Document Scope and Intended Audience
The intended audience of this document is system administrators who need to identify if their systems are affected by transient execution attacks, and if so, what actions are required to mitigate their systems. Table 1 enumerates the issues covered in this document as well as their severity assessment.
Table 1. List of vulnerabilities covered in this document
| Common Name - Method | CVE Number | CVSS Severity |
|---|---|---|
| Variant 1 - Bounds Check Bypass | CVE-2017-5753 | Medium |
| Variant 1.1 - Bounds Check Bypass Store | CVE-2018-3693 | Medium |
| Variant 2 - Branch Target Injection | CVE-2017-5715 | Medium |
| Variant 3 - Rogue Data Cache Load | CVE-2017-5754 | Medium |
| Variant 3a - Rogue System Register Read | CVE-2018-3640 | Medium |
| Variant 4 - Speculative Store Bypass | CVE-2018-3639 | Medium |
| Foreshadow - L1 Terminal Fault | CVE-2018-3615 CVE-2018-3620 CVE-2018-3646 |
High |
| Zombieload - Fallout - RIDL - Microarchitectural Data Sampling | CVE-2018-12126 CVE-2018-12127 CVE-2018-12130 CVE-2019-11091 |
Medium |
| TSX Asynchronous Abort | CVE-2019-11135 | Medium |
| Special Register Buffer Data Sampling | CVE-2020-0543 | Medium |
This document describes some good practices that you can enable in production systems but does not prescribe exactly how to implement them. It focuses on the Linux* operating system (OS), but other OSes might provide similar approaches. Refer to the Refined Speculative Execution Terminology guide for detailed definitions of the terminology used in this document.
Transient Execution Side Channels
Modern processors use diverse techniques to improve performance. One of these techniques is known as transient execution. Transient execution (also known as speculative execution) means that instructions are executed before it is known if they are actually required or that arguments for some instructions are guessed by the CPU before they are calculated. Without speculation, the processor would have to wait for prior instructions or addresses to be resolved. For example, the first instruction after a jump would only be executed once the address of the jump is resolved. With speculation, the processor tries to guess the address of the jump before it is resolved, and it starts executing transient instructions at the predicted address. If the assumption was incorrect, the results of these transient instructions are squashed without incurring a performance penalty. A correct guess increases processor performance by minimizing latency and extracting greater parallelism.
Transient execution might affect the microarchitectural state of the processor even when the results of the transient instructions are not made visible architecturally. For example, the contents of caches and buffers might include the results of transient instructions that never retire. Normally these microarchitectural states are visible to the software, but incidental side channels may potentially allow malicious actors to infer data by observing these temporary states.
Recent research has shown how some Intel® platforms might be targeted by different methods to try to leak privileged information. For transient execution attacks to be successful, the malicious actor and the victim must share some physical resources (for a quick introduction to some of the basics of multicore systems, refer to the Hardware Overview). As the threat environment continues to evolve, Intel is continuously investigating architectural and/or microarchitectural changes to combat these types of methods. As a result, recently released platforms include hardware components that protect against these methods. Intel also works with ecosystem partners to develop software and firmware updates that can protect systems from these methods.
Issues Covered in this Document
We quickly introduce the different methods covered in this document. For information on the specifics of each particular technique, please refer to the Intel Software Guidance for Security Advisories.
Spectre and Meltdown
Spectre and Meltdown include several methods that exploit speculative execution to potentially gather sensitive information1,2. Spectre variant 1, variant 2, and variant 4 target the prediction algorithms that are key to speculative execution. Variant 3 (Meltdown)3 attempts to leak data as the result of faulting load instructions forwarding data to subsequent speculative instruction
L1TF
L1 Terminal Fault (L1TF) is a method that may enable an untrusted malicious actor to infer secret data from the level 1 data cache (L1D)4. Certain memory operations can trigger a fault as a result of page swapping. Before this fault resolves, the processor may speculatively access data in the L1D and the microarchitectural effects of these loads might be used to gather data.
MDS
Microarchitectural Data Sampling (MDS) techniques attempt to leak data from small structures within each individual CPU5,6,7. These complex methods observe microarchitectural structures on the physical core where they run, which means that the victim needs to run on the same physical core. These structures are very small, restricting a successful implementation to only being able to extract a few bytes on a successful leakage.
TAA
TSX Asynchronous Abort (TAA) is a subset of the MDS technique. An untrusted process might try to leak data from the victim as the result of an asynchronous abort within a transactional region using Intel® Transactional Synchronization Extensions (Intel® TSX). While this abort is pending, the processor might still perform some subsequent transient load operations. Malicious software running on the same physical core as the victim could use these transient instructions to try to leak stale data from the victim. The victim does not need to make use of Intel TSX to be the target of an attack. For more information about Intel TSX, visit Web Resources About Intel® Transactional Synchronization Extensions.
SRBDS
The Special Register Buffer Data Sampling (SRBDS) technique that may allow data values from special registers to be inferred by malicious code executing on any core of the CPU. These special registers might be used when executing the following instructions that might deal with secrets: RDRAND, RDSEED and EGETKEY.
