Introduction
In this article, I show how to transform a simple C++ program—in this case a simplified version of the famous UNIX command-line utility grep—in order to take advantage of persistent memory (PMEM). The article starts with a description of what the volatile version of the grep program does with a detailed look at the code. I then discuss how you can improve grep by adding to it a persistent caching of search results. Caching improves grep by1 adding fault tolerance (FT) capabilities and2 speeding up queries for already-seen search patterns. The article goes on to describe the persistent version of grep using the C++ bindings of libpmemobj, which is a core library of the Persistent Memory Developer Kit (PMDK) collection. Finally, parallelism (at file granularity) is added using threads and PMEM-aware synchronization.
Volatile Grep
Description
If you are familiar with any UNIX*-like operating system, such as GNU/Linux*, you are probably also familiar with the command-line utility grep (which stands for globally search a regular expression and print). In essence, grep takes two arguments (the rest are options): a pattern, taking the form of a regular expression, and some input file(s) (including standard input). The goal of grep is to scan the input, line by line, and then output those lines matching the provided pattern. You can learn more by reading the grep manual page (type man grep on the terminal or view the Linux man page for grep online).
For my simplified version of grep, only the two aforementioned arguments are used (pattern and input), where input should be either a single file or a directory. If a directory is provided, its contents are scanned to look for input files (subdirectories are always scanned recursively). To see how this works in practice, let’s run it using its own source code as input and “int” as pattern.
The code can be downloaded from GitHub*. To compile the code from the root of the pmdk-examples repository, type make simple-grep. libpmemobj must be installed in your system, as well as a C++ compiler.
If the program compiles correctly, we can run it like this:
$ ./grep int grep.cpp
FILE = grep.cpp
44: int
54: int ret = 0;
77: int
100: int
115: int
135: int
136: main (int argc, char *argv[])
As you can see, grep finds seven lines with the word “int” on it (lines 44, 54, 77, 100, 115, 135, and 136). As a sanity check, we can run the same query using the system-provided grep:
$ grep int –n grep.cpp
44:int
54: int ret = 0;
77:int
100:int
115:int
135:int
136:main (int argc, char *argv[])
So far, we have the desired output. The following listing shows the code (note: line numbers on the snippets above do not match the following listing because code formatting differs from the original source file):
#include <boost/filesystem.hpp>
#include <boost/foreach.hpp>
#include <fstream>
#include <iostream>
#include <regex>
#include <string.h>
#include <string>
#include <vector>
using namespace std;
using namespace boost::filesystem;
/* auxiliary functions */
int
process_reg_file (const char *pattern, const char *filename)
{
ifstream fd (filename);
string line;
string patternstr ("(.*)(");
patternstr += string (pattern) + string (")(.*)");
regex exp (patternstr);
int ret = 0;
if (fd.is_open ()) {
size_t linenum = 0;
bool first_line = true;
while (getline (fd, line)) {
++linenum;
if (regex_match (line, exp)) {
if (first_line) {
cout << "FILE = " << string (filename);
cout << endl << flush;
first_line = false;
}
cout << linenum << ": " << line << endl;
cout << flush;
}
}
} else {
cout << "unable to open file " + string (filename) << endl;
ret = -1;
}
return ret;
}
int
process_directory_recursive (const char *dirname, vector<string> &files)
{
path dir_path (dirname);
directory_iterator it (dir_path), eod;
BOOST_FOREACH (path const &pa, make_pair (it, eod)) {
/* full path name */
string fpname = pa.string ();
if (is_regular_file (pa)) {
files.push_back (fpname);
} else if (is_directory (pa) && pa.filename () != "."
