Introduction
The Distributed Asynchronous Object Storage (DAOS) has two important features to protect data against loss resulting from media and/or server failures. These features allow developers to create data redundancy as pure data replication, or as Reed-Solomon erasure codes (EC), with the latter introduced in DAOS version 2.0. In addition to this protection dimension in DAOS, data can also be sharded (or striped) for performance to speed up distributed I/O. In this article, we will shed some light on redundancy and sharding in DAOS, showing how you can configure and use both, as well as what are some of the performance implications of using replication and Erasure Code for redundancy.
Basic DAOS Terminology
First, let’s introduce some DAOS terminology. Be aware that this section is not a comprehensive introduction to DAOS. For more information about DAOS architecture, storage model, and other topics, please refer to the DAOS overview page.
Out of the DAOS storage model, the key element for data protection is the object. Objects belong logically to a container, which is used to group objects together (a DAOS pool is composed of one or more containers). Apart from that, containers have their own useful features too, such as the ability to work with transactions. Although somewhat related to data protection, transactions will be out of the scope of this article.
Inside each object, the data is stored following a 2-level key structure. First, there is a dkey (or distribution key), which is used to distribute the data—within an object—to different pool shards (but only if that object was created to be sharded; more on that later). A pool shard is space allocated to the pool on a particular