This technical documentation expands on the information in the Microarchitectural Data Sampling (MDS) guidance. Be sure to review the disclosure overview for software developers first and apply any microcode updates from your OS vendor.
How Microarchitectural Data Sampling (MDS) Works
MDS may allow a malicious user who can locally execute code on a system to infer the values of secret data otherwise protected by architectural mechanisms. Although it may be difficult to target particular data on a system using these methods, malicious actors may be able to infer secrets by collecting and analyzing large amounts of data. Refer to the MDS table in CPUID Enumeration and Architectural MSRs for a list of processors that may be affected by MDS. MDS only refers to methods that involve microarchitectural structures other than the level 1 data cache (L1D) and thus does not include Rogue Data Cache Load (RDCL) or L1 Terminal Fault (L1TF).
The MDS speculative execution side channel methods can be used to expose data in the following microarchitectural structures:
- Store buffers: Temporary buffers to hold store addresses and data.
- Fill buffers: Temporary buffers between CPU caches.
- Load ports: Temporary buffers used when loading data into registers.
These structures are much smaller than the L1D, and therefore hold less data and are overwritten more frequently. It is also more difficult to use MDS methods to infer data that is associated with a specific memory address, which may require the malicious actor to collect significant amounts of data and analyze it to locate any secret data.
New microcode updates (MCUs) are being released to help software mitigate these issues. Intel recommends updating the microcode and clearing microarchitectural buffers when switching to software that is not trusted by the previous software. These mitigations will require changes and updates to operating systems, hypervisors, and Intel® Software Guard Extensions (Intel® SGX).
The microarchitecture details in this document are applicable to the processors affected by MDS techniques and should not be considered universal for all Intel processors. Refer to CPUID Enumeration and Architectural MSRs for a list of affected processors.
Microarchitectural Store Buffer Data Sampling (MSBDS) CVE-2018-12126
When performing store operations, processors write data into a temporary microarchitectural structure called the store buffer. This enables the processor to continue to execute instructions following the store operation, before the data is written to cache or main memory. I/O writes (for example, OUT) are also held in the store buffer.
When a load operation reads data from the same memory address as an earlier store operation, the processor may be able to forward data to the load operation directly from the store buffer instead of waiting to load the data from memory or cache. This optimization is called store-to-load forwarding.
Under certain conditions, data from a store operation can be speculatively forwarded from the store buffer to a faulting or assisting load operation for a different memory address. It is possible that a store does not overwrite the entire data field within the store buffer due to either the store being a smaller size than the store buffer width, or not yet having executed the data portion of the store. These cases can lead to data being forwarded that contains data from older stores. Because the load operation will cause a fault/assist1 and its results will be discarded, the forwarded data does not result in incorrect program execution or architectural state changes. However, malicious actors may be able to forward this speculative-only data to a disclosure gadget in a way that allows them to infer this value.
Cross-Thread Impacts of MSBDS
For processors affected by MSBDS, the store data buffer on a physical core is statically partitioned across the active threads on that core. This means a core with two active threads would have half of the store buffer entries used only for thread one and half only for the other. When a thread enters a sleep state, its store buffer entries may become usable by the other active thread. This causes store buffer entries that were previously used for the thread that is entering the sleep state (and may contain stale data) to be reused by the other (active) thread. When a thread wakes from a sleep state, the store buffer is repartitioned again. This causes the store buffer to transfer store buffer entries from the thread that was already active to the one which just woke up. Note that threads do not enter sleep states or repartition store buffers speculatively.
Microarchitectural Fill Buffer Data Sampling (MFBDS) CVE-2018-12130
A fill buffer is an internal structure used to gather data on a first level data cache miss. When a memory request misses the L1 data cache, the processor allocates a fill buffer to manage the request for the data cache line. The fill buffer also temporarily manages data that is returned or sent in response to a memory, I/O, or special register operation. Special register operations are described in the Special Register Buffer Data Sampling. Fill buffers may also be used when stores hit in the L1 data cache. Fill buffers can forward data to load operations and also write data to the data cache. Once the data from the fill buffer is written to the cache (or otherwise consumed when the data will not be cached), the processor deallocates the fill buffer, allowing that entry to be reused for future memory operations.
Fill buffers may retain stale data from prior memory requests until a new memory request overwrites the fill buffer. Under certain conditions, the fill buffer may speculatively forward data, including stale data, to a load operation that will cause a fault/assist. This does not result in incorrect program execution because faulting/assisting loads never retire and therefore do not modify the architectural state. However, a disclosure gadget may be able to infer the data in the forwarded fill buffer entry through a side channel timing analysis.
