Summary
The Spain-based technology company provides a software development platform for optimizing C/C++/Fortran application performance across modern heterogeneous hardware. Using Intel® oneAPI tools and the latest Intel® Xeon® Scalable processors, Codee achieved up to 18x performance improvement on mature, open source mathematical and cryptographic algorithms.
The Challenge of Delivering Time-Critical Code
Software solutions can be time-critical for many industries such as automotive, consumer electronics, aerospace/military, renewable energy, medical devices, and high-performance computing. For these and other industries, developing time-critical software requires adapting C/C++/Fortran source code to the characteristics of the target environment—the operating system, compiler toolchain, and target hardware, from microcontrollers and microprocessors to accelerators. Additionally, software development and testing teams must deliver code that’s cost-effective and maintainable and meets the ever-increasing business requirements of increased speed, reduced size, minimized energy consumption, and compliance with industry regulations.
As a result, software developers must follow a lengthy, expensive, trial-and-error, manual development process, demanding new tools to automate performance optimization tasks and to leverage the skills of expert performance software engineers.
For Codee, there had to be a better way.
And there was.
Empowering Developers with Shift-Left Performance
Codee is a software development platform that provides tools to help improve the performance of C/C++/Fortran applications. Its Static Code Analyzer provides a systematic predictable approach to enforce C/C++/Fortran performance optimization best practices for the target environment: hardware, compiler, and operating system. It provides innovative Coding Assistant capabilities to enable semi-automatic source code rewriting through the software development lifecycle.
