This article describes essential techniques to tune the performance of codes built and executed using the Intel® MPI Library. The tuning methodologies presented require no code changes, and are accessible to users of all levels of experience.
Note: This content is valid for Intel® MPI Library 2018 but not 2019 and newer versions.
Use the best available communication fabric
The Intel® MPI Library will attempt to select the fastest available fabric by default, but this selection can be explicitly set using the variable I_MPI_FABRICS, which has the following syntax:
I_MPI_FABRICS=<fabric>|<intra-node fabric>:<inter-nodes fabric>
The fabric actually being used during run time can be checked by setting the environmental variable I_MPI_DEBUG=2. The following table shows the available fabrics under Intel® MPI Library version 2018:
| Fabric | Description |
|---|---|
| shm | Shared-memory only; intra-node default |
| tcp | TCP/IP-capable network fabrics, such as Ethernet and InfiniBand* (through IPoIB*) |
| dapl | DAPL–capable network fabrics, such as InfiniBand*, iWarp*, and XPMEM* (through DAPL*) |
| ofa | OFA-capable network fabric including InfiniBand* (through OFED* verbs) |
| tmi | Tag Matching Interface (TMI) capable network fabrics, such as Intel® True Scale Fabric, Cornelis* Omni-Path Architecture and Myrinet* |
| ofi | OFI (OpenFabrics Interfaces*)-capable network fabric including Intel® True Scale Fabric, and TCP (through OFI* API) |
In a typical Cornelis Omni-Path installation the default setting is:
I_MPI_FABRICS=shm:ofi
For details on working with the OpenFabrics interface and the Intel® MPI Library refer to our Using libfabric with the Intel® MPI Library online guide.
Disable fallback for benchmarking
The Intel® MPI Library will fall back from the ofi or shm:ofi fabrics to tcp or shm:tcp if the OFI provider initialization fails. Disable I_MPI_FALLBACK to avoid unexpected performance slowdowns (this is the default when I_MPI_FABRICS is set):
$ export I_MPI_FALLBACK=0
or, on the command line, use one of the two following options:
$ mpirun -genv I_MPI_FABRICS ofi -genv I_MPI_FALLBACK 0 -n ./app
$ mpirun –OFI -n ./app
Using these settings the run will fail if the high performance fabric is not available, rather than run at a degraded performance over a backup fabric.
Enable multi-rail capability
Multi-rail capability refers to the ability to use multiple hardware links simultaneously to exchange data at an increase rate. In this context a rail is a hardware link ( a single port adapter, or a single port in a multi-port adapter). If each cluster node is equipped with multiple adapters or multi-port adapters, you can use them to increase the aggregated transfer bandwidth. Note that at least one rank per rail is needed in order to take advantage of this feature.
Multi-rail for Cornelis* Omni-Path Architecture fabrics
Cornelis Omni-Path Architecture fabrics use the Intel® Performance Scaled Messaging 2 (PSM2) library to interface with the higher level MPI functionality. Some tuning knobs, such as those to enable multi-rail support, are within the PSM2 library itself. When using either TMI or OFI fabrics, multi-rail support is enabled in the PSM2 layer using the following settings:
PSM2_MULTIRAIL=<number of rails (max 4)>
PSM2_MULTIRAIL_MAP=<unit:port,unit:port,…>
The variable PSM2_MULTIRAIL_MAP defines the multi-rail map, with unit starting at 0 and port always being 1 since Cornelis Omni-Path Host fabric Interfaces (HFIs) are single port devices.
Multi-rail for Infiniband* fabrics
For Infiniband* using the OFA fabric multi-rail support is enabled by the following environment settings:
I_MPI_FABRICS=shm:ofa
I_MPI_OFA_NUM_ADAPTERS=2
I_MPI_OFA_NUM_PORTS=1
Starting with IMPI 5.1.2, DAPL UD also provides support for multi-rail. In that case the I_MPI_DAPL_UD_PROVIDER should not be populated – HCAs are taken according to /etc/dat.conf
Use lightweight statistics
Lightweigth statistics are a great way to characterize your code communication requirements without significant overhead. Information can be gathered in either native or integrated performance monitoring (IPM) formats.
