Authors: Jun Xu, Liang He, Xin Wang
Co-Authors: Wenyong Huang, Ning Wang.
Abstract
WebAssembly (abbreviated WASM) is a binary format for a stack-based virtual machine. It is originally designed for web-based deployment and execution combined with JavaScript and can also be used in standalone environments. Though there are some JIT and AOT implementations, the interpreter has advantages on quick startup, small footprint, and good portability, especially when there is not enough memory or no executable memory available. The performance of the stack-based interpreter of WASM is not as good as expected. In this paper, we introduced wasm-micro-runtime (abbreviated WAMR) fast-interpreter, in which several optimization methods are applied including fast bytecode dispatching, bytecode fusion, etc. Experiments show that the performance can be improved by ~150% on CoreMark compared with the classic stack-based interpreter.
Keywords: WebAssembly (WASM), WASM-Micro-Runtime (WAMR), interpreter, stack-based, bytecode fusion
Introduction
WebAssembly (WASM) is a binary instruction format for a stack-based virtual machine, providing a secure sandboxed execution environment. The original goal of WASM is to enable high-performance applications on web pages, but it can also be executed and integrated into other standalone environments as well. The World Wide Web Consortium (W3C) maintains the standard with contributions from Mozilla, Microsoft, Google, Apple, Fastly, Intel, and Red Hat. Nowadays more and more WASM applications are deployed in IoT devices, host, and cloud servers. And many languages can be compiled into WASM application, like C/C++, TypeScript, Rust, Python, Go etc. [1] [2]
Though there are some JIT and AOT implementations of WASM, interpreter has advantages on quick startup, small footprint, and good portability, especially when the resources are limited, e.g., not enough memory or no executable memory available on the device.
As the WASM bytecodes are stack-based operations, including not only operand stack but also label stack, the performance of stack-based interpreter is not as good as expected. Usually, a stack-based VM pushes and popes the bytecode operands many times, while a register-based VM simply allocates the right number of registers and operates on them, which can significantly reduce the number of operations and CPU time.
Studies have shown that a register-based architecture requires an average of 47% less executed VM instructions than stack-based architecture, and the register-based VM code is 25% larger than corresponding stack code but this increased cost of fetching more VM instructions due to larger code size involves only 1.07% extra real machine loads per VM instruction which is negligible. The overall performance of a registerbased VM is that it takes, on average, 32.3% less time to execute standard benchmarks. [3]
To improve the WASM interpreter’s performance, WASM-Micro-Runtime (WAMR) pre-compiles the WASM bytecode array into new bytecode array with many optimizations applied, including:
- Use label table with Labels-as-Values feature to quickly dispatch bytecodes
- Refactor stack-based bytecode array to register-based
- Reduce bytecode decoding overhead
Fast Bytecode Dispatching
The bytecode is the basic execution unit of the interpreter, each has a corresponding handler to finish the execution logic. Once a bytecode finishes execution, there is a process to let the interpreter jump to the next bytecode handler, which is known as bytecode dispatching. The interpreter holds a global handler table which contains handlers for every bytecode, and the bytecode represents the entry index of the corresponding handler in the table. The interpreter needs to find the entry from the table firstly, and then get the actual address for jumping.
The dispatching expends a large number of CPU cycles because of its quantity, thus reducing the total instructions required by a single dispatch can improve the performance of the interpreter. In WAMR’s fastinterpreter, the handler address of every bytecode is determined during loading time, the loader finds the entry for every bytecode and emits the handler address rather than the original one.
