If you are familiar with the Intel® Integrated Performance Primitives (Intel® IPP) library you know that it is widely used to build applications built for the Microsoft* Windows* and Linux* operating systems – today's most prevalent "standard" desktop and server operating system (OS) platforms. What you may not know is that the Intel IPP library can also be used with applications built for some embedded and real-time operating systems (RTOS). It's not possible to build an IPP application for use on every embedded OS, but if your embedded platform and development tools meet a few key conditions, you might be able to take advantage of the SIMD acceleration provided by this library in your embedded application on a "non-standard" operating system.
For more information about what's required to use the Intel IPP library with your embedded application on a non-standard OS see the article titled Using the Intel® IPP Library in an Embedded System – on Non-Standard Operating Systems. Below you can find description of the common linkage options available for the library and understand how those affect the overall size of your Intel IPP application.
Linkage Options
On the Windows and Linux platforms the Intel IPP library is available in dynamic (shared) library and static forms. There are no functional differences between these two library variants, both contain the same set of functions. Deciding which linkage model to use depends on how you choose to build and deploy your application. The tradeoff is complexity versus size versus flexibility. Dynamic linkage allows multiple applications to share code and, potentially, reduce the overall size of the deployment, but only if enough applications share the common library. Static linkage is simpler to deploy and results in a smaller code footprint if a small number of functions in the library are used (< a few hundred) or the library is used by only a few applications.
Since every embedded environment has its own unique set of constraints, you should consider the installation and runtime constraints unique to your situation, as well as the development resources available and the release, update, and distribution needs of your application. Reviewing the following questions will help you guide that decision process:
- Executable and installation package size.
Are there limits to the size of the application executable? Are there limits to the size of the installation package? - File locations at installation time.
During installation, are there restrictions on where application files and shared libraries can be placed? - Number of coexisting Intel IPP–based applications.
Does the application include multiple executables based on the Intel IPP library? Are there other Intel IPP applications that may coexist on the system? - Memory available at runtime.
What memory constraints exist on the deployed system? - Kernel-mode versus user-mode.
Is the Intel IPP application a device driver or other “ring 0” application that will execute in kernel-mode? - Number of processor types supported by the Intel IPP application.
Will the application be installed on systems with a range of SIMD instruction sets, or is the application intended for use on a well-defined set of processors that support only one SIMD instruction set? - Development resources.
What resources are available for maintaining and updating custom Intel IPP components? What level of effort is acceptable for incorporating new processor optimizations into the application? - Release, distribution, and update.
How often will the application be updated? Can application components be distributed independently or are they always packaged together?
The following table compares the four most common linkage models used to build Intel IPP applications. Size, performance and flexibility tradeoffs are the same, regardless of the OS. (Note that if you are applying the Intel IPP library to an embedded OS other than Windows or Linux the standard dynamic link option may not be a viable option – see this article for more information.)
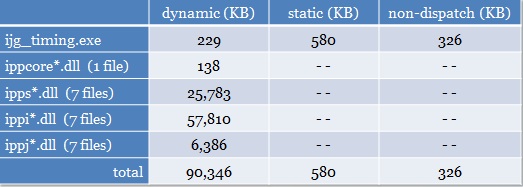
Standard Dynamic
The standard distribution dynamic library is ready-to-use for both development and deployment. This version of the library includes the full set of processor optimizations and provides the benefit of runtime code sharing between multiple Intel IPP-based applications. Detection of the runtime processor, and dispatching to the appropriate optimization layer is completely automatic.
Benefits of this model include:
- Automatic runtime dispatch of processor-specific optimizations
- Ability to distribute minor updates without a recompile or relink
- Share a single library distribution among multiple Intel IPP executables
- More efficient use of memory at runtime for multiple Intel IPP applications
Considerations to keep in mind when using this model include:
- Potentially very large deployment (install) package size
- Application executable requires access to Intel IPP runtime DLLs (shared objects)
- Not appropriate for kernel-mode (ring-0) and/or device-drivers
- Potential performance penalty on first load of DLLs (SOs)
Custom Dynamic
If your application needs dictate the use of a dynamic library but the standard DLL (SO) files are too large, you may benefit from building a custom dynamic library (from the static library files), especially if the number of Intel IPP functions used in your application is small (which is the case for most Intel IPP applications).
Benefits of this model include:
- Automatic runtime dispatch of processor-specific optimizations
- Ability to distribute minor updates without a recompile or relink
- Share a single library distribution among multiple Intel IPP executables
- More efficient use of memory at runtime for multiple Intel IPP applications
- Substantially reduced footprint compared to standard DLLs (SOs)
Considerations when using this model include:
- Application executable requires access to custom DLLs (SOs)
- Not appropriate for kernel-mode (ring-0) and/or device-drivers
- Potential performance penalty when DLLs (SOs) are first loaded
- Additional effort required to create and maintain your custom DLL (SO)
Dispatched Static
The dispatched static library is one of the simplest options to use for building an Intel IPP application. It is also the simplest to deploy, since no separate DLL (SO) files are need to be distributed. The standard static library is provided ready to link and includes the full set of processor optimizations. Detection of the runtime processor and dispatching to the appropriate optimization layer within the library is automatic (be sure you call the appropriate ippInit() function before using the library).
Linking against a static library has the advantage of avoiding shared library version conflicts (aka “DLL hell”) and includes only those functions your application requires. When using the static library, your application includes all the optimization layers required to support all processors supported by the library, but only for those functions called by your application. This approach provides an excellent tradeoff between size, performance and deployment complexity. Distributing applications built with the static library is very simple because the application executable is complete and self-contained.
Benefits of this model include:
- Automatic runtime dispatch of processor-specific optimizations
- Simple recompile/relink/redistribute executable for library updates
- Single self-contained application executable
- Smaller footprint than most DLL (SO) distributions
- Appropriate for real-time and non-supported embedded operating systems
Considerations when using this model include:
- Intel IPP code may be duplicated across multiple executables
Non-Dispatched Static
If you need to minimize the footprint of your Intel IPP application, you might consider linking against a non-dispatched static version of the library. The development process is only slightly more complex than that required of the standard dispatched static library but yields an executable containing only the optimization layer required by your target processor. This model achieves the smallest footprint at the expense of restricting your optimization to one specific processor type (one SIMD instruction set).
This linkage model is most appropriate when only one processor type (or SIMD instruction set) is required on the target hardware. It is also the recommended linkage model for use in kernel-mode (ring-0) and/or device-driver applications – although the dispatched static model is also applicable. A common use for this model is embedded applications where the application is guaranteed to be executed on one processor type (for example, an Atom processor platform).
Benefits of this model include:
- Smallest total size with support for only one processor (SIMD) type
- Suitable for kernel-mode (ring-0) and/or device-driver applications
- Single self-contained application executable
- Smaller footprint than most DLL (SO) distributions
- Appropriate for real-time and non-standard embedded operating systems
Considerations for using this model include:
- Intel IPP code may be duplicated across multiple Intel IPP executables
- Executable will run on only the optimized processor type (or greater)