Native statistics
The environmental variable I_MPI_STATS controls the format and verbosity of the collected statistics:
I_MPI_STATS=[native:][n-]m
where n and m represent the range of information collected, as described in the table below. If no lower limit is provided the output will include information for all levels below the one required.
| Statistics level (n,m) | Output information |
|---|---|
| 1 | Amount of data sent by each process |
| 2 | Number of calls and amount of transferred data |
| 3 | Statistics combined according to actual call arguments |
| 4 | Statistics defined by a bucket list |
| 10 | Collective operation statistics for all communication contexts |
| 20 | Additional timing information for all MPI functions |
The data collected will be saved by default to a file named stats.txt, but the target output file may be changed using the environmental variable I_MPI_STATS_FILE.
Since large amounts of data may be generated for production codes, the collection can be customized in several ways. The environmental variable I_MPI_STATS_SCOPE allows for filtering of point to point and collective MPI functions, and even for fine grained control where a smaller subset of MPI functions is required:
I_MPI_STATS_SCOPE="<subsystem>[:<ops>][;<subsystem>[:<ops>][...]]"
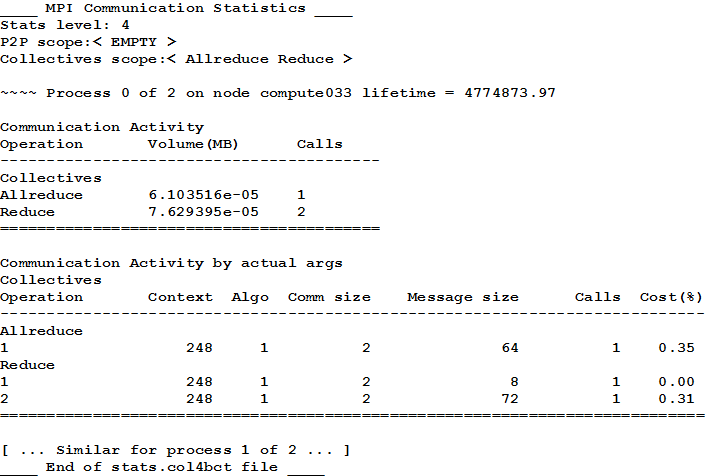
In this definition the <subsystem> option is one of all (default), p2p (point to point only) or coll (collectives only). Most collective and point to point calls may be specified as <ops> using a comma separated list of names that exclude the initial "MPI_" prefix. The following example specifies that only statistics level 2 through 4 are collected for the MPI_Allreduce and MPI_Reduce calls:
$ export I_MPI_STATS=2-4
$ export I_MPI_STATS_SCOPE="coll:Allreduce,Reduce"
The output for this example is shown in the figure below.
Another way of customizing the statistics report is to define buckets of message and communicator sizes to act as aggregation filters for the collected data. This is controlled via the environmental variable I_MPI_STATS_BUCKETS:
I_MPI_STATS_BUCKETS=<msg>[@<proc>][,<msg>[@<proc>]]...
where <msg> is a given message size or range in bytes, and <proc> is a given process count for collective operations. For example, to look only at messages smaller than 4 kB we use:
$ export I_MPI_STATS_BUCKETS=0-4000
And to look at messages of size 4 kB but only for cases where 8 processors are involved we use:
$ export I_MPI_STATS_BUCKETS="4000@8"
Consult the Developer Reference from the Intel® MPI Library documentation site for a complete description of the I_MPI_STATS, I_MPI_STATS_SCOPE, and I_MPI_STATS_BUCKETS options.
IPM statistics
The environmental variable I_MPI_STATS can be used to set the statistics format to IPM:
I_MPI_STATS=ipm[:terse]
A full IPM output is shown in the figure below. The terse output corresponds to the short section on the top, which contains no details on individual MPI functions.