Codee is a world-first solution providing a systematic, predictable approach to enforce C/C++/Fortran performance optimization best practices for CPUs and GPUs. Notably, it is the perfect complement to the best-in-class Intel® oneAPI DPC++/C++ Compilers and runtimes.
By combining Codee’s tools platform with the complementary Intel® oneAPI Base Toolkit (analysis & profiling tools, debuggers, compilers, a code-migration tool, and more), the company enabled shift-left performance by automating source code inspection tasks carried out manually by expert performance software engineers, complemented with coding assistance capabilities to actually implement performance optimizations in the C/C++/Fortran source code tailored to the Intel® oneAPI DPC++/C++ Compiler (part of the Base Kit) and Intel® Xeon® Scalable processors.
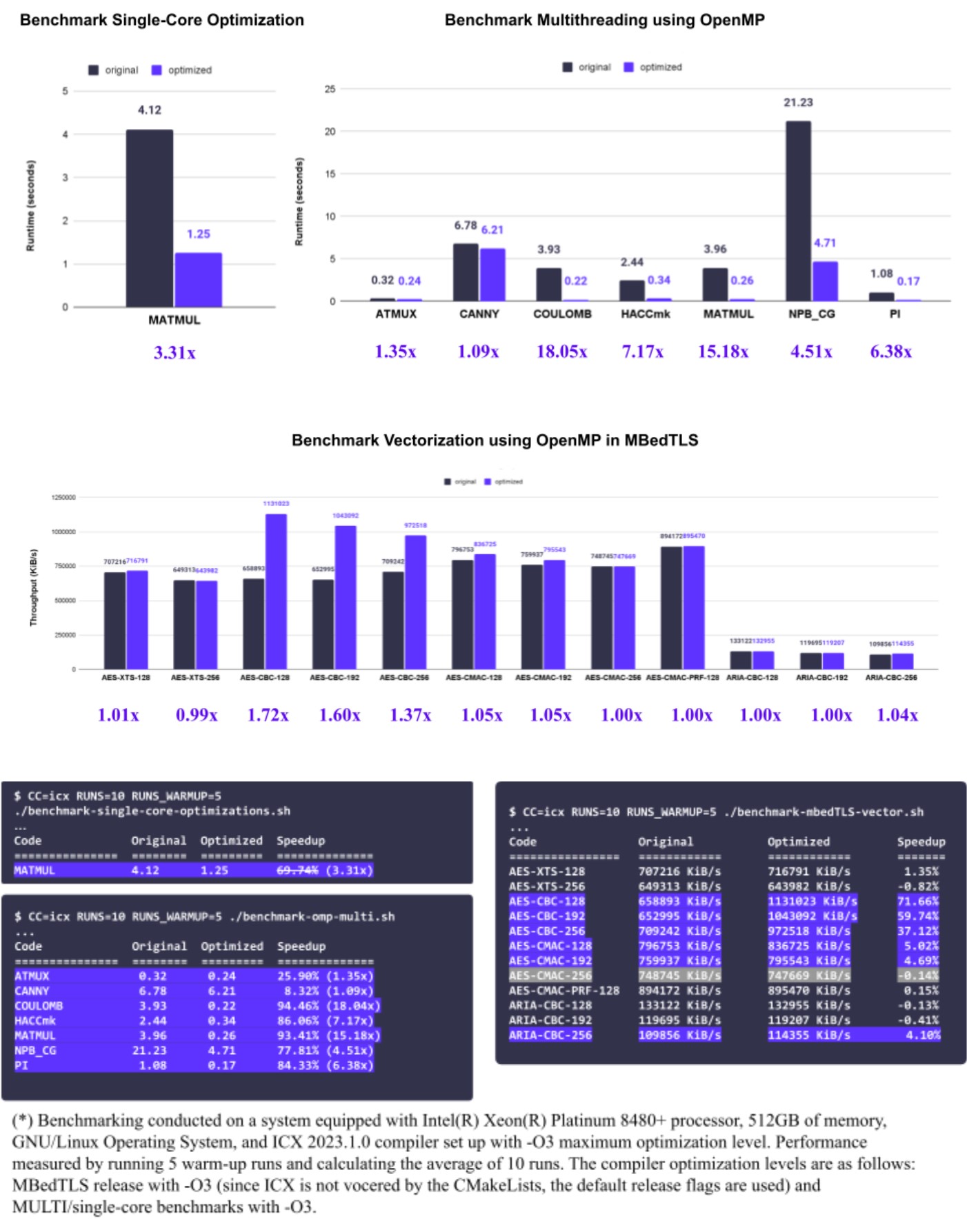
The following performance-optimization areas illustrate how Codee is a perfect complement to Intel oneAPI tools on the Intel Xeon Scalable processor*1:
- Memory efficiency: Codee enables 3.3x faster execution of matrix-matrix multiplication.
- Multithreading: Codee enables up to 18x faster execution of well-known open-source mathematical, science and engineering codes.
- Vectorization: Codee enables up to 1.7x faster execution of open-source AES encryption cryptographic code.
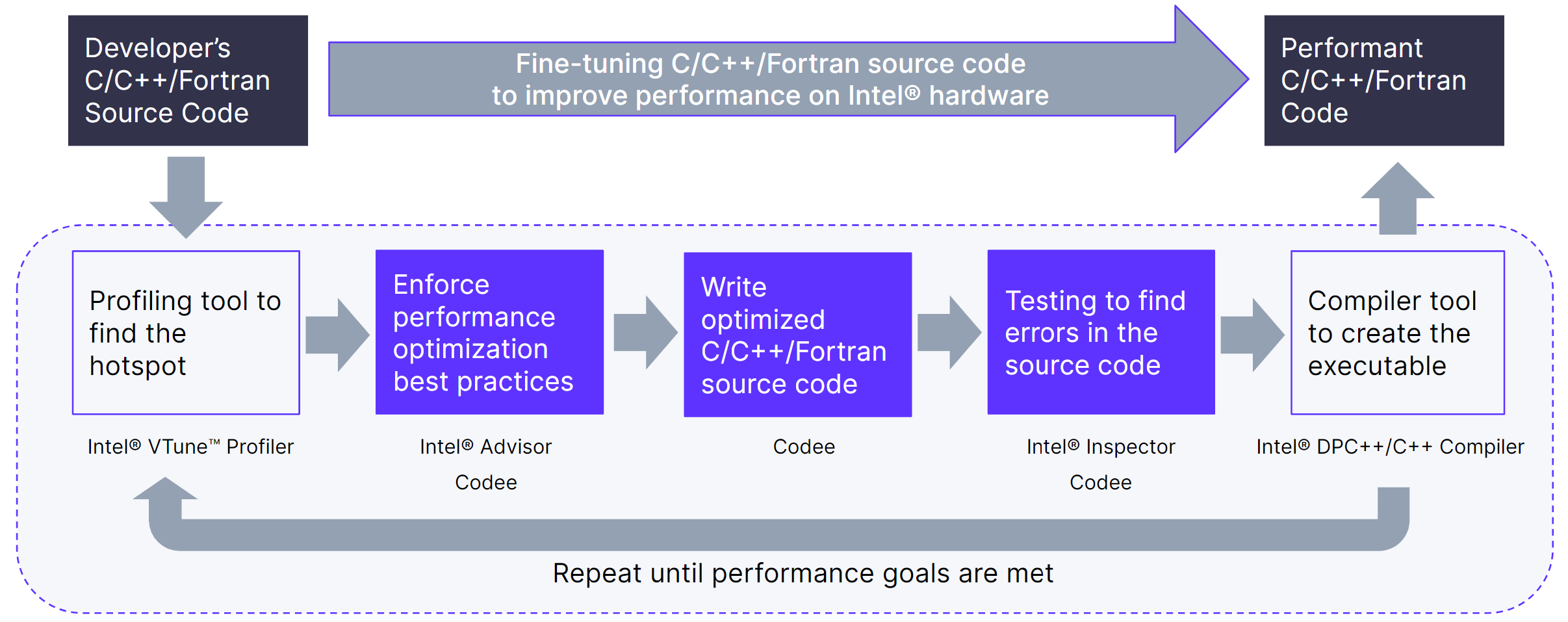
Codee’s 4-Step Optimization Approach
Codee provides a systematic predictable approach to C/C++/Fortran performance optimization, enabling developers to write faster code at an expert level, alleviating the scarcity of senior developers. For experts, it helps enforce that performance optimization best practices are applied before the final release.
