Author: Carson Wang
Co-authors: Chenzhao Guo, Hao Cheng (Intel), Yucai Yu, Yuanjian Li (Baidu)
Spark SQL* is the most popular component of Apache Spark* and it is widely used to process large-scale structured data in data center. However, Spark SQL still suffers from some ease-of-use and performance challenges while facing ultra large scale of data in large cluster. To address these challenges, Intel big data team and Baidu infrastructure team refined the Adaptive Execution implementation based on existing upstream work. This article will describe detail of the challenges, dispose Adaptive Execution architecture and our optimization work, and then raise the performance gain on 99 nodes cluster for the TPC-DS benchmark in 100TB data scale. Lastly, we will share the benefits of Adaptive Execution’s adoption in Baidu’s Big SQL platform.
Challenge 1: Shuffle Partition Number
In Spark SQL, shuffle partition number is configured via spark.sql.shuffle.partition, and the default value is 200. This parameter determines the number of reduce tasks and impact the query performance significantly.
For example, a Spark SQL query runs on E executors, C cores for each executor, and shuffle partition number is P. Then, each reduce stage needs to run P tasks except the initial map stage. Due to preemptive scheduling model of Spark, E x C task executing units will preemptively execute the P tasks until all tasks are finished. During this process, if some tasks deal with much more data than others (i.e. data skew) or they run for a long time due older disk, lower CPU frequency, etc., the resource utilization rate of the entire cluster will be low and the current stage execution time will be longer.
How do we configure an appropriate shuffle partition number? If it is too small, then lower parallelism, and each reduce task has to process more data. Spilling to disk even happens as memory may not hold all data. In the worst case, it may cause serious GC problems or OOMs.
However, if the value is too large, we may not ignore the scheduling overhead as there will be too many small reduce tasks and many small files generated, also will cause performance issue.
In short, shuffle partition number can neither be too small nor too large. In order to get the best performance, we often need to tune shuffle partition number for multiple rounds in non-production environment.
In practice, SQL queries often run as Cron jobs to process data for various different time periods. The amount of data may vary, and manual tuning does cause lots of human effort. On the other hand, this parameter is a global setting and impact all of the reduce tasks number in different stages for current query, but the same shuffle partition number cannot fit all stages for a single query, as each stage has different output data size and distribution.
Can we set this value for each stage respectively and automatically?
Challenge 2: Best Execution Plan
Physical plan selection impacts the SQL query execution performance a lot. However, the physical plan selection has been planned before the query execution launched, and can’t be modified in runtime. However, we may decide to use better physical plan in runtime, as we can collect more runtime information like the output data distribution, and record count etc.
Take join as an example. 2 often seen join operators in Spark SQL are BroadcastHashJoin and SortMergeJoin. BroadcastHashJoin is an optimized join implementation in Spark, it can broadcast the small table data to every executor, which means it can avoid the large table shuffled among the cluster. This improves the query performance a lot.
While SortMergeJoin is a typical shuffle join. Large amount of data is shuffled across the whole cluster, and causes many I/O and network overhead, so Spark SQL plan optimizer will try to plan join as BroadcastJoin operator in any applicable case.
During planning phase, Spark estimates the tables’ size for join and chooses BroadcastHashJoin if one table is smaller than the broadcast threshold, otherwise SortMergeJoin is used. However, the estimation is always inaccurate, for example the join may take intermediate results as input and it’s hard to predict. As a result, the conservative estimation may judge the actually smaller-than-threshold table as bigger than.
Image 1 is an example of this case, the left table is only 600kb but Spark still plans the join as SortMergeJoin.
Can we dynamically adjust the execution plan according to runtime information?
