AUTHOR:
Adam Straw
Adam Procter
Robert Earhart
The rapid growth of deep learning (DL) in large-scale, real-world applications has produced a sharp increase in the demand for high-performance training and inference solutions. This demand is reflected in the growing investment in DL performance by major hardware manufacturers, including a proliferation of application-specific accelerators.
Of course, performance isn’t driven by hardware alone. In the software realm, new deep learning compilers are helping to maximize the performance and scalability of deep learning systems while increasing the productivity of AI developers.
At this week’s Artificial Intelligence Conference, presented by O’Reilly and Intel and held in New York City, we’ll lead a session that provides a comprehensive overview of nGraph, an open source deep learning compiler, library and runtime suite. The session will take a deep dive into the design of nGraph, including the compiler’s intermediate representation, optimization pipelines, runtime interface, and framework integration. We’ll also discuss the rationale for the development of nGraph and show the benefits it offers to developers creating DL applications for the enterprise, as well as to AI service providers and hardware vendors that want to deliver flexible, performant DL technologies to their users and customers.
nGraph supports a range of deep learning frameworks (TensorFlow*, PyTorch*, MXNet*, etc) and hardware back-ends (CPUs, GPUs, specialized accelerators) and delivers dramatic performance improvements on a range of platforms. Figure 1 depicts benchmark results that show how nGraph can deliver as much as a 45x increase in normalized inference throughput leveraging MKL-DNN on Intel® Xeon® Scalable processors. [1]
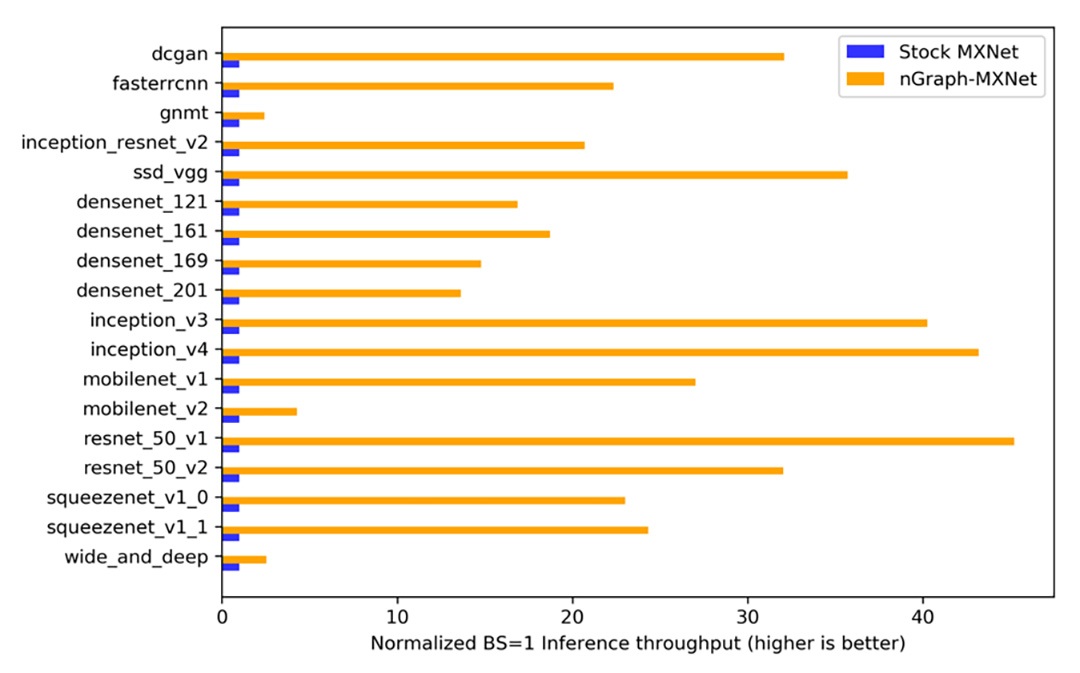
Figure 1. Normalized inference throughput (images per second with a batch size of 1) across several models comparing stock Apache* MXNet* (not based on MKL-DNN) (blue) and with nGraph-compiled MXNet (orange) leveraging MKL-DNN on the same Intel® Xeon® Scalable processor-based backend. [1]
Beyond Kernel Libraries
Increasing levels of deep learning performance are crucial to keeping pace with the rapid expansion in models and data set sizes. The state-of-the-art software approach to DL acceleration has been to integrate high performance kernel libraries such as Intel® Math Kernel Library for Distributed Neural Networks (Intel® MKL-DNN) into deep learning frameworks.
Kernel libraries offer runtime performance on specific hardware targets though highly optimized kernels and operator-level optimizations. But kernel libraries, in which an interpreter orchestrates the invocation of per-operation compute kernels, can be hard-pressed to handle the rising complexity of today’s changing industry requirements. Here are three major reasons:
- Kernel libraries do not support graph-level optimization. Although each operation may be optimal, the graph itself may not be, resulting in inefficient execution of duplicate operations.
- With the growing diversity in DL hardware, the number of distinct kernels that must be written is becoming untenable. For optimal performance, each kernel must be modified for the targeted chip design, data types, operations, and parameters. This creates a large burden that must be revisited each time the infrastructure is upgraded or the DL solution is applied to a different workload.
