| File(s): | GitHub* |
| License: | BSD 3-clause |
| Optimized for... | |
|---|---|
| Operating System: | Linux* kernel version 4.3 or higher |
| Hardware: | Emulated: See How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM) |
| Software: (Programming Language, tool, IDE, Framework) |
Intel® C++ Compiler, Persistent Memory Development Kit (PMDK) libraries |
| Prerequisites: | Familiarity with C++ |
Introduction
With Intel© Optane™ DC Persistent Memory, Intel has revolutionized the data center memory and storage hierarchy by adding a new tier that is byte addressable like memory and persistent like storage. This flexible tier can be used to expand volatile memory (Memory Mode) or to store data persistently (App Direct Mode) In this article we focus on the App Direct Mode usage.
Using Intel© Optane™ DC memory modules (Intel© Optane™ DC PMM) you can update an existing application or create a new one where you permanently store a large data set close to the CPU. Your data will be accessible at memory bus speeds for fast application restart, and byte-addressable, low latency processing.
This tutorial includes a comprehensive code example used to demonstrate how to make your application persistent memory-aware using the Persistent Memory Development Kit (PMDK), which is a collection of libraries and tools designed to facilitate programming for persistent memory. The code example leverages the libpmemobj library of the PMDK to implement a sample storage engine for the open source MariaDB*. This storage engine was created to illustrate concepts of persistent memory programming and is not part of any MariaDB distribution.
The libpmemobj library simplifies access to application data that is stored in persistent memory by adding additional features on top of traditional memory mapped files, including persistent memory pools, a transactional object store, memory allocation, persistent memory pointers and more. The code example stores data in persistent memory pools. It implements transactional functions to create, read, update and delete data and manages table indexes. With PMDK, storage engine data is protected from unplanned interruptions such as a power or application failure during a write.
This article assumes that you have a basic understanding of persistent memory concepts and are familiar with some of the elementary features of the PMDK. If not, please visit the Intel® Developer Zone’s Persistent Memory Programming site, where you'll find the information you need to get started.
Code Example Overview
MariaDB provides a pluggable architecture for storage engines. In our code example, we implement a pluggable persistent memory-enabled storage engine prototype for MariaDB. We show how to use PMDK for the basic storage engine implementation, data management, indexing, and transactions.
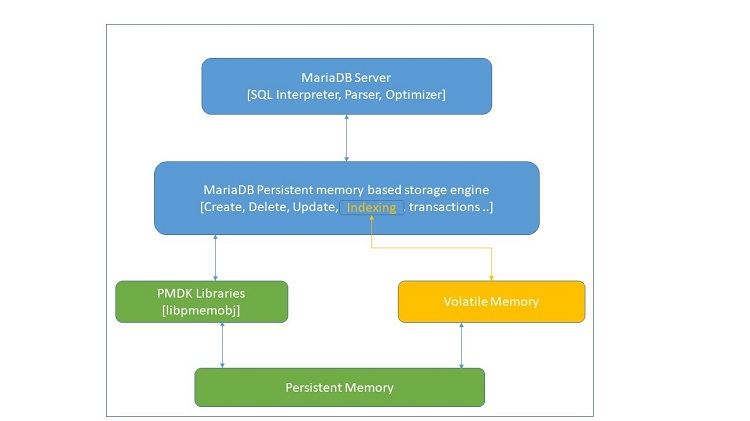
Figure 1. MariaDB storage engine architecture diagram for persistent memory
Figure 1 shows how the storage engine communicates with libpmemobj to manage the data stored in persistent memory. All of the basic functionality is implemented as a part of the plugin using guidelines from the Writing a Custom Storage Engine chapter of the MySQL* Internals Manual. For storing the objects, we used libpmemobj to turn a persistent memory file into a flexible object store that supports transactions, memory management, locking, lists, and some other features. To implement indexing, we maintain two concurrent copies of the index; one in persistent memory and another in volatile memory for faster access. The development environment we used is Ubuntu* 18.04 Virtual Machine using persistent memory emulation. Create your own emulated environment by following the instructions in How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM).
The Basic Storage Engine
The engine described in this article is a single threaded application that supports a single session, a single user and single table requests. The MariaDB server communicates with storage engines through a well-defined handler interface that includes a handlerton, which is a singleton handler that is connected to a table handler. The handlerton defines the storage engine and contains pointers to the methods that apply to the PMDK based storage engine as a whole.
The first method the storage engine needs to support is to enable the call for a new handler instance.
When a handler instance is created, the MariaDB server sends commands to the handler to perform data storage and retrieval tasks such as opening a table, manipulating rows, managing indexes, and transactions. When a handler is instantiated, the first required operation is the opening of a table. Since the storage engine is a single user and single-threaded application, only one handler instance is created in this implementation.
Various handler methods are also implemented. These methods apply to the storage engine as a whole, as opposed to methods like create() and open() that work on a per-table basis. Some examples of such methods include transaction methods to handle commits and rollbacks.