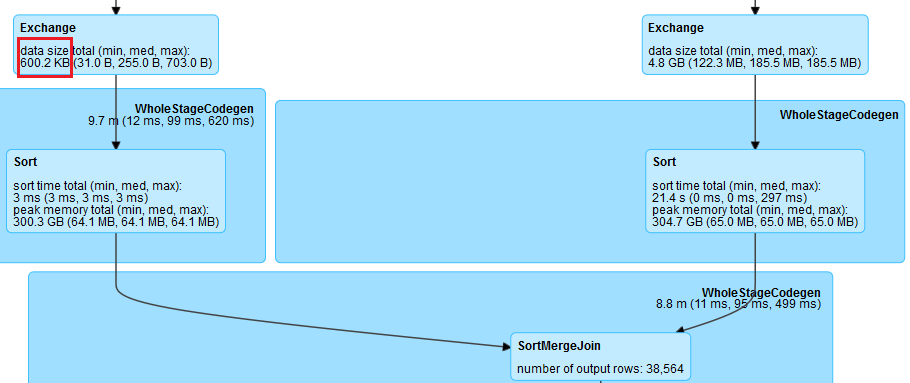
Image 1
Challenge 3: Data Skew
Data skew is a common issue that leads to the poor performance of Spark SQL. It refers to the condition when data size of some partitions is much larger than the others. Those corresponding tasks may run much longer and make the entire query slow.
In real world, data size in each hash bucket is usually different. In some extreme cases, a large number of records share the same key, and all of them will be put into the same partition bucket. Following is an example of tasks’ executing time in data skew condition. Most of the tasks took 3 seconds, while the slowest task processed 35x data size than the median, and it took 4 minutes to complete.
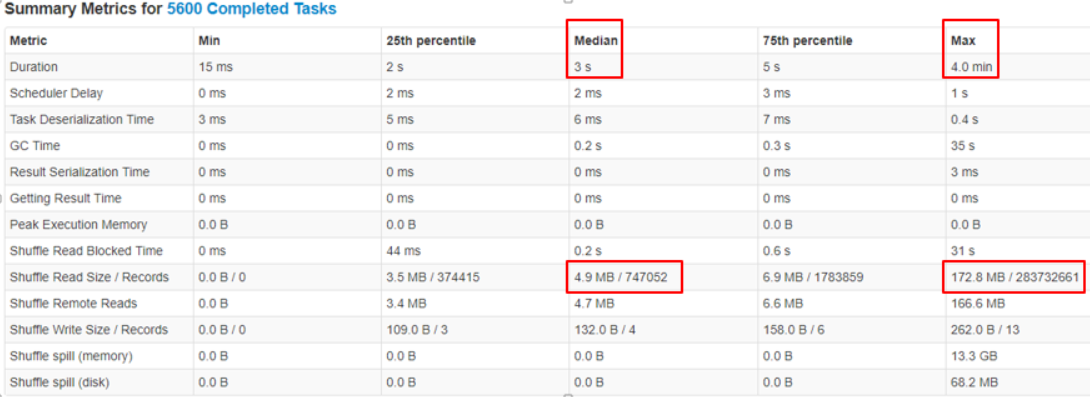
Image 2
There are some ways to handle data skew currently:
- Increase the shuffle partition number, in this way data is more likely to be hashed into different partitions. Unfortunately this won’t help when large amounts of data share same keys.
- Increase BroadcastHashJoin threshold to translate more previously planned SortMergeJoin to BroadcastHashJoin. This can avoid the data skew caused by shuffle in limited situations. More broadcast overhead is also introduced.
- Manually filter the skewed key and add a random prefix to these data. In another table, the corresponding data also need to be duplicated. If one of the join tables are taken from intermediate results, this is hard to implement.
All these methods are limited solutions and require manual efforts. Can we automatically handle data skew in join at runtime?
Adaptive Execution Background
Spark community proposed the basic idea of Adaptive Execution in 2015. In DAGScheduler, a new API is added to support submitting a single map stage. The community also tried to change the shuffle partition number at runtime. However there are some limitations in the current implementation, like introducing additional shuffles and not handling 3+ table joins well.
Based on community work, Intel big data team and Baidu infrastructure team redesigned Adaptive Execution and implemented a more flexible framework. Based on this newly implemented framework, developers are able to add more rules to support new futures. So far the implemented features include: auto setting the number of reducers, optimizing execution plan and handling skewed join at runtime.
