Related Content
Return Stack Buffer Underflow (RSBU)
Introduction
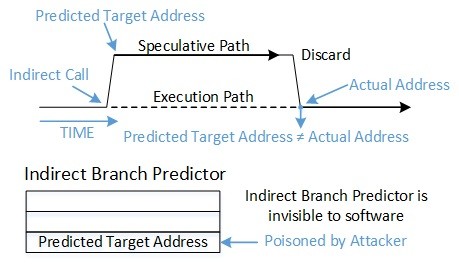
The branch target injection exploit targets a processor’s indirect branch predictor. Direct branches occur when the destination of the branch is known from the instruction alone. Indirect branches1, on the other hand, occur when the destination of the branch is not contained in the instruction itself, such as when the destination is read from a register or a memory location. The indirect branch predictor uses information about previously-executed branches to predict the destinations of future indirect branches.
Programmers’ use of function pointers in compiled languages, like C and C++, can result in indirect calls. For instance, sort functions are frequently passed a comparison function. Each call from inside sort() to compare() in the example below is likely to be an indirect call.
int compare(int a, int b)
{
return a < b;
}
sort(array, &compare);
In C++, calls to object functions are frequently implemented with indirect calls, especially when inheritance is being used.
Vehicle *car = new Car();
car->drive();
In addition to indirect branches that are performed explicitly by programmers, the compiler itself might insert indirect branches without the programmer ever being aware of them.
Exploit Composition
An exploit using branch target injection is composed of five specific elements, all of which are required for successful exploitation. Traditional application software which is not security-sensitive needs to be carefully evaluated for all five elements before applying mitigation.
- The target of the exploit (the victim) must have some secret data that an exploit wants to obtain. In the case of an OS kernel, this includes any data outside of the user’s permissions, such as memory in the kernel memory map.
- The exploit needs to have some method of referring to the secret. Typically, this is a pointer within the victim’s address space that can be made to reference the memory location of the secret data. Passing a pointer of an overt communication channel2 between the exploit and victim is a straightforward way to satisfy this condition.
- The exploit’s reference must be usable during execution of a portion of the victim’s code which contains an indirect branch that is vulnerable to exploitation. For example, if the exploit pointer value is stored in a register, the attacker’s goal is for speculation to jump to a code sequence where that register is used as a source address for a move operation.
- The exploit must successfully influence this indirect branch to speculatively mispredict and execute a gadget. This gadget, chosen by the exploit, leaks the secret data via a side channel, typically by cache-timing.
- The gadget must execute during the “speculation window,” which closes when the processor determines that the gadget execution was mispredicted.
The retpoline mitigation is applied to mitigate the vulnerable indirect branches in element 4 and has no effect on the other elements. But because the exploit depends on satisfying all five elements, removing element 4 is sufficient to stop the branch target injection exploit.
Retpoline Concept
Mitigations for speculation-based, side-channel security issues fall into two categories: directly manipulating speculation hardware, or indirectly controlling speculation behavior. Direct manipulation of the hardware is generally performed by microcode updates or manipulation of hardware registers. Indirect control is accomplished via software constructs that limit or constrain speculation. Retpoline is a hybrid approach since it requires updated microcode to make the speculation hardware behavior more predictable on some processor models. However, retpoline is primarily a software construct that leverages specific knowledge of the underlying hardware to mitigate branch target injection.
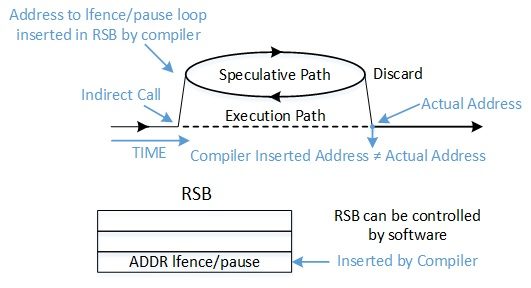
As discussed earlier, the branch target injection exploit relies on influencing the speculated targets of indirect branches. Indirect JMP and CALL instructions consult the indirect branch predictor to direct speculative execution to the most likely target of the branch. The indirect branch predictor is a relatively large hardware structure which cannot be easily managed by the operating system. Instead of attempting to manage or predict its behavior, a retpoline is a method to bypass the indirect branch predictor. Refer to Figure 1 and Figure 2 for the flow of indirect-branch prediction before and after retpoline is implemented.
Prediction of RET instructions differs from JMP and CALL instructions because RET first relies on the Return Stack Buffer (RSB). In contrast to the indirect branch predictors RSB is a last-in-first-out (LIFO) stack where CALL instructions “push” entries and RET instructions “pop” entries. This mechanism is amenable to predictable software control.