storage target, and storage targets are portions of persistent memory (PMem) optionally combined with pre-allocated space on NVMe storage. Apart from EC objects, all data within the same dkey is guaranteed to be collocated on the same target/shard. Within each space associated with a particular dkey, there are further key-value associations using akeys (attribute keys). This design allows accessing both structured and unstructured data efficiently.
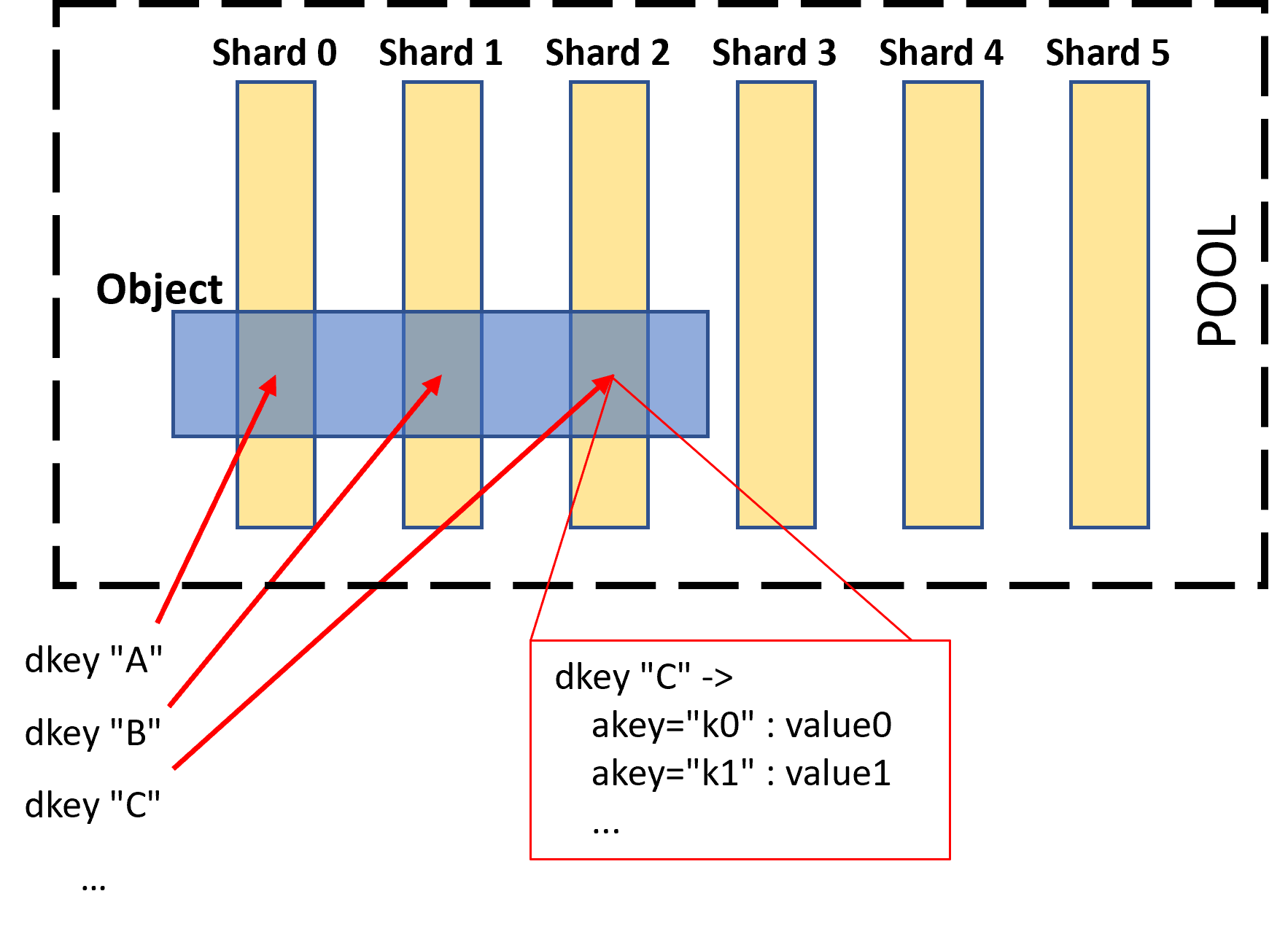
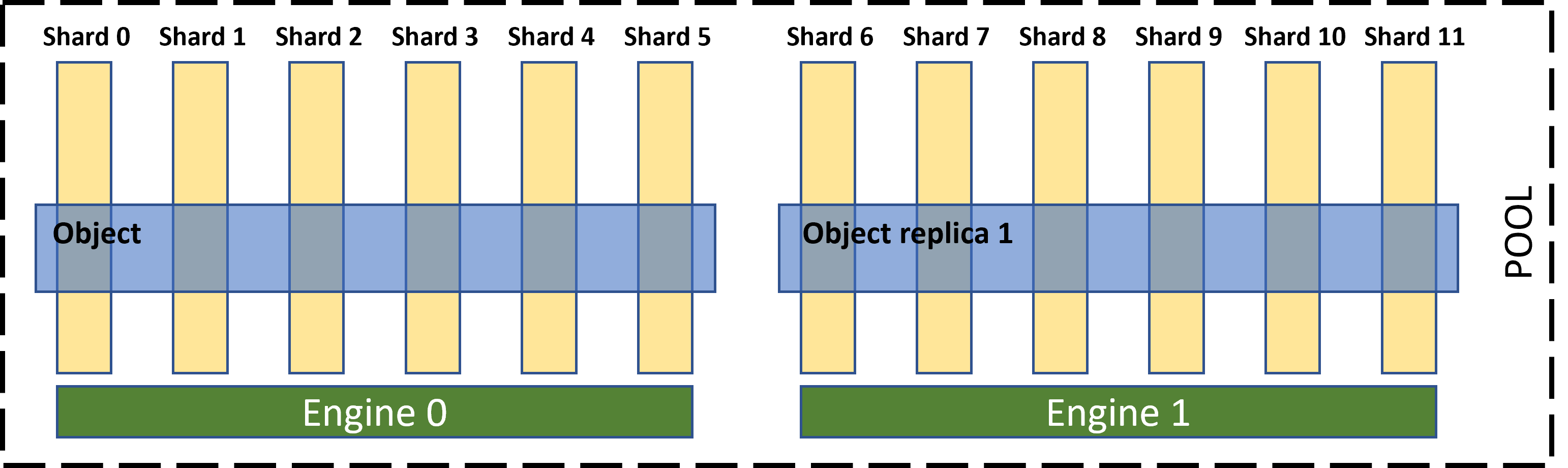
Another important component in DAOS is the engine, which runs as its own process in every storage node and controls the locally attached PMem and NVMe storage exposed through the network. If the storage node is a multi-socket server, an engine process is usually run for each socket.
In the current state of the art, the engine is also the basic unit of fault tolerance in the system (i.e., the basic failure domain). This, however, could change in future DAOS releases. Data sharding is applied within the targets of each of the participating engines.
Object Redundancy and Sharding
As stated in the introduction, there are two types of redundancy for DAOS objects: replication, and Reed-Salomon EC.
Replication provides redundancy by simply copying the data to targets located in other engines in the DAOS system. Only one copy/replica—chosen at random—is used for reads. If an object has a replication factor of n, the object will be able to tolerate up to n-1 engine failures without losing any data. The cost of replication goes up very quickly as the desired tolerance increases. For example, the storage overhead to tolerate 2 failures is 200%, for 3 is 300%, 4 is 400%, etc.