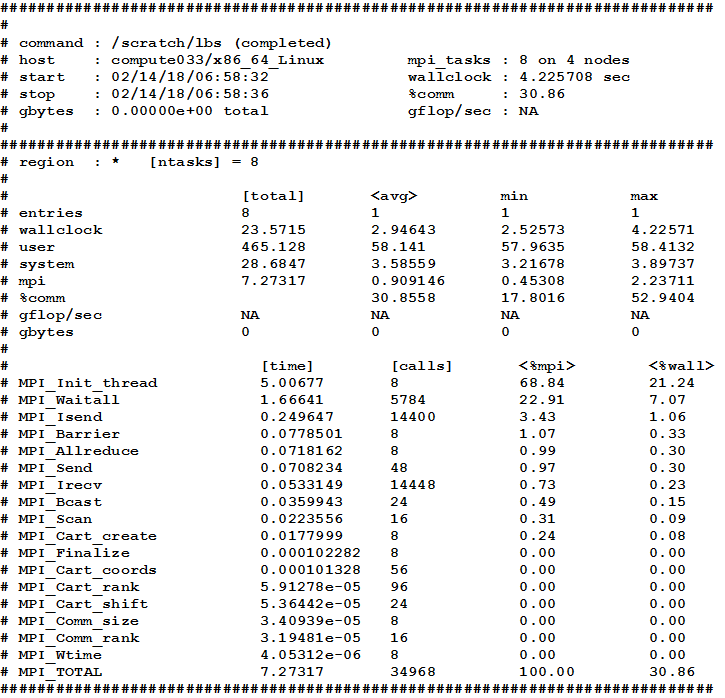
IPM output is saved by default to the file stats.ipm, but a different file name may be specified using the I_MPI_STATS_FILE variable.
As with native statistics the output may be customized using the environmental variable I_MPI_STATS_SCOPE, but its syntax is different when used with the IPM format:
I_MPI_STATS_SCOPE="<subset>[;<subset>[;…]]"
where the subsets are pre-defined collections such as all2one (all-to-one collective types) or recv (receive functions). The complete list is comprehensive and too long to include in this document, but it can be found on the Developer Reference from the Intel® MPI Library documentation site.
Native and IPM statistics
Native and IPM statistics can be gathered separately in a single run. FOr maximum detail simpli use:
$ export I_MPI_STATS=all
For better control use the following syntax:
I_MPI_STATS=[native:][n-]m,ipm[:terse]
where all definitions of the options described in the two sections above.
The I_MPI_STATS_SCOPE variable may not be used when collecting both native and IPM statistics.
Choose the best collective algorithm
Use one of the I_MPI_ADJUST_<opname> knobs to change the algorithm
- Focus on the most critical collective operations (see statistics)
- Use the Intel® MPI Benchmarks by selecting various algorithms to find out the right algorithms for collective operations
- Or use mpitune for automatic (/fast) tuning!
I_MPI_ADJUST_<collective>=<algorithm #>
Section “Collective Operation Control” of the Intel® MPI Library Developer Reference defines the full set of variables and algorithm identifiers.
Select a proper process pinning
The default pinning is suitable for most scenarios, but the Intel MPI Library provides multiple means for process pinning control.
To control the number of processes to be executed per node use the environmental variable I_MPI_PERHOST or the command line options -perhost / -ppn :
$ mpirun -ppn <# processes per node> -n < # total processes> ...
The Intel® MPI Library respects the batch scheduler settings, but this behavior may be overridden with the following setting:
I_MPI_JOB_RESPECT_PROCESS_PLACEMENT=0
Note that per-node pinning may also be achieved using a machinefile.
Custom processor core pinning can be achieved by two different environment variables:
- I_MPI_PIN_PROCESSOR LIST : Pure MPI applications
- I_MPI_PIN_DOMAIN : Hybrid MPI + threading applications
When setting custom pinning you can use the cpuinfo utility provided with the Intel® MPI Library to observe the processor topology.
While we provide some examples below, section “3.5 Process Pinning” of the Intel® MPI Library Developer Reference defines the full set of variables and possibilities available for process pinning control.
Custom pinning for pure MPI applications
- <proclist>
- [<procset>][:map=<map>]
- [<procset>][:[grain=<grain>][,shift=<shift>][,preoffset=<preoffset>][,postoffset=<postoffset>]]
To place the processes exclusively on physical cores regardless of Hyper Threading mode, use allcores setting:
$ mpirun –genv I_MPI_PIN_PROCESSOR_LIST allcores -n <# total processes> ./app
To avoid sharing of common resources by adjacent MPI processes, use map=scatter setting:
$ mpirun –genv I_MPI_PIN_PROCESSOR_LIST map=scatter -n <# total processes> ./app
To place adjacent MPI processes on different sockets, use shift=socket:
$ mpirun –genv I_MPI_PIN_PROCESSOR_LIST shift=socket -n <# total processes> ./app
To specify that processes must be bound to logical CPUs 0, 3 , 5, and 7:
$ mpirun –genv I_MPI_PIN_PROCESSOR_LIST 0,3,5,7 -n <# total processes> ./app
Custom pinning for hybrid (MPI + threading) applications
Control of pinning for hybrid applications running under the Intel® MPI Library is performed using one of the three available syntax modes for the I_MPI_PIN_DOMAIN variable:
- <mc-shape>
- <size>[:<layout>]
- <masklist>
It is important to realize that threads of hybrid applications are not pinned by default, and that they can migrate across the cores of a rank as defined by the I_MPI_PIN_DOMAIN setting. Thread pinning may be specified separately using, for example, OMP_PLACES or KMP_AFFINITY settings.
