Co-Author: Di Yin (endymecyyin@tencent.com), Ping Gao (pingpgao@tencent.com)
Introduction
Intel® Analytics Zoo is a unified big data analytics and artificial intelligence (AI) platform that seamlessly unites TensorFlow*, Keras*, PyTorch*, Apache Spark*, Apache Flink* and Ray* programs into an integrated pipeline, which can transparently scale from a single laptop to a large-scale distributed cluster to process production data.
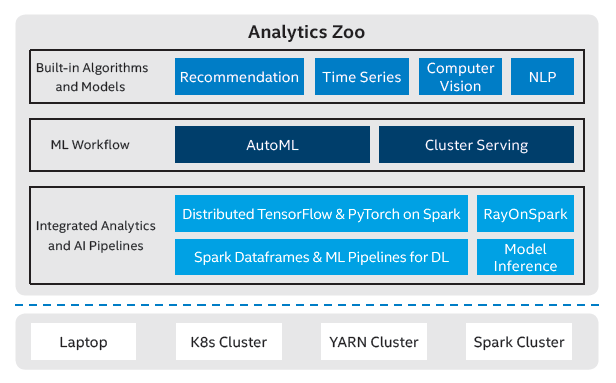
Figure 1 Analytics Zoo architecture
With Analytics Zoo, users can easily develop and deploy end-to-end AI applications. For example, they can write TensorFlow* or PyTorch* code in Spark program and perform distributed training and inference on Spark, or directly run Ray programs on big data clusters through RayOnSpark. Analytics Zoo also allows users to use high-level machine learning (ML) workflows to automate the development process of large-scale ML applications. For example, users can use Cluster Serving for automatically distributed (TensorFlow*, PyTorch*, Caffe*, BigDL, and OpenVINO™) model inference, or use the scalable AutoML for time series prediction. In addition, Analytics Zoo provides various algorithms and models for recommendation, time series data, computer vision, and natural language processing (NLP) applications.
In a typical ML application, users usually have to perform the appropriate operations such as data preprocessing, feature engineering, feature extraction, and feature selection, so that the input data can be effectively used by ML applications; after data preprocessing, users must use the appropriate models and hyperparameter tuning to maximize the predictive performance of ML models and algorithms. These steps are extremely challenging, making it difficult for common users to use ML technologies.
Automated machine learning (AutoML) automates the process of applying ML to real-world problems. AutoML covers the complete pipeline from raw dataset processing to ML model deployment. AutoML was proposed as an AI-based solution to the ever-growing challenge of applying ML to real world applications. The highly automated AutoML allows non-experts to easily make full use of ML models and techniques. AutoML provides users with automated and end-to-end ML capabilities, simpler AI solutions, and faster creation of solutions that often outperform manually tuned models.
Collaboration between Tencent* and Intel on AutoML
TI-ONE* is a one-stop ML platform service based on Tencent Cloud's powerful computing capabilities. It combines various data sources, components, algorithms, models, and evaluation modules, and allows algorithm engineers and data scientists to easily perform model training, evaluation, and prediction. TI-ONE supports various computing frameworks such as PySpark, PyTorch*, and TensorFlow*.
Through in-depth technical cooperation, ML teams from Intel and Tencent have integrated Analytics Zoo into the TI-ONE platform, empowering the platform with AutoML features, thus making it easy for AI beginners to use. With the AutoML framework of Analytics Zoo, users can easily perform time series analytics, such as time series prediction and anomaly detection.
Time series data, as the name suggests, is a series of data collected in chronological order. Time series data prediction is to use time series data of the past as input to predict data values of the future. Time series data prediction is applicable in a wide range of real-world scenarios, such as network quality analytics for ISPs, log analytics of data center operation and maintenance, and preventive maintenance of high-value equipment. It can also be used as a threshold value for exception detection, so that it triggers an alarm when the deviation between the actual and predicted values is large.
Classical time series data prediction usually uses descriptive models or statistical methods. Such methods often involve making assumptions about the distribution of data and decomposing time series into components such as cycle, trend, and noise. Compared with classical linear prediction models (such as ARIMA and ES), ML-based time series data prediction methods (such as neural network models) make almost no assumptions about data and perform better in identifying complex patterns. In fact, neural network models already have a number of successful use cases in time series prediction. Building ML applications for time series data prediction is a time-consuming and labor-intensive process that requires a lot of expertise. The AutoML framework in Analytics Zoo implements automated feature generation and selection, model selection, and hyperparameter tuning, simplifying the process of training time series analytics models.
In Analytics Zoo, the time series data prediction tool based on AutoML is built on Ray and Ray Tune. Ray is a distributed computing framework open sourced by the Berkeley RISE laboratory, University of California, and is used to develop new types of AI applications. Ray Tune is a scalable hyperparameter tuning library running on Ray* and enables users to perform a large number of experiments efficiently on large-scale clusters. Analytics Zoo supports RayOnSpark and allows users to directly run new AI applications built on top of Ray in existing big data clusters, which can then be seamlessly integrated into the big data processing and analysis pipeline.