The abstract methods defined in the handler class are implemented to work with persistent memory. An internal representation of the objects in persistent memory is created using a single linked list (SLL). This internal representation is very helpful as a way to iterate through the records to improve performance.
To perform a variety of operations and gain faster and easier access to data, we used the following simple structure to hold the pointer to persistent memory and the associated field value in the buffer.
Creating a table
The create() abstract method is implemented to create the table. This method creates all necessary files in persistent memory using libpmemobj APIs. We create a new pmemobj pool for each table using the pmemobj_create() method. This method creates a transactional object store with the given total poolsize. The table is created in the form of .an obj extension.
Opening the table
Before any read or write operations are performed on a table, the MariaDB server calls the open() method to open the table data and index table. This method opens all of the named tables associated with the PMDK based storage engine at the time the storage engine starts. A new table class variable, objtab, was added to hold the PMEMobjpool. The table names for the tables to be opened are provided by MariaDB server. The index container in volatile memory is populated using the open() function call at the time of server start using the loadIndexTableFromPersistentMemory() function. The pmemobj_open() function from libpmemobj is used to open an existing object store memory pool. In addition, the table is also opened at the time of table creation if any read/ write action is triggered.
Once the Storage engine is up and running, the end user can run any database operation described below. We explain each of these operations.
Closing the table
When the server is finished working with a table, it calls the closeTable() method to close the file using pmemobj_close() and release any other resources. The pmemobj_close() function closes the memory pool indicated by objtab and deletes the memory pool handle.
Insert operation
Insert functionality is implemented in the write_row() method. During an insert, row objects are maintained in an SLL. If the table is indexed, the index table container in volatile memory is updated with the new row objects after the persistent operation completes successfully. write_row() is an important method because, in addition to the allocation of persistent pool storage to the rows, it is used to populate the indexing containers. pmemobj_tx_alloc() is used for inserts. It transactionally allocates a new object of given size and type_num.
Additionally, in every insert operation the field values are checked for a preexisting duplicate The primary key field in the table is checked using the isPrimaryKey() utility function. If the key is a duplicate, the error HA_ERR_FOUND_DUPP_KEY is returned for the insert.
Update operation
The server executes UPDATE statements by performing a rnd_init() or index_init() table scan until it locates a row matching the key value in the WHERE clause of the UPDATE statement and then calling the update_row() method. If the table is an indexed table, the index container is also updated after this operation is successful. In the method defined below, the old_data field will have the previous row record in it, while new_data will have the newest data in it.
The index table is also updated using the updateRow() method.
Delete operation
Delete is implemented using the delete_row() method. There are three different scenarios:
- Deleting an indexed value from the indexed table
- Deleting a non-indexed value from the indexed table
- Deleting a field from the non-indexed table
For these different scenarios, different functions are called. After the operation is successful, the entry is removed from both the index (if the table is an indexed table) and persistent memory.
The function deleteRowFromAllIndexedColumns() deletes the value from the index containers using the deleteRow() method. deleteNodeFromSLL() deletes the object from persistent memory.
Select operation
Select is an important operation that is required by the majority of methods. Many methods that are implemented for the select operation are called from other methods as well. The rnd_init() method is used to prepare for a table scan for non-indexed tables, resetting counters and pointers to the start of the table. If the table is an indexed table, the MariaDB Server calls the index_init() method. As shown in the code snippet below the pointers are initialized.
After the table is initialized, the MariaDB server calls the rnd_next() or index_first() or index_read_map() method depending on whether the table is a non-indexed or indexed table. These methods populate the buffer with data from the current object and point the iterator to the next value. The methods are called once for every row to be scanned.
As shown in the code snippet above, the buffer passed to the function is populated with the contents of the table row in the internal MariaDB format. If there are no more objects to read the return value must be HA_ERR_END_OF_FILE.
Indexing
Capabilities of a storage engine are quite limited without indexing. Indexing provides the basis for both rapid random lookups and efficient access of ordered records. As part of every table-write operation (INSERT, UPDATE, DELETE), the storage engine is required to update this internal index information. Indexes are implemented as a multimap container in volatile memory.
To implement indexing, containers are created to hold the values in volatile memory and provide faster row access in persistent memory.
The key class implements containers that hold key values and their corresponding persistent pointers to persistent memory rows. It uses standard multimap container to hold the table rows. In addition, the class has many functions that help in manipulating container values. The following code snippet shows the definition of the key class used to create the indexing implementation.
The table_ class contains the list of indexed keys. The container uses the unordered map to hold the keys It also has similar methods to get and set the values.
Likewise, the database class is a singleton class that holds the value of the list of tables currently in the database. These values are saved in the tables variable in an unordered map. Various functions are also implemented to get the table, delete the table, and insert a value into the table container.