Taking advantage of Codee, the development process starts with a profiling of the C/C++/Fortran code and a quick assessment of the existing performance optimization opportunities available in the code. Integrating Codee into the software development process is straightforward.
First, produce the Codee Screening Report: Invoke the “pwreport --screening” command, enabling source code checks for CPU and GPU (“--include-tags all”), passing the target source code (main.c) and its corresponding compilation flags after the special mark “--” (“-I include -fast”). In this case, the screening reported 8 checks in the source code, with the breakdown being 1 check related to scalar optimizations, 3 checks related to memory issues, 2 checks related to vectorization, 1 check related to multithreading and 1 check related to offloading.
$ pwreport --screening main.c --include-tags all -- -I include -fast
Compiler flags: -I include -fast
[C] target compiler: <none> (Compiler Agnostic Mode)
LANGUAGE SUMMARY
C files: 1
SCREENING REPORT
Target Lines of code Optimizable lines Analysis time # checks Effort Cost Profiling
------ ------------- ----------------- ------------- -------- ------ ------- ---------
main.c 55 14 22 ms 8 57 h 1865€ n/a
------ ------------- ----------------- ------------- -------- ------ ------- ---------
Total 55 14 22 ms 8 57 h 1865€ n/a
CHECKS PER STAGE OF THE PERFORMANCE OPTIMIZATION ROADMAP
Target Scalar Control Memory Vector Multi Offload Quality
------ ------ ------- ------ ------ ----- ------- -------
main.c 1 0 3 2 1 1 0
------ ------ ------- ------ ------ ----- ------- -------
Total 1 0 3 2 1 1 0
. . .
SUGGESTIONS
Use --verbose to get more details, e.g:
pwreport --verbose --screening main.c --include-tags all -- -I include -fast
You can automatically vectorize every vectorizable loop of one function with:
pwdirectives --auto --vector omp --in-place main.c -- -I include -fast
Use --checks to find out details about the detected checks:
pwreport --checks main.c --include-tags all -- -I include -fast
You can focus on a specific optimization type by filtering by its tag (scalar, control, memory, quality, vector, multi, offload), eg.:
pwreport --checks --only-tags scalar main.c -- -I include -fast
Consider using Codee with a target compiler in order to filter out optimizations that are already applied by your compiler. For example, for GCC:
pwreport --target-compiler-cc gcc --screening main.c --include-tags all -- -I include -fast
1 file successfully analyzed and 0 failures in 22 ms
Second, produce the Codee Checks Report. Dig deeper into the performance issues discovered listing all the checks found in the code, by invoking the “pwreport --checks” command. The output format is similar to other static code analyzers in order to facilitate the user uptake and integration in the development workflow.
$ pwreport --checks main.c:matmul --verbose --include-tags all -- -I include -fast
Compiler flags: -I include -fast
[C] target compiler: <none> (Compiler Agnostic Mode)
CHECKS REPORT
main.c:18:17 [PWR048]: Replace multiplication/addition combo with an explicit call to fused multiply-add
Suggestion: Replace a combination of multiplication and addition `C[i][j] += A[i][k] * B[k][j];`, with a call to the `fma` function.
Documentation: https://www.codee.com/knowledge/pwr048
main.c:9:9 [PWR053]: consider applying vectorization to forall loop
Suggestion: use pwdirectives to automatically optimize the code
Documentation: https://www.codee.com/knowledge/pwr053
AutoFix:
* Using OpenMP pragmas (recommended):
pwdirectives --vector omp --in-place main.c:9:9 -- -I include -fast
* Using Clang compiler pragmas:
pwdirectives --vector clang --in-place main.c:9:9 -- -I include -fast
* Using GCC pragmas
pwdirectives --vector gcc --in-place main.c:9:9 -- -I include -fast
* Using ICC pragmas:
pwdirectives --vector icc --in-place main.c:9:9 -- -I include -fast
main.c:15:5 [PWR035]: avoid non-consecutive array access for variables 'A', 'B' and 'C' to improve performance
Non-consecutive array access:
18: C[i][j] += A[i][k] * B[k][j];
Suggestion: consider using techniques like loop fusion, loop interchange, loop tiling or changing the data layout to avoid non-sequential access to variables 'A', 'B' and 'C'.