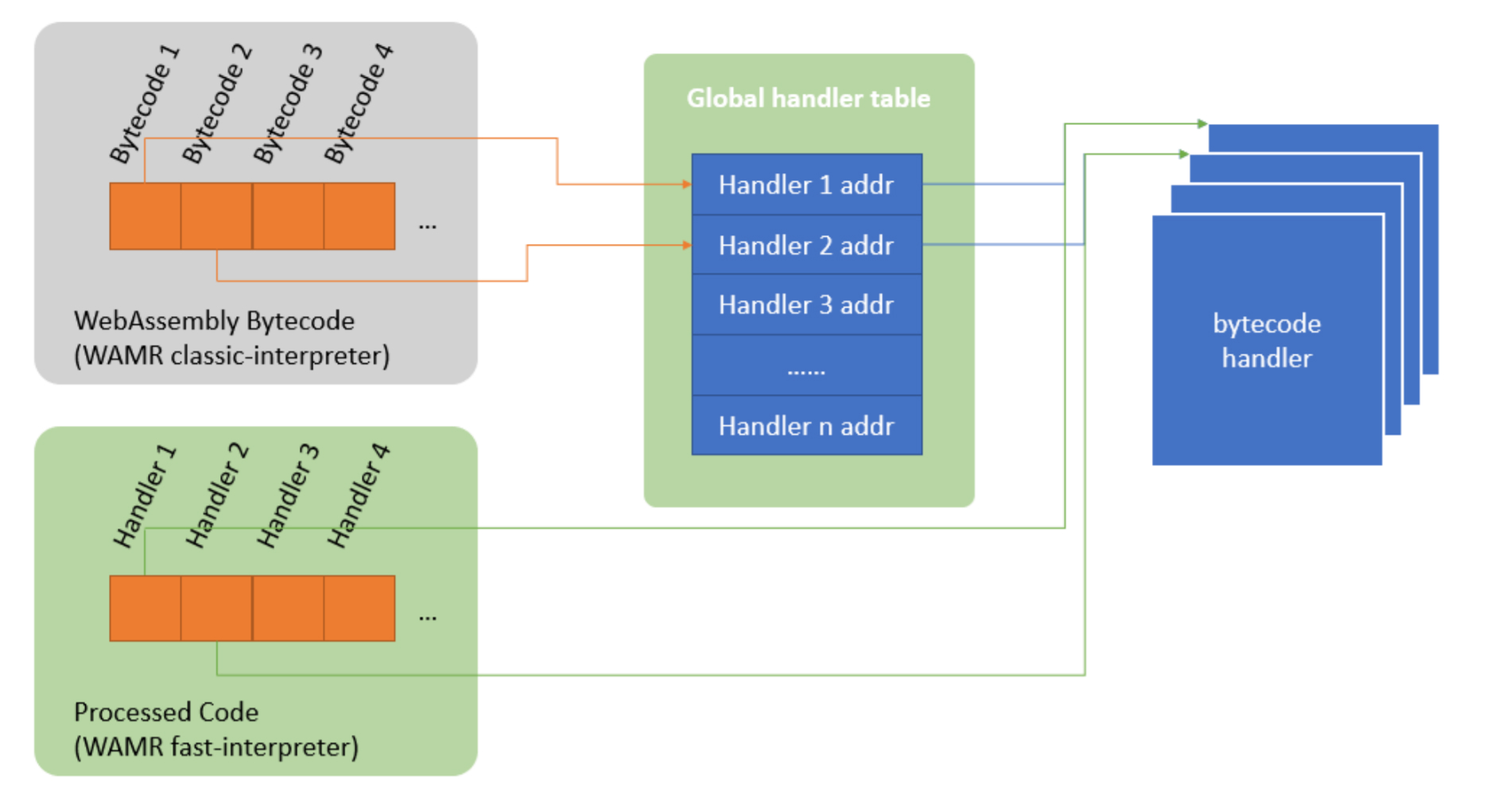
Figure 1. Bytecode Handler Dispatch
Figure 1 shows dispatch pipelines of WAMR’s two interpreters: the classical stack-based interpreter (classicinterpreter) and the optimized register-based interpreter (fast-interpreter). In the fast-interpreter, the address of the bytecode handler has been resolved during loading, so the dispatching during runtime is simpler than the classic-interpreter. The experiment shows that the fast bytecode dispatching introduces about 7% performance improvement on the CoreMark benchmark. [4]
Bytecode Fusion
The WebAssembly is designed as so-called “zero-address code” which means there are no operands for every instruction, this can optimize file size to reduce network transmission time. However, this kind of bytecode requires an evaluation stack to store the intermediate values and a control block stack to store the block scopes, which is not friendly to execution performance.

Figure 2. The Stack Frame Layout in Classic-Interpreter
Figure 2 shows the stack frame of WAMR’s classic interpreter. The local space is used to store the locals defined by WASM spec. Given the simple bytecode sequence for example, “get_local 0, i32.const 0, i32.add, set_local 0”, four bytecodes are required to finish a simple ADD operation, two for loading data to the stack, one for execution, and one for writing data back to local, and this is how WAMR’s classic-interpreter executes the WASM bytecode.