EC solves this problem with much better storage efficiency. For example, typical configurations for Reed-Solomon ECs are RS(6, 3) (6 cells for data, 3 for parity) and RS(10, 4). RS(6, 3) tolerates up to 3 failures with just a 50% storage overhead, while RS(10, 4) tolerates up to 4 failures with a 40% storage overhead.
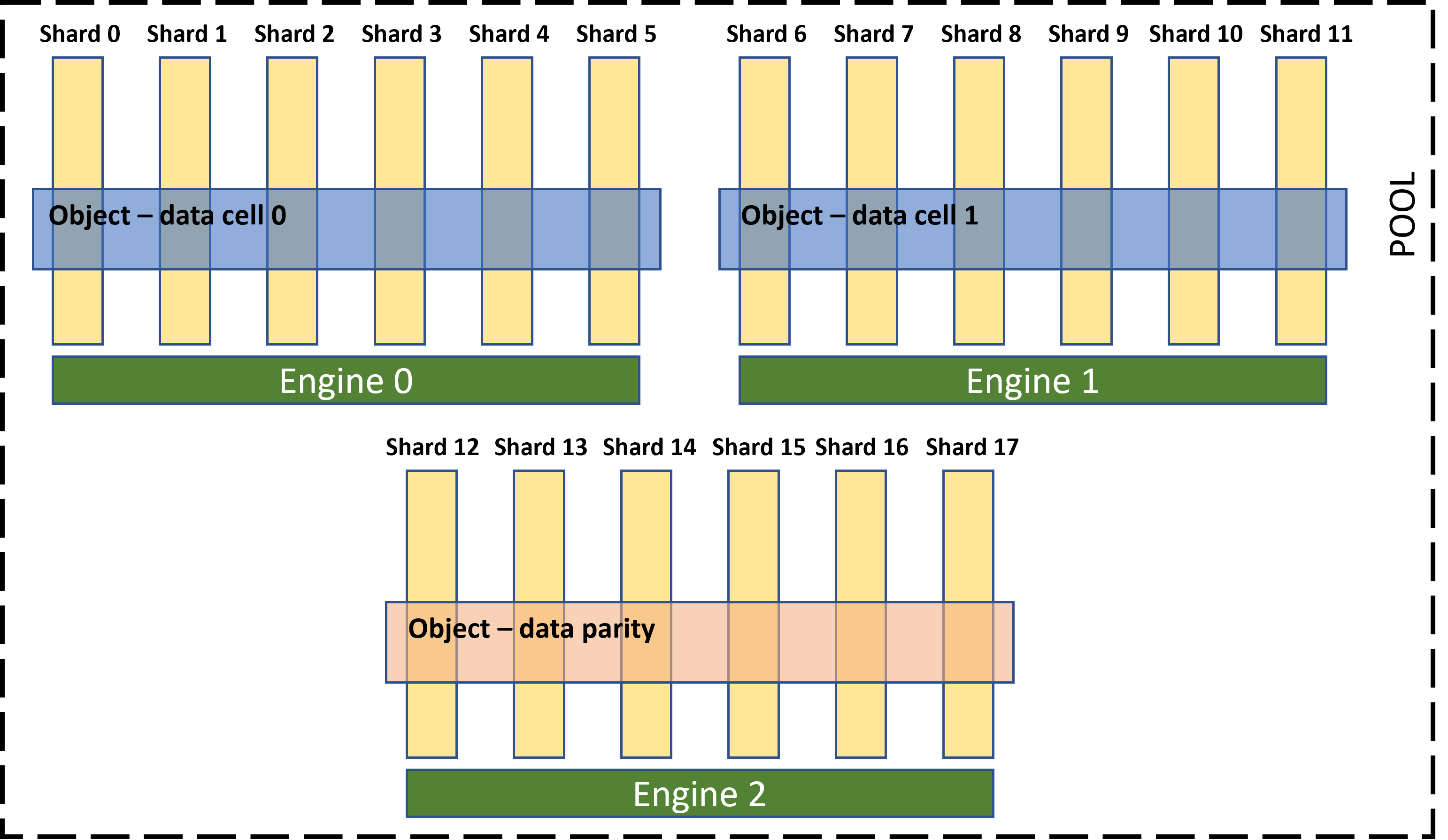
The savings in storage overhead in EC, however, come at an increase in computational overhead needed to split/merge the data and calculate the parity. Nevertheless, the computational overhead incurred by EC is usually negligible when data is large enough. In fact, DAOS only uses EC when values are larger than data_cell_size x data_cell_count, where the minimum cell size is 4 KiB, the default is 64 KiB, and the maximum is 1 MiB. In other cases, the EC object falls back to simple replication. For example, for the case presented in Figure 3, and assuming cell size is 4 KiB, EC will be applied only for values of 8 KiB or larger.