Affected Platforms
The first step before applying any mitigation is to identify whether a system is affected by any issue. On updated Linux systems, sysfs will report the status of the vulnerability, including whether the platform is affected or not. There are also different tools and guidance for how to detect whether a system is vulnerable. For example, for Linux and BSD systems Intel published a document with step by step instructions, "System Check for Speculative Execution Side Channel”. For Microsoft* systems, Microsoft created a simple step by step guide and released a step-by-step guide to check for a variety of speculative execution side-channel issues, refer to Understanding Get-SpeculationControlSettings PowerShell script output. It is expected that other OS vendors will have similar instructions.
Risk Assessment
- Intel has not received any reports of real-world examples of these transient execution attacks being used to compromise system security. However, proofs of concepts that could gather data from unprivileged levels on unmitigated systems have been tested in controlled research environments. This includes data from the OS or from other applications that share certain hardware resources with the attacker.
- A successful malicious actor has read only access to the data.
- There is no privilege escalation by just using these techniques, meaning this actor cannot become a privileged user of the system.
- Remote attacks using the CVEs listed at the beginning of this document are not possible8.
- When a malicious actor successfully locates an address with secret data, it has a short time window to gather it, as these issues arise as a result of speculative execution. This limits the rate at which data can be extracted. In the cases of MDS and TAA, only a few bytes can be extracted within a successful leak. This actor might need an extended period of time running on the same resources than the victim to collect meaningful information.
- You need to carefully consider the type of data that it is processed in your systems and how this data is handled by the software. In systems where no secret data is present, it might still be theoretically possible to infer secret data from the OS.
General Structure of a Data Leakage Implementation
As mentioned, Intel does not have any knowledge about implementations of any of these methods being used in the real world. To illustrate the complexity of a successful data leakage, in this section we describe the steps that a malicious actor would need to follow to successfully implement MDS or TAA. Other methods slightly differ, but they all follow similarly complex steps.
For a process to successfully gather data from a victim using MDS/TAA:
- The malicious actor needs to detect whether the target system can be used to leak data and run an implementation of MDS/TAA.
- Both victim and attacker need to run on the same physical core.
- In cloud environments, it might be difficult for the malicious actor to land on the same core as a targeted victim. Unless this actor has some previous specific knowledge about the system, workloads, users, and scheduling model implemented in the system, the method will likely run next to an unknown victim.
- It might still be possible to leak data from the OS or from system interrupts that might happen on the core where the malicious software is running. Gathering useful stale data from the OS is difficult and reading seemingly random data from system interrupts might translate to collecting mostly noise.
- Both victim and attacker need to run for an extended period of time on the same core. An MDS-based method leverages internal CPU structures that only store a handful of bytes. Only a few bits or bytes can be leaked in a successful iteration of the technique.
- The victim must bring the same data to the CPU repeatedly. The attacker has no control over what data the victim brings to memory unless it is able to force the victim to run a specific program or gadget. The data needs to be used multiple times to be fully inferred due to the low leakage rate of this method.
- Once the data is extracted, it has to be stored somewhere else quickly. There is a small time window where the stale data is available.
- It might be difficult to infer what the gathered data actually means. This implies that there is a post-processing component required for a successful leakage.
- Any post-processing might happen after the data sampling has finished. An attacker might not want this post process to interfere with the collection process. This process will need to account for the fact that the data collected might belong to different processes or workloads, which increases the complexity of this task.
Malicious Actor Detection
As mentioned, Intel has not received any reports of real-world examples of these methods. An implementation of any of these methods might not want to leave any trace in the OS logs so that it remains undetected. For the same reason, it is also expected that they would not show any unforeseen behavior in the system. Some researchers have tried to detect a potential speculative execution side channel method by evaluating different performance events and creating different metrics9. This approach, however, might lead to many false positives. For TAA methods, the performance events that count the number of transactional sections entered and aborted might be an indicator of a potential malicious actor. It is however difficult to set a ratio of sections aborted relative to those started that would unequivocally identify an implementation of this method.
Impact of Mitigations on Application Performance
Overall, the impact on application performance when running on mitigated platforms affected by these issues will vary based on workload and will often not be significant. There are, however, some cases that might require careful considerations when using affected platforms:
- Programs with frequent system calls or switches between user and kernel space might be impacted in their performance. Typical examples include those with I/O operations. Reducing the number of system calls in the software would limit the impact of mitigations on system performance.
- Applications with high numbers of indirect jumps and calls are affected by Spectre. Newly released platforms might already have hardware mitigations that reduce or remove any performance penalty.
- Those applications that benefit from Intel TSX might see a performance drop after enabling the microcode and OS updates for TAA on affected platforms. You should carefully consider when to apply these mitigations.
- Applications and workloads that use RDRAND and/or RDSEED heavily might see a performance impact after installing the SRBDS mitigations. You should consider whether those mitigations might be disabled on your system or if a different pseudorandom number generator could be used.
- Disabling Intel HT might highly impact the performance of the system. Intel does not recommend this approach. You should perform a careful risk assessment of your systems and mitigation opportunities when considering this approach.
- Improving hardware isolation using scheduling techniques might reduce the overall throughput of your system depending on the workload.