This kind of execution introduces a lot of dispatches. Even though the dispatch has been greatly optimized, it’s still expensive as it doesn’t bring any contribution to the application’s logic, so there would be a chance to improve the execution efficiency if bytecodes can be combined.
Processing Flow
Observing the bytecode above can draw some findings: some bytecodes just push data to stack without any other operations, such as “get_local” and “i32_const”, which can be marked as providers, and others such as “i32.add”, which pop some data and do some processing, can be marked as consumers. What interesting is that, if the consumers can know where to get the data themselves, then the providers are no longer needed. The fast-interpreter introduces a mechanism to remove these providers during loading time. The loader simulates the execution of this program using a stack-based mechanism, but it doesn’t evaluate the actual value. Instead, it calculates a slot id for every operand. There are three spaces in every function’s execution frame: a constant space, a local space, and a dynamic space. The slot id for a local variable is its index. The slot id for a const variable is a fixed negative offset in the constant space, and for those operands generated by consumers, their slot ids are dynamically assigned during processing.

Figure 3. Sample Code
Take above source code for example, generated bytecodes are listed in the table below. There are two locals in this function, so the local space occupies two slots, the dynamic space starts at 2. The table below shows the processing flow of WAMR fast interpreter.
| WebAssembly bytecode | Slot stack during processing | Generated code | Comment |
|---|---|---|---|
| get_local 0 | [0] | ① | |
| get_local 1 | [0, 1] | ||
| I32.add | [2] | I32.add 1, 0, 2 | ② |
| I32_const 1 | [2, -1] | ③ | |
| I32.add | [2] | ④ | |
| set_local 0 | [] | I32.add -1, 2, 0 |
Table 1. Processing flow of bytecode fusion
- The “get_local” bytecode provides a value to the stack, its index is pushed to the slot stack, no code is emitted.
- The “i32.add” bytecode consumes two operands from the stack and generates an intermediate value on the top of the stack, the intermediate value doesn’t have a fixed slot, so a new dynamic slot is assigned to it and pushed to the slot stack. In the meanwhile, a new code is emitted as “ADD [1] [0] [2]”, the first two parameters represent the slot of the operands, they are popped from the slot stack, and the last one represents the slot of the result, which is in the dynamic space.
- “i32.const” provides a const value to the stack, the loader allocates a slot from the const space for a new const or finds the slot for an exist value, and then pushes the slot to the slot stack. The slot id of const is a negative value.
- Additional processing is applied for “set_local” bytecode, if the “set_local” is right after another bytecode which generates a value.
After the processing, the pre-compiled code contains two bytecodes. Many bytecode dispatching is omitted, thus the execution efficiency is improved significantly. By this step, stack-based bytecodes are converted into register-based.
Preserving Local Value
This processing can greatly reduce the total number of bytecodes of a program. However, some semantics in the origin stack-based bytecode may be destroyed, some additional processing are required to deal with these situations. Firstly, some local values may be pushed to stack before they are modified, in the stackbased bytecode, original values are recorded on the stack so the operator can consume the right data later. But in the fast-interpreter, local values are modified immediately, and there is not an evaluation stack to store original values, so an additional preserve space is introduced to keep those local values.
The table below shows the processing for this case.
| WebAssembly bytecode | Slot stack | Generated code |
|---|---|---|
| get_local 0 | [0] | |
| i32.const 1 | [0, -1] | |
| i32.const 2 | [0, -1, -2] | |
| set_local 0 | [{reserve_id}, -1] | copy [0], [{reserve_id}] set_local 0 [0] |
| i32.add | [2] | i32.add [-1], [{reserve_id}], [2] |
Table 2. Additional Process for Local Value
When processing the “set_local” bytecode, the local value preserve analyses are applied. The loader walks through the slot stack to check if the slot to be set exists on the stack. If so, a preserve slot is allocated, and a “copy” bytecode is emitted to copy the original value to the preserved space. Meanwhile, the slot id is changed to the id of the preserve slot. Thus, the final form of the execution frame consists of four spaces: a const space, a local space, a dynamic space, and a preserve space.

Figure 4. Stack Frame Layout of Fast-Interpreter
Figure 4 shows the layout of four spaces. The local space is fixed, it is determined by the function definition. The other three spaces are gradually grown during processing. The const space grows once a new const value appears in the current function. The dynamic space starts at the end of the local space, it grows up once the bytecode generates an intermediate value, and it also decreases once the generated value is consumed by other bytecodes. The green area in the figure represents the maximum space during processing. And the preserved space starts at the end of the dynamic space, this requires a second traversal since the maximum dynamic space can‘t be calculated during the first traversal.