&& pa.filename () != "..") {
if (process_directory_recursive (fpname.c_str (), files)
< 0)
return -1;
}
}
return 0;
}
int
process_directory (const char *pattern, const char *dirname)
{
vector<string> files;
if (process_directory_recursive (dirname, files) < 0)
return -1;
for (vector<string>::iterator it = files.begin (); it != files.end ();
++it) {
if (process_reg_file (pattern, it->c_str ()) < 0)
cout << "problems processing file " << *it << endl;
}
return 0;
}
int
process_input (const char *pattern, const char *input)
{
/* check input type */
path pa (input);
if (is_regular_file (pa))
return process_reg_file (pattern, input);
else if (is_directory (pa))
return process_directory (pattern, input);
else {
cout << string (input);
cout << " is not a valid input" << endl;
}
return -1;
}
/* MAIN */
int
main (int argc, char *argv[])
{
/* reading params */
if (argc < 3) {
cout << "USE " << string (argv[0]) << " pattern input ";
cout << endl << flush;
return 1;
}
return process_input (argv[1], argv[2]);
}
I know the code is long but, trust me, it is not difficult to follow. All I do here is to check whether the input is a file or a directory in process_input(). In the case of the former, the file is directly processed in process_reg_file(). Otherwise, the directory is scanned for files in process_directory_recursive(), and then all scanned files are processed one by one in process_directory() by calling process_reg_file() on each one. When processing a file, each line is checked to see whether it matches the pattern or not. If it does, the line is printed to standard output.
Persistent Caching
Now that we have a working grep, let’s see how we can improve it. The first thing we see is that grep does not keep any state at all. Once the input is analyzed and the output generated, the program simply ends. Let say, for instance, that we are interested in scanning a large directory (with hundreds of thousands of files) for a particular pattern of interest, every week. And let’s say that the files in this directory could, potentially, change over time (although not likely all at the same time), or new files could be added. If we use the classic grep for this task, we would be potentially scanning some of the files over and over, wasting precious CPU cycles. This limitation can be overcome with the addition of a cache: If it turns out that a file has already been scanned for a particular pattern (and its contents have not changed since it was last scanned), grep can simply return the cached results instead of re-scanning the file.
This cache can be implemented in multiple ways. One way, for example, is to create a specific data base (DB) to store the results of each scanned file and pattern (adding also a timestamp to detect file modifications). Although this surely works, a solution not involving the need to install and run a DB engine would be preferable, not to mention the need to perform DB queries every time files are analyzed (which may involve network and input/output overhead). Another way to do it would be to store this cache as a regular file (or files), loading it into volatile memory at the beginning, and updating it either at the end of the execution or every time a new file is analyzed. Although this seems to be a better approach, it still forces us to create two data models, one for volatile RAM, and another for secondary persistent storage (files), and write code to translate back and forth between the two. It would be nice to avoid this extra coding effort.
Persistent Grep
Design considerations
Making any code PMEM-aware using libpmemobj always involves, as a first step, designing the types of data objects that will be persisted. The first type that needs to be defined is that of the root object. This object is mandatory and used to anchor all the other objects created in the PMEM pool (think of a pool as a file inside a PMEM device). For my grep sample, the following persistent data structure is used:
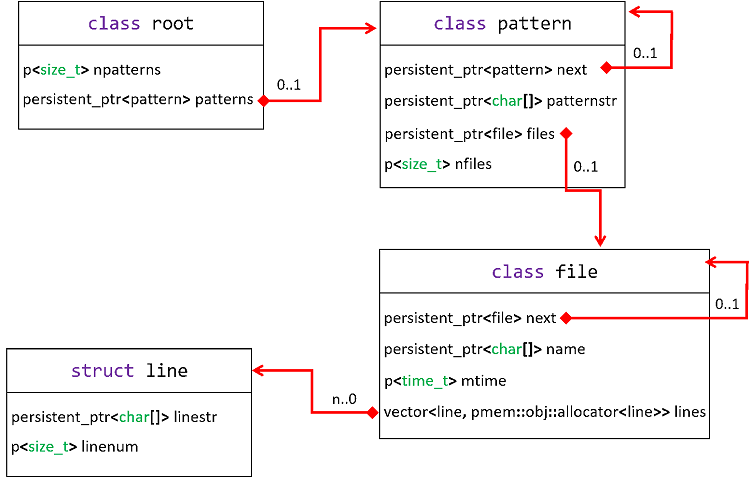
Figure 1. Data structure for PMEM-aware grep.
