Introduction
Intel® Optane™ DC Persistent Memory
Intel® Optane™ DC persistent memory is an innovative memory technology that delivers a unique combination of affordable large capacity and support for data persistence.
This technology introduces a flexible new tier to the traditional memory and storage hierarchy, architected specifically for data center usage. By deploying systems enabled by this new class of memory, customers can optimize their workloads more effectively by moving and maintaining larger amounts of data closer to the processor, thus minimizing the higher latency that can occur when fetching data from the system storage. In this article, we examine how Intel developers optimized Apache Spark* for Intel Optane DC Persistent Memory.
Intel Optane DC Persistent Memory has two operating modes: App Direct and Memory Mode. Memory Mode is the ‘out of the box’ answer that requires no code changes to the application and leverages the large capacity of Intel® Optane™ DC memory modules as volatile memory. In this mode, the DRAM acts as another level of cache, and the persistent memory capacity becomes the main memory. Data placement in memory mode is controlled by the memory controller instead of the application. In App Direct mode, on the other hand, persistent memory is exposed to the OS as a special block device, and DRAM is used as the main memory.
Apache Spark*
Apache Spark* is a popular open-source data processing engine designed to execute advanced analytics on very large data sets, which are common in today’s enterprise use cases involving cloud-based services, IoT, and machine learning. Spark is a general-purpose clustered computing framework that can ingest and process real-time streams of very large data, enabling instantaneous event and exception handling, analytics, and decision making for responsive user interaction.
Improve Caching Performance
Challenges
One of the challenges facing large Apache Spark* workloads is that of performance bottlenecks when accessing data from either local or remote storage, with the latter being more pressing as it becomes more popular to store data in the cloud. As the data size increases, traditional ways of caching, such as those used by operating system’s page caches, tend to be unable to effectively reutilize data to avoid excessive I/O wait times.
Solution
To this end, Intel developed the Optimized Analytics Platform (OAP), an open source middleware for Apache Spark providing a smart caching layer between data movement and computing with the following features:
- Hot data caching
- User-defined indexes
- Cache-aware scheduling
OAP’s cache-aware scheduler can intelligently schedule processes in computing nodes where the data to be processed is located. Doing so reutilizes previous queries’ used data and results. The benefit is a significant reduction in the amount of I/O accesses needed for a wide range of workloads. OAP is an open source solution that is easy to use and works on any hardware. Nevertheless, and as we will show in this article, OAP has been optimized to fully take advantage of Intel® Optane™ DC Persistent Memory Modules.
