Generative AI (GenAI) is reshaping industries with its ability to generate text, code, and images at scale. Despite the growing excitement around GenAI, many enterprises and developers are struggling to move beyond pilot projects. Technical implementation, operational cost (cost to run the GenAI initiatives), and concerns around data security are the top barriers in implementing GenAI applications. Also, for many enterprises, the GenAI ecosystem is too fragmented, and this complexity is another major obstacle to moving from experimentation to production. This is where Open Platform for Enterprise AI (OPEA) come into play to address the challenges outlined.
In this article, we’ll break down the core concepts of OPEA, Bedrock, and OpenSearch, and how to leverage the microservices effectively using OPEA.
What is OPEA?
OPEA is a framework that enables the creation and evaluation of open, multi-provider, robust, and composable generative AI (GenAI) solutions, leading to quicker GenAI adoption and business value.
OPEA includes:
-
Detailed framework of composable microservices building blocks for state-of-the-art GenAI systems including LLMs, data stores, and prompt engines
-
Architectural blueprints of retrieval-augmented GenAI component stack structure and end-to-end workflows
-
Multiple micro- and megaservices to get your GenAI into production and deployed
-
A four-step assessment for grading GenAI systems around performance, features, trustworthiness and enterprise-grade readiness
Architecture
-
Microservices – allows you to independently develop, deploy, and scale individual components of the application, making it easier to maintain and evolve over time. Each microservice is designed to perform a specific function or task within the application architecture.
-
Megaservices – are composed of one or more microservices. Unlike microservices which focuses on a specific task or function, a megaservice orchestrates multiple microservices by coordinating the interactions between them to fulfill specific application requirements.
-
Gateways - acts as the entry point for incoming requests, routing them to the appropriate microservices within the megaservice. Gateways support API definition, API versioning, rate limiting, and request transformation, allowing for fine-grained control over how users interact with the underlying microservices.
Core Components
-
GenAIComps - collection of microservice components, leveraging a service composer to assemble a mega-service tailored for real-world Enterprise AI applications.
-
GenAIExamples - Generative AI (GenAI) and Retrieval-Augmented Generation (RAG) examples, demonstrating the whole orchestration pipeline (examples include ChatQnA and DocSum, which leverages microservices for specific applications.)
-
GenAIInfra - containerization and cloud native suite for OPEA, which can be used by enterprise users to deploy to their own cloud.
-
GenAIEval - evaluation, benchmark, and scorecard suite for OPEA, targeting performance on throughput and latency, accuracy on popular evaluation harness, safety, and hallucination.
What is Amazon Bedrock?
A fully managed service that provides access to the leading foundation models through a single API to build and scale generative AI applications with security, privacy, and responsible AI.
In addition to a single unified API, Bedrock also provides the following capabilities:
-
Model Choice - Take advantage of the latest generative AI innovations with easy access to a choice of high-performing foundation models. Single-API access gives you the flexibility to use different models and upgrade to the latest model versions with minimal code changes.
-
Customization – You can customize models for specific tasks by privately fine-tuning models using your own labeled datasets in just a few quick steps. This helps you deliver differentiated and personalized user experiences.
-
RAG - Knowledge Bases for Amazon Bedrock is a fully managed RAG capability that allows you to customize foundation model responses with contextual and relevant company data.
-
Agents - You can create an agent in just a few quick steps by first selecting a model and providing it with access to your enterprise systems and knowledge bases to securely execute your APIs.
-
Data Automation - Streamlines the generation of valuable insights from unstructured multimodal content such as documents, images, audio, and videos and automate Media Analysis and RAG workflows quickly and cost-effectively.
-
Guardrails - Provides configurable safeguards to help safely build generative AI applications at scale. With a consistent and standard approach used across all supported foundation models (FMs), Guardrails delivers industry-leading safety protections
-
Evaluation tools - Evaluate, compare, and select the foundation model for your use case with Model Evaluation. Prepare your RAG applications built on Amazon Bedrock Knowledge Bases for production by evaluating the retrieve or retrieve and generate functions.
Integration of Amazon Bedrock with OPEA
Let's look at ChatQnA application from OPEA GenAIExamples GitHub repository – uses RAG architecture, which combines the benefits of a knowledge base and generative models to reduce hallucinations, maintain up-to-date information, and leverage domain-specific knowledge.
For this application, Bedrock will be integrated with the LLM microservice. The user begins the process by submitting a query through the front-end application. Based on the nature of the query, ChatQnA-LLM routes either a chat or retrieved documents to a remote LLM server - in this case, Amazon Bedrock. The Bedrock service automatically scales to accommodate any number of incoming requests, eliminating the need for users to manage infrastructure.