Documentation: https://www.codee.com/knowledge/pwr035
main.c:15:5 [PWR050]: consider applying multithreading parallelism to forall loop
Suggestion: use pwdirectives to automatically optimize the code
Documentation: https://www.codee.com/knowledge/pwr050
AutoFix (choose one option):
* Using OpenMP 'for' (recommended):
pwdirectives --multi omp-for --in-place main.c:15:5 -- -I include -fast
* Using OpenMP 'taskwait':
pwdirectives --multi omp-taskwait --in-place main.c:15:5 -- -I include -fast
* Using OpenMP 'taskloop':
pwdirectives --multi omp-taskloop --in-place main.c:15:5 -- -I include -fast
main.c:15:5 [PWR055]: consider applying offloading parallelism to forall loop
Suggestion: use pwdirectives to automatically optimize the code
Documentation: https://www.codee.com/knowledge/pwr055
AutoFix:
* Using OpenMP (recommended):
pwdirectives --offload omp-teams --in-place main.c:15:5 -- -I include -fast
* Using OpenAcc:
pwdirectives --offload acc --in-place main.c:15:5 -- -I include -fast
main.c:16:9 [PWR039]: consider loop interchange to improve the locality of reference and enable vectorization
Loops to interchange:
16: for (size_t j = 0; j < n; j++) {
17: for (size_t k = 0; k < p; k++) {
Suggestion: loop interchange can be used to improve the performance of the loop nest.
Documentation: https://www.codee.com/knowledge/pwr039
AutoFix:
pwdirectives --memory loop-interchange --in-place main.c:16:9 -- -I include -fast
main.c:17:13 [PWR010]: 'B' multi-dimensional array not accessed in row-major order
Accesses:
18: C[i][j] += A[i][k] * B[k][j];
Suggestion: change the code to access the 'B' multi-dimensional array in a row-major order
Documentation: https://www.codee.com/knowledge/pwr010
main.c:17:13 [RMK010]: the vectorization cost model states the loop is not a SIMD opportunity due to strided memory accesses in the loop body
Documentation: https://www.codee.com/knowledge/rmk010
SUGGESTIONS
More details on the defects, recommendations and more in the Knowledge Base:
https://www.codee.com/knowledge/
1 file successfully analyzed and 0 failures in 110 ms
Third, solve the performance issue by understanding its logic through the open catalog documentation and by implementing the proper fix. A memory inefficiency was pointed out by the PWR039 check, which provides an AutoFix. For this purpose, copy and paste the pwdirectives invocation suggested by the tool.
$ pwdirectives --memory loop-interchange main.c:16:9 -o main_li.c -- -I include -fast
Compiler flags: -I include -fast
[C] target compiler: <none> (Compiler Agnostic Mode)
Results for file 'main.c':
Successfully applied loop interchange between the following loops:
- main.c:16:9
- main.c:17:13
Successfully created main_li.c
Want More?
Take your continuous integration/continuous delivery (CI/CD) pipeline to the next level by adding code performance to your Shift-Left strategy:
- Explore Codee capabilities through the open catalog of performance optimization best practices for C/C++/Fortran.
- Reproduce Codee Benchmarking on your own - GitHub
Codee helps developers to speed up and improve performance, scalability, and time-to-market of the final product. Collaborating with Intel has helped us fine-tune our capabilities to streamline and improve Codee’s software solutions, filling the gap for code-performance checks in the existing CI/CD pipelines. We look forward to continuing our collaboration with Intel to add more value to our customers.
Performance Optimization Best Practices
Maximizing performance is essential across a wide range of industries and use cases, from embedded systems to high-performance computing. There are many angles to tackle performance improvement such as using the latest generation of hardware, latest releases of compilers and system libraries, and high-speed storage. This case study addresses performance optimization from the perspective of fine-tuning C/C++/Fortran source code to make it friendly to the Intel oneAPI DPC++/C++ Compiler targeting Intel Xeon Scalable processors. For the first time, Codee enables shift-left performance in the Intel developer ecosystem by providing a systematic, predictable approach to enforce performance optimization best practices on legacy and modernized C/C++/Fortran code.