Cache data is organized by creating a linked list of patterns hanging from the root class. Every time a new pattern is searched, a new object of class pattern is created. If the pattern currently searched for has been searched before, no object creation is necessary (the pattern string is stored in patternstr). From the class pattern we hang a linked list of files scanned. The file is composed of a name (which, in this case, is the same as the file system path), modification time (used to check whether the file has been modified), and a vector of lines matching the pattern. We only create new objects of class file for files not scanned before.
The first thing to notice here are the special classes p<> (for basic types) and persistent_ptr<> (for pointers to complex types). These classes are used to tell the library to pay attention to those memory regions during transactions (changes done to those objects are logged and rolled back in the event of a failure). Also, and due to the nature of virtual memory, persistent_ptr<> should always be used for pointers residing in PMEM. When a pool is opened by a process and mapped to its virtual memory address space, the location of the pool could be different than previous locations used by the same process (or other’s processes accessing the same pool). In the case of PMDK, persistent pointers are implemented as fat pointers; that is, they consist of a pool ID (used to access current pool virtual address from a translation table) + offset (from the beginning of the pool). For more information about pointers in PMDK you can read Type safety macros in libpmemobj, and also C++ bindings for libpmemobj (part 2) – persistent smart pointer.
You may wonder why, then, is the vector (std::vector) of lines not declared as a persistent pointer. The reason is that we do not need to. The object representing the vector, lines, does not change once it is created (during construction of an object of class file), and hence there is no need to keep track of the object during transactions. Still, the vector itself does allocate (and delete) objects internally. For this reason, we cannot rely only on the default allocator from std::vector (which only knows about volatile memory, and allocates all objects in the heap); we need to pass a customized one—provided by libpmemobj—that knows about PMEM. This allocator is pmem::obj::allocator<line>. Once we have declared the vector that way, we can use it as we would in any normal volatile code. In fact, you can use any of the standard container classes this way.
Code Modifications
Now, let’s jump to the code. In order to avoid repetition, only new code is listed (the full code is available in pmemgrep/pmemgrep.cpp). I start with definitions (new headers, macros, namespaces, global variables, and classes):
...
#include <libpmemobj++/allocator.hpp>
#include <libpmemobj++/make_persistent.hpp>
#include <libpmemobj++/make_persistent_array.hpp>
#include <libpmemobj++/persistent_ptr.hpp>
#include <libpmemobj++/transaction.hpp>
...
#define POOLSIZE ((size_t) (1024 * 1024 * 256)) /* 256 MB */
...
using namespace pmem;
using namespace pmem::obj;
/* globals */
class root;
pool<root> pop;
/* persistent data structures */
struct line {
persistent_ptr<char[]> linestr;
p<size_t> linenum;
};
class file
{
private:
persistent_ptr<file> next;
persistent_ptr<char[]> name;
p<time_t> mtime;
vector<line, pmem::obj::allocator<line>> lines;
public:
file (const char *filename)
{
name = make_persistent<char[]> (strlen (filename) + 1);
strcpy (name.get (), filename);
mtime = 0;
}
char * get_name (void) { return name.get (); }
size_t get_nlines (void) { return lines.size (); /* nlines; */ }
struct line * get_line (size_t index) { return &(lines[index]); }
persistent_ptr<file> get_next (void) { return next; }
void set_next (persistent_ptr<file> n) { next = n; }
time_t get_mtime (void) { return mtime; }
void set_mtime (time_t mt) { mtime = mt; }
void
create_new_line (string linestr, size_t linenum)
{
transaction::exec_tx (pop, [&] {
struct line new_line;
/* creating new line */
new_line.linestr
= make_persistent<char[]> (linestr.length () + 1);
strcpy (new_line.linestr.get (), linestr.c_str ());
