Overview
When using generative AI (GenAI), fine-tuning large language models (LLM) like Llama 2 presents unique challenges due to the workload computational and memory demands. However, using LoRA on Intel® Gaudi® AI accelerators presents a powerful option for tuning state-of-the-art (SOTA) LLMs faster and at a reduced cost. This capability makes it easier for researchers and application developers to unlock the potential of larger models.
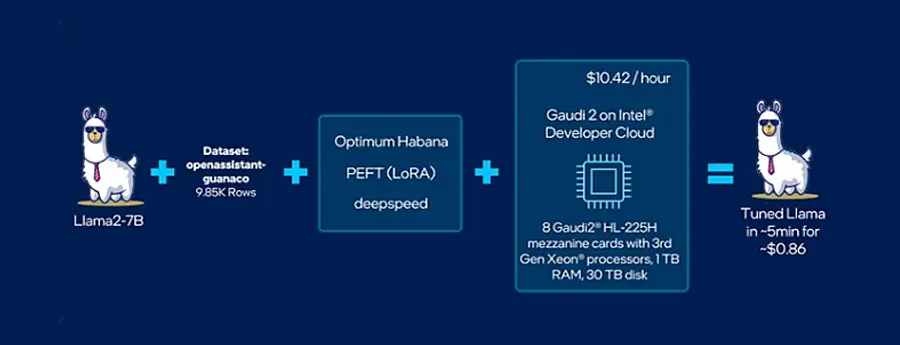
Figure 1. The workflow for fine-tuning a Llama 2 model on Intel® Gaudi® AI accelerators on the Intel® Tiber™ AI Cloud
This tutorial explores using LoRA to fine-tune SOTA models like Llama-2-7B-hf in under six minutes for approximately $0.86 on the Intel Developer Cloud (Figure 1). It covers the following topics:
- Setting up a development environment for LoRA fine-tuning on Intel® Gaudi® AI accelerators
- Fine-tuning Llama 2 with LoRA on the openassistant-guanaco dataset using the Optimum Habana Hugging Face* library and Intel® Gaudi® processors
- Performing inference with LoRA-tuned Llama2-7B-hf and comparing response quality to a raw pretrained Llama 2 baseline
Use this article's insights and sample code to enhance your LLM model development process. You can quickly experiment with various hyperparameters, datasets, and pretrained models, ultimately speeding up the optimization of SOTA LLMs for your GenAI applications.
Introduction to Parameter-Efficient Fine-Tuning with LoRA
At its core, the theory behind LoRA revolves around matrix factorization and the principle of low-rank approximations. In linear algebra, any given matrix can be decomposed into several matrices of lower rank. In the context of neural networks, this decomposition can be viewed as breaking down dense, highly parameterized layers into simpler, compact structures without significant loss of information. By doing so, LoRA aims to capture a model's most influential parameters or features while discarding the extraneous ones.
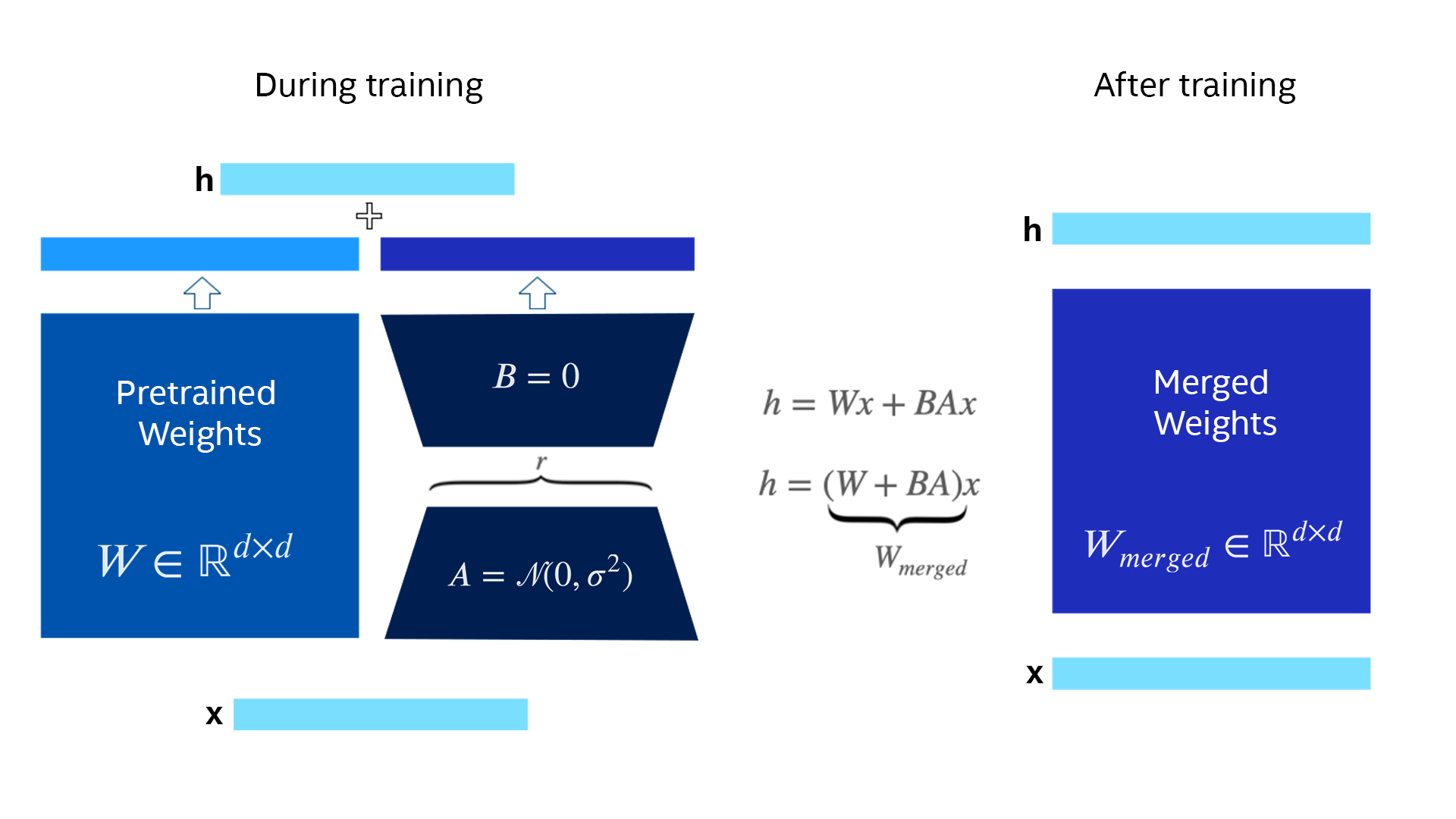
Figure 2. Illustration of LoRA during and after training.
More information can be found in the LoRA conceptual guide.