Cross-Thread Impacts of MFBDS
Fill buffers are shared between threads on the same physical core without any partitioning. Because fill buffers are dynamically allocated between sibling threads, the stale data in a fill buffer may belong to a memory access made by the other thread. For example, in a scenario where different applications are being executed on sibling threads, if one of those applications is under the control of a malicious actor, it may be possible under a specific set of conditions to use MFBDS to infer some of the victim's data values through the fill buffers.
Microarchitectural Load Port Data Sampling (MLPDS) CVE-2018-12127
Processors use microarchitectural structures called load ports to perform load operations from memory or I/O. During a load operation, the load port receives data from the memory or I/O system, and then provides that data to the register file and younger dependent operations. In some implementations, the writeback data bus within each load port can retain data values from older load operations until younger load operations overwrite that data.
Microarchitectural Load Port Data Sampling (MLPDS) can reveal stale load port data to malicious actors in these cases:
- A faulting/assisting vector (SSE/Intel® AVX/Intel® AVX-512) load that is more than 64 bits in size
- A faulting/assisting load which spans a 64-byte boundary
In these cases, faulting/assisting load operations speculatively provide stale data values from the internal data structures to younger dependent operations. Because the faulting/assisting load operations never retire, speculatively forwarding this data does not result in incorrect program execution. However, the younger dependent operations that receive the stale data may be part of a disclosure gadget that can reveal the stale data values to a malicious actor.
Cross-Thread Impacts of MLPDS
Load ports are shared between threads on the same physical core. Because load ports are dynamically allocated between threads, the stale data in a load port may belong to a memory access made by the other thread. For example, in a scenario where different applications are being executed on sibling threads, if one of those applications is under the control of a malicious actor, it may be possible under a specific set of conditions to use MLPDS to infer some of the victim's data values through the load ports.
Microarchitectural Data Sampling Uncacheable Memory (MDSUM) CVE-2019-11091
Core or data accesses that use the uncacheable (UC) memory type do not fill new lines into the processor caches. On processors affected by Microarchitectural Data Sampling Uncachable Memory (MDSUM), load operations that fault or assist to uncacheable memory may still speculatively see the data value from those core or data accesses. Because uncacheable memory accesses still move data through store buffers, fill buffers, and load ports, and those data values may be speculatively returned on faulting or assisting loads, malicious actors can observe these data values through the MSBDS, MFBDS, and MLPDS mechanisms discussed above.
Mitigations for Microarchitectural Data Sampling Issues
Hardware Mitigations
Future and some current processors will have microarchitectural data sampling methods mitigated in the hardware. Most processor mitigations will forward a value of 0 to the speculative dependent operations of a load that encounters an assist during load execution or a fault. Other processors (Intel Atom and future Intel Core) will prevent execution of speculative dependent operations of a load that encounters an assist during load execution or a fault. For a complete list of affected processors, refer to the MDS table in CPUID Enumeration and Architectural MSRs.
The following MSR enumeration enables software to check if the processor is affected by MDS methods:
A value of 1 indicates that the processor is not affected by RDCL or L1TF. In addition, a value of 1 indicates that the processor is not affected by MFBDS.
- IA32_ARCH_CAPABILITIES[0]: RDCL_NO
- IA32_ARCH_CAPABILITIES[5]: MDS_NO
A value of 1 indicates that processor is not affected by MFBDS/MSBDS/MLPDS/MDSUM.
Note that MFBDS is mitigated if either the RDCL_NO or MDS_NO bit (or both) are set. Some existing processors may also enumerate either RDCL_NO or MDS_NO only after a microcode update is loaded.
Mitigations for Affected Processors
The mitigation for microarchitectural data sampling issues includes clearing store buffers, fill buffers, and load ports before transitioning to possibly less privileged execution entities (for example, before the operating system (OS) executes an IRET or SYSRET instructions to return to an application).
There are two methods to overwrite the microarchitectural buffers affected by MDS: MD_CLEAR functionality and software sequences.
Processor Support for Buffer Overwriting (MD_CLEAR)
Intel will release microcode updates and new processors that enumerate MD_CLEAR functionality2. On processors that enumerate MD_CLEAR3, the VERW instruction or L1D_FLUSH command4 should be used to cause the processor to overwrite buffer values that are affected by MDS, as these instructions are preferred to the software sequences.
The VERW instruction and L1D_FLUSH command4 will overwrite the store buffer value for the current logical processor on processors affected by MSBDS. For processors affected by MFBDS, these instructions will overwrite the fill buffer for all logical processors on the physical core. For processors affected by MLPDS, these instructions will overwrite the load port writeback buses for all logical processors on the physical core. Processors affected by MDSUM are also affected by one or more of MFBDS, MSBDS, or MLPDS, so overwriting the buffers as described above will also overwrite any buffer entries holding uncacheable data.
VERW Buffer Overwriting Details
The VERW instruction is already defined to return whether a segment is writable from the current privilege level. MD_CLEAR enumerates that the memory-operand variant of VERW (for example, VERW m16) has been extended to also overwrite buffers affected by MDS.
