Accelerate GenAI Deployment with Intel® AI for Enterprise Inference
An open source, native large language model (LLM) serving stack designed for Intel® Xeon® processors and Intel® Gaudi® AI accelerators, deployable on cloud and on-premises environments.
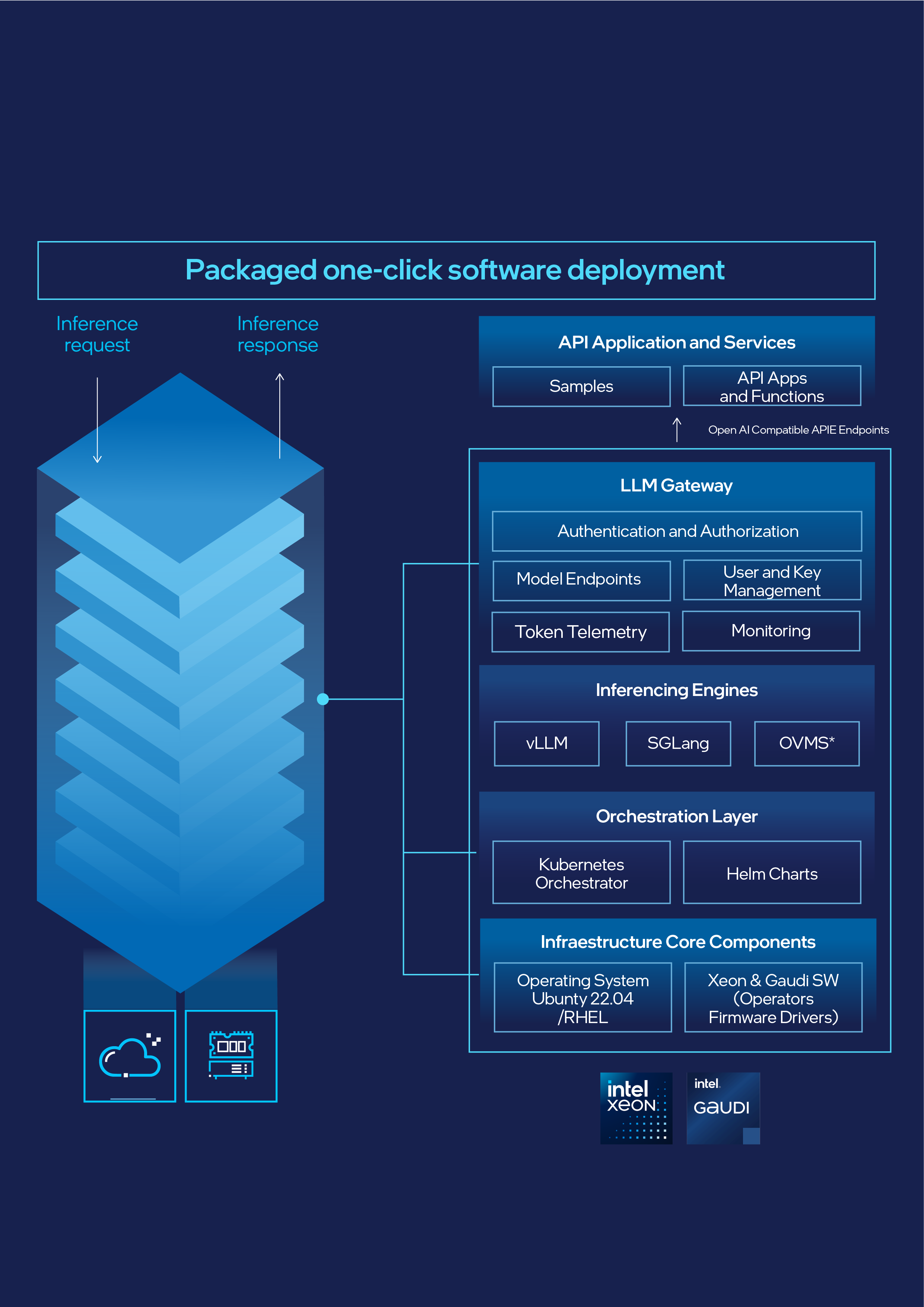
Intel® AI for Enterprise Inference makes it simpler for developers to run generative AI (GenAI) models at scale—securely, efficiently, and with minimal set up. Whether you’re building copilots, integrating summarization into workflows, or running batch inference jobs, this solution delivers production-grade results with open standards and a developer-first design.
Production-Ready Inference in Minutes
This modular, packaged solution integrates seamlessly with your existing applications and supports OpenAI*-compatible endpoints. Developers can go from testing to production without rewriting infrastructure or retraining workflows.
Key capabilities include:
- Prebuilt API endpoints and token-based access
- Support for leading open source models (LLaMA, Mistral AI*, Whisper*, Stable Diffusion*, and more)
- Full bring-your-own-model (BYOM) compatibility and versioning
- GitHub*-hosted, open source deployment assets
Scalable Performance
Intel AI for Enterprise Inference intelligently routes workloads based on performance needs:
- Intel Xeon processors for low-latency, real-time tasks like chat and summarization
- Intel Gaudi AI accelerators for high-throughput tasks such as batch inference and image generation
Its vLLM-based architecture improves memory efficiency, supports concurrent inference, and delivers faster response times across use cases.
On a single card, Intel® Gaudi® 3 AI accelerators on IBM Cloud* can generate over 5,000 tokens per second for the IBM* granite-8b model, supporting over 100 concurrent users with an inter-token latency of fewer than 20 milliseconds.
Secure, Scalable, and Enterprise-Ready
Built with enterprise security in mind, the platform includes:
- Open Authorization (OAuth) 2.0 and token-based permissions
- Encrypted communication between components
- Support for hybrid, private, and regulated deployments
- Kubernetes*-native observability and autoscaling tools
Integration Capabilities
- Connect with enterprise tools like Slack*, Microsoft SharePoint*, Jira*, and continuous integration and continuous delivery (CI/CD) pipelines to embed AI capabilities directly into your workflows.
- Build custom AI applications using orchestration frameworks like LangChain and retrieval augmented generation (RAG).
- Monitor performance and dynamically scale resources with Kubernetes-native observability and autoscaling tools.
Community and Support
- Access open source code, deployment assets, and detailed documentation through the GitHub Repository.
- Get ongoing support through the Intel® Tiber™ AI Cloud with forums, technical discussions, and product updates.
Deployment Options That Fit Your Environment
Denvr Cloud*: optimized for scalable GenAI workloads (coming in Q3 2025)
IBM Cloud: integrated with an enterprise-native infrastructure
RedHat OpenShift offering coming in Q3 2025
AWS Xeon Offering and Azure Xeon Offering;
Xeon 4th generation and above – both as coming in Q3 2025
Self-hosted Kubernetes: complete flexibility and control
Designed for Developer Velocity
Whether you're launching internal agents, building custom image generators, or deploying speech analytics at scale, Intel AI for Enterprise Inference helps you move faster.
Get started today through Denvr Cloud or IBM Cloud, or explore the open source stack on GitHub.