Why does this low-rank approach work, especially in large-scale neural networks? The answer lies in the intrinsic structure of the data these models deal with. High-dimensional data, like those processed by deep learning models, often reside in lower-dimensional subspaces. Essentially, not all dimensions or features are equally crucial. LoRA taps into this principle by creating an effective subspace where the neural network's parameters live. This process involves introducing new, task-specific parameters while constraining their dimensionality (using low-rank matrices), thus ensuring they can be efficiently fine-tuned on new tasks. This matrix factorization trick enables the neural network to gain new knowledge without retraining its entire parameter space, providing computational efficiency and rapid adaptability to new tasks.
Environment Setup
Hardware can be obtained from the Intel® Tiber™ AI Cloud, if required. Cloud instances of Intel® Gaudi® AI accelerators are also available. To get started, see these instructions.
Once connected to the Intel® Gaudi® AI accelerator platform, run the following git command to clone the Gaudi-tutorials repository:
git clone https://github.com/HabanaAI/Gaudi-tutorials.git
Use the instructions found in the top level README.md of the Gaudi-tutorials repository to setup the container and Jupyter Lab environment required for the llama2 fine tuning inference tutorial.
Fine-Tune Llama-2-7B-hf with PEFT (LoRA)
Now that your environment is set up, to run the sample, do the following:
In the file tree, navigate to the folder Gaudi-tutorials/PyTorch/llama2_fine_tuning_inference/, and then open the following notebook: llama2_fine_tuning_inference.ipynb
Note Although instructions are provided on this page, users should be able to execute commands through the Jupyter environment.
Access the model. Start with a foundational Llama-2-7B-hf model from Hugging Face, and then for causal language-modeling text generation, fine-tune it on the openassistant-guanaco dataset. Some things to note:
- The openassistant-guanaco dataset is a subset of the Open Assistant Dataset. This subset only contains the highest-rated paths in the conversation tree, with 9,846 samples.
- Using the Llama 2 model requires you to accept Meta* license terms before accessing the model through the Transformers library. Using the pretrained model is subject to compliance with third-party licenses. For details, see Llama 2 Community License Agreement.
