A recipe for efficient coordination between user-mode applications and accelerators for optimizing data processing.
Introduction
The emerging era of data-centric computing is forcing increased focus on accelerating workloads and reducing COGS (cost of goods sold) in data centers. Hardware methods for such acceleration include specialized instruction set architecture (ISA) extensions in CPU cores, programmable heterogeneous elements (such as GPUs and FPGAs), and offload acceleration engines for data movement and transformation functions. While ISA-based acceleration is well defined within the instruction set architecture of the host CPU, offload-based acceleration organically evolved from traditional I/O controller and device driver models without consistent constructs and capabilities. This paper provides an overview of various accelerator-interfacing technologies that were introduced on upcoming Intel® Xeon® processors. These technologies target reduced offload overheads, minimized end-to-end latencies, a simplified memory model, and scalable virtualization capabilities suitable for workload deployment through virtual machines and/or containers.
Current Landscape
Offload acceleration hardware and software that evolved from traditional I/O controller designs suffer from many challenges. These include work submission overheads, memory management complexity, work completion synchronization overheads, and sharing accelerators among applications or tenants.
Work Submission Overheads
Traditionally, when an application submits work to an accelerator, the request is routed to a kernel-mode device driver that abstracts the interface between the software and hardware of the underlying accelerator device. The latencies and overheads associated with kernel I/O stacks can cause bottlenecks for high-performance, streaming accelerators.
Memory Management Complexity Overheads
Traditional accelerator designs require pinned memory to share data between an application and a hardware accelerator. Also, an accelerator’s view of memory (accessed via direct memory access) is significantly different from an application’s view, often requiring the underlying software stack to bridge the two views through costly memory pinning and unpinning and DMA map and unmap operations.
Work Completion Synchronization Overheads
Existing software stacks for accelerators rely on either interrupt-driven processing, busy-polling of completion status registers, or descriptors in memory. Interrupt processing architecture in operating system kernels imposes overhead with context switching and deferred processing that can reduce system performance. On the other hand, busy polling consumes more power, reduces the number of CPU cycles available to other applications, and can negatively impact scaling.
Accelerator Shareability
Efficient and secure sharing of an accelerator across multiple concurrent applications, containers, and virtual machines is a foundational requirement for deploying data centers. Hardware-assisted I/O virtualization, such as SR-IOV, accelerates I/O virtualization by eliminating the hypervisor from the process of accessing an accelerator on the behest of guest software.
However, such architectures tend to be hardware-intensive and less well suited for two kinds of designs:
- Resource-constrained system-on-a-chip (SoC) integrated accelerator designs
- Use cases that need more scalability than is currently available in virtual machine-based usages (for example, uses that share an accelerator among thousands of concurrent containers)
In summary, the system architecture for accelerators must address the following requirements:
- Offload efficiency—low overhead, user-mode, function offload (scalable and low-latency work dispatch, lightweight synchronization, event signaling, and others)
- Memory model—a uniform view of memory by the application and the function offloaded to the accelerator
- Virtualization—efficient sharing of the accelerator across applications, containers, and virtual machines
- Consistency—a consistent hardware and software interface and SoC interfacing architecture across all IPs
Accelerator Interfacing Technologies
This section summarizes the capabilities of accelerator-interfacing technologies on upcoming Intel® Xeon® processors.
These capabilities address the requirements above and include the following:
- Work-dispatch instructions (MOVDIRI, MOVDIR64B, ENQCMD/S) for optimized offload
- User-mode wait instructions (UMONITOR, UMWAIT, TPAUSE) for efficient synchronization
- Low-latency user interrupts
- Shared virtual memory
- Scalable I/O virtualization
Enhancements for Offload Efficiency & Scalability
MOVDIRI
Enables high-throughput (4B or 8B) doorbell-writes using direct-store semantics to benefit streaming offload models where small units of work are streaming at a high rate to the accelerator.
MOVDIR64B
Enables 64-byte atomic writes to accelerator work-queues to benefit low-latency offload models where accelerator devices are highly optimized for completing the requested operation at a minimal latency. The 64-byte payload enables accelerators to avoid DMA read latencies for fetching the work-descriptor and in some cases even the actual data (thereby reducing the end-to-end latency).