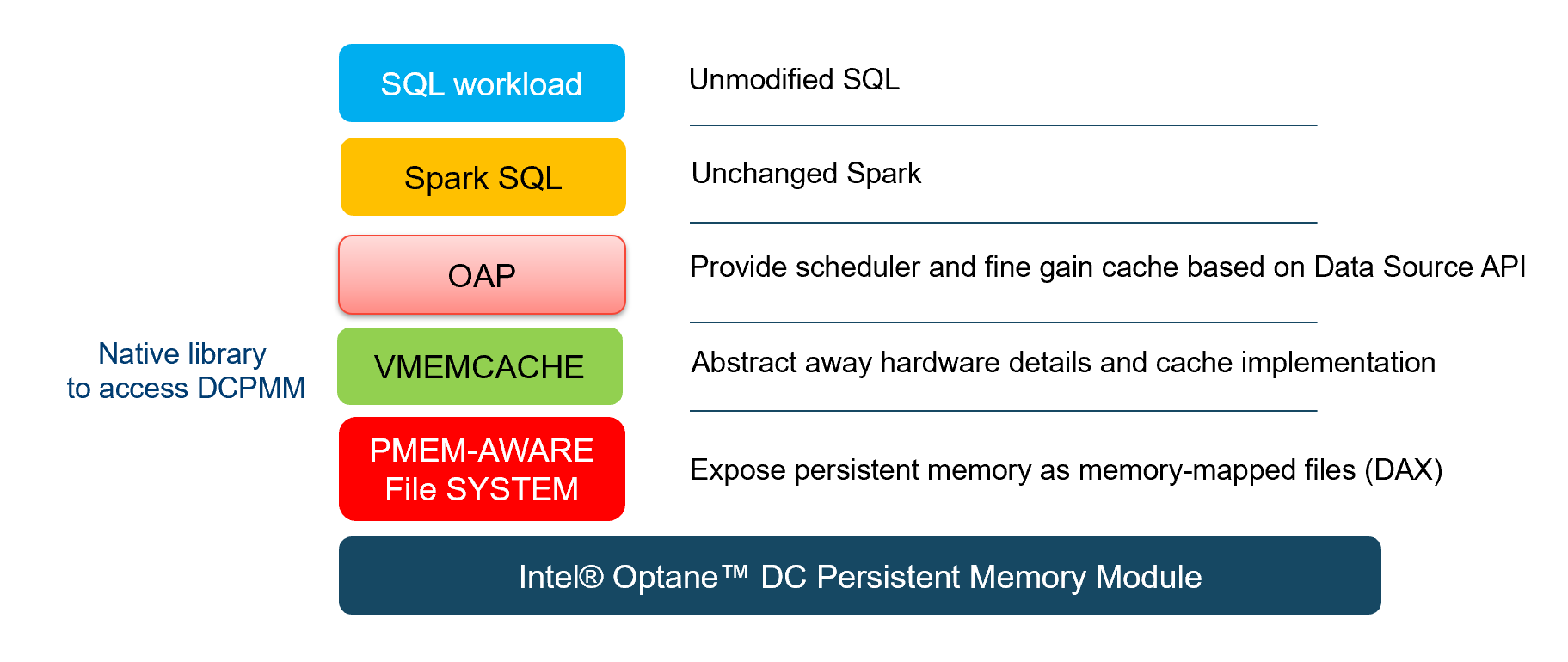
Figure 1: New Apache Spark* analysis stack including OAP and Intel® Optane™ DC Persistent Memory Modules.
In order to understand why adding Intel® Optane™ DC Persistent Memory to OAP makes sense, realize that OAP effectiveness depends heavily on the size of the cache, and this cache is stored in DRAM in the original design. DRAM can become significantly expensive when scaling beyond certain module sizes, or directly not available. Intel Optane DC Persistent Memory, on the other hand, is cheaper than DRAM and can scale all the way to 3TB per CPU socket.
The rest of this article explains how OAP was modified to take advantage of Intel Optane DC Persistent Memory. In each step, we show the different technologies considered, the problems encountered along the way, and what developers did to overcome them.
Adding Persistence Using PMDK
When considering how to make OAP use persistent memory, the development team started with testing the persistence libraries libpmem and libpmemobj from the Persistent Memory Development Kit (PMDK), a collection of libraries and utilities for managing persistent memory. PMDK, while developed and maintained by Intel, is vendor neutral, fully open source, and is built upon the SNIA NVM Programming Model. These libraries build on the Direct Access (DAX) feature available in both Linux and Windows, which allows applications direct load/store access to persistent memory by memory-mapping files on a persistent memory aware file system.
The idea was to cache OAP’s large chunks of data in persistent memory. Although the libpmem and libpmemobj libraries are specifically designed for persistent memory programming, the level of abstraction offered by their APIs wasn’t quite the right one. Their scope aims more toward applications that require complex persistent data structures. OAP, on the other hand, required something more high level. A mechanism allowing it to cache large chunks of data—corresponding to files in the old design—easily and efficiently was needed.
Managing Volatile Capacity Using Memkind
The team then looked to the Memkind library, a user-extensible memory allocator built atop jemalloc with a malloc()/free()-like API. Memkind, which is also part of PMDK, enables partitioning of the heap between different kinds of memory. Benefits of managing large, volatile memory with memkind include:
- Applications see separate pools of memory for DRAM and persistent memory
- Applications have more memory available for data sets
- Latency-sensitive data goes into DRAM for optimal quality of service
- Applications can manage data placement
Memkind allowed developers to separate the memory allocated for the processes’ heap in DRAM, and the processes’ OAP cache in persistent memory.