Adaptive Execution Architecture
For current Spark, after a physical execution plan is determined during planning phase, the DAG of RDD is generated according to the definition of each operator. Then Spark scheduler creates stages by breaking the RDD graph at shuffle boundaries and submits the stages for execution.
For the new Adaptive Execution framework, we give more decision-making power to the runtime. Stages are divided earlier based on SQL execution plan to make changes at runtime. New nodes named QueryStage and QueryStageInput are introduced. QueryStage is a sub-tree of whole execution plan tree that runs in a single stage. QueryStageInput is the leaf node of a QueryStage, it is used to hide the QueryStage’s child QueryStage from its father and provide the result of child to its father. QueryStages and QueryStageInputs are added by finding Exchanges in execution plan. How are QueryStages executed? Firstly its child QueryStages are submitted. After the completion of all children, shuffle data size is collected. Based on the collected statistics of shuffle data, execution plan of current QueryStage is optimized to a better one.
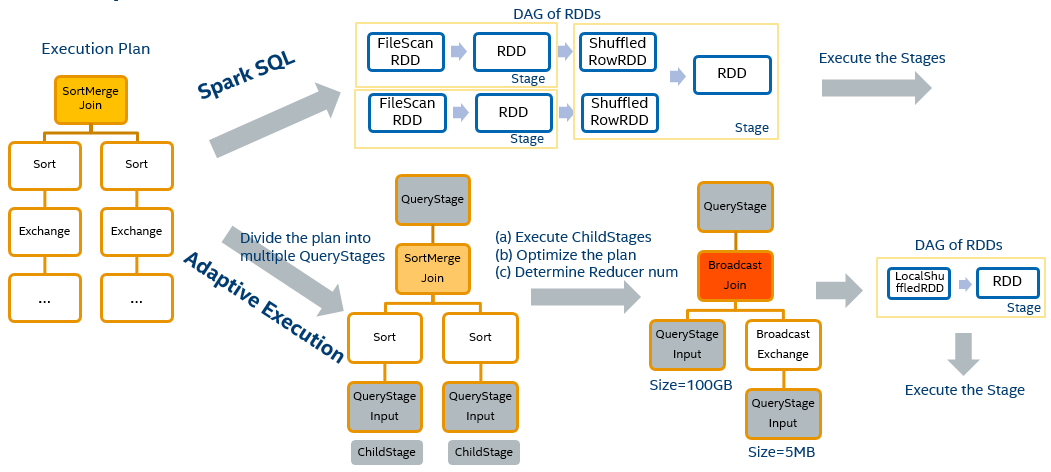
Image 3
Image 3 illustrates how Adaptive Execution works. 3 QueryStages are created in this example of joining two tables. The root node is ResultQueryStage, its sub-tree contains two QueryStageInputs providing two child QueryStage’s output. At runtime, the right table of join turns out to be 5MB which is smaller than the broadcast threshold. So the SortMergeJoin is translated to BroadcastHashJoin for better performance. Then the number of reducers is determined based on child QueryStages’ output statistics. After all optimization is applied to the current QueryStage, RDD DAG of it is generated and submitted to DAGScheduler.
Auto Setting the Number of Reducers
Image 4 illustrates how auto setting the number of reducers works. Suppose shuffle partition number is 5 and target data size per reducer is 64MB. After the map stage is finished, we know the size of each partition is 70MB, 30MB, 20MB, 10MB and 50MB respectively. In order to try to make the size of each post-shuffle partition smaller than target data size without splitting partitions, 3 reducers are determined to use at runtime for balance. The first reducer handles partition 0 (70MB). The second reducer handles 3 continuous partitions (partition 1 to 3, 60MB in total). The third reducer handles partition 4 (50MB). This is derived base on a simple algorithm which was implemented by community before.