Pinning Defaults
The following table shows the default values used for pining by the Intel® MPI Library. Note that on Windows* systems the only available option for I_MPI_PIN_MODE is lib.
| Default | Impact |
|---|---|
| I_MPI_PIN=on | Pinning enabled |
| I_MPI_PIN_MODE=pm | Use the Hydra process manager for pinning |
| I_MPI_PIN_RESPECT_CPUSET=on | Respect process affinity mask |
| I_MPI_PIN_RESPECT_HCS=on | Pin according to HCA socket |
| I_MPI_PIN_CELL=unit | Pin on all logical cores |
| I_MPI_PIN_DOMAIN=auto:compact | Pin size #lcores/#ranks : compact |
| I_MPI_PIN_ORDER=compact | Oder domains adjacent |
Tuning for numerical stability
In this section we discuss how to tune for numerical stability in the context of reproducibility. We define an execution as repeatable when it provides consistent results if the application is launched under the exact same conditions - repeating a run on the same machine - and configuration. We define an execution as (conditionally) reproducible when it provides consistent results even if the distribution of ranks differs, while the number of ranks (and threads for hybrid applications) involved has to remain stable. In this later case the runtime including the microarchitecture has to be consistent.
The following guidelines should be followed to achieve conditional reproducibility when using the Intel® MPI Library:
- Do not use topologycally-aware algorithms for collective reduction operations
- Avoid the recursive doubling algorithm for MPI_Allreduce
- Avoid calls to MPI_Reduce_scatter_block, as well as the MPI-3 non-blocking collective operations
The following table lists collective reduction algorithms that are not topology-aware.
| Collective MPI Reduction Operation | Control Variable | Non Topologically-Aware Algorithms |
|---|---|---|
| MPI_Allreduce | I_MPI_ADJUST_ALLREDUCE | [1], 2, 3, 5, 7, 8, 9 |
| MPI_Exscan | I_MPI_ADJUST_EXSCAN | 1 |
| MPI_Reduce_Scatter | I_MPI_ADJUST_REDUCE_SCATTER | 1, 2, 3, 4 |
| MPI_Reduce | I_MPI_ADJUST_REDUCE | 1, 2, 5, [7] |
| MPI_Scan | I_MPI_ADJUST_SCAN | 1 |
Read The Parallel Universe Magazine Issue 21 for additional information on this subject.
[1] Even though the first algorithm of MPI_Allreduce is not topologically aware it does not guarantee conditionally reproducible results.
[7] The Knomial algorithm provides reproducible results, only if the I_MPI_ADJUST_<COLLECTIVE-OP-NAME>_KN_RADIX environment is kept stable – or unmodified
Use connectionless communication (Infiniband*)
Connectionless communication typically provides better scalability and reduces memory footprint by reducing the number of receive queues. It is generally recommended to use this feature for large and memory hungry jobs over a thousand MPI ranks, and it is automatically triggered for large jobs via I_MPI_LARGE_SCALE_THRESHOLD, which by default is 4096 ranks.
Cornelis Omni-Path Architecture fabrics TMI and OFI automatically use the PSM2 provided connectionless communication features.
For Infiniband* fabrics using a DAPL provider version higher than 2.0.27 this can be enabled via environmental variables:
I_MPI_FABRICS=shm:dapl
I_MPI_DAPL_UD=1
I_MPI_DAPL_UD_PROVIDER=<chosen from /etc/dat.conf entries>
Useful Resources
- Intel® MPI Library documentation site
- Using libfabric with the Intel® MPI Library
- Tuning the Intel® MPI Library: Advanced Techniques