Fragmentation Issues
Persistent memory is attractive due to its low latency, huge storage capacities, and support from PMDK. But there is a common challenge of fragmentation that caching systems and any long-running application must handle, which wasn’t solved by the available set of libraries.
Let say, for example, that you have an address space of 384 bytes and make the following allocation requests:
A=malloc(128);
B=malloc(128);
C=malloc(128);
If, later, you decide to free A and C:
Free(A); Free(C);
Your resulting address space would have two chunks of 128 bytes available. In principle, you have 256 bytes, which means that you should be able to call malloc to allocate 256 bytes successfully. However, an error stating not enough memory would be returned since there isn’t a contiguous capacity of 256 bytes available.
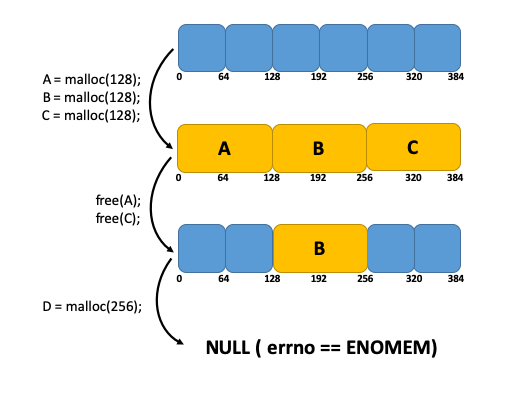
Figure 2: Memory fragmentation problem affecting long-running caching systems.
There are multiple ways to allocate/free memory in a heap, and each mechanism has its pros and cons. Compacting garbage collectors and defragmentation algorithms, for example, require processing to occur on the heap to free unused allocations or move data to create contiguous space. Another type of allocator, called “slab allocators,” usually defines a fixed set of different sized buckets at initialization without knowing how many of each bucket the application will need. If the slab allocator depletes a certain bucket size, it allocates from larger sized buckets, which reduces the amount of free space. Neither of these approaches was fully satisfactory for the task at hand, given that applications would either suffer memory fragmentation or a performance impact due to the processing needed for memory management.
Developers were still looking for something lightweight and efficient to create an in memory, local, and scalable cache that would take advantage of the large capacities available with persistent memory.
Libvmemcache
After trying a few different solutions, an accelerator called vmemcache was developed to help resolve fragmentation issues. Libvmemcache, written in C, is an embeddable, lightweight in-memory caching solution with a key-value store at its core. It is designed to take full advantage of large-capacity memory, such as persistent memory, efficiently using memory mapping in a scalable way.
Libvmemcache design revolves around two main aspects:
- Allocator designed to improve/resolve fragmentation issues
- A scalable and efficient Last Recently Use (LRU) policy called buffered LRU
Thanks to Persistent Memory’s ability to support cache-line granularity, Libvmemcache efficiently uses extent allocation for relatively small blocks. The figure below shows that if a single contiguous free block is not available to allocate an object, multiple, non-contiguous blocks are used to satisfy the allocation request. This allowed developers to sidestep fragmentation problems that affect many in-memory databases and achieve very high space utilization for most workloads.
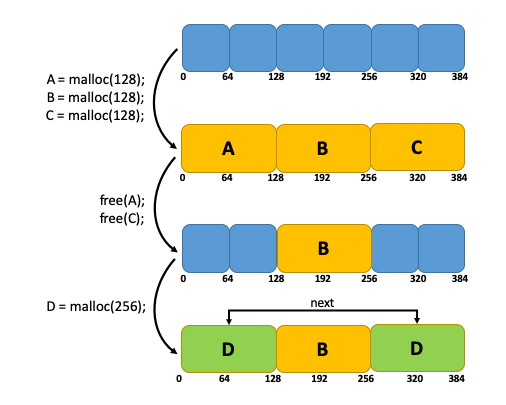
Figure 3: Fragmentation problem solved using extent allocation.