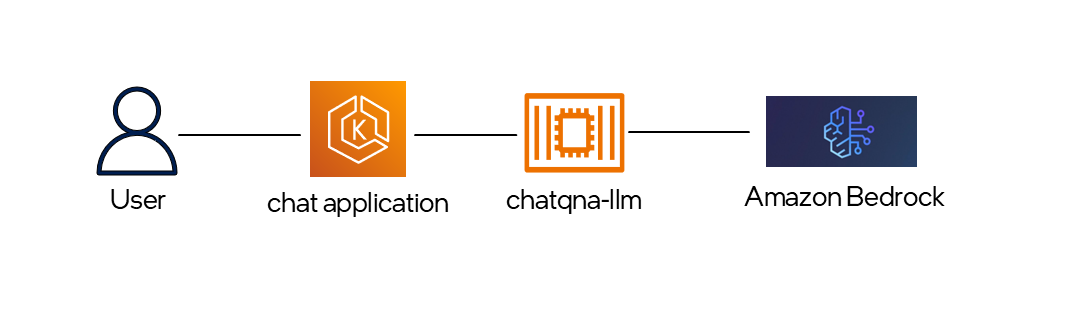
Steps to consume Bedrock through OPEA
-
Build and consume Bedrock as a microservice through GenAIComps repository from OPEA. For detailed instructions - refer here.
git clone https://github.com/opea-project/GenAIComps.git export OPEA_GENAICOMPS_ROOT=$(pwd)/GenAIComps cd $OPEA_GENAICOMPS_ROOT -
Set the environment variable and build the docker image as shown below.
export AWS_REGION=${aws_region} export AWS_ACCESS_KEY_ID=${aws_access_key_id} export AWS_SECRET_ACCESS_KEY=${aws_secret_access_key} docker build --no-cache -t opea/llm-textgen:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f comps/llms/src/text-generation/Dockerfile . -
Start the container with the required environment variables and port mapping.
docker run -d --name bedrock -p 9009:9000 --ipc=host -e http_proxy=$http_proxy -e https_proxy=$https_proxy -e LLM_COMPONENT_NAME="OpeaTextGenBedrock" -e AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID -e AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY -e AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN -e BEDROCK_REGION=$AWS_REGION opea/llm-textgen:latest -
Finally, validate the service using the command below -
curl http://${host_ip}:9009/v1/chat/completions \ -X POST \ -d '{"model": "us.anthropic.claude-3-5-haiku-20241022-v1:0", "messages": [{"role": "user", "content": "What is Deep Learning?"}], "max_tokens":17, "stream": "true"}' \ -H 'Content-Type: application/json'
What is OpenSearch?
OpenSearch is an open-source, distributed search and analytics engine designed for real-time data exploration at scale. It combines scalable full-text search with ML capabilities for anomaly detection and predictive analytics. Designed for observability and security analytics, OpenSearch supports ingestion of logs and metrics, while also offering encryption and access control – making it ideal for both real-time monitoring and secure data analysis.
How does it work?
-
Data Ingestion - Send data from various sources like logs, metrics and documents as JSON to OpenSearch through REST APIs
-
Indexing - OpenSearch will parse the data received and stores in an index with inverted indexing for fast search
-
Searching - Use raw vector search or AI-powered methods like semantic, hybrid, multimodal, or neural sparse search.
Integration of OpenSearch with OPEA
Let’s look at the same ChatQnA application again which was discussed in the Bedrock section. OpenSearch can be used as a vector database to store and retrieve documents in an end-to-end RAG application scenario.
-
During dataprep
- The user can upload a single document or multiple documents through the client-facing application.
- The dataprep microservice extracts the text, creates chunks, embeds the chunks using the embedding microservice, and stores it in the OpenSearch vector database. -
During retrieval
- When a user query comes, the retriever embeds the query using the embedding microservice.
- The embedded query is compared in the vector database to get the number of relevant documents to be retrieved.