The following describes how to use Ray Tune and RayOnSpark to implement the AutoML framework and automatic time series data prediction.
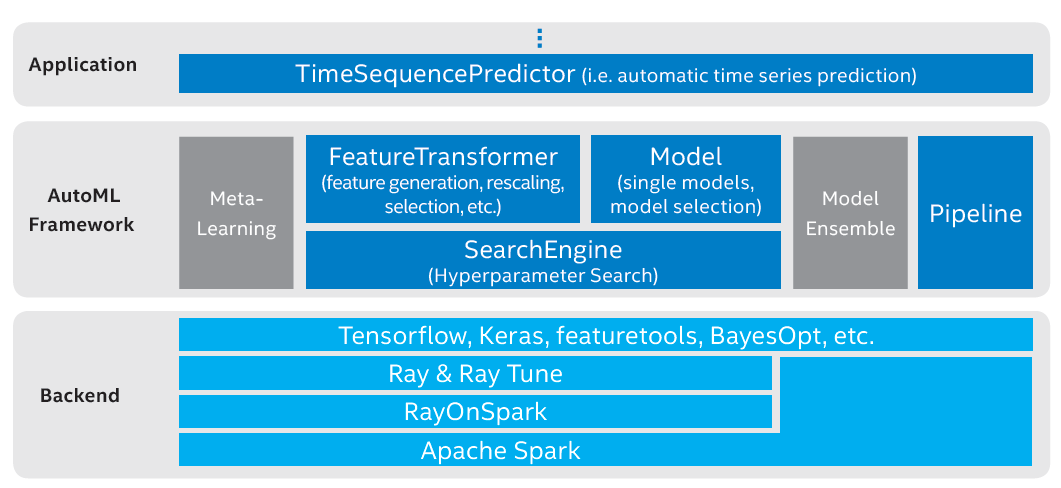
Figure 2 AutoML framework in Analytics Zoo
The AutoML framework uses Ray Tune for hyperparameter search on RayOnSpark. In implementation, hyperparameter search covers feature engineering and modeling. For feature engineering, the search engine selects the best subset of features from a set of features that are automatically generated by various feature generation tools (such as Featuretools). For modeling, the search engine searches for hyperparameters, such as the number of nodes per layer and the learning rate. In this project, popular deep learning frameworks, such as TensorFlow* and Keras*, are used to build and train models, and Apache Spark* and Ray* are used for distributed execution.
The AutoML framework includes four basic components, namely FeatureTransformer, Model, SearchEngine, and Pipeline. A FeatureTransformer defines the feature engineering process, which usually includes a chain of operations, such as feature generation, scaling, and selection. A Model defines a model (such as an neural network-based model) and the optimization algorithm used (such as SGD and Adam). A Model may also include the procedure of model/algorithm selection. A SearchEngine searches for the best set of hyperparameters for both FeatureTransformer and Model, and guides the actual model fitting process. A Pipeline is a convenient utility that integrates FeatureTransformer and Model into a data analysis pipeline. A Pipeline can be easily saved to a file and loaded for reuse later elsewhere.
In general, a typical model training workflow with the AutoML framework is as follows:
-
A FeatureTransformer and a Model are first instantiated. A SearchEngine is then instantiated and configured with the FeatureTransformer and Model, along with search presets (which specify how the hyperparameters are searched, the reward metric, and so on).
-
The SearchEngine runs the search procedure. Each run will generate multiple trials at a time and distribute the trials in a cluster using Ray Tune. Each trial runs feature engineering and the model fitting process with a different combination of hyperparameters and returns the specified target metrics.
-
After all trials are completed, the best set of hyperparameters and optimized model are retrieved according to the target metrics. They are used to generate the result FeatureTransformer and Model, which are in turn used to compose a Pipeline. The Pipeline can then be saved to a file and loaded later for inference and/or incremental training.
Analytics Zoo provides a convenient interface TimeSequencePredictor, which encapsulates the above process of the AutoML framework, integrates a large number of time series-related feature processing workflows and models, and is specifically used for the training of time series prediction models. Users can directly call this interface to perform automatic time series prediction model training, generate a Pipeline, and save the pipeline to a file, facilitating subsequent prediction, deployment, and incremental training update.
TI-ONE* has integrated Analytics Zoo, as shown in Figure 3. Users can use the Analytics Zoo component on TI-ONE* to perform time series data analytics and machine learning modeling.