Buffered LRU combines a traditional LRU doubly linked list with a non-blocking ring buffer to deliver high scalability on modern multi-core CPUs. When an element is retrieved, it is added to this buffer, and only when the buffer is full (or the element is being evicted), the linked-list is locked, and the elements in that buffer are processed and moved to the front of the list. This method preserves the LRU policy and provides a scalable LRU mechanism with a minimal performance impact. The figure below shows a ring buffer-based design for the LRU algorithm.
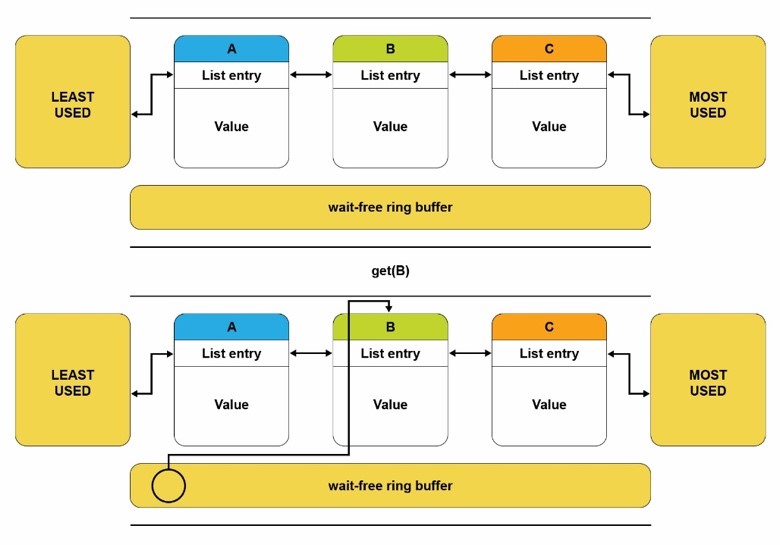
Figure 4: Scalable LRU list using a non-blocking ring buffer.
Performance of Spark with OAP
To get a sense of how the large capacities offered by Intel® Optane™ DC memory modules can help Apache Spark (enhanced with OAP) analyze large quantities of data, we compare the performance of running two workloads on two servers: one with just DRAM, and another with Intel Optane DC memory modules. The DRAM-only server is configured with 768GB of DRAM; the second server is configured with 192GB of DRAM and 1TB of Intel Optane DC persistent memory in a 2-2-1 setting (each memory controller has 3 DRAM modules and 2 persistent memory modules, totaling 12 DRAM modules and 8 persistent memory modules for a 2-socket server). For more details regarding the testing environment, see the performance disclaimer at the end of this article.
Each server configuration is chosen in order to have a fair comparison with respect to total cost of ownership (TCO), although this is never an exact science given that prices of DRAM change widely over time. Normally, we can think of a server with 768GB of DRAM to have a similar TCO than a server with 192GB of DRAM and 1.5TB of Intel Optane DC Persistent Memory (with all the other components constant), so using 1TB allows us to play it safe.
For the analysis, we use the 9 most I/O intensive queries out of the total 99 queries making up the decision support workload. By virtue of being I/O intensive, these queries are the best to showcase the value of adding Intel Optane DC memory modules. Nevertheless, we plan to update this article with the performance results for the whole set of 99 queries, so stay tuned if you wish to know more. Likewise, we are performing another experiment (which will be also included in this article) to see the added benefit when scaling out the execution to multiple nodes in a cluster setting.
The cache size is configured to be 610GB for the DRAM-only server and 1TB for the server with persistent memory. This gives the latter a capacity advantage of nearly 400GB (+64%). In all experiments, 9 threads (multi-tenants) are used as query-submitting clients.
The first set of experiments are run with a 2TB data scale, where both servers can hold the entirety of the working set size (613GB) in the cache.