Basic Block Boundaries
Another place to take care about is the boundaries of the basic blocks. In WebAssembly, the basic blocks may be declared with a certain result type, which means there should be a value of that type on the top of the evaluation stack once the block finished, this is also known as stack balance. This happens naturally in the stack-based classic interpreter because the result of the block is always on the top of the stack once the block exit, however, when it turns into the fast-interpreter, things get changed.
As explained earlier, the fast interpreter uses a slot stack to evaluate the slot of every operand during loading, when a block returned, it remains a slot on the stack for further reference, but if this is a “if-else” block, thetwo branches may remain different slot ids on the stack. In this case, an additional “copy” code needs to be inserted before the end of the block.
| WebAssembly bytecode | Slot stack | Generated code |
|---|---|---|
| if i32 | if | |
| i32.const 1 | [-1] | copy [-1], [0] |
| else | else | |
| get_local 0 | [0] | |
| get_local 1 | [0, 1] | |
| i32.add | [0] | i32.add [0], [1], [0] |
| end | end |
Table 3. Additional Process for Block Boundaries.
Every block’s result is in a slot in dynamic space, in other words, the whole block can be treated as a large bytecode which consumes some value from the stack and generates the result. The block’s result slot can be calculated before evaluating its inner bytecodes, and at the end of the block, the top of the slot stack is checked, if it’s not equal to the block’s result slot, a “copy” code is emitted. Therefore, the if branch above generates a copy code, but the else branch does not.
Pre-Decode LEB
All integers in WebAssembly are encoded using the LEB128 variable-length integer encoding, in either unsigned or signed variants. LEB128 is a form of compression algorithm and is used to store a large integer in a small number of bytes. It is suitable for the final .wasm binary file size but spends additional time decoding while using all integer literals.

Figure 5. Pseudo Code for Decoding LEB128
Replacing LEB128 encoded integers with normal integers is a better and simple solution to speed up execution. It only requires that the interpreter decodes each integer number once during the loading phase and stores the result instead and avoids potential following decoding calculation. But it increases memory consumption.
| Number of bytes in LEB128 | Number of bytes | |
|---|---|---|
| i32.const 64 | 1 (0x40) | 4 |
| i64.const 64 | 1 (0x40) | 8 |
| i32.const 65536 | 3 (0x80 0x80 0x04) | 4 |
| i32.const 4294967295 | 5 (0xff 0xff 0xff 0xff 0x0f) | 4 |
Table 4. Number of Encoding Bytes for Integer
Here is an observation from the above table. Small Integers (SMI), smaller than 255, have the same bytes in both LEB128 and generic form. It also decreases 8x memory consumption in LEB128.
For those integer literals greater than 255, a const pool is helpful. Using the index of const pool replace LEB128 encoding bytes. If setting up the pool for every function, it is reasonable to limit the pool size in the range [0, 2 ^ 16 -1], in other words, a short integer as index.
Results
This first evaluation compared classic-interpreter and fast-interpreter using performance execution score, peak memory usage and retired instructions with CoreMark. Figure below showed the optimized version got ~1.5x performance improvement and only ~0.3x memory consumption increment on top. It fitted the “space for time” strategy discussed above.The significant point was that fast-interpreter only generates 42% number of instructions of classic-interpreter for the same benchmark.