new_line.linenum = linenum;
lines.insert (lines.cbegin (), new_line);
});
}
int
process_pattern (const char *str)
{
ifstream fd (name.get ());
string line;
string patternstr ("(.*)(");
patternstr += string (str) + string (")(.*)");
regex exp (patternstr);
int ret = 0;
transaction::exec_tx (
pop, [&] { /* dont leave a file processed half way through */
if (fd.is_open ()) {
size_t linenum = 0;
while (getline (fd, line)) {
++linenum;
if (regex_match (line, exp))
/* adding this line... */
create_new_line (line, linenum);
}
} else {
cout
<< "unable to open file " + string (name.get ())
<< endl;
ret = -1;
}
});
return ret;
}
void remove_lines () { lines.clear (); }
};
class pattern
{
private:
persistent_ptr<pattern> next;
persistent_ptr<char[]> patternstr;
persistent_ptr<file> files;
p<size_t> nfiles;
public:
pattern (const char *str)
{
patternstr = make_persistent<char[]> (strlen (str) + 1);
strcpy (patternstr.get (), str);
files = nullptr;
nfiles = 0;
}
file *
get_file (size_t index)
{
persistent_ptr<file> ptr = files;
size_t i = 0;
while (i < index && ptr != nullptr) {
ptr = ptr->get_next ();
i++;
}
return ptr.get ();
}
persistent_ptr<pattern> get_next (void) { return next; }
void set_next (persistent_ptr<pattern> n) { next = n; }
char * get_str (void) { return patternstr.get (); }
file *
find_file (const char *filename) {
persistent_ptr<file> ptr = files;
while (ptr != nullptr) {
if (strcmp (filename, ptr->get_name ()) == 0)
return ptr.get ();
ptr = ptr->get_next ();
}
return nullptr;
}
file *
create_new_file (const char *filename) {
file *new_file;
transaction::exec_tx (pop, [&] {
/* allocating new files head */
persistent_ptr<file> new_files
= make_persistent<file> (filename);
/* making the new allocation the actual head */
new_files->set_next (files);
files = new_files;
nfiles = nfiles + 1;
new_file = files.get ();
});
return new_file;
}
void
print (void)
{
cout << "PATTERN = " << patternstr.get () << endl;
cout << "\tpattern present in " << nfiles;
cout << " files" << endl;
for (size_t i = 0; i < nfiles; i++) {
file *f = get_file (i);
cout << "###############" << endl;
cout << "FILE = " << f->get_name () << endl;
cout << "###############" << endl;
cout << "*** pattern present in " << f->get_nlines ();
cout << " lines ***" << endl;
for (size_t j = f->get_nlines (); j > 0; j--) {
cout << f->get_line (j - 1)->linenum << ": ";
cout
<< string (f->get_line (j - 1)->linestr.get ());
cout << endl;
}
}
}
};
class root
{
private:
p<size_t> npatterns;
persistent_ptr<pattern> patterns;
public:
pattern *
get_pattern (size_t index)
{
persistent_ptr<pattern> ptr = patterns;
size_t i = 0;
while (i < index && ptr != nullptr) {
ptr = ptr->get_next ();
i++;
}
return ptr.get ();
}
pattern *
find_pattern (const char *patternstr)
{
persistent_ptr<pattern> ptr = patterns;
while (ptr != nullptr) {
if (strcmp (patternstr, ptr->get_str ()) == 0)
return ptr.get ();
ptr = ptr->get_next ();
}
return nullptr;
}
pattern *
create_new_pattern (const char *patternstr)
{
pattern *new_pattern;
transaction::exec_tx (pop, [&] {
/* allocating new patterns arrray */
persistent_ptr<pattern> new_patterns
= make_persistent<pattern> (patternstr);
/* making the new allocation the actual head */
new_patterns->set_next (patterns);
patterns = new_patterns;
npatterns = npatterns + 1;
new_pattern = patterns.get ();
});
return new_pattern;
}
void
print_patterns (void)
{
cout << npatterns << " PATTERNS PROCESSED" << endl;
for (size_t i = 0; i < npatterns; i++)
cout << string (get_pattern (i)->get_str ()) << endl;
}
}
...
Shown here is the C++ code for the diagram in Figure 1. You can also see the headers for libpmemobj, a macro (POOLSIZE) defining the size of the pool, and a global variable (pop) to store an open pool (you can think of pop as a special file descriptor). Notice how all modifications to the data structure—in root::create_new_pattern(), pattern::create_new_file(), and file::create_new_line()—are protected using transactions. In the C++ bindings of libpmemobj, transactions are conveniently implemented using lambda functions (you need a compiler compatible with at least C++11 to use lambdas). If you do not like lambdas for some reason, there is another way.