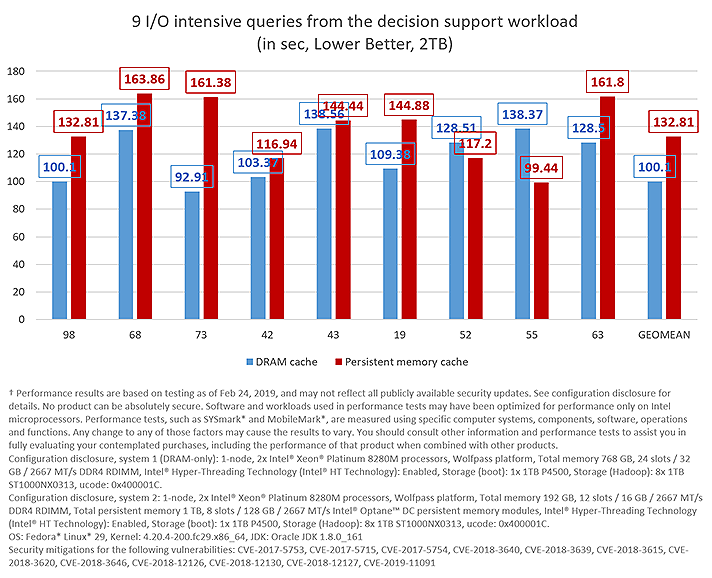
Figure 5: 9 I/O intensive queries using a 2TB data scale with a working set size of 613GB.
In this case, the DRAM-only server is 24.6% faster—on average—than the one with persistent memory. This is somewhat expected, given that DRAM has better performance than persistent memory in general. In addition, the server with persistent memory is being penalized in terms of bandwidth given that we are not fully populating all the available slots (8 of 12 are populated).
For the second set of experiments, a 3TB data scale is used with a working set size (920GB) fitting only in the server with a persistent memory cache.
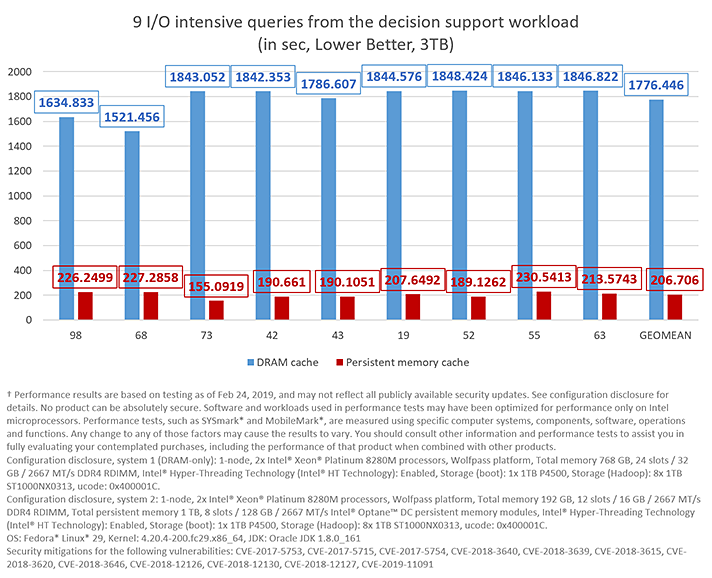
Figure 6: 9 I/O intensive queries using a 3TB data scale with a working set size of 920GB.
In this case, the server with persistent memory is the clear winner thanks to its extra cache capacity, giving it an 8X performance gain—on average—as compared to the DRAM-only server.
Finally, the third set of experiments test the case where 4TB Data Scale is used with a working set size (1226.7GB) that does not fit in either of the two servers’ caches.