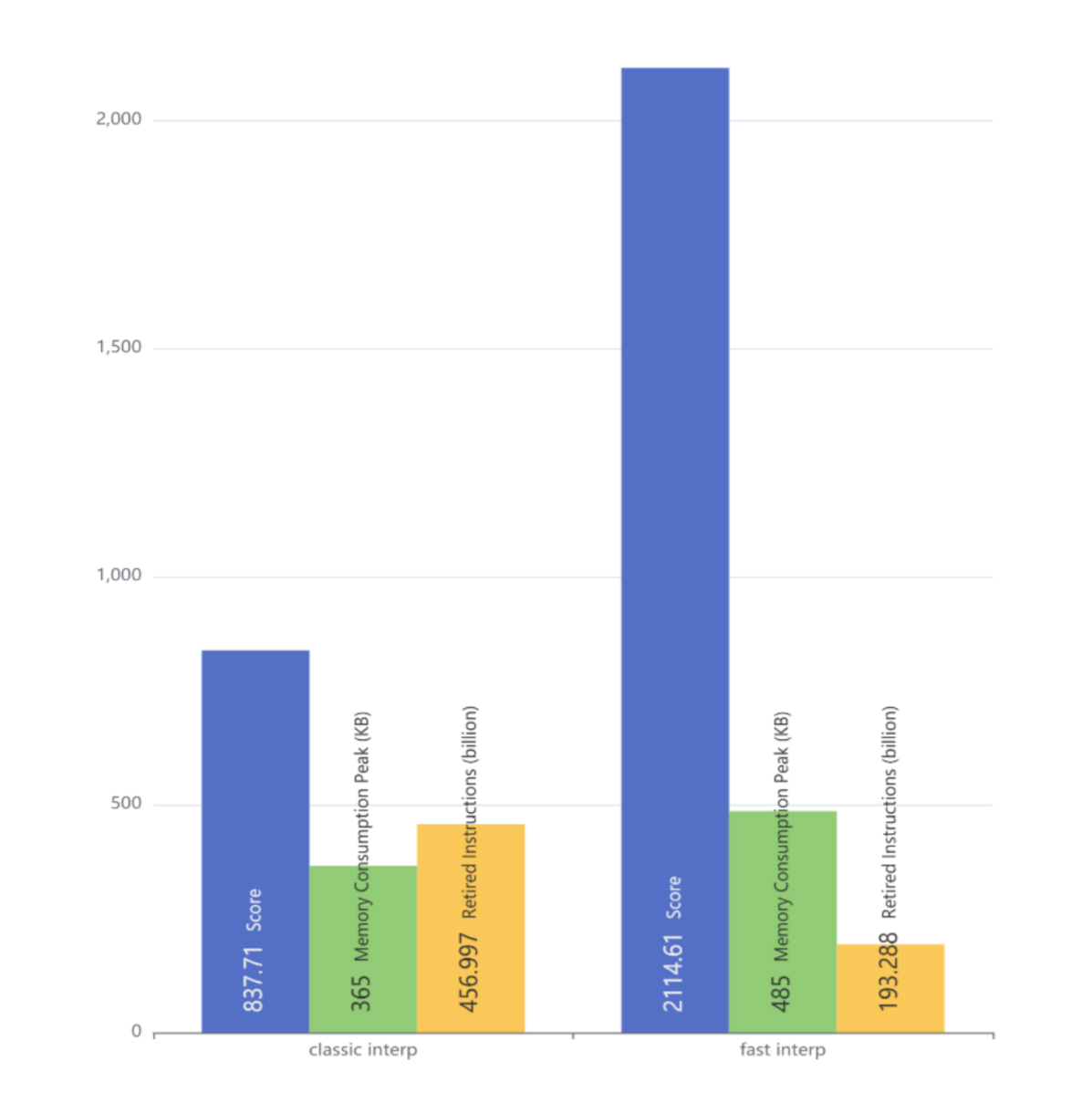
Figure 6. Measurement With CoreMark
The second measurement used the “Sightglass”[5], which is a benchmark suite and tool to compare different implementations of the same primitives. Fast-interpreter demonstrated comparable performance in all benchmarks especially in “base64”, “gimli”, “sieve” showing the highest speedups of 53%, 62%, 67%, respectively.