Retpoline Implementation
Deploying retpoline requires replacing vulnerable indirect branches with non-vulnerable retpoline sequences. The simplest retpoline sequence is a replacement for a single indirect JMP instruction.
| Before retpoline | jmp *%rax |
|---|---|
| After retpoline |
|
In this example, a jump is performed to an instruction address stored in the %rax register. Without retpoline, the processor’s speculative execution typically consults the indirect branch predictor and may speculate to an address controlled by an exploit (satisfying element 4 of the five elements of branch target injection exploit composition listed above).
The retpoline sequence is more complicated and works in several stages to separate the speculative execution from the non-speculative execution:
- "1:call load_label" pushes the address of “2: pause ; LFENCE” on the stack and the RSB, and then jumps to:
- "4: mov %rax, (%rsp)" takes the target of the indirect jump (in %rax) and writes it over the return address stored on the stack. At this point the in-memory stack and the RSB differ.
- If speculating, the CPU uses the RSB entry created in step 1 and jumps to "2: pause ; LFENCE". It is “trapped” in an infinite loop. The Speculation Barriers section has more details about the importance of this sequence.
- Eventually, the CPU realizes that the speculative RET does not agree with the in-memory stack value, and the speculative execution is stopped. Execution jumps to *%rax.
An indirect CALL is more complicated, but uses the same approach, as shown below:
| Before retpoline | call *%rax |
|---|---|
| After retpoline |
|
- “1: jmp label2”, jumps to “7: call label0”.
- “7: call label0” pushes the address of “8: … continue execution” on the stack and the RSB, then jumps to:
- “2: call label1” which pushes the address of “3: pause ; LFENCE” on the stack and the RSB, then jumps to:
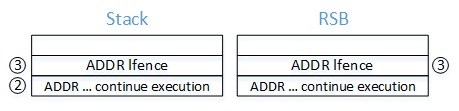
- “5. mov %rax, (%rsp)" which takes the target of the indirect call (in %rax) and writes it over the return address stored on the stack. At this point the in-memory stack and the RSB differ.
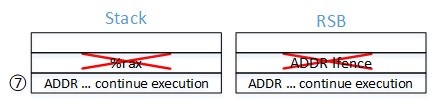
- “6. ret". If speculating, the CPU consumes the RSB entry created in step 3 and jumps to 3: pause ; LFENCE”. It is “trapped” in an infinite loop. The Speculation Barriers section has more details about the importance of this sequence.
- Eventually, the CPU realizes that the speculative RET does not agree with the in-memory stack value, and that speculative execution is stopped. Execution jumps to the target of the indirect call: *%rax, which was placed on the stack in step 4.

- The target of the indirect call returns, consuming the RSB and in-memory stack entry placed there in step 2.
Deploying Retpoline - Compilers
Since most indirect branches are generated by compilers when building a binary, deploying retpoline requires recompiling the software that needs mitigation. A retpoline-capable compiler can avoid generating any vulnerable indirect CALL or indirect JMP instructions and instead uses retpoline sequences. Of course, for code not generated by the compiler (such as inline assembly) programmers must insert retpoline sequences manually.
Deploying Retpoline – Runtime Patching
One option when deploying retpoline is to have the compiler insert a full retpoline sequence at each indirect branch that needs mitigation. However this makes the code larger than needed, so the preferred option is to have the program itself provide the retpoline sequences in one central place, and then have the compiler refer to these sequences. For example, the program might provide the sequence shown in Table 2 above at a location called retpoline_target_in_rax.
| Before retpoline | call *%rax |
|---|---|
| After retpoline | call retpoline_target_in_rax |
The program might also provide retpoline sequences for many possible call instruction possibilities, such as for making calls to targets stored in each of the general purpose registers.
This approach provides a more compact instruction sequence at each indirect call site, and also concentrates the retpoline implementations into a controlled set of locations. Programs supporting runtime patching (such as the Linux* kernel) can evaluate systems for vulnerability to branch target injection. If the system is not vulnerable (such as on systems with older processors, or with future processors implementing enhanced IBRS mitigations), the program-provided retpoline sequence can be replaced with a non-mitigated sequence.
| Mitigated Code | Runtime patch for mitigated CPU |
|---|---|
retpoline_target_in_rax:
|
retpoline_target_in_rax
|
Interaction with Control-flow Enforcement Technology (CET)
Control-flow Enforcement Technology (CET) is a future CPU technology which provides capabilities to defend against Return-Oriented-Programming (ROP) control-flow subversion attacks. However, the retpoline technique closely resembles the approaches used in ROP attacks. If used in conjunction with CET, retpoline might trigger false positives in the CET defenses.