You should consider using a typical or representative workload of your system and benchmark it to make an informed decision about how mitigations affect your system.
Execution Scenarios & Mitigations
Intel has released new microcode updates (MCU) for the platforms affected by these issues as well as implemented updates in the Linux kernel to protect your systems against any implementation of these attacks, even though there are no known implementations of these methods beyond simple proofs of concept. System manufacturers and OS vendors distribute these MCU changes. MCU will require a system reboot. Check the References section for links to different OS vendors.
While these updates provide important mitigations, they might not be sufficient to protect against some potential attacks in all possible scenarios. You should evaluate the risk profile of your systems and apply the appropriate mitigations in your host machines and, if applicable, your Virtual Machine Managers (VMMs) and Virtual Machines (VMs). As mentioned, the malicious software needs to share hardware resources with the victim, which oftentimes means running on the same physical core. Refer to the Appendix: Hardware Overview section for a quick general overview of computer architecture. Table 2 below shows a list of mitigations on affected platforms for these methods. OS updates might also require a system reboot (different OS vendors will provide different instructions). All mitigations can be disabled at boot time by passing the mitigations=off parameter to the kernel.
Table 2. Software mitigations on affected platforms
| Common Name - Method | Mitigation on affected platforms |
|---|---|
| Variant 1 - Bounds Check Bypass | OS update to limit some speculative execution scenarios |
| Variant 1.1 - Bounds Check Bypass Store | OS update to limit some speculative execution scenarios |
| Variant 2 - Branch Target Injection | MCU and OS update to enable techniques that limit speculation on indirect branches |
| Variant 3 - Rogue Data Cache Load | OS update to implement KPTI (Kernel Page Table Isolation) on Linux or KVA (Kernel Virtual Address) Shadow on Microsoft Windows |
| Variant 3a - Rogue System Register Read | MCU to verify that certain instruction does not speculatively return data under some conditions |
| Variant 4 - Speculative Store Bypass | MCU to disable the technique that allows this method |
| Foreshadow - L1 Terminal Fault | MCU and OS update to flush L1D cache. Host, VMMs and VMs should be updated. Follow scheduling technique suggested in this guide. |
| Zombieload - Microarchitectural Data Sampling | MCU and OS update to enable buffer clearing. Follow scheduling technique suggested in this guide. |
| TSX Asynchronous Abort | MCU and OS update to disable TSX or to implement buffer clearing. Follow scheduling technique suggested in this guide. |
| Special Register Buffer Data Sampling | MCU and OS updates to control the mitigation |
Critical Systems
Systems that are critical in your organization using any of the affected platforms should implement all of the proposed mitigations, including MCU and OS updates, for that particular CPU.
Trusted Codes and Guests
Certain computing environments are characterized by only permitting trusted code, libraries and users. System administrators have control over what runs on the system, and strict rules are followed. In these cases, it might be possible to disable all mitigations.
Untrusted Codes and Guests
This is a common scenario in particular cloud instances known as Infrastructure as a Service (IaaS), although other configurations might also support untrusted guests in a system. In this case, untrusted guests can run VMs that might be initially prepared by the particular cloud provider. Users can run a large variety of workloads and untrusted code on those VMs with limited oversight by the administrators. In this case, an unknown malicious actor might be scheduled to execute on the same physical core as the victim (this is known as co-residency).
Typically, the attacker and victim need to run concurrently for an extended period of time for these methods to extract valuable data. Overcommitted systems where multiple processes run on the same CPU or where processes are continuously migrated between cores pose additional challenges for these methods.
Spectre and Meltdown
The mitigation for the different types of techniques under the Spectre and Meltdown umbrella is to try to effectively limit the extent to which side effects of transient execution can be exploited by malicious software. These mitigations limit the ability of the processor to transiently execute certain sequences of instructions. The proposed mitigations remove the risks associated with these methods on affected platforms. New systems also include new hardware designs that remove these issues. On affected platforms, the mitigations can be configured at boot time as shown in Table 3. Default is spectre_v2=auto spectre_v2_user=auto spec_store_bypass_disable=auto.
Table 3. Controlling Spectre and Meltdown mitigation from the Linux kernel command line. Not all possible values are covered
| Parameter | Effect |
|---|---|
| spectre_v2= | This parameter protects the kernel from attacks from user space. |
| spectre_v2=on | Enable Spectre V2 mitigations (also spectre_v2_user=on). |
| spectre_v2=off | Disables mitigations for Spectre V2 (also spectre_v2_user=off). |
| spectre_v2=auto | Detects whether the platform is affected and enables/disables mitigation accordingly (default). |
| spectre_v2=retpoline | Replace indirect branches. |
| spectre_v2_user= | This parameter protects between user space tasks. |
| spectre_v2_user=on | Enable mitigations. |
| spectre_v2_user=off | Disables mitigations. |
| spectre_v2_user=prctl | Mitigation is enabled but can be controlled via prctl. |
| spectre_v2_user=auto | Detects whether the platform is vulnerable and selects the best option (default). On affected systems it normally means prctl. |
| nospectre_v1 | Disable mitigations for Spectre variant 1. |
| nospectre_v2 | Disable mitigations for Spectre variant 2. |
| nopti | Disables Meltdown (Kernel Page Table Isolation) mitigation. |
| spec_store_bypass_disable= | This parameter controls the behavior of Spectre variant 4 mitigations. |
| spec_store_bypass_disable=on | Enable mitigations for Spectre variant 4. |
| spec_store_bypass_disable=off | Disable mitigations for Spectre variant 4. |
| spec_store_bypass_disable=prctl | Mitigation is enabled but can be controlled via prctl. |
| spec_store_bypass_disable=auto | Kernel detects whether the platform is vulnerable and selects the best option (default). |
L1TF
In unmitigated environments that include any affected platform, a process running on a VM might be able to read host or other guest data that resides on the L1D cache by using complex techniques.