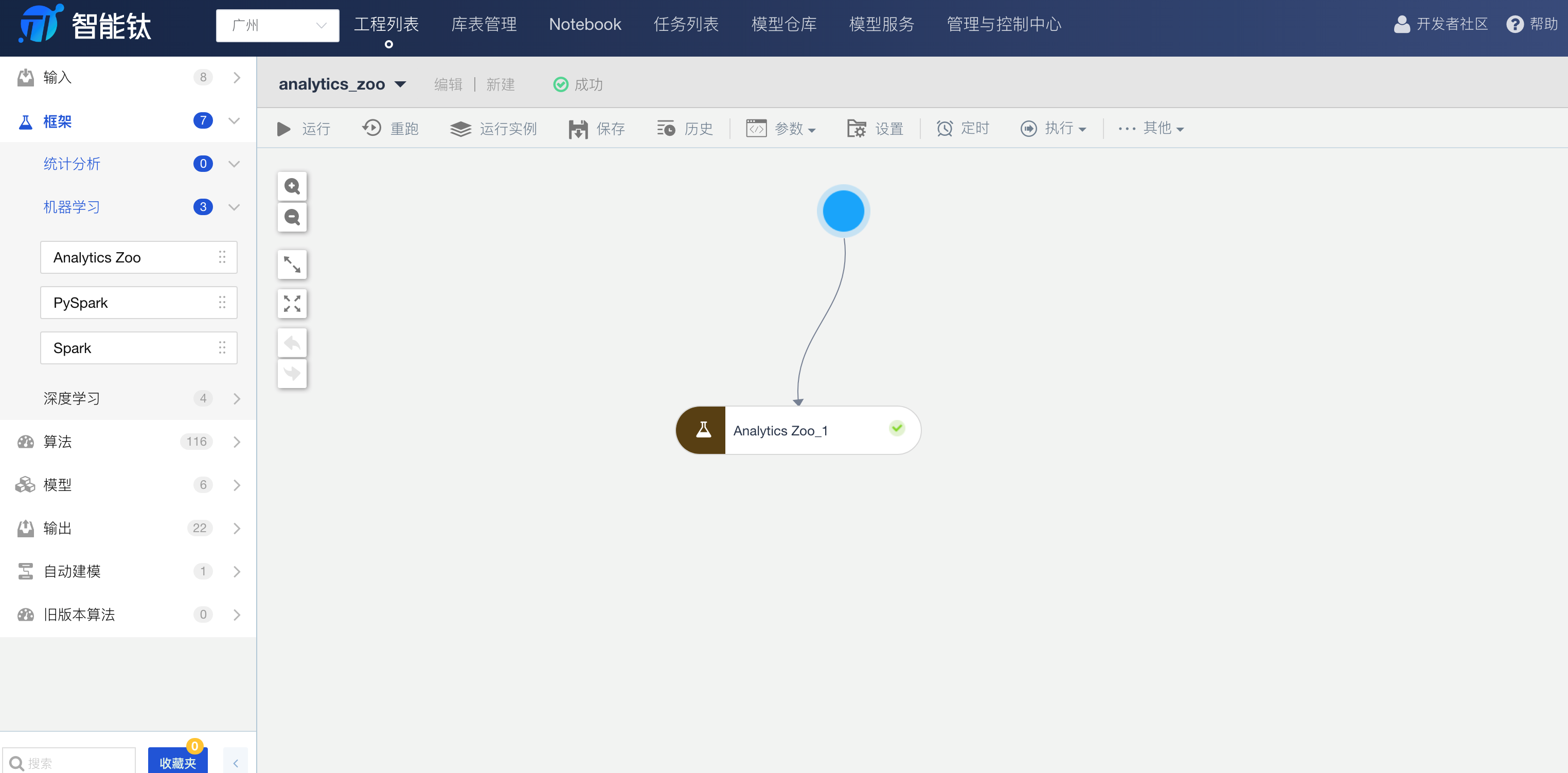
Figure 3 TI-ONE integrated with Analytics Zoo
Benefits of Analytics Zoo AutoML
The AutoML support in Analytics Zoo can automate feature generation, model selection, and hyperparameter tuning. In addition, a model generated through the training of AutoML is usually more accurate than that generated through traditional methods or manual tuning measures. As shown in the comparison between Figure 4 and Figure 5, when the periods of time-series data are irregular, using traditional method to predict time-series data produces large deviations, whereas the predicted values obtained through Analytics Zoo AutoML are almost consistent with the actual values. As shown in the comparison between Figure 6 and Figure 7, when the peaks of time-series data do not occur regularly, using the traditional method to predict time-series data produces large deviations, whereas the predicted values obtained through Analytics Zoo AutoML are almost consistent with the actual values.