This buffer overwriting functionality is not guaranteed for the register operand variant of VERW. The buffer overwriting occurs regardless of the result of the VERW permission check, as well as when the selector is null or causes a descriptor load segment violation. However, for lowest latency we recommend using a selector that indicates a valid writable data segment.
Example usage5:
MDS_buff_overwrite():
sub $8, %rsp
mov %ds, (%rsp)
verw (%rsp)
add $8, %rsp
ret
Note that the VERW instruction updates the ZF bit in the EFLAGS register, so exercise caution when using the above sequence in-line in existing code. Also note that the VERW instruction is not executable in real mode or virtual-8086 mode.
The microcode additions to VERW will correctly overwrite all relevant microarchitectural buffers for a logical processor regardless of what is executing on the other logical processor on the same physical core.
VERW Fall-Through Speculation
Some processors that enumerate MD_CLEAR support may speculatively execute instructions immediately following VERW. This speculative execution may happen before the speculative instruction pipeline is cleared by the VERW buffer overwrite functionality.
Because of this possibility, a speculation barrier should be placed between invocations of VERW and the execution of code that must not observe secret data through MDS.
To illustrate this possibility, consider the following instruction sequence:
- Code region A
- VERW m16
- Code region B
- Speculation barrier (for example, LFENCE)
- Code region C
Suppose that secret data may be accessed by instructions in code region A. The VERW instruction overwrites any data that instructions in code region A place in MDS-affected buffers. However, instructions in code region B may speculatively execute before the buffer overwrite occurs. Because loads in code region C execute after the speculation barrier, they will not observe secret data placed in the buffers by code region A.
When used with VERW, the following are examples of suitable speculation barriers for VERW on affected processors:
- LFENCE
- Any change of current privilege level (such as SYSRET returning from supervisor to user mode)
- VM enter or VM exit
- MWAIT that successfully enters a sleep state
- WRPKRU instruction
- Architecturally serializing instructions or events
For example, if the OS uses VERW prior to transition from ring 0 to ring 3, the ring transition itself is a suitable speculation barrier. If VERW is used between security subdomains within a process, a suitable speculation barrier might be a VERW; LFENCE sequence.
Software Sequences for Buffer Overwrite
On processors that do not enumerate the MD_CLEAR functionality2, certain instruction sequences may be used to overwrite buffers affected by MDS. These sequences are described in detail in the Software Sequences to Overwrite Buffers Section.
Different processors may require different sequences to overwrite the buffers affected by MDS. Some requirements for the software sequences are listed below:
- On processors that support simultaneous multithreading6 (SMT), other threads on the same physical core should be quiesced during the sequence so that they do not allocate fill buffers. This allows the current thread to overwrite all of the fill buffers. In particular, these quiesced threads should not perform any loads or stores that might miss the L1D cache. A quiesced thread should loop on the PAUSE instruction to limit cross-thread interference during the sequence.
- For sequences that rely on REP string instructions, the MSR bit IA32_MISC_ENABLES[0] must be set to 1 so that fast strings are enabled.
Implicit Data Access while Running in a Less-Privileged Mode
Clearing out the affected data buffers during privilege transitions will clear any secret data put into those buffers by the more-privileged code. There may be certain specific operating system or VMM structures that, though privileged, are accessed implicitly during less-privileged modes of operation (for example: page tables, GDT, LDT, and VMCS contents). As with other side channel methods (for example, Rogue Data Cache Load or L1TF), this makes data in those structures potentially vulnerable to MDS side channel analysis. Although the data in these structures is generally of low value to a malicious attacker, that data should nevertheless not be assumed to be secret from local processes on affected systems.
When to Overwrite Buffers
Store buffers, fill buffers, and load ports should be overwritten whenever switching to software that is not trusted by the previous software. If software ensures that no secret data exists in any of these buffers then the buffer overwrite can be avoided.
OS
The OS can execute the VERW instruction2 to overwrite any secret data in affected buffers when transitioning from ring 0 to ring 3. This will overwrite secret data in the buffers that could belong to the kernel or other applications. When SMT is active, this instruction should also be executed before entering C-states, as well as between exiting C-states and transitioning to untrusted code.
Intel® Software Guard Extensions (Intel® SGX)
When entering or exiting Intel® Software Guard Extensions (Intel® SGX) enclaves, processors that enumerate support for MD_CLEAR will automatically overwrite affected data buffers.
Virtual Machine Managers (VMMs)
The VMM can execute either the VERW instruction or the L1D_FLUSH command4 before entering a guest VM. This will overwrite secret data in the buffers that could belong to the VMM or other VMs. VMMs that already use the L1D_FLUSH command before entering guest VMs to mitigate L1TF may not need further changes beyond loading a microcode update that enumerates MD_CLEAR.