Indexes are populated at the time of the table’s open() function call. To achieve indexing, various methods are implemented in the PMDK storage engine. These are listed below.
index_init
As described before, this method is called before an index is used to allow the storage engine to perform any necessary preparation or optimization. The necessary pointers and iterators are assigned to this method.
index_read_map
This method positions an index cursor to the key specified in the parameters, which is passed to this method from the MariaDB server. The key is converted using the IdentifyTypeAndConvertToString() utility function and checked against the index key maintained by the storage engine in volatile memory using utility function verifyKey(). If there is a match, this function sets the row in the indexed table.
index_first
This method positions an index cursor to the first position in the index table. It populates the buffer with the first row in the index. In the code snippet below, the function finds the first row from the multimap container and sets the buffer value and SLL current pointer to this row.
index_next
This method is implemented in a similar way to index_first(). It is used for index scanning. The buffer variable is passed to the MariaDB server, where it is populated with the row that corresponds to the next matching key. The rowItr currEle = k1->getCurrent() gets the next element from index map.
index_end
This method is a counterpart to the index_init() method. The purpose of index_end() is to clean up any preparations made by the index_init() method.
Transactions
As mentioned before, we have handler methods for transaction management to handle commits and rollbacks. A transaction can be defined as a group of tasks implicitly started through calls to either start_stmt() or external_lock(). If the preceding methods are called, and a transaction already exists, the transaction is not replaced. The persistent memory enabled storage engine stores transaction information in the memory.
external_lock
In the external_lock() function to support rollback, we are taking a backup of the index table so that we can save the current session of index tables. For tables in persistent memory, there are functions already supported for rollback by libpmemobj. The function also registers the transaction in persistent memory and MariaDB server using trans_register_ha function to allow the server to later issue COMMIT and ROLLBACK operations.
The external_lock() method is called at the start of a statement. With this, the storage engine registers the transaction with MariaDB and calls the transaction related function for persistent memory (pmemobj_tx_begin). The pmemobj_tx_begin() function starts a new transaction in the current thread. pmemobj_tx_begin() will acquire all locks prior to successful completion, and they will be held by the current thread until the outermost transaction is finished. If another task is added during this process, it throws an error and does not allow the process to run.
start_stmt
Another method that can start a transaction in the storage engine is the start_stmt() function. In the case where a table was locked previously by a LOCK TABLES command, external_lock() is not called. In that case, the start_stmt() method is called.
pmdk_rollback
Using rollback, all operations that occurred during the transaction are reversed such that all rows are unchanged from before the transaction began. For implementing rollback, pmemobj_tx_abort() and pmemobj_tx_end() functions are used from libpmemobj .pmemobj_tx_abort() aborts the current transaction and causes a transition to TX_STAGE_ONABORT. For indexed tables, we are getting the previous session saved before the transaction. Rollback is implemented as:
pmdk_commit
During a commit operation, all changes made during a transaction are made permanent, and a rollback operation is not possible after that. To commit into persistent memory, we have used the pmemobj_tx_commit() function from libpmemobj. The pmemobj_tx_commit() function commits the current open transaction and causes a transition to TX_STAGE_ONCOMMIT. To close the transaction we use the pmemobj_tx_end() function provided by libpmemobj. The pmemobj_tx_end() function performs a cleanup of the current transaction. If called in the context of the outermost transaction, it releases all the locks acquired by pmemobj_tx_begin() for outer and nested transactions. To support COMMIT, the function is defined as:
In these functions, the THD parameter is used to identify the transaction that needs to be rolled back, while the bool parameter indicates whether to roll back the entire transaction or just the last statement.
Using the Storage Engine
This persistent memory-enabled MariaDB storage engine code example is open source and available in the PMDK GitHub repository. To use the storage engine, follow these steps:
- Install the PMDK libraries.
- Download/clone the pmdk-examples repo
git clone https://github.com/pmem/pmdk-examples.git - Go to the pmem-mariadb folder.
- Compile the MariaDB, so that the PMDK storage engine binaries are generated.
- From the MariaDB client prompt, use the following command to install the PMDK storage engine.
INSTALL PLUGIN PMDK SONAME 'ha_pmdk.so'; - After the plugin is successfully installed, tables can be created by providing the suffix for the storage engine. For example:
CREATE TABLE customers( customer_id int NOT NULL, customer_name char(50) NOT NULL,address char(50),city char(50),zip_code char(10)) ENGINE= 'PMDK';
Summary
Use of persistent memory in your application can provide continuity in the event of an unplanned system shutdown along with improved performance gained by storing your data close to the CPU where you can access it at memory bus speeds.
The Persistent Memory Development Kit is a fully validated, performance-tuned set of libraries designed to make it easier to convert an existing application or create a new one to take advantage of persistent memory. Using a MariaDB storage engine that we created as an example, we illustrated the major PMDK functionality required for persistent memory applications.
Learn more about PMDK and Intel Optane DC Persistent Memory by visiting the links in the Resources section below, then use these materials to get started with your own persistent memory project.
Technical questions? Visit the pmem Google* Group.
Resources
The Intel Developer Zone Persistent Memory site
Learn about PMDK at pmem.io
How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM)
The Non-Volatile Memory (NVM) Programming Model (NPM)