To avoid this conflict, future Intel® processors implementing CET will also contain hardware mitigations for branch target injection (enhanced IBRS), that obviate the need for retpoline. On these processors, runtime patching can be used both to remove conflicts with CET and regain use of the indirect branch predictor for hardened indirect branch speculation.
Speculation Barriers
Although the retpoline sequence includes slow instructions like LFENCE, PAUSE, and INT3, these instructions only execute in speculative code that never retires, and thus they do not have significant performance impact.
The architectural specification for LFENCE defines that it does not execute until all prior instructions have completed, and no later instructions begin execution until LFENCE completes. This specification limits the speculative execution that a processor implementation can perform around the LFENCE, possibly impacting processor performance, but also creating a tool with which to mitigate speculative-execution side channel attacks.
However, this architecturally-defined speculation control behavior is only required when the processor actually executes (retires) the LFENCE. A speculatively-executed LFENCE that never actually executes (retires) may have a much smaller performance impact because the speculative behavior is not architecturally defined. The LFENCE (and other instructions impacting speculation that are part of the retpoline concept), is only speculatively executed and thus may not exhibit the same performance impact typically associated with speculation barriers. This allows retpoline to impact speculative execution without the overhead traditionally associated with instructions that directly impact speculation.
The same property also applies to PAUSE and INT3. Unlike INT3 and LFENCE, PAUSE is not architecturally guaranteed to delay later instructions until all older instructions have completed.
Retpoline Preconditions
Processor Models
Retpoline is known to be an effective branch target injection mitigation on Intel processors belonging to family 6 (enumerated by the CPUID instruction) that do not have support for enhanced IBRS. On processors that support enhanced IBRS, it should be used for mitigation instead of retpoline. Specifically, retpoline may not be a fully effective branch target injection mitigation on processors based on Intel Atom® microarchitectures code named Goldmont Plus and Tremont. Retpoline remains effective on other Intel processors with enhanced IBRS support.
Some processors with enhanced IBRS have restricted RSBA (RRSBA) behavior. Updated guidance for this behavior is provided in the Return Stack Buffer Underflow (RSBU) documentation.
Empty RSB Mitigation on Skylake-generation
As described in the Retpoline Concept section, the RSB is a fixed-size stack implemented in hardware. As with any stack, it can underflow in certain conditions causing undesirable behavior. “RSB stuffing” is a technique to reduce the likelihood of an underflow from occurring.
The predictable speculative behavior of the RET instruction is the key to retpoline being a robust mitigation. RET has this behavior on all processors which are based on the Intel® microarchitecture codename Broadwell and earlier when updated with the latest microcode. Processors based on the Intel microarchitecture codename Skylake and its close derivatives have different RSB behavior than other processors when the RSB is empty. Processors with the latest microcode that have this RSB behavior will either enumerate IA32_ARCH_CAPABILITIES[RSBA] or have a DisplayFamily/DisplayModel signature (provided by the CPUID instruction) listed in the following table.
Note that Table 5: Processors with Different Empty RSB Behavior below contains the same information as the Return Stack Buffer Underflow (RSBU) RSB Alternate (RSBA) column in the 2022 tab of the consolidated affected processors table.
| Processor | Stepping | CPUID | Code Names / Microarchitectures |
|---|---|---|---|
| 06_4EH | 3 | 406E3 | Skylake Y Skylake U Skylake U23e |
| 06_5EH | 3 | 506E3 | Skylake Xeon E3 Skylake H Skylake S |
| 06_55H | 3,4 | 50653 50654 |
Skylake Server Skylake D, Bakerville Skylake W Skylake X |
| 06_66H | 3 | 60663 | Cannon Lake L |
| 06_8EH | 9,A,B | 806E9 806EA 806EB |
Amber Lake Y Kaby Lake U Kaby Lake Y Kaby Lake U23e Coffee Lake U43e Kaby Lake Refresh U Whiskey Lake U |
| 06_9EH | 9,A,B,C | 906E9 906EA 906EB 906EC |
Kaby Lake S Kaby Lake H Kaby Lake G Kaby Lake X Kaby Lake Xeon E3 Coffee Lake H Coffee Lake S Xeon E Coffee Lake S Coffee Lake S w/KBP Coffee Lake Xeon E |
Applications may need OS help discover the RSBA value since RDMSR is a privileged instruction.
Any future processors that are not in the above table which exhibit this empty RSB behavior will enumerate RSBA in the IA32_ARCH_CAPABILITIES MSR. Any such part is expected to also support IBRS_ALL.