While a VMM may issue L1D_FLUSH on only one thread to flush the data in the L1D, fill buffers, and load ports for all threads in the core, only the store buffers for the current thread are cleared. When the other thread next enters a guest, a VERW may be needed to overwrite the store buffers belonging to the other thread.
System Management Mode (SMM)
Exposure of system management mode (SMM) data to software that subsequently runs on the same logical processor can be mitigated by overwriting buffers when exiting SMM. On processors that enumerate MD_CLEAR2, the processor will automatically overwrite the affected buffers when the RSM instruction is executed.
Security Domains within a Process
Software using language based security may transition between different trust domains. When transitioning between trust domains, a VERW instruction can be used to clear buffers.
Site isolation, as discussed in Managed Runtime Speculative Execution Side Channel Mitigations, may be a more effective technique for dealing with speculative execution side channels in general.
Mitigations for Environments Utilizing Simultaneous Multithreading (SMT)
OS
The OS must employ two different methods to prevent a thread from using MDS to infer data values used by the sibling thread. The first (group scheduling) protects against user vs. user attacks. The second (synchronized entry) protects kernel data from attack when one thread executes kernel code by an attacker running in user mode on the other
Group Scheduling
The OS can prevent a sibling thread from running malicious code when the current thread crosses security domains. The OS scheduler can reduce the need to control sibling threads by ensuring that software workloads sharing the same physical core mutually trust each other (for example, if they are in the same application defined security domain) or ensuring the other thread is idle.
The OS can enforce such a trusted relationship between workloads either statically (for example, through task affinity or cpusets), or dynamically through a group scheduler in the OS (sometimes called a core scheduler). The group scheduler should prefer processes with the same trust domain on the sibling core, but only if no other idle core is available. This may affect load balancing decisions between cores. If a process from a compatible trust domain is not available, the scheduler may need to idle the sibling thread.
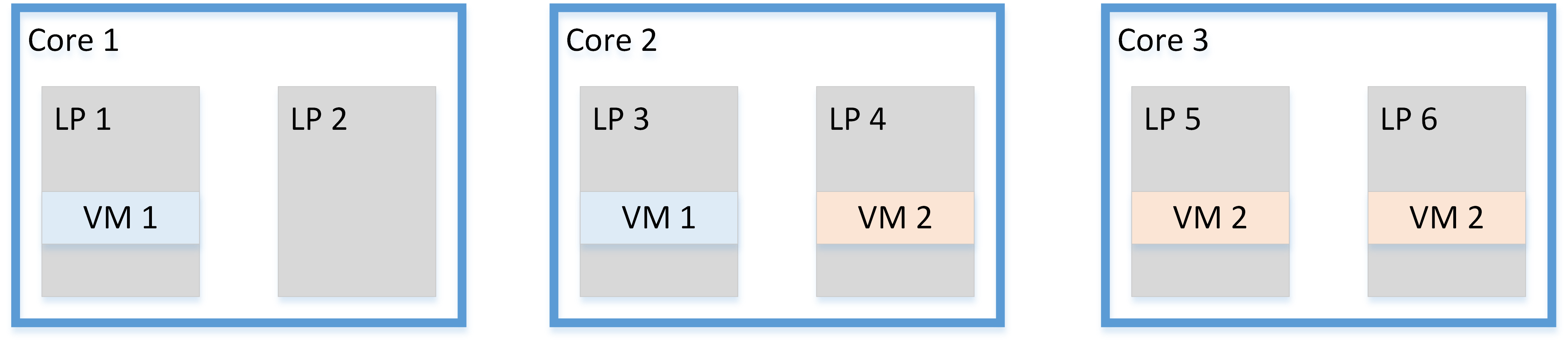
Figure 1. System without group scheduling

Figure 2. System with group scheduling
Figure 1 shows a three-core system where Core 2 is running processes from different security domains. These processes would be able to use MDS to infer secrets from each other. Figure 2 shows how a group scheduler removes the possibility of process-to-process attacks by ensuring that no core runs processes from different security domains at the same time.
Synchronized ring 0 entry and exit using IPIs
The OS needs to take action when the current hardware thread makes transitions from user code (application code) to the kernel code (ring 0 mode). This can happen as part of syscall or asynchronous events such as interrupts, and thus the sibling thread may not be allowed to execute in user mode because kernel code may not trust user code. In a simplified view of an operating system we can consider each thread to be in one of three states:
- Idle
- Ring 0 (kernel code)
- User (application code)
Figure 3 below shows the state transitions to keep the kernel safe from a malicious application.