Notice also how all the memory allocation is done through make_persistent<>() instead of the regular malloc() or the C++ `new` construct.
The functionality of the old process_reg_file() is moved to the method file::process_pattern(). The new process_reg_file() implements the logic to check whether the current file has already been scanned for the pattern (if the file exists under the current pattern and it has not been modified since last time):
int
process_reg_file (pattern *p, const char *filename, const time_t mtime)
{
file *f = p->find_file (filename);
if (f != nullptr && difftime (mtime, f->get_mtime ()) == 0) /* file exists */
return 0;
if (f == nullptr) /* file does not exist */
f = p->create_new_file (filename);
else /* file exists but it has an old timestamp (modification) */
f->remove_lines ();
if (f->process_pattern (p->get_str ()) < 0) {
cout << "problems processing file " << filename << endl;
return -1;
}
f->set_mtime (mtime);
return 0;
}
The only change to the other functions is the addition of the modification time. For example, process_directory_recursive() now returns a vector of tuple<string, time_t> (instead of just vector<string>):
int
process_directory_recursive (const char *dirname,
vector<tuple<string, time_t>> &files)
{
path dir_path (dirname);
directory_iterator it (dir_path), eod;
BOOST_FOREACH (path const &pa, make_pair (it, eod)) {
/* full path name */
string fpname = pa.string ();
if (is_regular_file (pa)) {
files.push_back (
tuple<string, time_t> (fpname, last_write_time (pa)));
} else if (is_directory (pa) && pa.filename () != "."
&& pa.filename () != "..") {
if (process_directory_recursive (fpname.c_str (), files)
< 0)
return -1;
}
}
return 0;
}
Sample Run
Let’s run this code with two patterns: “int” and “void”. This assumes that a PMEM device (real or emulated using RAM) is mounted at /mnt/mem:
$ ./pmemgrep /mnt/mem/grep.pool int pmemgrep.cpp
$ ./pmemgrep /mnt/mem/grep.pool void pmemgrep.cpp
$
If we run the program without parameters, we get the cached patterns:
$ ./pmemgrep /mnt/mem/grep.pool
2 PATTERNS PROCESSED
void
int
When passing a pattern, we get the actual cached results:
$ ./pmemgrep /mnt/mem/grep.pool void
PATTERN = void
1 file(s) scanned
###############
FILE = pmemgrep.cpp
###############
*** pattern present in 15 lines ***
80: get_name (void)
86: get_nlines (void)
98: get_next (void)
103: void
110: get_mtime (void)
115: void
121: void
170: void
207: get_next (void)
212: void
219: get_str (void)
254: void
255: print (void)
326: void
327: print_patterns (void)
$
$ ./pmemgrep /mnt/mem/grep.pool int
PATTERN = int
1 file(s) scanned
###############
FILE = pmemgrep.cpp
###############
*** pattern present in 14 lines ***
137: int
147: int ret = 0;
255: print (void)
327: print_patterns (void)
337: int
356: int
381: int
395: int
416: int
417: main (int argc, char *argv[])
436: if (argc == 2) /* No pattern is provided. Print stored patterns and exit
438: proot->print_patterns ();
444: if (argc == 3) /* No input is provided. Print data and exit */
445: p->print ();
$
Of course, we can keep adding files to existing patterns:
$ ./pmemgrep /mnt/mem/grep.pool void Makefile
$ ./pmemgrep /mnt/mem/grep.pool void
PATTERN = void
2 file(s) scanned
###############
FILE = Makefile
###############
*** pattern present in 0 lines ***
###############
FILE = pmemgrep.cpp
###############
*** pattern present in 15 lines ***
80: get_name (void)
86: get_nlines (void)
98: get_next (void)
103: void
110: get_mtime (void)
115: void
121: void
170: void
207: get_next (void)
212: void
219: get_str (void)
254: void
255: print (void)
326: void
327: print_patterns (void)
Parallel Persistent Grep
Now that we have come this far, it would be a pity not to add multithreading support too; especially so, given the small amount of extra code required (the full code is available in pmemgrep_thx/pmemgrep.cpp).