- Framework integration of kernel libraries does not scale. Each deep learning framework must be integrated individually with a given kernel library, and each integration is unique to the framework and its set of deep learning operators, its view on memory layout, its feature set, and so forth.
nGraph uses high performance kernel libraries such as MKL-DNN to enable the best performance of the underlying hardware. In addition, nGraph provides graph-level optimizations that can be shared across multiple frameworks and target hardware platforms. nGraph also offers a universal way of interacting with deep learning frameworks through an intermediate representation of the deep learning graph.
By combining intermediate graph representations with the open source tensor compiler PlaidML* and Microsoft’s open source Open Neural Network Exchange* (ONNX*), nGraph delivers performance portability across a wide range of DL frameworks and a variety of CPU, GPU, and other accelerator processor architectures. (See Figure 2.) Developers and solution providers can enhance productivity by using a single API to produce efficient, highly performant DL solutions. This approach also preserves the flexibility to keep pace with changing workload requirements and new frameworks and platforms. Hardware platforms that don’t have a kernel library or don’t have the exact kernel they need, can use PlaidML to help simplify the work of creating new kernels. The PlaidML framework generates efficient kernels automatically from polyhedral tensor expressions, transforming graph-level operations requested by nGraph into optimized device-specific implementations.
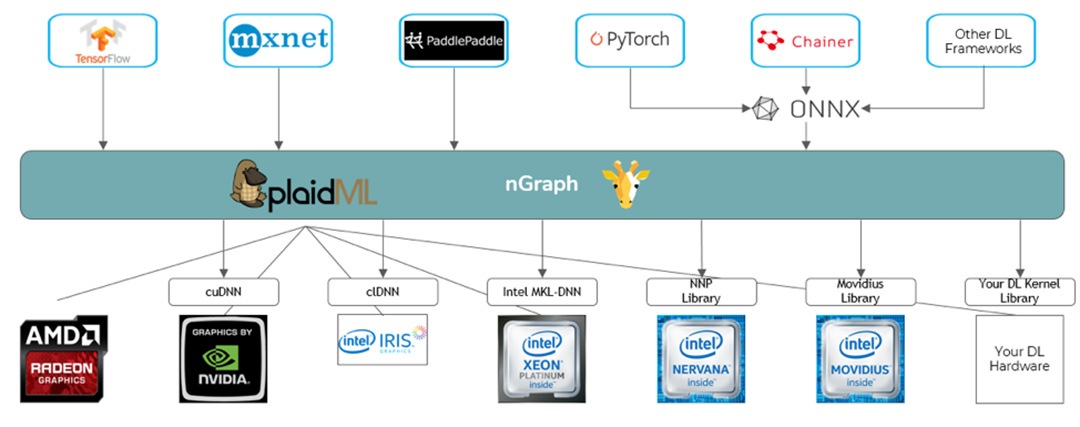
Figure 2. nGraph ecosystem. nGraph has support for TensorFlow*, MXNet* directly through nGraph and PlaidML. PyTorch*, Chainer*, and other frameworks are supported indirectly through ONNX*.
Go Further
We encourage you to attend our session today at 11:05 a.m. EDT and stop by our booth to learn more. Whether you attend the AI Conference or not, we hope you’ll visit the GitHub repository, download nGraph, try it out, and add your contributions. The current, beta version of nGraph is open source and works out of the box with TensorFlow*, MXNet*, and ONNX, with planned support for PaddlePaddle*, so please clone the repo and get started! Watch for the Gold Release 1.0 version of nGraph coming this year, and follow us @IntelAI for the latest happenings at #TheAIConf in NYC.
Additional Resources:
- Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning. Scott Cyphers et al. SysML 2018
- nGraph-HE: A Graph Compiler for Deep Learning on Homomorphically Encrypted Data. Fabian Boemer, Yixing Lao, and Casimir Wierzynski
- Reintroducing PlaidML. Choong Ng
- Explore Intel’s product portfolio for AI.
Notices and Disclaimers:
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/benchmarks.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Performance varies depending on system configuration. No product or component can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com.
[1] Benchmarks were measured by Intel Corporation on October 10, 2018 using a custom automation wrapper around publicly available model implementations. Gluon models DCGAN, Densenet, and Squeezenet were converted to static graphs via standard module APIs. Performance tests were performed with real data and random weights initialized with the Xavier initializer. Hardware configuration: 2S Intel® Xeon® Scalable Platinum 8180 processor @ 2.50GHz (28 cores), HT enabled, turbo enabled, scaling governor set to "performance" via intel pstate driver, microcode version 0x200004d, Intel Corporation Bios Version SE5C620.86B.00.01.0014.070920180847, 384GB (12 * 32GB) DDR4 ECC SDRAM RDIMM @ 2666MHz (Micron* part no. 36ASF4G72PZ-2G6D1), 800GB SSD 2.5in SATA 3.0 6Gb/s Intel Downieville SSDSC2BB800G701 DC S3520, client Ethernet adapter: Intel PCH Integrated 10 Gigabit Ethernet Controller
Software configuration: Ubuntu* 16.04.3 LTS (GNU/Linux* 4.4.0-109-generic x86_64), base MXNet version https://github.com/apache/incubator-mxnet/tree/064c87c65d9a316e5afda26d54ed2c1e6f38e04f and ngraph-mxnet version https://github.com/NervanaSystems/ngraph-mxnet/tree/a8ce39eee3b5baea070cefea0aa991f6773ba694 and Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) version 0.14. Both tests used environment variables OMP_NUM_THREADS=28 and KMP_AFFINITY=granularity=fine, compact,1,0.
Intel, Xeon, and the Intel logo are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries.
*Other names and brands may be claimed as the property of others.
© Intel Corporation