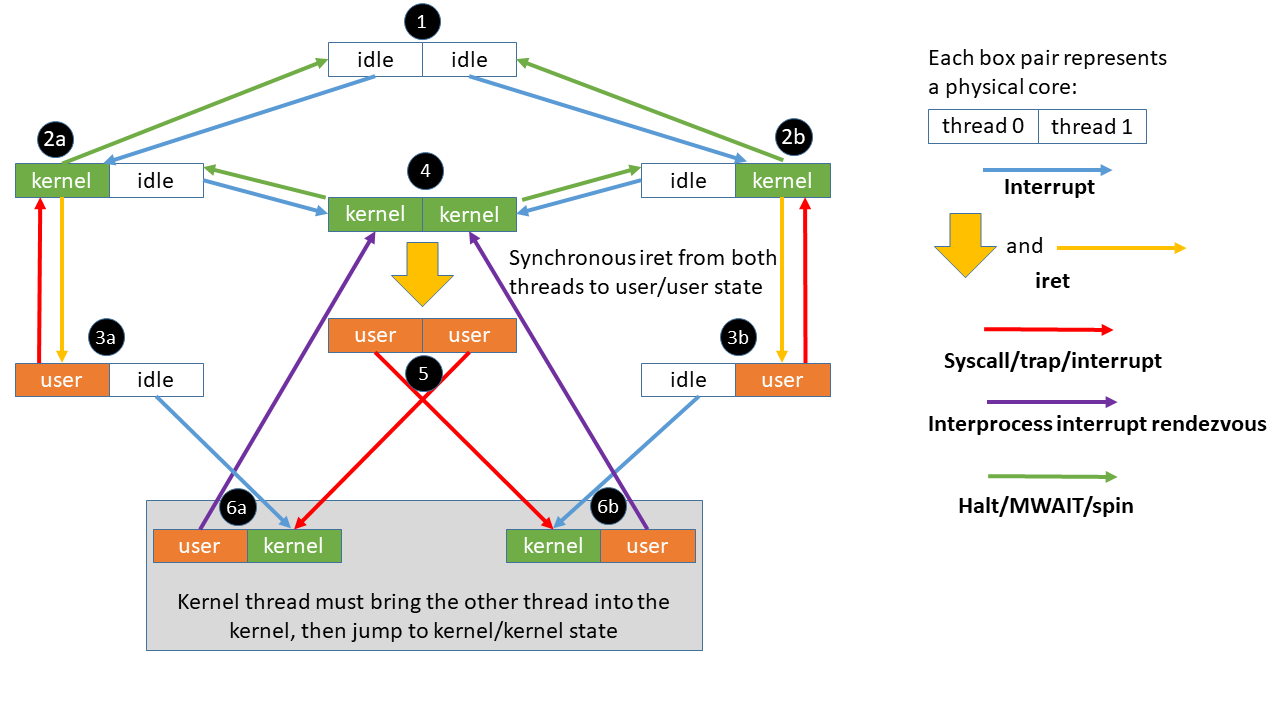
Figure 3. Thread rendezvous
Each node in the figure above shows the possible execution states of the two threads that share a physical core.
Starting at state 1, both threads are idle. From this state, an interrupt will transition the core to state 2a or 2b depending on which thread is interrupted. If there are no user tasks to run, the physical core transitions back to state 1 upon completion of the interrupt. If the idle state is implemented using processor C-states, then VERW should be executed before entry to C-states on processors affected by MSBDS.
From 2a or 2b, a thread may begin running a user process. As long as the other thread on the core remains idle, SMT-specific mitigations are not needed when transitioning from 2a to 3a or 2b to 3b, although the OS needs to overwrite buffers by executing VERW before transitioning to 3a or 3b.
Alternatively, from 2a or 2b the physical core may transition to state 4 if an interrupt wakes the sibling thread. The physical core may possibly return back to 2a or 2b if that interrupt does not result in the core running a user process.
From state 4, the core can transition to state 5 and begin executing user code on both threads. The OS must ensure that the transition to state 5 prevents the thread that first enters user code from performing an attack on secrets in microarchitectural buffers of the other thread. The OS should also execute VERW on both threads. There is no hardware support for atomic transition of both threads between kernel and user states, so the OS should use standard software techniques to synchronize the threads. The OS should also take care at the boundary points to avoid loading secrets into microarchitectural buffers when one or both threads are transitioning to user mode. Note that the kernel should only enter state 5 when running two user threads from the same security domain (as described in the group scheduling section above).
The core may enter either state 6a or 6b from state 5 because one of the threads leaves user mode or from state 3a or 3b because an interrupt woke a thread from idle state. When in state 6a or 6b, the OS should avoid accessing any data that is considered secret with respect to the sibling thread in user mode. If the thread in kernel state needs to access secret data, the OS should transition from state 6a or 6b to state 4. The thread in kernel state should use an interprocessor interrupt (IPI) to rendezvous the two threads in kernel state in order to transition the core to state 4. When the kernel thread is ready to leave the kernel state (either by going into the idle state or returning to the user state), the sibling thread can be allowed to exit the IPI service routine and return to running in user state itself after executing a VERW.
