Introduction
The Storage Performance Developer Kit (SPDK), a collection of application software acceleration tools and libraries, was developed by Intel to accelerate the use of Non-Volatile Memory Express* (NVMe) solid state drives (SSD) as a back-end storage solution. The core of this software library is a user space, asynchronous, poll mode NVMe driver. Compared to kernel NVMe drivers, this driver provides a cost-effective solution that can greatly reduce the latency of NVMe commands and improve per-CPU core input/output operations per second (IOPS).
In this article, we show how the SPDK-based virtual host (vhost) solution can be applied to a Hyper Converged Infrastructure (HCI) to accelerate NVMe input/output (I/O) in the virtual machine.
Application Event Framework
To achieve this goal, it is not enough to provide user space NVMe operation functions. If used incorrectly in some application scenarios, it will not only fail to give full play to the performance of the user space NVMe driver, but may even lead to program errors. In order to better manage performance of the underlying NVMe and guarantee the expected behavior, SPDK provides a programming framework (SPDK Application Event Framework) to guide software developers working with the SPDK user space NVMe driver and user space block device layer (bdev). Users have two choices:
- Implement the application logic by directly using the SPDK application event framework.
- Using the idea of SPDK application event framework, customize the existing application programming logic to better adapt the SPDK user space NVMe driver.
In general, the application event framework of SPDK can be divided into the following parts:
- Management of CPU cores and threads
- Efficient cross-thread communication
- The I/O processing model and the lockless mechanism of data path
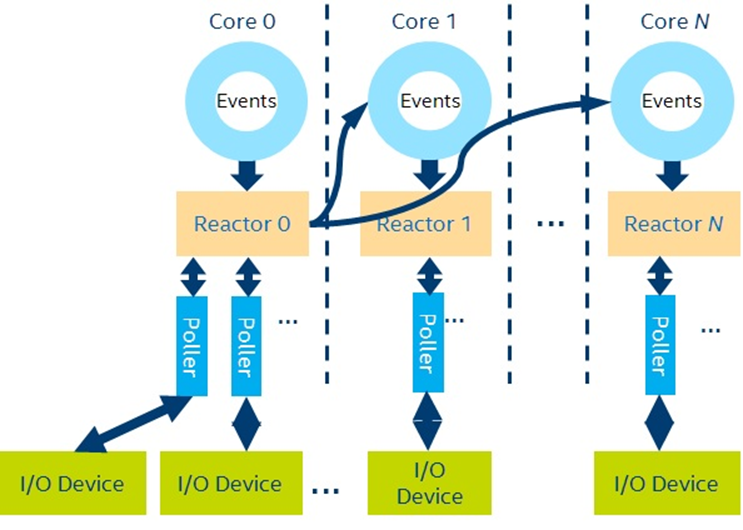
Figure 1. Storage Performance Development Kit (SPDK) Application Event Framework (Reactor, Event, Poller)
CPU Core and Thread Management
One of the main goals of SPDK is to accomplish the greatest number of tasks while using the fewest CPU cores and threads. To do this, the SPDK initializes the program (currently calling the spdk_app_start function) by limiting the cores bound to CPU. You can set it up in a configuration file or in the command line; for example, using -c 0x5 on the command line means using core0 and core2 to start the program. With the affinity of the CPU kernel binding function, it is possible to limit CPU usage and run a thread on each kernel, which is called Reactor in SPDK (as shown in Figure 1). The SPDK environment library (ENV) currently relies on the Data Plane Development Kit (DPDK) Environment abstraction library (EAL) by default. In general, the Reactor thread executes the function _spdk_reactor_run whose body contains a while(true){} loop until the state of the Reactor is changed, such as by spdk_app_stop. In order to be efficient, there are also statements in the loop that make CPU resources available (such as sleep). This while loop often leads to 100% CPU usage, which is similar to DPDK behavior.
An application using the SPDK application event framework, assuming two CPU cores, will start one Reactor thread per core. So how do users perform their own functions? In order to solve this problem, SPDK provides a Poller mechanism, which is actually a sub-assembly of user-defined functions. There are two types of Pollers provided by the SPDK:
- A timer-based Poller
- A non-timer Poller
The data structure corresponding to the SPDK Reactor thread struct spdk_reactor has a corresponding list to maintain the mechanism of Poller. For example, there is a linked list to maintain the timer-based Poller. There is also another linked list to maintain the non-timer Poller and provide Poller registration and destruction functions. In the Reactor while loop, the state of these Pollers is kept in-check, and the corresponding calls are made so that the user's functions can be invoked accordingly. Since there is only one Reactor thread on a single CPU, the same Reactor thread does not require a lock mechanism to protect resources. But if there are multiple CPU cores, threads on the cores of different CPUs are necessary to communicate with each other. To solve this problem, SPDK encapsulates messages that are passed asynchronously between threads using a technique called async messaging passing.