When the RSB “stack” is empty on these processors, a RET instruction may speculate based on the contents of the indirect branch predictor, the structure that retpoline is designed to avoid. The RSB may become empty under the following conditions:
- Call stacks deeper than the minimum RSB depth (16) may empty the RSB when executing RET instructions. This includes CALL instructions and RET instructions within aborting TSX transactions.
- IBPB command may empty the RSB.
- Certain instructions may empty the RSB5:
- WRMSR to 0x79 (microcode update) , 0x7A (SGX activation).
- WRMSR/RDMSR to/from 0x8C-0x8F (SGX Launch Enclave Public Key Hash).
- Intel® Software Guard Extensions (Intel® SGX) instructions (ENCLS, ENCLU) and Intel SGX CPUID leaf.
- Imbalance between CALL instructions and RET instructions that leads to more RET instructions than CALL instructions. For example:
- OS context switch
- C++ exception
- longjmp
- Entering sleep state of C6 or deeper (for example, MWAIT) may empty the RSB.
The depth of the call stack may depend on many factors that are not known until runtime which makes the call stack difficult to mitigate in software. However, exploiting a deep call stack is expected to require much more comprehensive control and prediction of the behavior of the CPU and program state than a traditional branch target injection attack. Intel considers the risk of an attack based on exploiting deep call stacks low.
There are also a number of events that happen asynchronously from normal program execution that can result in an empty RSB. Software may use “RSB stuffing” sequences whenever these asynchronous events occur:
- Interrupts/NMIs/traps/aborts/exceptions which increase call depth.
- System Management Interrupts (SMI) (see BIOS/Firmware Interactions).
- Host VMEXIT/VMRESUME/VMENTER.
- Microcode update load (WRMSR 0x79) on another logical processor of the same core.
Software may avoid RSB underflow by inserting an “RSB stuffing” sequence following all of the above conditions.
These RSB stuffing sequences, with an example of one instance shown below, can be removed using runtime patching techniques in the same way as the retpoline sequences on processors that do not require this mitigation.
void rsb_stuff(void)
{
asm(".rept 16\n"
"call 1f\n"
"pause ; LFENCE\n"
"1: \n"
".endr\n"
"addq $(8 * 16), %rsp\n");
}
Reduced-Width RSB Mitigation
Processors based on the the Intel microarchitectures codename Silvermont and Airmont have a unique RSB implementation. On these processors, the RSB only stores bits 31:0 of the address. Bits 47:32 of the predicted RET target in 64-bit mode will match bits 47:32 of the address of the instruction sequentially after the RET.
This “reduced-width RSB” behavior creates a condition where a RET instruction can speculate to an “alias” instruction that matches bits 47:32 of the intended target.
Because of the aliasing properties, a predicted RET target on a processor with a reduced-width RSB may be different than a predicted RET on a processor with a full-width RSB, even when both processors execute the same instruction sequence. Despite this, all other branch target injection mitigations, such as retpoline and enabling Supervisor Mode Execution Protection (SMEP), remain effective and should continue to be deployed.
However, on processors with a reduced-width RSB, you should deploy some additional mitigations to reduce your system's exposure to branch target injection exploits.
RSB entries can be created by CALL instructions executed by a malicious actor. If a privileged RET instruction consumes one of these RSB entries, the RET can speculate to an attacker-controlled location up to 2 GB away from the RET instruction. Speculative execution of attacker-controlled, user-permission instructions could occur if those instructions are mapped in this location. SMEP mitigates this scenario by preventing speculative execution of user-permission instructions.
If the attacker-controlled location instead contains trusted instructions, an attacker might still be able to construct a side channel gadget even out of those trusted instruction sequences. This behavior can be mitigated by ensuring that privileged RET instructions do not consume RSB entries placed by malicious actors. These RSB stuffing sequences should be placed whenever there can be an imbalance between CALL instructions and RET instructions, as discussed in the Empty RSB Mitigation on Skylake-generation section. For full-width RSB processors, RSB-based speculation is always “perfect,” speculating to the exact address stored in the RSB.
RSB entries can also be created by trusted CALL instructions. However, the aliasing property of a reduced-width RSB means that a RET might speculate to a different location from the return address. A malicious actor could influence the sequence of CALL and RET instructions to exploit this aliasing and influence speculation to occur to an attacker-controlled address. Mapping all trusted code such that it shares bits 47:32 of the instruction linear address removes the possibility of aliasing, mitigating this attack.