Intel released MCU and implemented software mitigations in the Linux kernel. Other OS vendors have also introduced modifications in their software to mitigate against a potential implementation of this technique. Check the recommendations from your OS provider to identify their recommended steps.
The Linux kernel allows you to control the L1TF mitigation at boot time with the l1tf= option. The possible values for this parameter are listed in Table 4. Not specifying any value is equivalent to l1tf=flush.
Table 4. Controlling L1TF mitigations from the Linux kernel command line
| l1tf value | Effect |
|---|---|
| full | Enables all mitigations for the L1TF vulnerability. Disables SMT and enables all mitigations in the hypervisors. The sysfs interface permits to control SMT and L1D flush after boot. |
| full, force | Same as full but disables SMT and L1D flush sysfs control. |
| flush | Enables SMT and the default hypervisor mitigation. Control through sysfs is permitted. |
| flush, nosmt | Disables SMT and enables the default hypervisor mitigation. Sysfs control after boot allowed. |
| flush, nowarn | Same as flush but hypervisors will not warn when a VM is started in a potentially insecure configuration. |
| off | Disables mitigations. |
Bare metal Systems
A mitigated platform affected by the L1TF issue is protected against this type of technique in user space. Since the OS has control over the page table, no other process can transiently access addresses that they should not have access to.
Shared Environments
Enabling the proposed mitigations reduces the risks associated with this method. There is still a small possibility that a process may potentially leak information that it should not have access to when it shares the physical core with another process.
MDS
Intel released microcode and software updates that mitigate some of the techniques associated with this issue on the affected platforms. Intel recommends performing a risk assessment and installing the MCU and the OS updates if your system is at risk. It is not possible to mitigate all different variations of this method on affected platforms while enabling processes to share the same physical core.
The Linux kernel allows a parameter (mds=) to control the behavior of the mitigation on systems that are up to date. See Table 5 for more details. Not specifying any option is equivalent to mds=full.
Table 5. Controlling MDS mitigations on the Linux kernel command line
| mds parameter | Effect |
|---|---|
| full | If an affected platform, it enables all available MDS mitigations. |
| full, nosmt | The same as mds=full and disables simultaneous multithreading (SMT) on affected CPUs. |
| off | Disables MDS mitigations. |
Bare Metal Systems
Even after installing the mitigations on bare metal environments, it is still theoretically possible for an untrusted process to leak data from the host when the untrusted process process is able to run on more than one logical processor on the same physical core. See Figure 1 for this case.

Figure 1. Scenario where a malicious actor using MDS could try to leak data from the OS
In this figure, both threads or processes of the malicious actor (green) are scheduled on the same physical core (Core 1). In this case, one of the processes or threads could try to force the OS to bring some data to the core. This could then be used by the other process or thread to leak stale data and infer some information by exploiting the MDS issue. This is still a highly sophisticated procedure and there is no evidence of any implementation.
Shared Environments
Since not all internal structures can be safely cleared even after installing the proposed software mitigation, there is still the risk of an untrusted process gathering data via using side channel methods when multiple processes can run on the same physical core. The software mitigation reduces the risks, but to fully protect your system you should not allow untrusted guests to share resources with other actors.
TAA
In the case of TAA, the proposed MCU and OS mitigations both disable Intel TSX on platforms that support this feature and clear the internal structures that can be used to leak stale data on affected processors. Any of these two actions remove the ability for an untrusted process to leak data. To disable Intel TSX at boot time, pass the tsx=off parameter to the kernel. Similarly, tsx=on enables Intel TSX. To enable TAA mitigation when Intel TSX is enabled, the pass the taa=full parameter to the kernel at boot time. Using taa=off disables the mitigation. On affected platforms with Intel TSX enabled and the TAA mitigation disabled, systems that enable users to share physical cores might be vulnerable to malicious actors. See Table 6 for different combinations of both parameters on affected platforms. CPUs that are not vulnerable to TAA do not need to have the TAA mitigation enabled. If nothing is specified, the default configuration is tsx=off taa=full.