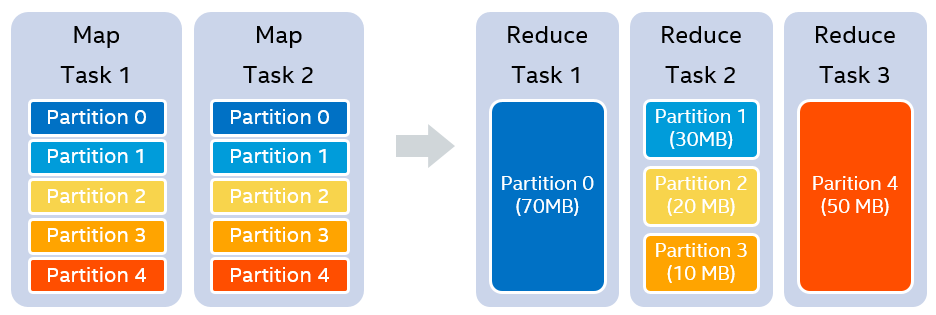
Image 4
In this new Adaptive Execution framework, each QueryStage knows all its child stages, not like the original Spark, an exchange can only see its direct child. This makes it handle well for 3+ tables join, not introducing more shuffles.
In addition, a target post shuffle partition records is also supported to be configured. This is introduced because shuffle data is usually compressed, sometimes the data size of a partition is not large but the record number is much more than others. Determining the number of reducers by considering both data size and record number is a more comprehensive approach.
Execution Plan Optimization at Runtime
Changing join strategy at runtime is a feature that has been implemented. Due to: 1. Shuffle data size information can provide current QueryStage with suggestions of better execution plan. 2. As stated in Challenge2: Best Execution plan, better performance will be got if BroadcastHashJoin is used instead of SortMergeJoin when one of the join tables's real size is small than threshold. SortMergeJoin is translated to BroadcastHashJoin when conditions are met.
Because output partitioning of SortMergeJoin and BroadcastHashJoin have different output partitionings, this translation may produce additional shuffles and cost. So we also introduced a configuration entry of max additional shuffle, it defaults to 0. The default value fits most cases, and a fine tuning for your case is also supported.
Image 5 illustrates the performance difference between SortMergeJoin and the BroadcastHashJoin translated to. Suppose the shuffle partition number is 5. In map stage, either join contains 2 map tasks. In reduce stage, 5 reducers are launched for SortMergeJoin, and each reducer proceeds remote shuffle reads. However, if BroadcastHashJoin is translated to, only 2 reducers need to be launched and each of them locally reads the full shuffle output of a mapper.
There are 3 advantages here: 1.No data transferred through network, so network I/O is saved. 2. Reading a file sequentially is much faster than randomly reading a small part of file in normal shuffle. 3. Data skew is avoided due to the shuffle is prevented.
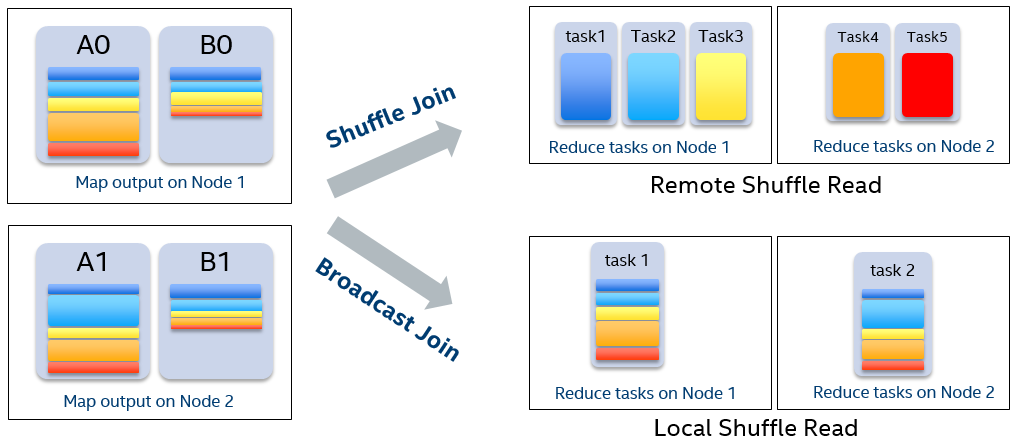
Image 5
Handling Skewed Join
In Adaptive Execution, skewed partitions are detected easily at runtime. After executing child QueryStages, shuffle data size and record number of each partition are collected. If the data size or record number of a partition is N times larger than the median and also larger than a preconfigured value, it is judged as a skewed partition and the join is judged as a skewed join.