The first thing we need to do is to add the appropriate header for pthreads and for the persistent mutex (more on this later):
...
#include <libpmemobj++/mutex.hpp>
...
#include <thread>
A new global variable is added to set the number of threads in the program, which now accepts a command-line option to set the number of threads (-nt=number_of_threads). If -nt is not explicitly set, one thread is used as default:
int num_threads = 1;
Next, a persistent mutex is added to the pattern class. This mutex is used to synchronize writes to the linked list of files (parallelism is done at the file granularity):
class pattern
{
private:
persistent_ptr<pattern> next;
persistent_ptr<char[]> patternstr;
persistent_ptr<file> files;
p<size_t> nfiles;
pmem::obj::mutex pmutex;
...
You may be wondering why the pmem::obj version of mutex is needed (why not use the C++ standard one). The reason is because the mutex is stored in PMEM, and libpmemobj needs to be able to reset it in the event of a crash. If not recovered correctly, a corrupted mutex could create a permanent deadlock; for more information you can read the following article about synchronization with libpmemobj.
Although storing mutexes in PMEM is useful when we want to associate them with particular persisted data objects, it is not mandatory in all situations. In fact, in the case of this example, a single standard mutex variable—residing in volatile memory—would have sufficed (since all threads work on only one pattern at a time). The reason why I am using a persistent mutex is to showcase its existence.
Persistent or not, once we have the mutex we can synchronize writes in pattern::create_new_file() by simply passing it to the transaction::exec_tx() (last parameter):
transaction::exec_tx (pop,
[&] { /* LOCKED TRANSACTION */
/* allocating new files head */
persistent_ptr<file> new_files
= make_persistent<file> (filename);
/* making the new allocation the
* actual head */
new_files->set_next (files);
files = new_files;
nfiles = nfiles + 1;
new_file = files.get ();
},
pmutex); /* END LOCKED TRANSACTION */
The last step is to adapt process_directory() to create and join the threads. A new function—process_directory_thread()—is created for the thread logic (which divides work by thread ID):
void
process_directory_thread (int id, pattern *p,
const vector<tuple<string, time_t>> &files)
{
size_t files_len = files.size ();
size_t start = id * (files_len / num_threads);
size_t end = start + (files_len / num_threads);
if (id == num_threads - 1)
end = files_len;
for (size_t i = start; i < end; i++)
process_reg_file (p, get<0> (files[i]).c_str (),
get<1> (files[i]));
}
int
process_directory (pattern *p, const char *dirname)
{
vector<tuple<string, time_t>> files;
if (process_directory_recursive (dirname, files) < 0)
return -1;
/* start threads to split the work */
thread threads[num_threads];
for (int i = 0; i < num_threads; i++)
threads[i] = thread (process_directory_thread, i, p, files);
/* join threads */
for (int i = 0; i < num_threads; i++)
threads[i].join ();
return 0;
}
Summary
In this article, I have shown how to transform a simple C++ program—in this case a simplified version of the famous UNIX command-line utility, grep—in order to take advantage of PMEM. I started the article with a description of what the volatile version of the grep program does with a detailed look at the code.
After that, the program is improved by adding a PMEM cache using the C++ bindings of libpmemobj, a core library of PMDK. To conclude, parallelism (at file granularity) is added using threads and PMEM-aware synchronization.
About the Author
Eduardo Berrocal joined Intel as a Cloud Software Engineer in July 2017 after receiving his PhD in Computer Science from the Illinois Institute of Technology (IIT) in Chicago, Illinois. His doctoral research interests were focused on (but not limited to) data analytics and fault tolerance for high-performance computing. In the past he worked as a summer intern at Bell Labs (Nokia), as a research aide at Argonne National Laboratory, as a scientific programmer and web developer at the University of Chicago, and as an intern in the CESVIMA laboratory in Spain.
Resources
- The Persistent Memory Development Kit (PMDK).
- Manual page for the grep command.
- The Boost C++ Library collection.
- Type safety macros in libpmemobj.
- C++ bindings for libpmemobj (part 2) – persistent smart pointer.
- C++ bindings for libpmemobj (part 6) – transactions.
- How to emulate Persistent Memory.
- Link to sample code in GitHub.