Table 6. Combination of kernel parameters and effect in the system on affected platforms
| tsx parameter | taa parameter | Effect |
|---|---|---|
| on | off | Enables Intel TSX and disables the TAA mitigation. The system is vulnerable. |
| on | full | Enables Intel TSX and enables the mitigation. The system is protected. |
| off | off | Disables Intel TSX and disables the mitigation. The system is protected. |
| off | full | Disables Intel TSX and disables the mitigation. The system is protected. |
As with MDS, the malicious actor using TAA has no control over what data is brought by the victim to the core. Malicious actors can only gain read access to the data, and no privilege escalation is possible by using this method. On systems where processes are migrated among the available cores with high frequency, or multiple processes are scheduled to run on the same physical core, the risks associated with this technique are low since malicious actors might not have enough time to extract valuable information from the victim.
Enabling the TAA mitigation or disabling Intel TSX protects against this type of method.
Shared Environments
In cloud environments, both the host and guest VMs should have the microcode and kernel mitigation installed. If the host has Intel TSX disabled or the TAA mitigation enabled, the system is protected regardless of how the VMs are configured or whether the guest VMs are migrated from hosts where mitigations are not implemented.
SRBDS
For SRBDS, the MCU enables the mitigation by default on affected platforms. It is possible to configure this at the OS level by using the srbds boot parameter. This parameter only accepts a possible value srbds=off, which disables the mitigation. When the parameter is not specified, the mitigation is enabled (default).
Table 7. Kernel parameter and effect in the system on affected platforms
| srbds parameter | Effect |
|---|---|
| off | Disables the SRBDS mitigation. The system is vulnerable. |
Improving Hardware Isolation Through Process Scheduling
As described in this document, these speculative execution side channel techniques require any implementations of these techniques to share certain computational resources with the victim process. Over the years, several published research papers address the how side channel methods, not only those related to transient execution, can be used on systems that permit multiple untrusted users to share resources due to general side channel techniques11,12,13,14. This is a common scenario in cloud environments. Other infrastructure that only accepts trusted code would not be affected by this type of vulnerability. Some systems might enable a single, sometimes untrusted, user running on a particular compute node for a certain time. In this case, a malicious actor might try to gather information from the OS. The proposed mitigations for these issues already significantly reduce the risks associated with this type of situation on affected platforms.
This section presents a scheduling technique that enables systems in which untrusted guests share resources with other processes to enhance their protection against malicious actors. For simplicity, let’s use a single socket system with four cores used in a cloud setup15 and two different guests16 as an example. In this initial configuration, the scheduler chooses any of the available logical cores to schedule the different VMs that are instantiated. As a result, VMs from different guests can end up on the same physical core, as shown in Figure 2.

Figure 2. No special scheduling used
In Figure 2, Core 1 is running a VM from Guest 1 (green) on logical processor 1 (LP1) and another VM for Guest 2 (blue) on logical processor 2. Core 2 runs another VM from Guest 1 on one of its logical processors. Finally, Core 3 is devoted to VMs of Guest 2.
In this scenario, imagine that the VMs of Guest 2 contain software that implements any of these methods and that tries to gather data from the shared L1 cache. In that case, this software might be able to extract information from the VM of Guest 1 running on LP1. A possible solution is shown in Figure 3, where VMs of different guests are scheduled to different physical cores.

Figure 3. Improved scheduling policy
In this figure, the two VMs of Guest 1 are scheduled on Core 1. This ensures that no other guest can read the L1 cache of Core 1. The VMs for Guest 2 are scheduled on two other available physical cores.
The previous scenario does not include the case where a supposedly trusted VM contains a malicious piece of code. It is the responsibility of the affected guest to avoid that type of situation. In the scheduling scenario shown in Figure 3, it would still be possible for the VM running on LP 2 to leak data from the VM on LP 1 if LP 2 hosts a malicious actor. In that case, either a new definition of what untrusted guest means in the system is required, or users need to understand the risks of running untrusted software in their deployments.
Enabling this type of scheduling in a system that only runs trusted software removes the possibility of a successful data leakage from internal buffers or the L1 cache.
You should check with your OS/software vendors whether it is possible to enable this type of scheduling on your systems. You should also carefully consider the potential impact of this approach in terms of overall throughput of the platform, performance, load balancing, and scheduling flexibility.
Scheduling Interrupts
Another scheduling approach that reduces the severity or feasibility of transient execution attacks is for VMMs to schedule their interrupts on a particular physical core and to ensure that no VM runs on that particular core. This approach is known as interrupt affinity, and an example is shown in Figure 4.

Figure 4. Interrupt affinity: all VMs schedule their interrupts (orange) to run on a dedicated core (logical processors 7 and 8)
In this case, Core 1 and Core 2 are used by VMMs. When they have to process an interrupt, this interrupt is serviced by Core 4. Notice how there are no VMs running on Core 4. This scheduling model reduces the chances for a malicious actor to infer data from system interrupts that belong to different users and that could end up running on the same physical core than this actor. Different OSes might provide their own mechanisms for enabling this process. This type of configuration does not fully remove the risk of data being leaked.
Guidelines Summary
Intel has released MCUs and has worked with the software ecosystem to enable software updates that mitigate most of the risks of these transient execution attacks on affected platforms. You should take special care when deciding which strategy to follow. System administrators should carefully study the security and performance implications of each possible solution in the context of the characteristics of the more relevant or typical workloads in their systems. Mission critical systems should enable all the mitigations released by different software vendors, including firmware, OS, drivers, and other installed software.
