and end-users. One of the key reasons Optimum Intel has garnered attention in the field is its ability to balance model size reduction with minimal loss in performance. Leveraging advanced algorithms and expertise from Intel ensures that neural networks remain accurate even after quantization. This means models can be deployed on devices without sacrificing performance or functionality. Additionally, Optimum Intel provides comprehensive tools that enable developers to fine-tune and customize model quantization according to specific requirements, ensuring optimal deployment in various scenarios. Check out the documentation for further details.
The Architecture Diagram below is of Optimum Intel provides quantization and the model and be deployed to different inference runtime. Developers can select the best quantization method, SmoothQuant for LLM accuracy, 4bits weight-only quantization for LLM performance, etc.
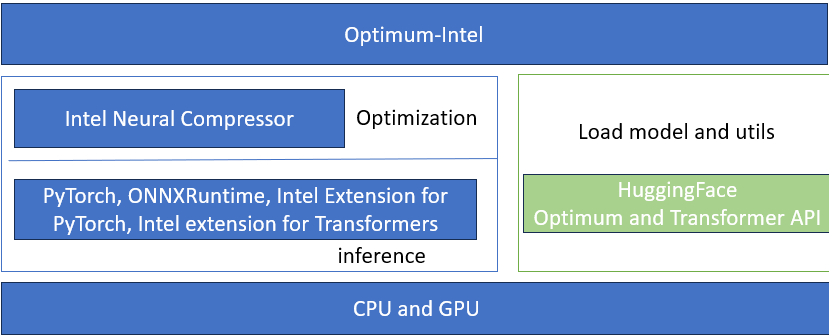
Comparative analysis of Optimum Intel with AIMET:
Optimum Intel and AIMET are renowned in model quantization for their cutting-edge approaches, yet they showcase distinct methodologies that warrant closer examination. Optimum Intel takes a comprehensive approach to model quantization by considering the interplay between different layers of neural networks and optimizing them holistically. Optimum Intel ensures efficient utilization of computational resources without sacrificing accuracy by analyzing how each layer contributes to overall performance. On the other hand, AIMET focuses on finding the optimal balance between model size reduction and preservation of predictive capabilities. Its approach includes identifying redundant weights and optimizing their representation to achieve lightweight models while maintaining high performance.
While both frameworks share a common goal of reducing computational requirements, their approaches have key differences. Optimum Intel primarily emphasizes optimizing neural network layers, whereas AIMET emphasizes individual weight optimization. This difference impacts the granularity at which each framework operates. While Optimum Intel aims for global optimization across all layers, AIMET aims to fine-tune specific weights within those layers.
Another notable distinction lies in their adaptability to different types of models. Aimed primarily at computer vision models built using popular libraries like PyTorch and TensorFlow, AIMET provides developers an encompassing toolkit that supports various hardware platforms such as CPUs and GPUs. In contrast, Optimum Intel enhances performance of Xeon CPU deployments with custom-developed acceleration engines.
Comparative analysis of Optimum Intel with ONNXRuntime Quantizer:
The comparative analysis of Optimum Intel and ONNXRuntime Quantizer in terms of performance is an intriguing aspect to delve into. When it comes to performance, Optimum Intel stands out with its ability to take full advantage of the deep neural network (DNN) capabilities of modern Intel CPUs. The highly optimized libraries and powerful hardware optimizations provided by Optimum Intel result in superior execution speed and efficiency. However, Optimum Intel falls short in its limited cross-platform support, as it is designed specifically for Intel CPUs.
On the other hand, ONNXRuntime Quantizer offers a versatile solution that can run on multiple platforms, including CPU, GPU, and even edge devices such as Raspberry Pi. This cross-platform compatibility allows developers to leverage the benefits of hardware acceleration on various devices. However, this flexibility comes at a cost, as ONNXRuntime Quantizer may not fully exploit the specialized DNN capabilities available on specific platforms like Optimum Intel offers.
Comparative analysis of Optimum Intel with PyTorch Quantization:
Optimizing and quantizing neural networks has become a crucial aspect of model development, intending to reduce inference time and model size while maintaining accuracy. Two popular tools for this purpose are Optimum Intel and PyTorch Quantization. Optimum Intel brings its unique set of features that leverage hardware-specific optimizations for Intel platforms, ensuring maximum efficiency. On the other hand, PyTorch Quantization offers a flexible framework that allows developers to quantize their models using various techniques, such as post-training static or dynamic quantization.
Regarding performance optimizations, Optimum Intel shines in its ability to take advantage of specific capabilities offered by Intel processors. By leveraging technologies like vector instructions (Intel® AVX-512) and kernel fusion, Optimum Intel can significantly boost inference speed on hardware equipped with these features. Moreover, it provides advanced profiling tools that allow developers to fine-tune different parts of their models for better performance. In contrast, PyTorch Quantization focuses more on general-purpose techniques that work across various hardware platforms, making it suitable for deployment on systems other than those based on Intel processors.
Conclusion:
Regarding model quantization, selecting the right tool can make a significant difference in your workflow. Two popular tools that often come up in discussions are Optimum Intel and PyTorch. Each has its strengths and weaknesses, but choosing the one that best aligns with your requirements is crucial.
Optimum Intel offers an optimized framework for deep learning models specifically designed for Intel hardware. It leverages the benefits of Intel's CPUs and accelerators to enhance model performance while reducing computational complexity. On the other hand, PyTorch provides flexibility and ease of use, making it an excellent choice if you need a tool with quick prototyping capabilities and extensive community support. In addition to these options, another tool worth considering is AIMET. By leveraging AIMET's capabilities alongside Optimum Intel or PyTorch, users gain access to advanced techniques such as layer fusion and weight sharing, leading to even better results in both efficiency and performance. If deployment efficiency is your priority, another option to explore is ONNX runtime. By combining the power of optimized quantization tools like Optimum Intel with PyTorch, ONNXRuntime's runtime environment, developers can unlock new possibilities in enhancing the efficiency and performance of their machine learning models.
Overall, there is no one-size-fits-all solution for choosing the right tool for model quantization. Each model has strengths; understanding your specific requirements and carefully evaluating options is recommended. But for LLM, we recommend choosing Optimum Intel as the quantizer.
Refer to the tabular report below:
| Quantizer models | Best use case Scenarios |
|---|---|
| Optimum Intel | Offers optimized framework for deep learning models, specifically Intel HW and SW. LLM specific quantization. |
| ONNXRuntime Quantizer | ONNXRuntime environment enhances efficiency and performance of machine learning. Along with Optimum Intel or PyTorch is best suited for deployment efficiency. |
| AIMET | Along with Optimum Intel or PyTorch provide access to advanced techniques such as Layer fusion and weight sharing in turn provides better results in terms of both efficiency and performance |
| PyTorch Quantization | Ease of use makes it first choice for prototyping and community support |
In addition to tools for model quantization, Intel provides an end-to-end software portfolio of AI/ML Framework optimizations and tools to help you prepare, build, deploy, and scale your AI solutions. We encourage you to check out and incorporate them into your AI workflows.