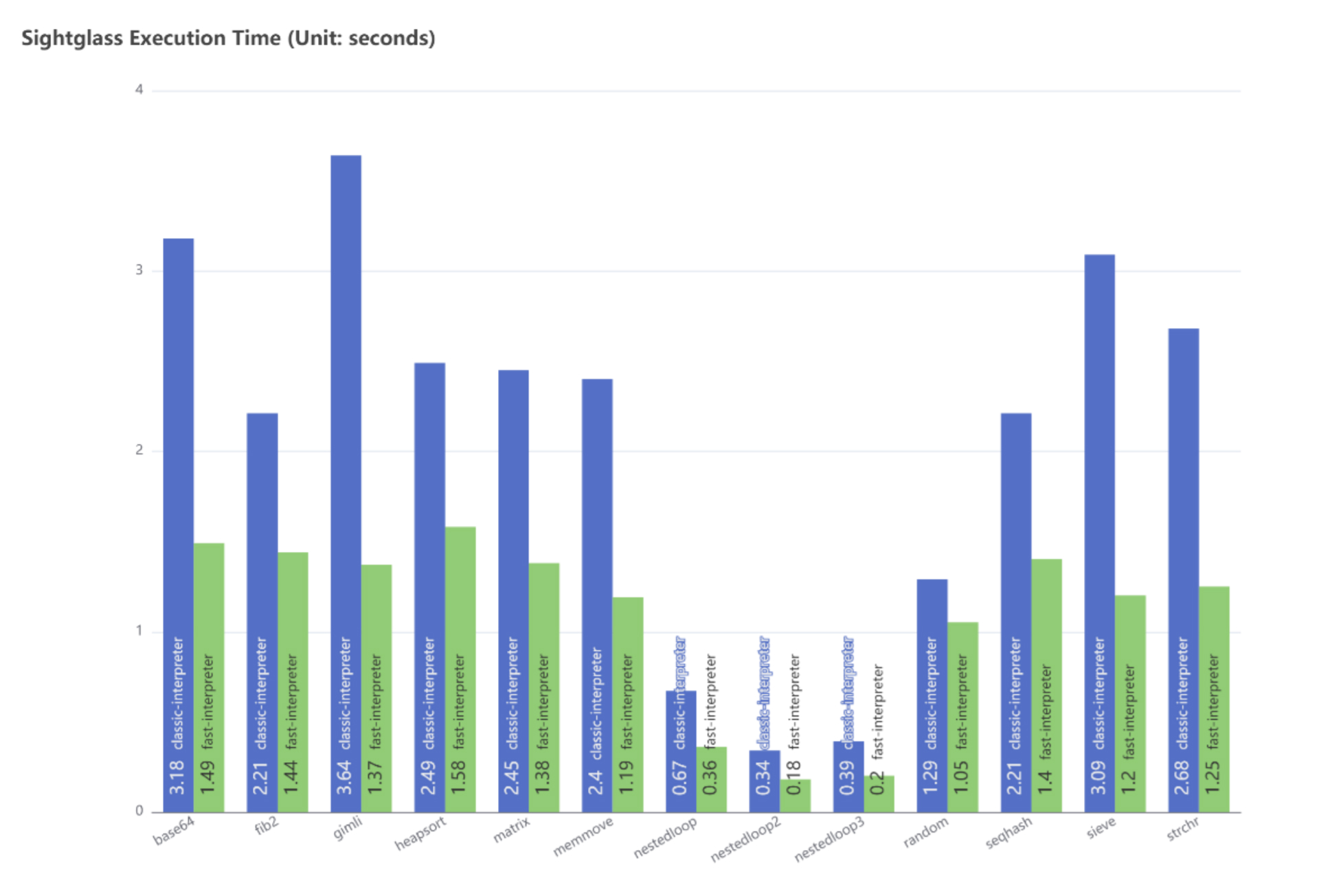
Figure 7. Workload Execution Time
Summary
We have presented a fast WebAssembly interpreter implementation in WAMR that can provide better performance and keep a quick start-up time. Holding the idea of converting stack-based bytecodes into register-based ones, we replace the bytecode array with pre-compiled code contains addresses of bytecode handlers, fuse stack operation bytecodes, and cache integer decoding results. Experimental results showed that the initial launch of fast-interpreter can bring up to 150% performance improvement and 42% generated instructions while only consuming 30% more memory than classic-interpreter for CoreMark. After the initial launch of the fast-interpreter, we are working to further improve startup time, reduce memory usage, and especially the performance of code generation. The first iteration of implementation is rarely the best one. Several things can be tuned to speed up the compilation speed even more.
Acknowledgments
We would like to appreciate Qi Zhang (qi.zhang@intel.com), Jonathan Ding (jonathan.ding@intel.com) and all team members of WPE WOT PWA for their support and suggestions to our work.
References
[1] A. R. D. S. B. T. D. G. L. W. A. Z. J. B. M. H. Andreas Haas, "Bring the Web up to Speed with WebAssembly," PLDI , 2017.
[2] A. R. J. P.-P. Conrad Watt, "Weakening WebAssembly," OOSPLA , 2019.
[3] Yunhe Shi, David Gregg, Andrew Beatty, "Virtual Machine Showdown: Stack Versus Registers," June. 2005.
[4] EEMBC, "CoreMark," EEMBC, [Online]. Available: https://www.eembc.org/coremark/.
[5] bytecodealliance, "sightglass," [Online]. Available: https://github.com/bytecodealliance/sightglass.