Systems where all software and users can be trusted might not need to be mitigated against these techniques. Systems used as software as a service (SaaS) infrastructure typically fall into this category. In systems that expect to run untrusted guests, you should apply the MCUs and OS updates and carefully consider the following:
- The described methods act locally, mainly affecting processes running on the same physical core.
- They do not get write privileges to the data.
- Privilege escalation is not possible by just following these methods.
- Not all possible transient execution attacks can be mitigated on the affected platforms just by installing MCUs and OS. You should evaluate the possible risks associated with those cases, the feasibility of a malicious actor exploiting those issues, and the requirements of the target system.
- When enabled, hardware isolation process scheduling restricts the ability of malicious software to collect data from other guests using transient execution attacks. While it is still theoretically possible for a process to leak data from the core where it is running, this scheduling technique effectively limits its impact.
- Mitigations might require system (host and VMs) reboots.
- Systems where the following conditions are true might not be as exposed to implementations of these methods due to the relatively low extraction rate that these methods present:
- Cores are overcommitted
- Processes/guests are frequently migrated between different cores
- Short-running processes are common
If the MCUs and/or OS updates cannot be applied to a particular system, you should consider scheduling alternatives to safeguard your users from potential implementations of these methods. However, even if you only follow these recommended mitigations, you can successfully limit the impact of these techniques.
On systems where MCUs and OS updates have been applied, you can still disable the mitigations. For example, Linux systems with kernel version 5.2+ can be booted with kernel parameter mitigations=off. For other operating systems, consult with your OS vendor. Figure 5 shows a diagram of the steps that you should take before applying the mitigations in your system.
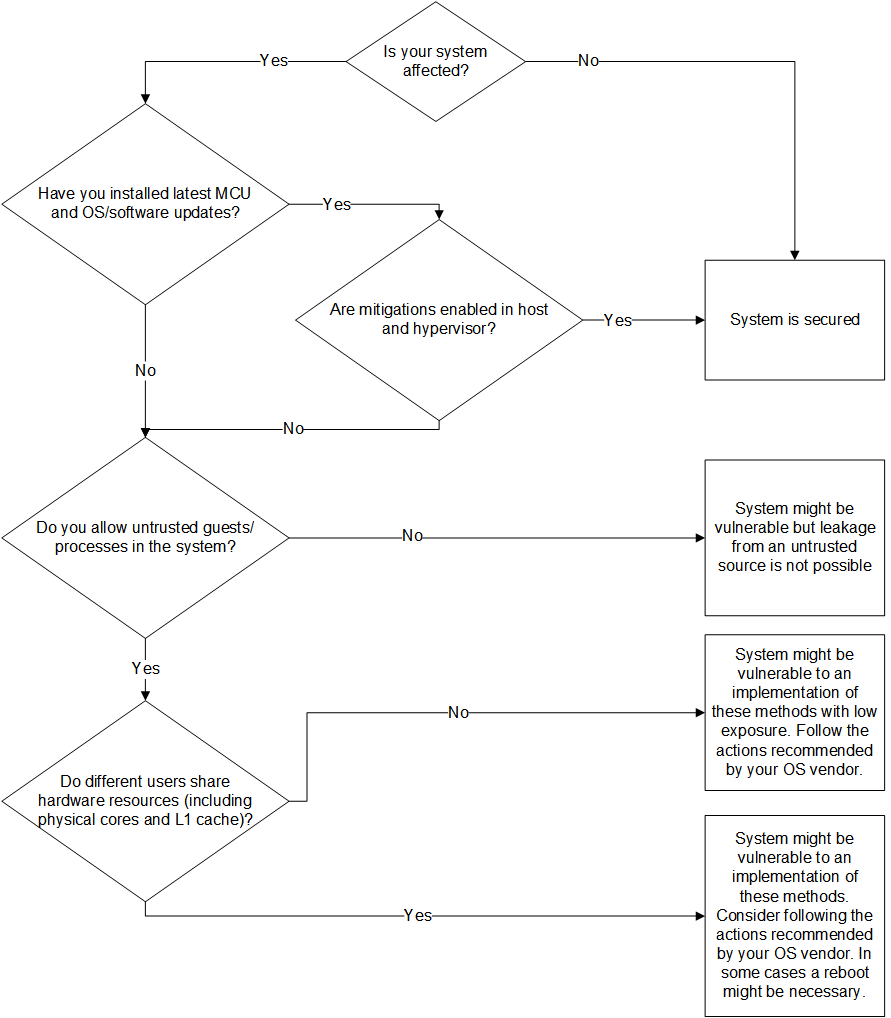
Figure 5. Decision tree for applying the mitigations
Appendix A: Hardware Overview
In modern multicore processors, different physical cores share a certain number of common resources. For example, Figure 6 shows a single-socket processor with four physical cores. Each core has its own L1. The L2 on each core is shared among all cores in the processor. Also, all cores share the same L3 cache.