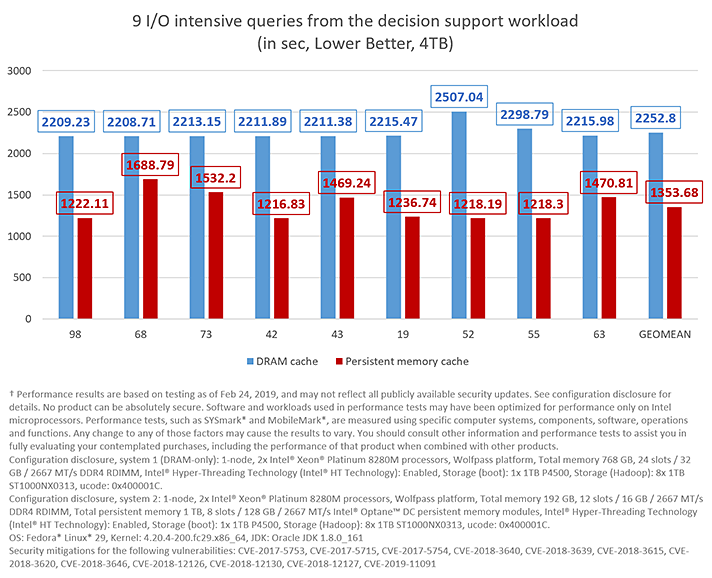
9 I/O intensive queries using a 4TB data scale with a working set size of 1226.7GB.
In this case, the server with persistent memory shows a 1.66X performance gain on average.
Summary
Accelerating Spark workloads to take full advantage of persistent memory is made easier thanks to vmemcache and OAP developed by Intel. Libvmemcache is an embeddable and lightweight in-memory caching solution that allows applications to efficiently use persistent memory’s large capacity in a scalable way. OAP builds upon that solution to tailor the acceleration to Spark workloads. Together, they were able to achieve impressive results for the 9 most I/O intensive queries out of the 99 queries composing the decision support workload. Both OAP and Libvmemcache are available as open-source projects on GitHub, where readers can build from source and contribute to the product development.
Resources
- Optimized Analytics Platform (OAP)
- Persistent Memory Development Kit (PMDK)
- SNIA NVM Programming Model
- Vmemcache
- Learn more about Intel Optane DC persistent memory
- Decision support workload
Notices
† Performance results are based on testing as of Feb 24, 2019, and may not reflect all publicly available security updates. See configuration disclosure for details. No product can be absolutely secure. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
Configuration disclosure, system 1 (DRAM-only): 1-node, 2x Intel® Xeon® Platinum 8280M processors, Wolfpass platform, Total memory 768 GB, 24 slots / 32 GB / 2667 MT/s DDR4 RDIMM, Intel® Hyper-Threading Technology (Intel® HT Technology): Enabled, Storage (boot): 1x 1TB P4500, Storage (Hadoop): 8x 1TB ST1000NX0313, ucode: 0x400001C.
Configuration disclosure, system 2: 1-node, 2x Intel® Xeon® Platinum 8280M processors, Wolfpass platform, Total memory 192 GB, 12 slots / 16 GB / 2667 MT/s DDR4 RDIMM, Total persistent memory 1 TB, 8 slots / 128 GB / 2667 MT/s Intel® Optane™ DC persistent memory modules, Intel® Hyper-Threading Technology (Intel® HT Technology): Enabled, Storage (boot): 1x 1TB P4500, Storage (Hadoop): 8x 1TB ST1000NX0313, ucode: 0x400001C.
OS: Fedora* Linux* 29, Kernel: 4.20.4-200.fc29.x86_64, JDK: Oracle JDK 1.8.0_161
Security mitigations for the following vulnerabilities: CVE-2017-5753, CVE-2017-5715, CVE-2017-5754, CVE-2018-3640, CVE-2018-3639, CVE-2018-3615, CVE-2018-3620, CVE-2018-3646, CVE-2018-12126, CVE-2018-12130, CVE-2018-12127, CVE-2019-11091
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. Check with your system manufacturer or retailer or learn more at intel.com.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps.
The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request.
Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm.
This sample source code is released under the Intel Sample Source Code License Agreement.
Intel, the Intel logo, Intel Optane, and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries.
*Other names and brands may be claimed as the property of others.
© 2019 Intel Corporation