Disable Simultaneous Multithreading (SMT)
Another method to prevent the sibling thread from inferring data values through MDS is to disable SMT either through the BIOS or by having the OS only schedule work on one of the threads.
SMT Mitigations for Atom and Knight Family Processors
Some processors that are affected by MDS (MDS_NO is 0) do not need mitigation for the other sibling thread. Specifically, any processor that does not support SMT (for example, processors based on the Silvermont and Airmont microarchitectures) does not need SMT mitigation.
Processors based on the Knights Landing or Knights Mill microarchitectures do not need group scheduling or synchronized exit/entry to mitigate against MDS attacks from the sibling threads. This is because these processors are only affected by MSBDS, and the store data buffers are only shared between threads when entering/exiting C-states. On such processors, the store buffers should be overwritten when entering, as well as between exiting C-states and transitioning to untrusted code. The only processors with four threads per core that are affected by MDS (do not enumerate MDS_NO) are Knights family processors.
Virtual Machine Manager (VMM)
Mitigations for MDS parallel those needed to mitigate L1TF. Processors that enumerate MDS_CLEAR have enhanced the L1D_FLUSH command4 to also overwrite the microarchitectural structures affected by MDS. This can allow VMMs that have mitigated L1TF through group scheduling and through using the L1D_FLUSH command to also mitigate MDS. The VMM mitigation may need to be applied to processors that are not affected by L1TF (RDCL_NO is set) but are affected by MDS (MDS_NO is clear). VMMs on such processors can use VERW instead of the L1D_FLUSH command. VMMs that have implemented the L1D flush using a software sequence should use a VERW instruction to overwrite microarchitectural structures affected by MDS.
Note that even if the VMM issues L1D_FLUSH on only one thread to flush the data for all threads in the core, the store buffers are just cleared for the current thread. When the other thread next enters a guest a VERW may be needed to overwrite the store buffers belonging to that thread.
Intel® SGX
The Intel SGX security model does not trust the OS scheduler to ensure that software workloads running on sibling threads mutually trust each other. The Intel SGX remote attestation reflects whether Intel® Hyper-Threading Technology (Intel® HT Technology) is enabled by the BIOS. An Intel SGX remote attestation verifier can evaluate the risk of potential cross-thread attacks when Intel® HT Technology is enabled on the platform and decide whether to trust an enclave on the platform to protect specific secret information.
SMM
SMM is a special processor mode used by BIOS. Processors that enumerate MD_CLEAR and are affected by MDS will automatically flush the affected microarchitectural structures during the RSM instruction that exits SMM.
SMM software must rendezvous all logical processors both on entry to and exit from SMM to ensure that a sibling logical processor does not reload data into microarchitectural structures after the automatic flush. We believe most SMM software already does this. This ensures that non-SMM software does not run while data that belong to SMM are in microarchitectural structures. Such SMM implementations do not require any software changes to be fully mitigated for MDS. Implementations that allow a logical processor to execute in SMM while another logical processor on the same physical core is not in SMM need to be reviewed to see if any secret data from SMM could be loaded into microarchitectural structures, and thus would be vulnerable to MDS from another logical processor.
CPUID Enumeration
For a full list of affected processors, refer to the MDS table in CPUID Enumeration and Architectural MSRs.
CPUID.(EAX=7H,ECX=0):EDX[MD_CLEAR=10] enumerates support for additional functionality that will flush microarchitectural structures as listed below.
- On execution of the (existing) VERW instruction where its argument is a memory operand.
- On setting the L1D_FLUSH command4 bit in the IA32_FLUSH_CMD MSR.
- On execution of the RSM instruction.
- On entry to, or exit from an Intel SGX enclave.
Note Future processors set the MDS_NO bit in IA32_ARCH_CAPABILITIES to indicate they are not affected by microarchitectural data sampling. Such processors will continue to enumerate the MD_CLEAR bit in CPUID. As none of these data buffers are vulnerable to exposure on such parts, no data buffer overwriting is required or expected for such parts, despite the MD_CLEAR indication. Software should look to the MDS_NO bit to determine whether buffer overwriting mitigations are required.
Note For Intel SGX, the MD_CLEAR and MDS_NO bits are also indirectly reflected in the Intel SGX Remote Attestation data.
Note All processors affected by MSBDS, MFBDS, or MLPDS are also affected by MDSUM for the relevant buffers. For example, a processor that is only affected by MSBDS but is not affected by MFBDS or MLPDS would also be affected by MDSUM for store buffer entries only.