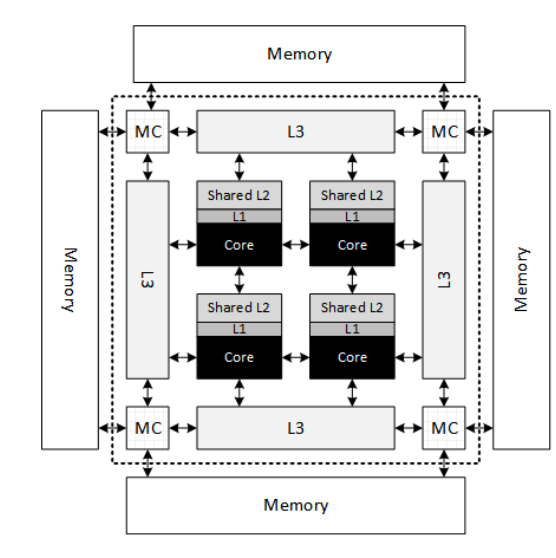
Figure 6. Generic multicore architecture composed of four individual cores
Simultaneous Multithreading (SMT) enables multiple independent threads to improve the utilization of the computational resources provided by modern processors. SMT enables hardware multithreading capability within a single core by using shared execution resources in the core. In Intel® Hyper-Threading Technology (Intel® HT Technology), Intel’s implementation of SMT, each physical core is able to run a number of hyperthreads independently. This number of hyperthreads per physical core is also known as logical processor. For example, Figure 7 shows a generic multi-processor design with four physical cores. In that design, each core can execute two threads concurrently. This means that each physical core provides two logical processors.
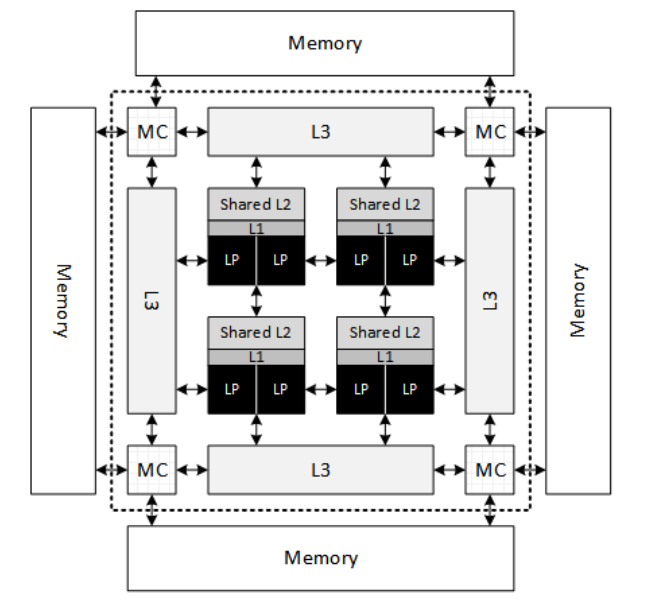
Figure 7. SMT design
Enabling SMT shows that L1 and L2 are shared by different logical cores on the same physical core. Speculative side-channel methods normally attempt to exploit the shared resources between two logical cores on the same physical core. This typically means L1 and internal structures to the core.
Appendix B: Trusted and Untrusted Guests
In general, systems that enable untrusted users and codes to execute are susceptible to possible malicious actors trying to get access to protected information.
Those systems where every single user or piece of code is trusted, or where administrators have confidence that no secret information is stored, might not be affected by these methods, and you might not need to implement any additional measures to protect your systems.
Some scenarios where different security related actions are required include:
- A VM or container that executes arbitrary code. This is code that users or customers develop themselves or download from untrusted sources.
- Trusted and untrusted users and code might coexist on the same physical core.
- The system, either bare-metal, VMs, or nested VMs, grants access to untrusted users. It’s important to differentiate between untrusted users and users that should not access the system under any circumstances.
Appendix C: Mitigation Status Report on sysfs
On an up to date OS, the status of the different mitigations is reported on sysfs. For simplicity, this document lists the files and possible values for MDS and SRBDS. For the full list, please refer to the Linux kernel documentation. When the files indicated cannot be found on a system, that might indicate that the OS is not up to date.
MDS
The relevant file for MDS can be found in /sys/devices/system/cpu/vulnerabilities/mds. The possible values for this file are shown in Table 8.
Table 8. Possible values reported in sysfs for MDS and their meaning
| Value | Meaning |
|---|---|
| Not affected | The platform is not vulnerable to MDS. |
| Vulnerable | The platform is vulnerable, there is an updated microcode that could mitigate against MDS, but the mitigation has been disabled by using the mds kernel parameter. |
| Vulnerable: Clear CPU buffers attempted, no microcode | The platform is vulnerable but the microcode has not been updated to support clearing the affected buffers. |
| Mitigation: Clear CPU buffers | The platform is vulnerable, but the microcode is up to date and the mitigation is enabled. |
SRBDS
For the case of SRBDS, the relevant file is /sys/devices/system/cpu/vulnerabilities/srbds. The possible values in this file are as shown in Table 9.