High-Efficiency Cross-Thread Communication
SPDK does not use the traditional method of locking to communicate between threads, which is less efficient. To make a thread execute only for the resources it manages, SPDK provides a mechanism for event calls. The essence of this mechanism is that each Reactor's corresponding data structure, struct spdk_reactor, maintains a Multi Producer and Single Consumer Model (MPSC). event ring. Each Reactor thread can receive event messages from any other Reactor thread, including the current Reactor thread, for processing. At present, the default implementation of event rings in SPDK depends on the mechanism of DPDK. This ring should have a locking mechanism, but it is more efficient than the synchronization mechanism between threads. There is no doubt that the processing of this Event ring is actually handled by Reactor's function, _spdk_reactor_run. The data structure of each event, struct spdk_event, actually includes the function that needs to be executed, along with the corresponding parameters, as well as the core to be executed. To summarize, when Reactor A communicates with Reactor B, it requires the execution function F(X) of Reactor B, where X is the corresponding parameter. Based on this mechanism, SPDK implements a more efficient mechanism for inter-thread communication. For specific examples, refer to some internal implementations of SPDK NVMe-oF target. The main code is located in the directory lib/nvmf in SPDK’s code base.
I/O Processing Model and Lockless Data Path
The SPDK's main I/O processing model is Run-to-Completion, which means rit runs until all tasks are done. As we discussed earlier, using the SPDK application event framework, a CPU core has only one thread that can execute many Pollers, including timers and non-timers. Run-to-Completion aims to make it possible for a thread to perform all tasks. The SPDK programming framework meets this need. If you do not use the SPDK application event framework, you need to pay attention to this matter yourself. If you are using the SPDK user space NVMe driver to access the corresponding I/O Queue Pair (containing both NVMe submission and completion queue) for read and write operations, SPDK provides functions for asynchronous read-write, spdk_nvme_ns_cmd_read, and functions to check whether they are completed, spdk_nvme_qpair_process_completions. Calls to these functions should be made by one thread, not across threads.
The SPDK I/O path also uses a lockless architecture. When more than one thread operation accesses an SPDK user-space bdev, SPDK puts forth a concept of I/O channel. The I/O channel is actually a mapping relationship between thread and device. When a different thread operates, the same device should be recognized as a different I/O channel, as each I/O channel uses its own independent resources on its I/O path. This avoids resource competition and removes the locking mechanism.
FAQ
- How many versions of SPDK are released each year?
-
Four versions are released each year in January, April, July, and November. For example: The version that released in April 2018 is 18.04.
- What's the version numbering system?
-
Version names are in the format YY.MM, where YY is year and MM is month. For example: The version that released in April 2018 is 18.04.
- What is the relationship between the SPDK and DPDK?
-
The original name of the SPDK was Waikiki Beach, and its full name was Intel® DPDK for Storage, but after moving to open-source in 2015, we changed the name to Storage Performance Developer Kit (SPDK). SPDK provides a set of environment abstraction libraries (located in the lib/env directory). This library is mainly used to manage CPU resources, memory, PCIe*, and other device resources used by SPDK storage applications. DPDK is the default environment library for SPDK. Each time the SPDK releases a new version, it will use the stable version of the newly released DPDK. For example, SPDK 18.04 used the DPDK 18.02 version.
- What are the typical usage scenarios for SPDK?
-
At present, the SPDK is not a universal adaptation solution for storage applications. Because the kernel drivers are placed in user mode, a complete I/O stack based on user mode software drivers is required. File systems are an important topic, and it is obvious that kernel file systems (such as Linux* ext4 or Btrfs filesystems) cannot be used directly. Although the SPDK currently provides a very simple "file system" blobfs/blobstore, it does not support the Portable Operating System (POSIX) interface. For this purpose, the file system application should be directly migrated to the SPDK user- mode "file system". Some code migration is required in this process. For example, an asynchronous read-write approach like AIO is used instead of the POSIX interface. Of course, the SPDK community has been working hard on file system support.
Currently, SPDK is best suited to use in the following application scenarios:
- Accelerating the back-end storage applications that provide block device interfaces such as the Internet Small Computer System Interface (iSCSI) target and the NVMe over Fabrics (NVMe-oF) target.
- Accelerating I/O (for example, Virtio or NVMe protocol) in a virtual machine. Customers primarily use Quick Emulator (QEMU) plus Kernel-based Virtual Machine (KVM) as a hypervisor to manage virtual machines in a Linux system. SPDK uses the vhost interaction protocol to implement an efficient vhost user-state target based on a shared memory channel (for example, vhost SCSI/BLK/NVMe target) to speed up the I/O drivers for the Virtio SCSI/BLK and kernel native NVMe protocols in the virtual machine. The main principle is to reduce the number of events such as VM interrupts (such as interrupt, VM_EXIT), and shorten the I/O stack in the host OS.
- Accelerating the database storage engine. By implementing the abstract file class in RocksDB, SPDK's blobfs/blobstore can now be integrated with RocksDB to speed up the use of the RocksDB engine on the NVMe SSD. The essence is the bypass kernel file system, which uses the SPDK-based user-space I/O Stack. In addition to SPDK support for RocksDB, SPDK blobfs/blobstore can also be used to integrate other database storage engines.
Conclusion
In summary, the Storage Performance Developer Kit (SPDK) was developed as a back-end storage solution initiated by Intel to speed up the use of NVMe SSDs. The application event framework guides software developers in implementing application logic to reduce program errors. Read additional information about the SPDK or download it today.