Another advantage of EC over replication is that multiple parts of the same data are read at the same time from multiple engines (data cells). This parallelism benefits reading large pieces of data from a single client process.
A final comment is needed with respect to sharding. Sharding larger than what is possible using the maximum number of targets in each engine is possible, in which case the number of engines have to be increased accordingly. For example, if we want 2-factor replication and 32-way sharding, but each engine only has 16 targets, we have to have at least 4 engines running in our DAOS cluster (instead of 2).
How to Specify Redundancy and Sharding
Redundancy and sharding for objects in DAOS are defined at object creation time by specifying an object class at the object ID creation step. Object IDs are created by calling daos_obj_generate_oid(). If no specific class is specified, DAOS will check if there are any hints specified in the call and use those to select the best class accordingly. If no hints are specified, DAOS will use the container properties to select the object class.
Hints
The following are the available flags for passing hints to daos_obj_generate_oid():
/** Flags for oclass hints */
enum {
/** Flags to control OC Redundancy */
DAOS_OCH_RDD_DEF = (1 << 0), /** Default - use RF prop */
DAOS_OCH_RDD_NO = (1 << 1), /** No redundancy */
DAOS_OCH_RDD_RP = (1 << 2), /** Replication */
DAOS_OCH_RDD_EC = (1 << 3), /** Erasure Code */
/** Flags to control OC Sharding */
DAOS_OCH_SHD_DEF = (1 << 4), /** Default: Use MAX for array &
* flat KV; 1 grp for others.
*/
DAOS_OCH_SHD_TINY = (1 << 5), /** <= 4 grps */
DAOS_OCH_SHD_REG = (1 << 6), /** max(128, 25%) */
DAOS_OCH_SHD_HI = (1 << 7), /** max(256, 50%) */
DAOS_OCH_SHD_EXT = (1 << 8), /** max(1024, 80%) */
DAOS_OCH_SHD_MAX = (1 << 9), /** 100% */
};
Hints are separated into two groups. The first group corresponds to hints for object redundancy, while the second corresponds to hints for object sharding. For example, we can specify DAOS_OCH_RDD_NO, which will create the object with no redundancy. We can also set DAOS_OCH_RDD_RP, so DAOS will create the object with a replication factor, or DAOS_OCH_RDD_EC to indicate that we want to use EC protection. Likewise, we can hint at how much sharding we want to be applied to the object. If we think the object will be small, for example, we can set DAOS_OCH_SHD_TINY to apply a modest sharding.
daos_handle_t coh; /** container open handle */
daos_obj_id_t oid; /** Object ID */
...
rc = daos_obj_generate_oid(coh, &oid, 0, 0, DAOS_OCH_RDD_NO | DAOS_OCH_SHD_MAX, 0);
As far as complexity is concerned, this is as much as hints allow us. If we want further control, we need to explicitly specify an object class.
Object Classes
You can find predefined object classes at the beginning of the include/daos_obj_class.h header file.
Predefined object classes go from very general, like OC_SMALL or OC_RP_LARGE, to very specific, like OC_EC_2P1G4 or OC_S32. Classes from the first type are similar, in complexity, with the hints we saw above. They allow us to give DAOS general information about the nature of our object, but without going into too many details. For example, OC_SMALL indicates that we want our object to be sharded among a “small” number of shards, with the “small” adjective being interpreted by DAOS depending on the current size of the pool. The second type of classes, on the other hand, define an explicit layout. For example, OC_EC_2P1G4 indicates that we want our object to be stored using EC with 2 cells for data, 1 cell for parity (3 in total), and 4 groups. Each cell is sharded/striped among 4 shards, which means that we need at least 3x4=12 shards (4 shards per engine in 3 engines).
daos_handle_t coh; /** container open handle */
daos_obj_id_t oid; /** Object ID */
...
rc = daos_obj_generate_oid(coh, &oid, 0, OC_SX, 0, 0);
In the example above, the object ID is created with the OC_SX class, which stripes the object data among all the available shards without applying any replication or EC.