Log into Hugging Face by running the following (Note this requires a Hugging Face account):
huggingface-cli login --token <your token here>
To deliver the highest performance on Intel® Gaudi® AI accelerators, install three libraries:
- Habana DeepSpeed*: Enables ZeRO-1 and ZeRO-2 optimizations on processors for Intel® Gaudi® AI accelerators. To install, run:
pip install -q git+https://github.com/HabanaAI/DeepSpeed.git
- Parameter Efficient Fine Tuning (PEFT): This library efficiently adapts pretrained models by only tuning a few parameters. This library enables LoRA, a subset of PEFT. To install, run:
git clone https://github.com/huggingface/peft.git
cd peft
pip install -q
- Optimum-Habana: Abstracts away lower-level libraries to make it easy to interface between processors for Intel® Gaudi® AI accelerators accelerator processors and the most popular APIs for Hugging Face. To install, run:
pip install -q --upgrade-strategy eager optimum[habana]
For language modeling, access the requirements files in optimum-habana/examples/language-modeling/requirements.txt, and then to install them into the environment:
cd optimum-habana/examples/language-modeling/
pip install -q -r requirements.txt
Start the fine-tuning process using the PEFT method, which refines only a minimal set of model parameters, significantly cutting down on computational and memory load. PEFT techniques have recently matched the performance of full fine-tuning. The procedure involves using language modeling with LoRA through the run_lora_clm.py command:
python ../gaudi_spawn.py --use_deepspeed \
--world_size 8 run_lora_clm.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--bf16 True \
--output_dir ./model_lora_llama \
--num_train_epochs 2 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 4 \
--evaluation_strategy "no"\
--save_strategy "steps"\
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 1e-4 \
--logging_steps 1 \
--dataset_concatenation \
--do_train \
--use_habana \
--use_lazy_mode \
--throughput_warmup_steps 3
Here are descriptions of some of the parameters in the previous command:
--use_deepspeed : enables the use of DeepSpeed. --world_size 8 : set the number of accelerators to 8. --bf16 True : enables half-precision training bf16. --num_train_epochs 2 : sets the number of epochs to 2. --use_habana : allows training to run on Intel Gaudi AI accelerators.
The loss flattens at 1.5 epochs so setting the number of training epochs to 2 ensures optimal training. This value varies based on other hyperparameters, datasets, and pretrained models, however, and is not always appropriate. Each Intel® Gaudi® AI accelerator node contains eight Intel Gaudi AI accelerator cards, setting the world size value to 8 uses all the cards on the node.
Using these parameters, just 0.06% of the massive 7B parameters are adjusted and, thanks to DeepSpeed, memory use is capped at 31.03 GB from the 94.61 GB available. This efficient process ends in under six minutes.
Inference with Llama 2
After finishing the fine-tuning process, use the PEFT LoRA-tuned weights to perform inference. First, establish a baseline by analyzing a snippet of the raw foundational model's response without the LoRA-tuned parameters:
PT_HPU_LAZY_MODE=1 python run_generation.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--batch_size 1 \
--do_sample
--max_new_tokens 500 \
--n_iterations 4 \
--use_kv_cache \
--use_hpu_graphs \
--bf16 \
--prompt "I am a dog. Please help me plan a surprise birthday party for my human, including fun activities, games and decorations. And don't forget to order a big bone-shaped cake for me to share with my fur friends!" \
From the command, note the values of the following parameters:
--max_new_tokens 500 : limits the maximum tokens to 500. --bf16 : enables inference at bf16 precision. --prompt : specify the prompt to give the model.
The raw pretrained model delivers the following response:
In this video I’ll show you how to install and setup your new Dell laptop. This is a step-by-step video that will walk you through the installation process. A few weeks ago, I had a chance to take a quick trip to San Diego. I spent a few days in the city and then a few days in the mountains . . . .
Notice that the results are incoherent. The request was for party planning suggestions, and the response was information about laptops and a trip to San Diego.
For inference, provide the same prompt but with the LoRA-tuned layers and then evaluate the response:
PT_HPU_LAZY_MODE=1 python run_generation.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--batch_size 1 \
--do_sample
--max_new_tokens 500 \
--n_iterations 4 \
--use_kv_cache \
--use_hpu_graphs \
--bf16 \
--prompt "I am a dog. Please help me plan a surprise birthday party for my human, including fun activities, games and decorations. And don't forget to order a big bone-shaped cake for me to share with my fur friends!" \
--peft_model /root/Gaudi-tutorials/PyTorch/llama2_fine_tuning_inference/optimum-habana/examples/language-modeling/model_lora_llama/
From the command, note the value of the --peft_model parameter, which specifies the path to the fine-tuned components of the model (generated during the fine-tuning step). This adds a small set of layers to the existing model.
The following is a snippet of the response:
I’m sorry, but I’m not a dog, and I don’t know how to plan a surprise birthday party. But I can give you some ideas for fun activities and games that your human might enjoy. Here are some fun activities and games that your human might enjoy: Puzzle games: Your human might enjoy playing puzzle games like jigsaw puzzles or logic puzzles. You could also look for games that involve building something, like a model airplane or a LEGO set . . . .
Notice that these results are much better, showcasing the significant impact LoRA techniques can provide in under six minutes and approximately $0.86 with Intel® Gaudi® AI accelerators on the quality of LLM responses.
Additional Resources
For a complete list of other models that are optimized for Intel® Gaudi® AI accelerators, see Optimum for Intel® Gaudi® AI Accelerators.
Also, review the official benchmarks to get an idea of model performance.