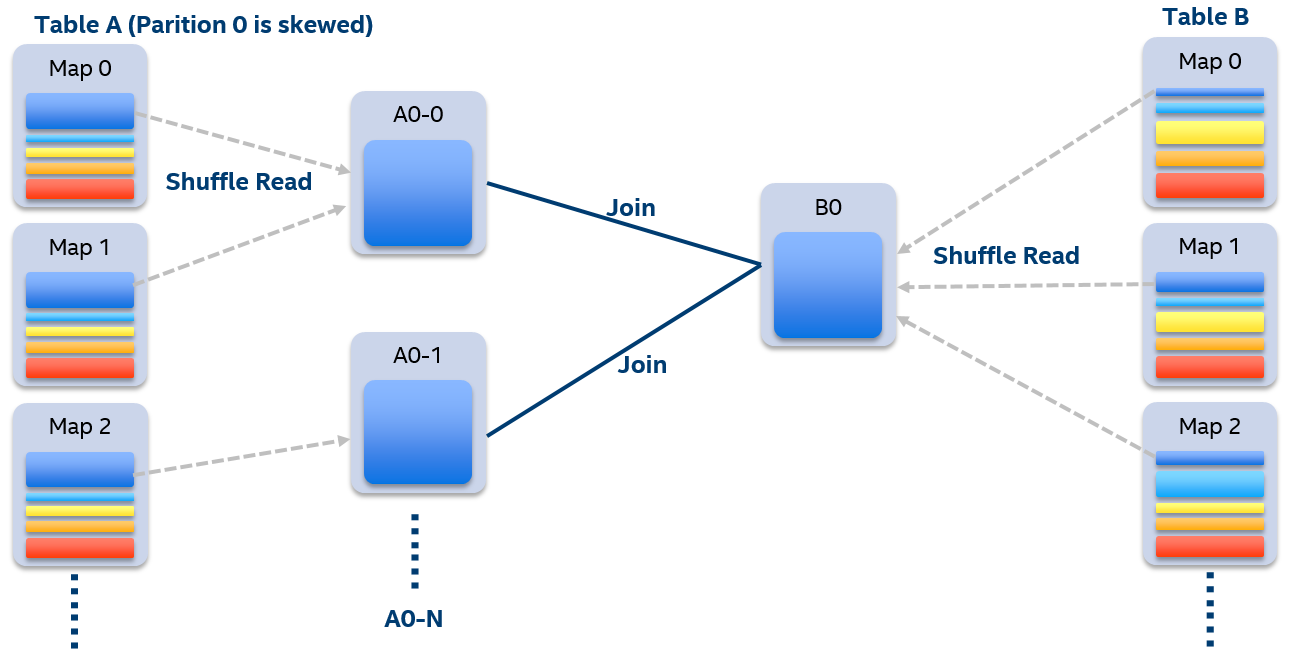
Image 6
Suppose table A and table B perform inner join and partition 0 in table A is skewed. For normal execution, partition 0 of table A and B are both shuffled to a single reducer for processing. Since this reducer need to fetch much data through network and process, it is likely to be the slowest task that extend the whole stage time.
Image 6 illustrates how handling skewed join works. N tasks are used to handle the skewed partition 0 of table A. Each task only reads a few mappers’ shuffle output of table A and joins with partition 0 of table B. The results of these N tasks are merged to get the final join result. To implement this, we updated the shuffle read API to allow reading a partition from only a few mappers instead of all.
During the processing, we can see partition 0 of table B will be read multiple times. Despite the overhead introduced, performance improvement is still significant.
Note in the above example, if partition 0 of table B is also skewed, we can also divide partition 0 of table B to several parts, joins it with each part of table A and finally union the results. However, dividing partition 0 of table B is not supported for other join types like left semi join.