Performance Implications
In this section, three experiments are shown that compare the read/write performance against objects stored using three different types of redundancy. More specifically, these types are: (1) no redundancy (object class = OC_SX), (2) replication with a factor of 2 (object class = OC_RP_2GX), and (3) EC with 2 data cells and 1 parity cell (object class = OC_EC_2P1GX). The sharding in all three cases is set to ‘X’, which means that DAOS should use as much sharding as possible.
A DAOS I/O cluster with 15 nodes, as well as a client computing cluster with 4 nodes, are used to perform these experiments. The nodes in the DAOS cluster are 2-socket servers, each equipped with 2nd generation Intel® Xeon® Platinum CPUs 8260L, 8x 8TB Intel® SSD DC P4510 NVMe drives, 12x 128 GB Intel® Optane™ Persistent Memory 100 series, and 2x 200Gbps Mellanox HDR InfiniBand adapters. The I/O cluster has a total of 22.5 TB of persistent memory, and 960 TB of NVMe storage. The nodes in the computing cluster are 2-socket servers, each equipped with 3rd generation Intel® Xeon® Platinum CPUs 8360Y and a 200Gbps Mellanox HDR InfiniBand adapter. Both clusters are connected using the InfiniBand HDR fabric.
With 15 storage nodes—each having 2 DAOS engines—there are a total of 30 engines. Going back to the object classes chosen for these experiments, it is possible to see that objects of class OC_SX are sharded among the shards of 30 engines (that is, all of them), objects of class OC_RP_2GX are sharded among 15 engines twice (half of the engines for each replica), and objects of class OC_EC_2P1GX are first split in half (2 data cells) and then each of the 3 cells (remember the parity cell) is sharded among the shards of 10 engines.
The experiments are performed using the IOR parallel I/O benchmark, which is a Message Passing Interface (MPI) application that tests the performance of parallel storage systems. MPI is a message-passing standard designed for applications running on parallel computing architectures. For more information, please refer to the MPI Forum website. The following command is used to run a single experiment:
$ mpirun -bootstrap ssh -env MV2_HOMOGENEOUS_CLUSTER=1 -env MV2_CPU_BINDING_POLICY=scatter --hosts-group $NODELIST -n 20 -ppn 5 ./ior -a DFS -w -r -o /testfile -F -t 16m -b 64G -i 3 --dfs.cont=$CONT --dfs.pool=$POOL
IOR is run using 20 MPI processes (5 per computing node) with the following options:
| -a DFS | API for I/O. In this case, we are using the DAOS File System. |
| -w -r | Do reads and writes. |
| -o /testfile | Prefix name for the test files. |
| -F | Use one file per MPI process. |
| -t 16m | Size of one transfer or I/O operation. In this case, 16 MiB. |
| -b 64G | Contiguous bytes to write per task. In this case, 64 GiB per MPI process. |
| -i 3 | Test repetitions. |
| --dfs.cont=$CONT | UUID for the DFS container. |
