Challenge
This is an era of climate disruption, as droughts, floods, and temperature extremes amplify the challenges faced by agricultural interests. Many researchers and scientists are strongly interested in finding ways to use AI and machine learning to explore how different factors affect crop yields. These challenges are global.
As the US Environmental Protection Agency (EPA) states in its article Climate Impacts on Agriculture and Food Supply, “Climate change is very likely to affect food security at the global, regional, and local levels. Climate change can disrupt food availability, reduce access to food, and affect food quality. For example, projected increases in temperatures, changes in precipitation patterns, changes in extreme weather events, and reductions in water availability may all result in reduced agricultural productivity.”
Maura Tokay (Figure 1), a computer scientist and programmer at Science Systems and Applications Inc., has worked closely with earth science researchers for more than 20 years. She wondered if AI technology could help gain insights into crop yields.

Figure 1. Maura Tokay in her role as a lead software programmer at Science Systems and Applications Inc.
“In my work at the USDA [United States Department of Agriculture], I saw how complex it is to develop models to estimate yield where so many factors need to be taken into consideration, such as soil chemistry, weather data, plant phenology—among others,” Maura said. "I started wondering if we could use machine learning to predict crop yield using only weather data. If I was successful predicting crop yield, a few other related questions could be considered. How many weeks in advance from harvest can I predict the crop yield based solely on the weather conditions? Does the same meteorological variable affect different crops in the same way? Is the assumption correct that temperature and precipitation are the variables that carry more impact on the outcome of crop yield?”
Solution
Maura's development work was valuable as a proof of concept and foundational step to determine the validity of using meteorological data for effectively predicting crop yields. The project included data exploration and preparation, model building and training, and an analysis of the results.
“My solution tries to predict crop yield using only meteorological data weeks prior to harvesting,” Maura said. “If more data was available, we could expand the study and include different crop varieties and soil types, making this a product that a farmer could use to forecast the crop production.
“I rely only on one set of information (weather data) to predict yields," she continued. "The first challenge was to find a dataset that I could use for my study.” Dr. Michel Cavigelli of the USDA helped get the project off to a strong start by sharing a comprehensive dataset he had assembled over a 20-year span that proved vital to Maura’s research.
History
In an earlier interview with Code Together, a series from Intel that explores the possibilities of cross-architecture development, Maura recounted her journey toward using computer science and AI to gain a greater understanding of the natural world.
“Well, I had always loved math,” Maura said, “so I signed up to learn computer science but didn't know anything about programming. When I got to the University of Taubaté, Brazil, I began an internship to work at INPE [National Institute for Space Research], the space agency in Brazil. That's where I started doing programming. And after that, I got an internship at NASA. I was working different projects, from the rainforest in the Amazon to water management in North Africa and the Middle East. It has always been about trying to use technology to improve people's understanding of nature.”
Development Milestones and Enabling Technologies
The dataset Maura used was compiled by the Farming Systems Project at the USDA office in Beltsville, Maryland. It consisted of 20 years of records, including meteorological data and details about the planting and harvesting of soybeans, wheat, and corn.
Maura’s first objective was to identify which variables were most important for predicting yield. The project progressed from exploratory data analyses and feature engineering to establishing a work environment to build and train the models. All the development work was accomplished on Intel® DevCloud. Because Intel DevCloud provides immediate, free access to a wide range of Intel® oneAPI toolkits and components—tuned for the latest Intel®-based hardware architectures—it makes an ideal development sandbox. Feature engineering can be accomplished efficiently with accelerated computing, sharpening the predictive accuracy of the machine learning algorithms by comparing the results achieved across a range of different variables.
Maura relied on the Intel® oneAPI AI Analytics Toolkit on Intel DevCloud for much of her work. Intel engineers provided technical support during the early setup stages of the projects. “Setting up my work environment on Intel DevCloud was easy,” Maura said. “I used Jupyter* Notebook to develop my model. The ability to create and customize the Anaconda* environment to attend to my needs without restrictions made my work more efficient.”
Preloaded frameworks and libraries on Intel DevCloud also proved useful. “The environment allowed me to install any packages I needed without previous authorization,” Maura said. Among these useful packages, the Intel® Distribution for Python*, which includes NumPy, SciPy, and scikit-learn*, boosted performance considerably, as numerous benchmarks demonstrated (for details, read Deliver Blazing-Fast Python Data Science and AI Performance on CPUs—with Minimal Code Changes).
Over the course of the project, Maura discovered that a different model responded better for each crop. “If I had assumed the best method for corn yield prediction would be the best method for wheat or soybean yield production,” she said, “my assumption would be wrong and my project would fail. It is important to be thorough with your research.
“If you are working with machine learning,” she continued, “use as much time as you need to make sure the data you have is accurate and it is in the format you need to use to train your model.”
Model Results for Soybeans
Maura used feature engineering to determine the factors that were most relevant to improve the predictive capabilities of the machine learning models. Figures 2 and 3 provide an example of her results for one of the crops included in the project: soybeans. The figures show the use of the Random Forest regression model. The model uses 15 weeks of weather data with 400 estimators and 30 depth (tree levels) with a confidence level of 83% and accuracy of approximately 261 kilograms per hectare. The top five features were minTemp12, maxTemp7, minTemp5, Precip10, and minTemp1.
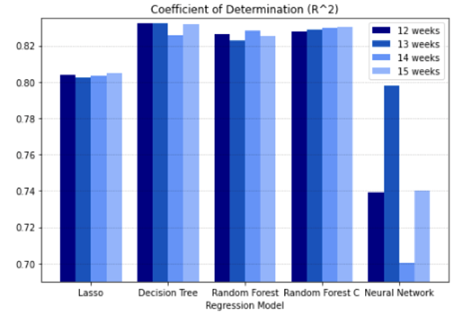
Figure 2. Coefficient of determination
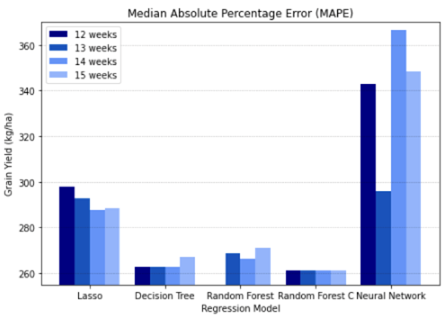
Figure 3. Median absolute percentage error
Conclusion
One of the key findings from Maura’s work is that relative humidity is a more important factor than precipitation for crop yield prediction. Temperature also plays a key role in accurately predicting crop yields.
“Climate change will have an impact on crop yield,” Maura noted. “The increase in temperature is often accompanied by drought and flooding conditions. For a future study, a sensitivity analysis can be performed to understand the climate anomalies on yield prediction.”
“The overall performance of all the models was rated as good (74% to 83%), but it could be better if more data were available to train the models,” Maura said.
Having effectively demonstrated the value of machine learning to let data scientists use well-known models to bridge the gap where a mechanistic model is not yet understood for certain phenomena, Maura offered this recommendation to other developers: “Intel DevCloud is a great space to work on your machine learning projects.”
Resources and Recommendations
Predicting Corn, Wheat, and Soybean Yields
Find out more on the Intel® DevMesh project page.
See the files related to the crop-yield project, including the dataset.
Get free access to code from home with cutting-edge Intel® CPUs, Intel® GPUs, Intel® FPGAs (field-programmable gate arrays), and preinstalled Intel oneAPI toolkits that include tools, frameworks, and libraries.
Experience self-paced, hands-on Data Parallel C++ (DPC++) trainings.