Table 9: Possible values reported in sysfs for SRBDS and their meaning
| Value | Meaning |
|---|---|
| Not affected | The system is not vulnerable to SRBDS. |
| Vulnerable | The system has updated microcode and the mitigation is disabled with the kernel parameter srbds=off. |
| Vulnerable: No microcode | The system is vulnerable to SRBDS and is running an older microcode without the SRBDS mitigation. |
| Mitigation: Microcode | The system has the updated microcode and the mitigation is enabled. |
| Mitigation: TSX disabled | The system has updated microcode and is one of the CPU’s that is only vulnerable when Intel TSX is enabled. Intel TSX has been disabled on this system at boot time. |
| Unknown: Dependent on hypervisor status | For virtualized environments, shown for all guest VMs. |
References
Intel
- Intel® Analysis of L1 Terminal Fault
- Intel Analysis of Microarchitectural Data Sampling
- Security Best Practices for Side Channel Resistance
- Intel® 64 and IA-32 Architectures Software Developer Manuals
- Intel® Software Guidance for Security Advisories
- How to Assess the Risk of Your Application
OS and Software Vendors
- Linux Kernel documentation for Spectre
- Linux Kernel documentation for L1TF
- Linux Kernel documentation for MDS
- Red Hat* Side-Channel Attacks
- Red Hat L1TF
- Red Hat MDS
- Ubuntu* Spectre and Meltdown
- Ubuntu L1TF
- Ubuntu MDS
- VMware* Spectre
- VMware L1TF
- VMware MDS
- Docker*: Using seccomp security profiles for Docker
- OpenStack* mitigation for MDS
- QEMU 2.11.1 and making use of Spectre/Meltdown mitigation for KVM guests
- Microsoft* “Understanding Get-SpeculationControlSettings PowerShell script output”
- Microsoft Guidance to Mitigate L1TF
- Microsoft Guidance to Mitigate MDS
- Microsoft Hyper-V* core scheduling
Footnotes
- Reading Privileged Memory with a Side-Channel. Google Project Zero. 2018.
- “Spectre Attacks: Exploiting Speculative Execution”. P. Kocher, J. Horn, A. Fogh, D. Genkin, D. Gruss, W. Haas, M. Hamburg, M. Lipp, S. Mangard, T. Prescher, M. Schwarz, Y. Yarom. 40th IEEE Symposium on Security and Privacy. 2019.
- “Meltdown: Reading Kernel Memory from User Space”. M. Lipp, M. Schwarz, D. Gruss, T. Prescher, W. Haas, A. Fogh, J. Horn, S. Mangard, P. Kocher, D. Genkin, Y. Yarom, M. Hamburg. 27th USENIX Security Symposium. 2018.
- “Foreshadow: Extracting the Keys to the Intel SGX Kingdom with Transient Out-of-Order Execution”. J. Van Bulck, M. Minkin, O. Weisse, D. Genkin, B. Kasikci, F. Piessens, M. Silberstein, T. F. Wenisch, Y. Yarom, Yuval, R. Strackx. Proceedings of the 27th USENIX Security Symposium. 2018.
- ”ZombieLoad: Cross-Privilege-Boundary Data Sampling”. M. Schwarz, M. Lipp, D. Moghimi, J. Van Bulck, J. Stecklina, T. Prescher, D. Gruss, Daniel. arXiv:1905.05726. 2019.
- "RIDL Rogue In-flight Data Load", S. van Schaik, A. Milburn, S. Österlund, P. Frigo, G. Maisuradze, K. Razavi, H. Bos, C. Giuffrida, Cristiano. 2019.
- "Fallout: Reading Kernel Writes From User Space", M. Minkin, D. Moghimi, M. Lipp, M. Schwarz, J. Van Bulck, D. Genkin, D. Gruss, B. Sunar, F. Piessens, Y. Yarom. 2019.
- There is a variation called NetSpectre, not covered in this document, that might leak data from a local network at a rate of up to 60 bits an hour, even less over the Internet. Refer to “NetSpectre: Read Arbitrary Memory over Network”. M Schwarz, M Schwarzl, M Lipp, D Gruss. CoRR abs/1807.10535 (2018).
- Detecting Spectre And Meltdown Using Hardware Performance Counters.
- “FLUSH+RELOAD: A High Resolution, Low Noise, L3 Cache Side-Channel Attack”. Y. Yarom, K. Falkne. USENIX Security Symposium 2014: 719-732.
- “Cross-Tenant Side-Channel Attacks in PaaS Cloud”s. Y. Zhang, A. Juels, M. K. Reiter, and T. Ristenpart. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security (CCS '14). ACM, New York, NY, USA, 990-1003
- “Cross-VM side channels and their use to extract private keys”. Y. Zhang, A.
- Juels, M. K. Reiter, and T. Ristenpart. In Proceedings of the 2012 ACM conference on Computer and communications security (CCS '12). ACM, New York, NY, USA, 305-316.
- “Last-Level Cache Side-Channel Attacks are Practical”. F. Liu, Y. Yarom, Q. Ge, G. Heiser, R. B. Lee. IEEE Symposium on Security and Privacy 2015: 605-622
Software Security Guidance Home | Advisory Guidance | Technical Documentation | Best Practices | Resources