| --dfs.pool=$POOL | UUID for the DFS pool. |
The object class for each experiment is set during container creation. As mentioned before, objects that are not created with a specific class use the one defined for the container. For example, for OC_EC_2P1GX, the container is created like the following:
$ daos cont create -p $POOL_NAME --type=POSIX -l $CONT_NAME --oclass=EC_2P1GX
The results of the experiments are presented in Figure 4:
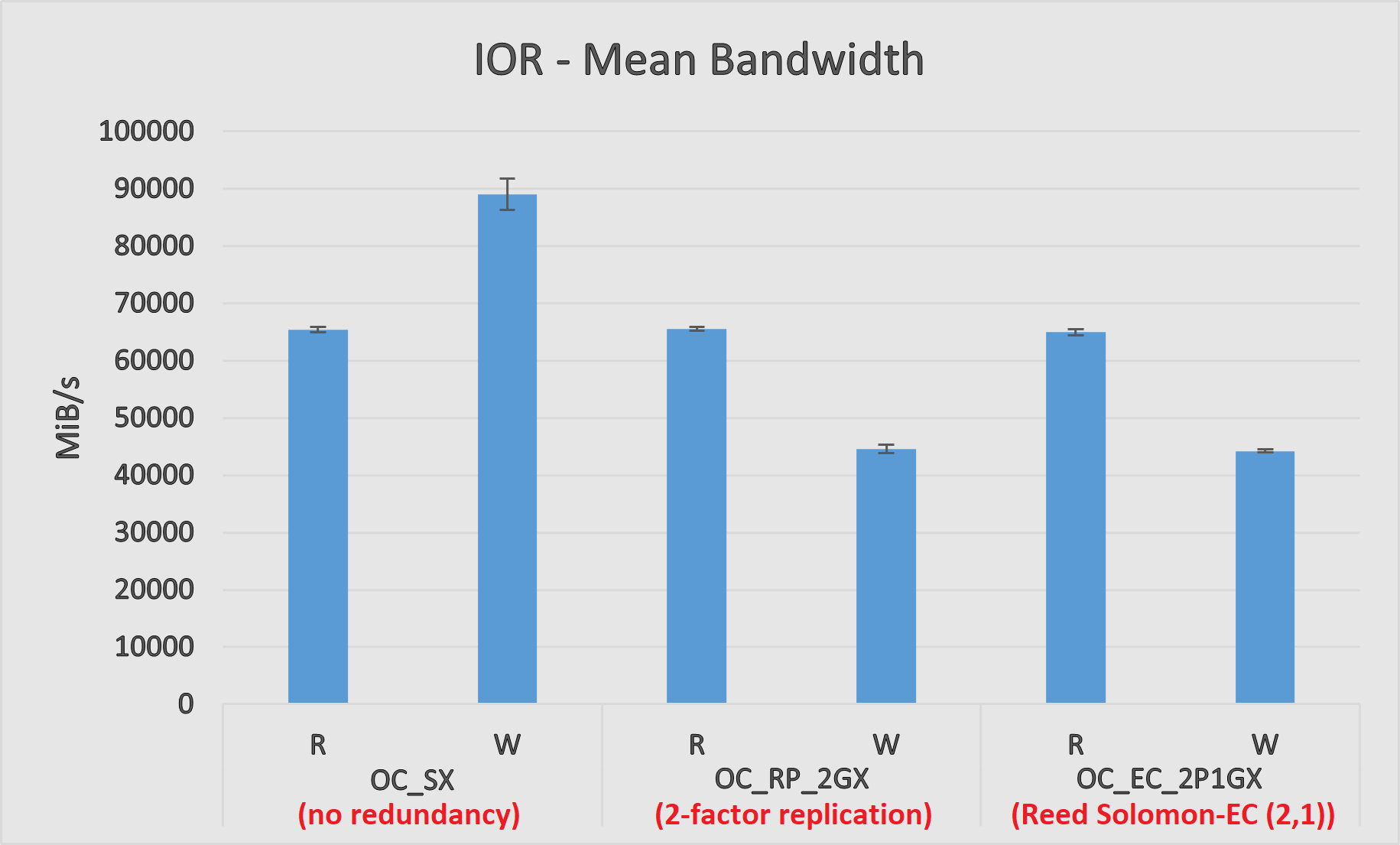
The first observation from Figure 4 is that introducing redundancy cuts our write performance more or less by half (as compared to OC_SX). This is somewhat expected due to the extra writes per transfer needed in both cases. In the case of replication, one extra write for the replica. For EC, two extra writes corresponding to one of the data cells and the parity cell (realize that, although EC introduces more writes, they are smaller in size).
The second observation is that redundancy does not affect read performance at all. With replication, a parallel application ends up using, in the aggregate, all engines in the system to perform reads (a process will pick a replica at random in every read). With EC, reads are only done against engines storing data cells. However, given that the parallel application is reading from multiple files (that is, EC objects), and that the parity cells from different objects are also distributed among different engines, in the aggregate all engines are used for reads too.
In general, there isn’t a simple answer as to which object class is better. It all depends on the particulars of every user, fault tolerance needs, and workload. The following table helps to better visualize the pros and cons of each one for the experiments presented above:
| Reads | Writes | Redundancy | Extra space utilization | |
| OC_SX no redundancy |
Fast | Fast | No | None |
| OC_RP_2GX 2-factor replication |
Fast | Fair | Yes | High |
| OC_EC_2P1GX RS-EC(2,1) |
Fast | Fair | Yes | Fair |
Finally, it is important to understand that these experiments are by no means exhaustive. They don’t represent the difference in performance between these classes in all possible use cases and workloads. One should always test their own applications in a real DAOS setup to get real tradeoffs.
Conclusions
In this article, we saw the two features for data redundancy available for DAOS objects—in the form of replication and Reed-Solomon EC—to protect data against loss resulting from media and/or server failures. Sharding (or striping) for distributed I/O performance was also discussed, along with a demonstration of how everything can be configured programmatically using the available APIs during object creation. Finally, three experiments using the IOR parallel I/O benchmarks were performed to get a sense of the difference in performance between both types of redundancy and no redundancy.