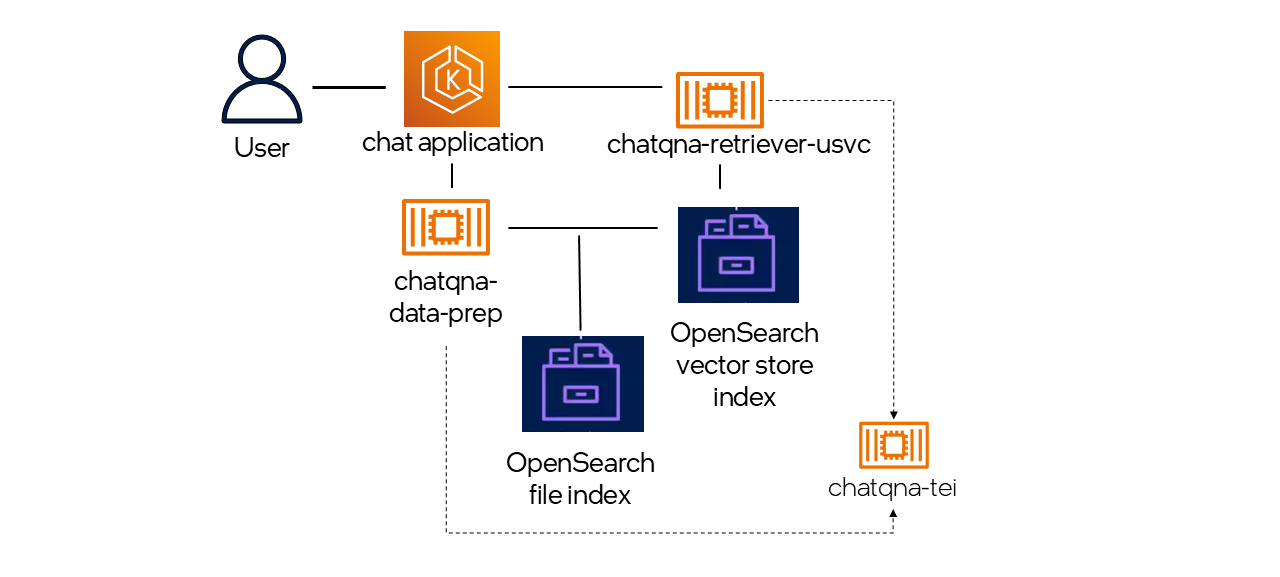
Steps to consume OpenSearch through OPEA
Both Dataprep and Retrieval microservices can leverage OpenSearch as the vector database. The first step is to set up the OpenSearch VectorDB service and then follow the below instructions to use OpenSearch for both the microservices.
DataPrep Microservice:
-
Setup the environment variables and start the Text Embedding Inference service. TEI is a comprehensive toolkit designed for efficient deployment and serving of open-source text embeddings models.
export your_ip=$(hostname -I | awk '{print $1}') export EMBEDDING_MODEL_ID="BAAI/bge-base-en-v1.5" export TEI_EMBEDDING_ENDPOINT="http://${your_ip}:6006" export OPENSEARCH_URL="http://${your_ip}:9200" export INDEX_NAME=${your_index_name} export HUGGINGFACEHUB_API_TOKEN=${your_hf_api_token} docker run -p 6006:80 -v ./data:/data --name tei_server -e http_proxy=$http_proxy -e https_proxy=$https_proxy --pull always ghcr.io/huggingface/text-embeddings-inference:cpu-1.6 --model-id $ EMBEDDING_MODEL_ID -
Build the dataprep microservice container.
cd $OPEA_GENAICOMPS_ROOT docker build -t opea/dataprep:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f comps/dataprep/src/Dockerfile .Note: Remember to clone the GenAIComps repo as shown in the Bedrock section of this blog.
-
Start the dataprep microservice with the environment variables as shown below.
docker run -d --name="dataprep-opensearch-server" -p 6007:6007 --runtime=runc --ipc=host -e http_proxy=$http_proxy -e https_proxy=$https_proxy -e OPENSEARCH_URL=$OPENSEARCH_URL -e INDEX_NAME=$INDEX_NAME -e EMBED_MODEL=${EMBED_MODEL} -e TEI_EMBEDDING_ENDPOINT=$TEI_EMBEDDING_ENDPOINT -e HUGGINGFACEHUB_API_TOKEN=$HUGGINGFACEHUB_API_TOKEN -e DATAPREP_COMPONENT_NAME="OPEA_DATAPREP_OPENSEARCH" opea/dataprep:latest -
When the container is up, test the microservice by uploading documents and make sure the file path is correct.
curl -X POST \ -H "Content-Type: multipart/form-data" \ -F "files=@./file1.txt" \ http://localhost:6007/v1/dataprep/ingest
Retrieval microservice:
- Set up the environment variables.
export RETRIEVE_MODEL_ID="BAAI/bge-base-en-v1.5" export OPENSEARCH_URL="http://${your_ip}:9200" export INDEX_NAME=${your_index_name} export TEI_EMBEDDING_ENDPOINT="http://${your_ip}:6060" export HUGGINGFACEHUB_API_TOKEN=${your_hf_token} export OPENSEARCH_INITIAL_ADMIN_PASSWORD=${your_opensearch_initial_admin_password} export RETRIEVER_COMPONENT_NAME="OPEA_RETRIEVER_OPENSEARCH" - Build the docker container.
cd $OPEA_GENAICOMPS_ROOT docker build -t opea/retriever:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f comps/retrievers/src/Dockerfile . - Run the retrieval microservices with all the necessary environment variables as shown below.