Adaptive Execution vs. Spark SQL at 100 TB
We setup the cluster with 99 servers and compared the performance of Adaptive Execution and Spark SQL 2.2 using the TPC-DS benchmark with 100 TB data scale. Below is the detailed information of cluster.

Image 7
The benchmark result shows 90% queries of TPC-DS (103 queries in total) get obvious performance improvement using Adaptive Execution, 47 queries run 1.1x faster and the maximum is 3.8x faster than vanilla Spark SQL. In addition, 5 queries failed because of OOM in vanilla Spark SQL, but our optimization in Adaptive Execution makes all 103 queries finished successfully. Below image shows the performance improvement brought by Adaptive Execution.
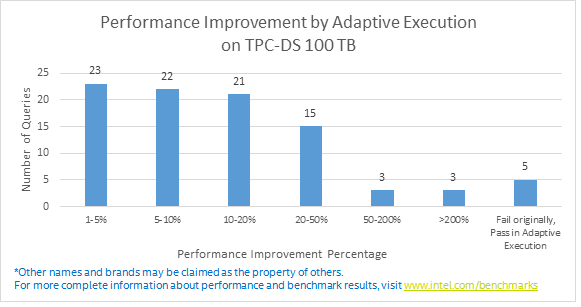
Image 8
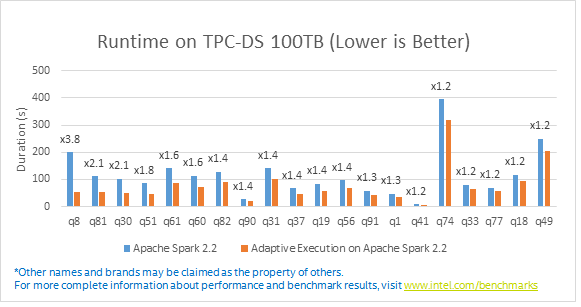
Image 9
We analyzed the SQL queries and the corresponding reason of performance improvement.
Firstly, auto setting the number of reducers provides ideal benefits. 10976 is set as shuffle partition number in vanilla Spark. In Adaptive Execution, it is changed to 1064 and 1079 for the below query. The execution time is much less because of less scheduling overhead, less task startup and less disk IO requests.
Vanilla Spark:

Image 10
Adaptive Execution:

Image 11
Secondly, optimizing the execution plan at runtime like converting SortMergeJoin to BroadcastHashJoin brings performance improvement. For example in the below query, it takes 2.5 minutes to perform SortMergeJoin. The long running time is mainly because of data skew. In Adaptive Execution, the SortMergeJoin is changed to BroadcastHashJoin because the real size of one table is only 2.5 KB. By optimizing the execution plan at runtime, the execution time of join decreases to 10 seconds.
Vanilla Spark:

Image 12
Adaptive Execution:

Image 13
Challenges at 100 TB Data Scale
Spark SQL claims to support all queries of TPC-DS but it is actually based on small data set. For such a large data scale, Spark may work inefficiently or even fail. We made some improvements to Spark on top of Adaptive Execution to make sure all queries can run successfully and efficiently. Several typical issues we resolved are recorded below.
Optimization of the single-point bottleneck of map output statistics aggregation (SPARK-22537)
At the end of each map task, data representing each partition’s size (i.e. CompressedMapStatus and/or HighlyCompressedMapStatus) is returned to driver. For Adaptive Execution, the driver aggregates partition size information given by each mapper to get the total size of each partition after the corresponding shuffle map stage is over.
If the number of mappers is M and the number of shuffle partitions is S, the aggregation time complexity is between O (M x S) ~ O (M x S x log (M x S)). When CompressedMapStatus is used, the complexity is the lower limit of this interval. When HighlyCompressedMapStatus is used, space is saved but time will be longer, the complexity will approach the upper limit of the interval.
As M x S increases, we encounter a single bottleneck on driver, a clear manifestation of pause between map stage and the reduce stage. To deal with this single point bottleneck, we divide the tasks as evenly as possible to multiple threads.