Processors with this RSB behavior can be identified using the following DisplayFamily/DisplayModel signatures provided by the CPUID instruction6:
| Processor | Stepping | Code Name / Microarchitectures |
|---|---|---|
| 06_37H | 3,8,9 | Valley View |
| 06_4AH | All | Tangier (Silvermont) |
| 06_4CH | All | Cherryview (Airmont) |
| 06_4DH | 8 | Avoton (Silvermont) Rangeley (Silvermont) |
| 06_5AH | All | Anniedale (Airmont) |
| 06_5DH | All | SoFIA 3G (Silvermont) |
| 06_65H | All | XMM7272 (Airmont) |
| 06_6EH | All | Couger Mountain (Airmont) |
Virtual Machine CPU Identification
A valuable tool in modern data centers is live migration of virtual machines (VMs) among a cluster of bare-metal hosts. However, those bare-metal hosts often differ in hardware capabilities. These differences could prevent a virtual machine that started on one host from being migrated to another host that has different capabilities. For instance, a virtual machine using Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions could not be live-migrated to an older system without Intel AVX-512.
A common approach to solving this issue is exposing the oldest processor model with the smallest subset of hardware features to the VM. This addresses the live-migration issue, but results in a new issue: Software using model/family numbers from CPUID can no longer detect when it is running on a newer processor that is vulnerable to exploits of Empty RSB conditions.
To remedy this situation, an operating system running as a VM can query bit 2 of the IA32_ARCH_CAPABILITIES MSR, known as “RSB Alternate” (RSBA). When RSBA is set, it indicates that the VM may run on a processor vulnerable to exploits of Empty RSB conditions regardless of the processor’s DisplayFamily/DisplayModel signature, and that the operating system should deploy appropriate mitigations. Virtual machine managers (VMM) may set RSBA via MSR interception to indicate that a virtual machine might run at some time in the future on a vulnerable processor.
Recompilation
Mitigation with retpoline requires that all code in a program (or OS kernel) is compiled with a retpoline-enabled compiler in order to make sure vulnerable indirect branches are replaced with the retpoline sequence. In practice, this means that retpoline can only be applied in environments where recompilation and redeployment of updated binaries is possible. This includes instances where full source code is available, or where instructions are generated by a JIT compiler.
However, retpoline is not a practical mitigation for environments where full recompilation itself is not practical. Other mitigations may be appropriate in those environments.
BIOS/Firmware Interactions
System Management Interrupt (SMI) handlers can leave the RSB in a state that OS code does not expect. In order to avoid RSB underflow on return from SMI, an SMI handler may implement RSB stuffing (for parts identified in Table 5) before returning from System Management Mode (SMM). Updated SMI handlers are provided via system BIOS updates.
Summary
There are a number of possible mitigation techniques for the branch target injection exploit. The retpoline mitigation technique presented in this document is resistant to exploitation and has attractive performance properties compared to other mitigations.
Linux* Implementation Details
Enabling and Enumerating Retpoline Support
The Linux kernel implements retpoline to protect the kernel from exploits. The CONFIG_RETPOLINE build option is used to enable support. You can check for support on many distributions by running the following command:
grep CONFIG_RETPOLINE /boot/config-`uname -r`
This build option indicates whether retpoline support was requested in the build. However, even with this option set, you can successfully build the kernel even if the compiler does not support retpoline. In this case, the kernel will only contain minimal mitigations with retpoline in assembly code. These kernels will indicate that they are still “Vulnerable” to branch target injection, as shown below:
# cat /sys/devices/system/cpu/vulnerabilities/spectre_v2
Vulnerable: Minimal generic ASM retpoline
Kernels which were built with a compiler that does support retpoline will indicate that they are mitigated and are no longer vulnerable:
# cat /sys/devices/system/cpu/vulnerabilities/spectre_v2
Mitigation: Full generic retpoline
Footnotes
- A full list vulnerable indirect branch instructions is listed in Table 2.1 of Speculative Execution Side Channels.
- An example overt channel is the system call interface between an OS kernel and an application.
- Runtime patching in this manner requires an out-of-line retpoline sequence which differs from the sequence in Table 2.
- Some newer processors that match the DisplayFamily/DisplayModel signatures in Table 6 enumerate the IBRS_ALL capability in the IA32_ARCH_CAPABILITIES MSR. Unlike other processors matching the Family/Model listed in Table 6, these processors with enhanced IBRS do not exhibit the empty RSB behavior described in this section. In other words, if a processor is in this table but enumerates IBRS_ALL and not RSBA, then it does not exhibit the empty RSB behavior.
- These conditions may apply to speculative execution in addition to the retired execution path.
- Additional processors may exhibit vulnerable RSB behavior that are not listed in this table.
Software Security Guidance Home | Advisory Guidance | Technical Documentation | Best Practices | Resources