docker run -d --name="retriever-opensearch-server" -p 7000:7000 --ipc=host -e http_proxy=$http_proxy -e https_proxy=$https_proxy -e OPENSEARCH_URL=$OPENSEARCH_URL -e INDEX_NAME=$INDEX_NAME -e TEI_EMBEDDING_ENDPOINT=$TEI_EMBEDDING_ENDPOINT -e HUGGINGFACEHUB_API_TOKEN=$HUGGINGFACEHUB_API_TOKEN -e RETRIEVER_COMPONENT_NAME=$RETRIEVER_COMPONENT_NAME opea/retriever:latest - Validate the retriever microservice using the curl command below.
export your_embedding=$(python -c "import random; embedding = [random.uniform(-1, 1) for _ in range(768)]; print(embedding)") curl http://${your_ip}:7000/v1/retrieval \ -X POST \ -d "{\"text\":\"What is the revenue of Nike in 2023?\",\"embedding\":${your_embedding}}" \ -H 'Content-Type: application/json'
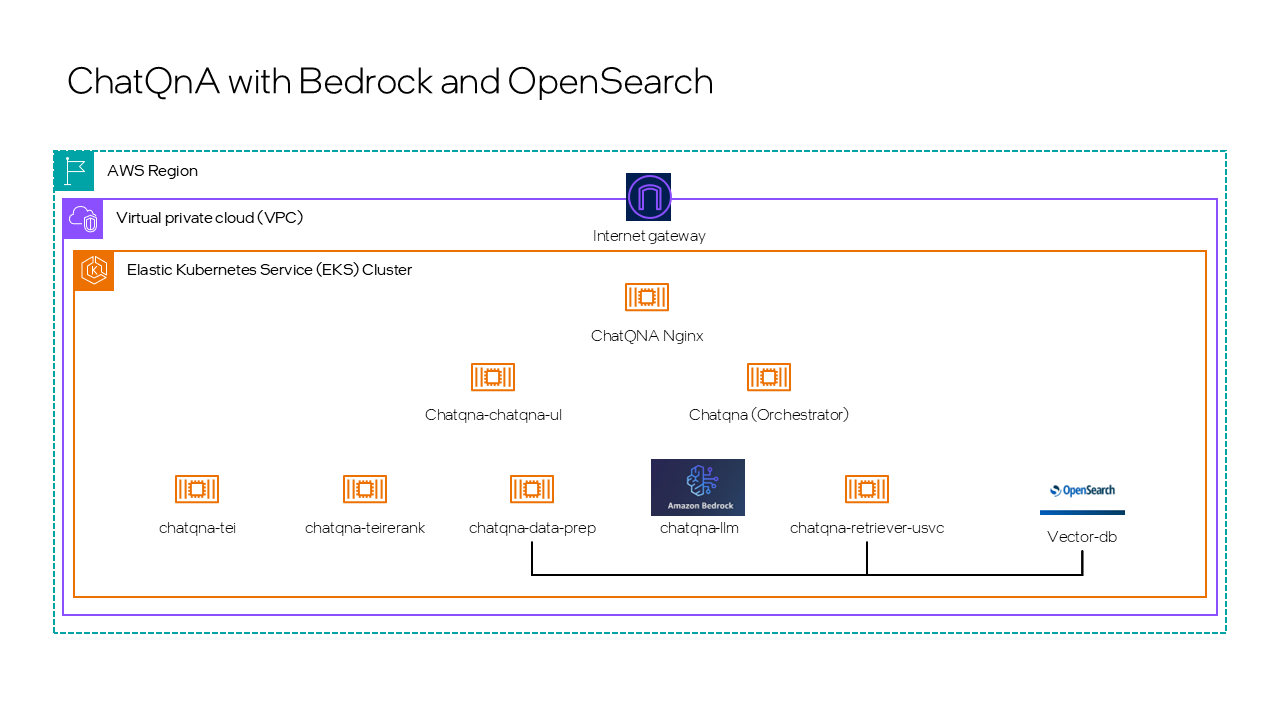
Figure 3 illustrates the ChatQnA application integration with all the components (Amazon Bedrock, OpenSearch and OPEA) involved. The microservices at the bottom layers are the building blocks which will be arranged by the chatqna megaservice (orchestrator). The chatqna-ui is another microservice that provides the client facing application to leverage the chatqna-megaservice. The gateway to the client application is through the chatqna-nginx microservice that sits on top of all these services.
What’s Next?
Try out other GenAI Examples such as AgentQnA, AudioQna from the OPEA GitHub repository. Also, leverage the above microservices explained as building blocks to create additional applications and use cases.
Additional Resources