Software Sequences to Overwrite Buffers
On processors that do not enumerate the MD_CLEAR functionality, the following instruction sequences may be used to overwrite buffers affected by MDS. On processors that do enumerate MD_CLEAR, the VERW instruction or L1D_FLUSH command4 should be used instead of these software sequences.
The software sequences use the widest available memory operations on each processor model to ensure that all of the upper order bits are overwritten. System management interrupts (SMI), interrupts, or exceptions that occur during the middle of these sequences may cause smaller memory accesses to execute which only overwrite the lower bits of the buffers. In this case, when the sequence completes, some of the buffer entries may be overwritten twice, while only the lower bits of other buffer entries are overwritten. Extra operations could be performed to minimize the chance of interrupts/exceptions causing the upper order bits of the buffer entries to persist.
Some of these sequences use %xmm0 to overwrite the microarchitectural buffers. It is safe to assume that this value contains no secrets because we perform this sequence before returning to user mode (which can directly access %xmm0). While the overwrite operation makes the %xmm0 value visible to the sibling thread via the MDS vulnerability, we assume that group scheduling ensures that the process on the sibling thread is trusted by the process on the thread returning to user mode.
Note that in virtualized environments, VMMs may not provide guest OSes with the true information about which real physical processor model is in use. In these environments, we recommend that the guest OSes always use VERW.
Nehalem, Westmere, Sandy Bridge, and Ivy Bridge
The following sequence can overwrite the affected data buffers for processor families code named Nehalem, Westmere, Sandy Bridge, or Ivy Bridge. It requires a 672-byte writable buffer that is WB-memtype, aligned to 16 bytes, and the first 16 bytes are initialized to 0. Note this sequence will overwrite buffers with the value in XMM0. If the function is called in a context where this not acceptable (where XMM0 contains secret data), then XMM0 should be saved/restored.
static inline void IVB_clear_buf(char *zero_ptr)
{
__asm__ __volatile__ (
"lfence \n\t"
"orpd (%0), %%xmm0 \n\t"
"orpd (%0), %%xmm1 \n\t"
"mfence \n\t"
"movl $40, %%ecx \n\t"
"addq $16, %0 \n\t"
"1: movntdq %%xmm0, (%0) \n\t"
"addq $16, %0 \n\t"
"decl %%ecx \n\t"
"jnz 1b \n\t"
"mfence \n\t"
::"r" (zero_ptr):"ecx","memory");
}
Haswell and Broadwell
The following sequence can overwrite the affected data buffers for processors based on the Haswell or Broadwell microarchitectures. It requires a 1.5 KB writable buffer with WB-memtype that is aligned to 16 bytes. Note this sequence will overwrite buffers with the value in XMM0.
static inline void BDW_clear_buf(char *dst)
{
__asm__ __volatile__ (
"movq %0, %%rdi \n\t"
"movq %0, %%rsi \n\t"
"movl $40, %%ecx \n\t"
"1: movntdq %%xmm0, (%0) \n\t"
"addq $16, %0 \n\t"
"decl %%ecx \n\t"
"jnz 1b \n\t"
"mfence \n\t"
"movl $1536, %%ecx \n\t"
"rep movsb \n\t"
"lfence \n\t"
::"r" (dst):"eax", "ecx", "edi", "esi",
"cc","memory");
}
Skylake, Kaby Lake, and Coffee Lake
For processors based on the Skylake, Kaby Lake, or Coffee Lake microarchitectures, the required sequences depend on which vector extensions are enabled. These sequences require a 6 KB writable buffer with WB-memtype, as well as up to 64 bytes of zero data aligned to 64 bytes.
If the processor does not support Intel® Advanced Vector Extensions (Intel® AVX) or Intel® Advanced Vector Extensions 512 (Intel® AVX-512), then this SSE sequence can be used. It clobbers RAX, RDI, and RCX.
void _do_skl_sse(char *dst, const __m128i *zero_ptr)
{
__asm__ __volatile__ (
"lfence\n\t"
"orpd (%1), %%xmm0\n\t"
"orpd (%1), %%xmm0\n\t"
"xorl %%eax, %%eax\n\t"
"1:clflushopt 5376(%0,%%rax,8)\n\t"
"addl $8, %%eax\n\t"
"cmpl $8*12, %%eax\n\t"
"jb 1b\n\t"
"sfence\n\t"
"movl $6144, %%ecx\n\t"
"xorl %%eax, %%eax\n\t"
"rep stosb\n\t"
"mfence\n\t"
: "+D" (dst)
: "r" (zero_ptr)
: "eax", "ecx", "cc", "memory"
);
}
If the processor supports Intel AVX but does not support Intel AVX-512, then this Intel AVX sequence can be used. It clobbers RAX, RDI, and RCX.