Optimization of shuffle read contiguous partitions (SPARK-9853)
In Adaptive Execution, a reducer may read contiguous blocks of data from a single map output file. In the current implementation, it needs to be split into many separate getBlockData calls, reading a small piece of data from the hard disk each time it is called, thus requiring a lot of disk I/O.
We have made Spark read all of these contiguous blocks all at once, thus drastically reduced disk I/O. From micro benchmark, shuffle read performance is increased 3x.
Optimization of avoiding unnecessary partition read in BroadcastHashJoin
Adaptive Execution is able to provide existing operators with more possibilities of optimization.
There is a basic design in SortMergeJoin: Each reduce task will read the records in the left table first, and if the data read is empty, we do not need to read data from the right table (for non-anti join situation), this design will bring benefits when some partitions of the left table are empty. This implementation in SortMergeJoin is natural.
BroadcastJoin lacks this optimization due to there is no partitioning by join key process. In Adaptive Execution, we can do this optimization utilizing the runtime statistics obtained from shuffle. If SortMergeJoin is turned to BroadcastHashJoin at runtime and we are able to get the accurate partition size corresponding to each partition key, the newly converted BroadcastHashJoin will be told: ignore the partitions which are empty in the small table, due to that join won’t get any results.
Verification in Baidu Production
We applied the Adaptive Execution optimization on Baidu’s internal ad hoc SQL query service Baidu Big SQL to make a landing verification. We selected genuine user queries of a whole day and rerun them according to the original order. We analyzed the results and got the following conclusions:
- For simple queries at second level, performance gains for Adaptive Execution are not noticeable, mainly because the bottlenecks and main time-consuming parts are IO, which is not the optimization point for Adaptive Execution.
- According to the query complexity dimension, the test results show that: the more complex the join scenario is, the better Adaptive Execution performs compared to original Spark. We simply separated the queries by number of operations of group by, sort, join, subqueries. We found queries with 3+ of these operations gain significant performance improvements. Performance gains from 50% to 150%, the main optimization comes from dynamic adjustments of shuffle parallelism and join optimization.
- From the perspective of business use, the SortMergeJoin converting to BroadcastHashJoin optimization rule described above hits a variety of typical business SQL templates in Big SQL. Consider the following computational requirements: The user expects to derive a sense of charge of certain users from two different dimensions of billing information. The original size of billing information is in the hundred T level. The user list only contains the meta information of the corresponding users, and the size is within 10M. The two billing information table contain similar fields, so we respectively inner join the two tables with the user list and then union the results, the SQL query:
select t.c1, t.id, t.c2, t.c3, t.c4, sum(t.num1), sum(t.num2), sum(t.num3) from
(
select c1, t1.id as id, c2, c3, c4, sum(num1s) as num1, sum(num2) as num2, sum(num3) as num3 from basedata.shitu_a t1 INNER JOIN basedata.user_82_1512023432000 t2 ON (t1.id = t2.id) where (event_day=20171107) and flag != 'true' group by c1, t1.id, c2, c3, c4
union all
select c1, t1.id as id, c2, c3, c4, sum(num1s) as num1, sum(num2) as num2, sum(num3) as num3 from basedata.shitu_b t1 INNER JOIN basedata.user_82_1512023432000 t2 ON (t1.id = t2.id) where (event_day=20171107) and flag != 'true' group by c1, t1.id, c2, c3, c4
) t group by t.c1, t.id, t.c2, t.c3, c4
Corresponding physical plan of original Spark:
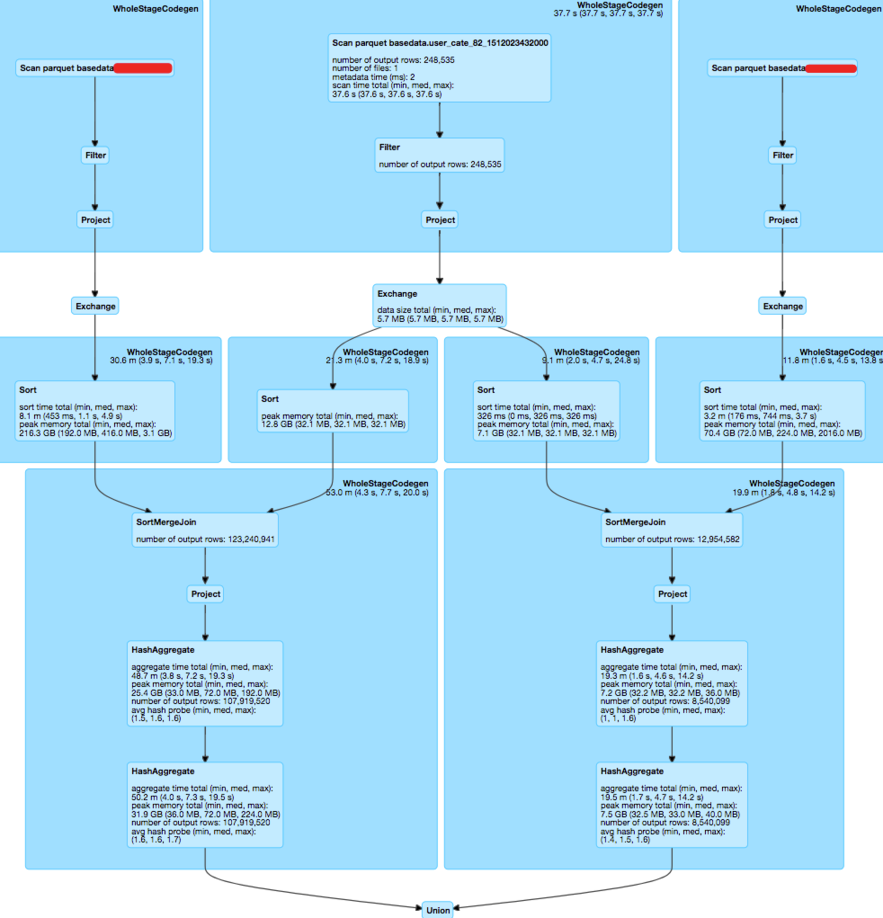
Image 14
For such scenarios, join optimization logic in Adaptive Execution is perfectly hit. SortMergeJoin is converted to BroadcastHashJoin for multiple times during execution, reducing the intermediate memory consumption and multiple rounds of sorts, achieving around 200% performance improvement.
To summarize, for complex queries running on large-scale clusters with thousands of nodes, Adaptive Execution can dynamically adjust the degree of parallelism in the calculation process, which can help greatly improve the resource utilization of the cluster. In addition, Adaptive Execution can obtain more accurate statistics between stages to make better changes.
The next step of Adaptive Execution’s landing in Baidu will concentrate on optimizing complex batch jobs with large data sets, and we may dynamically control the switch of turning on and off Adaptive Execution according to query complexity. Also, offering the corresponding data and Strategy interfaces to upper users of Baidu Spark platform and further customizing strategies for special jobs are good ways.
Conclusion
With the widespread use of Spark SQL and growing business scale, issues about ease of use and performance met on large data sets and complex queries are becoming increasingly serious.
This article illustrates three typical issues, including adjusting shuffle partition number, choosing the best execution plan and handling data skew. These are issues that need to be resolved urgently. Current framework cannot resolve them well, however, Adaptive Execution can make some difference. We introduce the architecture of it and how it can solve the three problems respectively. Then, we benchmark the Adaptive Execution we implemented using TPC-DS in 100TB data scale on 99 nodes. Compared to the original Spark SQL, 90% of the 103 SQL queries achieve significant performance gains with a maximum boost of 3.8x. Adaptive Execution also successfully complete the 5 queries that fail in original Spark. Further validation at Baidu’s Big SQL platform has shown 2x performance boost for genuine complex queries.
Adaptive Execution greatly improves Spark SQL’s ease-of-use and performance while running with large data sets and complex queries. From another perspective, cluster resource utilization in the condition of multi-tenant and multi-concurrent jobs in very large clusters is significantly improved. In the future, we plan to provide more optimization rules based on the framework of Adaptive Execution. The work will be contributed to the community and we wish more friends to join us, together we can make it better.