Basic Diagnostics for Correctable/Uncorrectable ECC Memory Errors with Intel® Server Boards
Content Type: Troubleshooting | Article ID: 000024007 | Last Reviewed: 02/11/2025
| Note | For support of troubleshooting described in this article, please refer to the Technical Product Specifications for your server platform. |
What am I seeing?
Correctable and/or Uncorrectable Error Correcting Code (ECC) events for memory modules. For example:
Mmry ECC Sensor SMI Handler Warning Memory CPU: 1, DIMM: D0 DIMM Rank: 1. - Correctable ECC / other correctable memory error - Asserted.
What is Memory Error Correction Code (ECC) Correctable Error Event?
ECC correctable error represents a threshold overflow for a given Dual In-line Memory Modules (DIMM) within a given timeframe.
How to fix it:
Memory data errors are logged as correctable or uncorrectable. Refer to the instructions below, based on the error type you encounter:
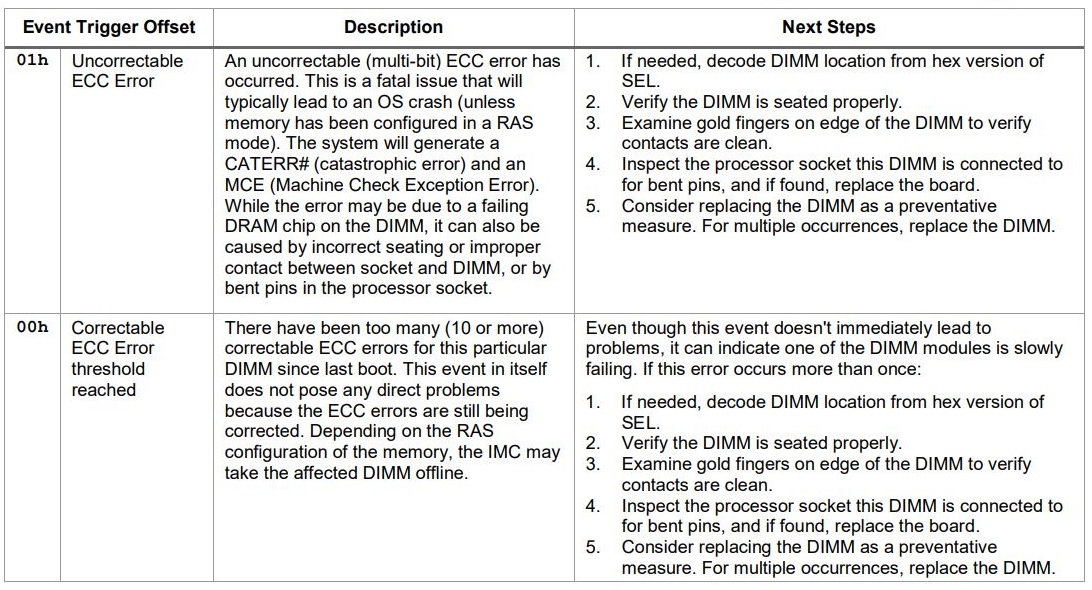
| Notes |
|
| Notes | The Error Correction Code (ECC) errors are self-correcting. Depending on the Reliability Availability Serviceability (RAS) configuration of the memory, the Integrated Memory Controller (IMC) may take the affected DIMM offline. |
| For different Intel server platforms, there are some differences in their event definition, refer to System Event Log Troubleshooting Guide for your server platform | |
| Intel recommends downloading and updating the system BIOS to the latest available version for your server platform. | |
| If the system is an Intel® Data Center Block for Nutanix* Enterprise Cloud, rather, visit the Nutanix* Life Cycle Manager page. For a list of hardware and firmware compatibility, visit the Nutanix* Hardware and Firmware compatibility page. |