void _do_skl_avx(char *dst, const __m256i *zero_ptr)
{
__asm__ __volatile__ (
"lfence\n\t"
"vorpd (%1), %%ymm0, %%ymm0\n\t"
"vorpd (%1), %%ymm0, %%ymm0\n\t"
"xorl %%eax, %%eax\n\t"
"1:clflushopt 5376(%0,%%rax,8)\n\t"
"addl $8, %%eax\n\t"
"cmpl $8*12, %%eax\n\t"
"jb 1b\n\t"
"sfence\n\t"
"movl $6144, %%ecx\n\t"
"xorl %%eax, %%eax\n\t"
"rep stosb\n\t"
"mfence\n\t"
: "+D" (dst)
: "r" (zero_ptr)
: "eax", "ecx", "cc", "memory", "ymm0"
);
}
If the processor supports Intel AVX-512, then this sequence can be used. Note that the usage of Intel AVX-512 operations may impact the processor frequency. Using VERW with MD_CLEAR support will not impact processor frequency and thus is recommended. It clobbers RAX, RDI, and RCX.
void _do_skl_avx512(char *dst, const __m512i *zero_ptr)
{
__asm__ __volatile__ (
"lfence\n\t"
"vorpd (%1), %%zmm0, %%zmm0\n\t"
"vorpd (%1), %%zmm0, %%zmm0\n\t"
"xorl %%eax, %%eax\n\t"
"1:clflushopt 5376(%0,%%rax,8)\n\t"
"addl $8, %%eax\n\t"
"cmpl $8*12, %%eax\n\t"
"jb 1b\n\t"
"sfence\n\t"
"movl $6144, %%ecx\n\t"
"xorl %%eax, %%eax\n\t"
"rep stosb\n\t"
"mfence\n\t"
: "+D" (dst)
: "r" (zero_ptr)
: "eax", "ecx", "cc", "memory", "zmm0"
);
}
Atom (Silvermont and Airmont Only)
The following sequence can overwrite the store buffers for processors based on the Silvermont or Airmont microarchitectures. It requires a 256-byte writable buffer that is WB-memtype and aligned to 16 bytes. Note this sequence will overwrite buffers with the value in XMM0. If the function is called in a context where this not acceptable (where XMM0 contains secret data), then XMM0 should be saved/restored.
Because Silvermont and Airmont do not support SMT, these sequences may not be needed when entering/exiting C-states. It clobbers RCX.
static inline void SLM_clear_sb(char *zero_ptr)
{
__asm__ __volatile__ (
"movl $16, %%ecx \n\t"
"1: movntdq %%xmm0, (%0) \n\t"
"addq $16, %0 \n\t"
"decl %%ecx \n\t"
"jnz 1b \n\t"
"mfence \n\t"
::"r" (zero_ptr):"ecx","memory");
}
Knights Landing and Knights Mill
The following software sequences can overwrite store buffers for processors based on Knights Landing and Knights Mill. It requires a 1,152-byte writable buffer that is WB-memtype and aligned to 64 bytes.
Knights family processors repartition store buffers when a thread wakes or enters a sleep state. Software should execute this sequence before a thread goes to sleep, as well as between when the thread wakes and when it executes untrusted code. Note that Knights family processors support user-level MWAIT which, when enabled by the OS, can prevent the OS from being aware of when a thread sleeps/wakes.
The Knights software sequence only needs to overwrite store buffers and thus does not require rendezvous of threads. It can be run regardless of what the other threads are doing.
void KNL_clear_sb(char *dst)
{
__asm__ __volatile__ (
"xorl %%eax, %%eax\n\t"
"movl $16, %%ecx\n\t"
"cld \n\t"
"rep stosq\n\t"
"movl $128, %%ecx\n\t"
"rep stosq\n\t"
"mfence\n\t"
: "+D" (dst)
:: "eax", "ecx", "cc", "memory"
);
}
Footnotes
- Assists are conditions that are handled internally by the processor and thus do not require software involvement. While both faults and assists may cause the results of a μop to be discarded, assists restart and complete the instruction without needing software involvement, whereas faults do need software involvement (for example, an exception handler). For example, setting the Dirty bit in a page table entry may be done using an assist.
- CPUID.(EAX=7H,ECX=0):EDX[MD_CLEAR=10]
- Some processors may only enumerate MD_CLEAR after microcode updates.
- On processors that enumerate both CPUID.(EAX=7H,ECX=0):EDX[MD_CLEAR=10] and CPUID.(EAX=7H,ECX=0):EDX[L1D_FLUSH=28]
- This example assumes that the DS selector indicates a writable segment.
- Simultaneous multithreading (SMT) is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better utilize the resources provided by modern processor architectures. Intel® Hyper-Threading technology (HT) is Intel’s implementation of SMT.
Software Security Guidance Home | Advisory Guidance | Technical Documentation | Best Practices | Resources