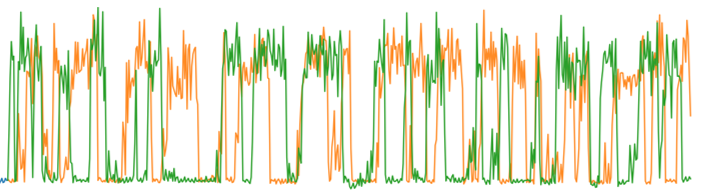
Figure 4 Time-series data predicted by using the traditional method

Figure 5 Time-series data predicted by using Analytics Zoo AutoML
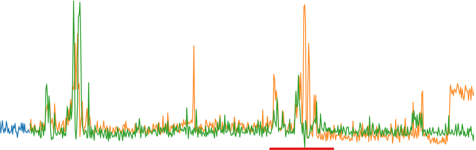
Figure 6 Time-series data predicted by using the traditional method
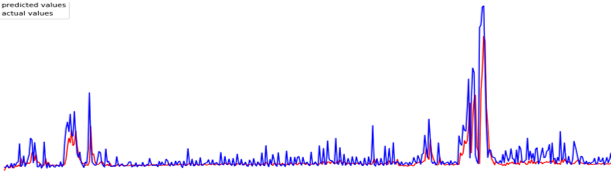
Figure 7 Time-series data predicted by using Analytics Zoo AutoML
Anomaly Detection Using AutoML on Tencent* Cloud's Ti-One Platform
The following section describes how to use Analytics Zoo AutoML on Tencent Cloud's TI-ONE platform through a use case.
Tencent Cloud applies the advanced 2nd generation Intel® Xeon® Scalable processors to Tencent Cloud's TI-ONE platform. The 2nd generation Intel® Xeon® Scalable processors support the Intel® Deep Learning Boost technology, which significantly increases performance of AI workloads, especially deep learning workloads. By leveraging the optimization and acceleration of Intel® MKL-DNN, Analytics Zoo greatly improves model training and inference performance of the Intel® Xeon® Scalable processors.
The process of creating an instance based on Intel® Xeon® Scalable processors on Tencent Cloud is as follows:
Create an instance -> customize configuration -> select a region or model -> select 2 cores (Cascade Lake) and 4 GB or better configuration

Figure 8 Creating an instance based on Intel® Xeon® Scalable processors on Tencent Cloud
Analytics Zoo provides a notebook example in which AutoML is used for anomaly detection for time-series data. AutoML uses historical values as input to train a model, and then uses the trained model to predict the next data point. When the actual value deviates significantly from the predicted value of the model, it is considered abnormal.
This case uses a dataset (NYC taxi passengers) of Numenta Anomaly Benchmark as an example. The dataset contains 10,320 samples, and each sample indicates the total number of taxi passengers in New York City at a particular point in time. The data format is as follows:
Before running the case, you need to download and decompress the data package, and upload the data file nyc_taxi.csv to cos.
The following are the key steps of using AutoML to train a time series model:
Use required parameters to initialize a TimeSequencePredictor object, and then call TimeSequencePredictor.fit to automatically perform machine learning and training on historical data in a distributed manner. After training is complete, a TimeSequencePipeline object is obtained.
The input data (train_df) of TimeSequencePredictor is a (Pandas) Dataframe that contains a series of records. Each record contains a timestamp (dt_col) and the associated data point value (target_col). Each record may also contain an extra input feature list (extra_feature_col). After the TimeSequencePredictor training is complete, TimeSequencePipeline is obtained, which is used to predict the target_col of future time steps.
The recipe parameter contains parameters required by TimeSequencePredictor, which are used to specify the search space, stop conditions, and sample quantity (the number of samples generated in the search space) during training. Currently, available recipe parameters include ‘SmokeRecipe’, ‘RandomRecipe’, ‘GridRandomRecipe’, and ‘BayesRecipe’.
You can save TimeSequencePipeline (containing the optimal hyperparameter configuration and the trained model returned by the AutoML framework) obtained through the training to a file and load it later for evaluation, prediction, or incremental training. The details are as follows:
The following figure shows the number of taxi passengers of the next time step predicted by using AutoML.

Figure 9 Number of taxi passengers of the next time step predicted by using AutoML
Summary
Through in-depth technical cooperation, ML teams from Intel and Tencent have integrated Analytics Zoo into the TI-ONE platform, empowering the platform with AutoML features, and thus making it easy for AI beginners to use. Integrated with Analytics Zoo, TI-ML platform combines various data sources, components, algorithms, models, and evaluation modules, and allows algorithm engineers and data scientists to perform model training, evaluation, and prediction with ease.
At present, the TI series supports public cloud access, private deployment, and dedicated cloud deployment.
Reference
https://github.com/intel-analytics/analytics-zoo
https://cloud.tencent.com/product/ti
*Other names and brands may be claimed as the property of others
The chinese version, please see https://www.intel.cn/content/www/cn/zh/service-providers/analytics-zoo-helps-tencent-cloud-improve-ti-ml-platform-performance.html