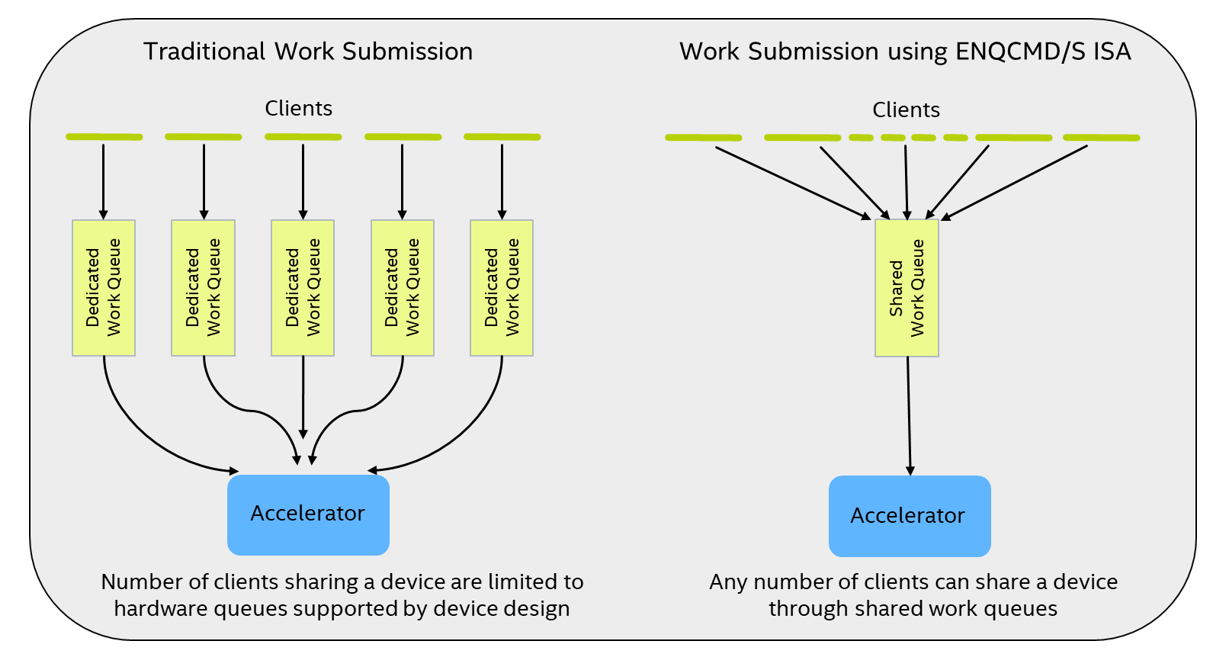
ENQCMD/S
Enable simultaneous and direct work submission from multiple, non-cooperating software entities (such as applications, containers, or applications/containers inside VMs) to an accelerator’s work queue (termed shared work queue or SWQ) as shown in the following figure. The instructions to enqueue commands—ENQCMD (enqueue command) and ENQCMDS (enqueue command as supervisor)—have two unique features:
- The work descriptor contains a process address space identifier (PASID) that allows the accelerator to identify the submitting software agent on a per-descriptor basis
- The commands use PCIe* deferrable memory write (DMWr) requests to allow the accelerator to carry-out or defer incoming DMWr requests
ENQCMD/S instructions return a "success" or "retry" (deferred) indication to software. Success indicates that the work was accepted into the SWQ, while retry indicates it was not accepted due to SWQ capacity, QoS, or other reasons. On receiving a retry status, the work submitter may retry later.
UMONITOR/UMWAIT/TPAUSE
Enable low-latency synchronization between user-mode software and offloaded tasks. Also, allow a processor to enter an implementation-dependent, optimized state while waiting for an accelerator to complete the dispatched work. The optimized state may be either a lightweight power or performance-optimized state or an enhanced power/performance-optimized state. The UMWAIT and TPAUSE instructions allow software to choose between the two optimized states; they also provide a mechanism to specify an optional timeout value. The TPAUSE instruction can be used along with the transactional synchronization extensions to wait on multiple events. These instructions allow a hyperthread (HT) to use compute resources when a sibling thread is efficiently waiting for an event.
User Interrupts
Enable a lightweight mechanism for directly signaling the user-mode software. User interrupts enable event delivery to the user-space applications without any kernel intervention and can be used by the kernel agents to send notifications to user-space application in lieu of using the operating system signaling mechanisms. User interrupts reduce the end-to-end latency, overall jitter, and context-switching overheads for high-performance applications.
Shared Virtual Memory (SVM)
SVM architecture enables a unified view of memory from both the CPU and an accelerator by:
- Allowing the accelerator to use same virtual addresses as the CPU
- Enabling the accelerator to access unpinned memory and to recover from the I/O page-faults
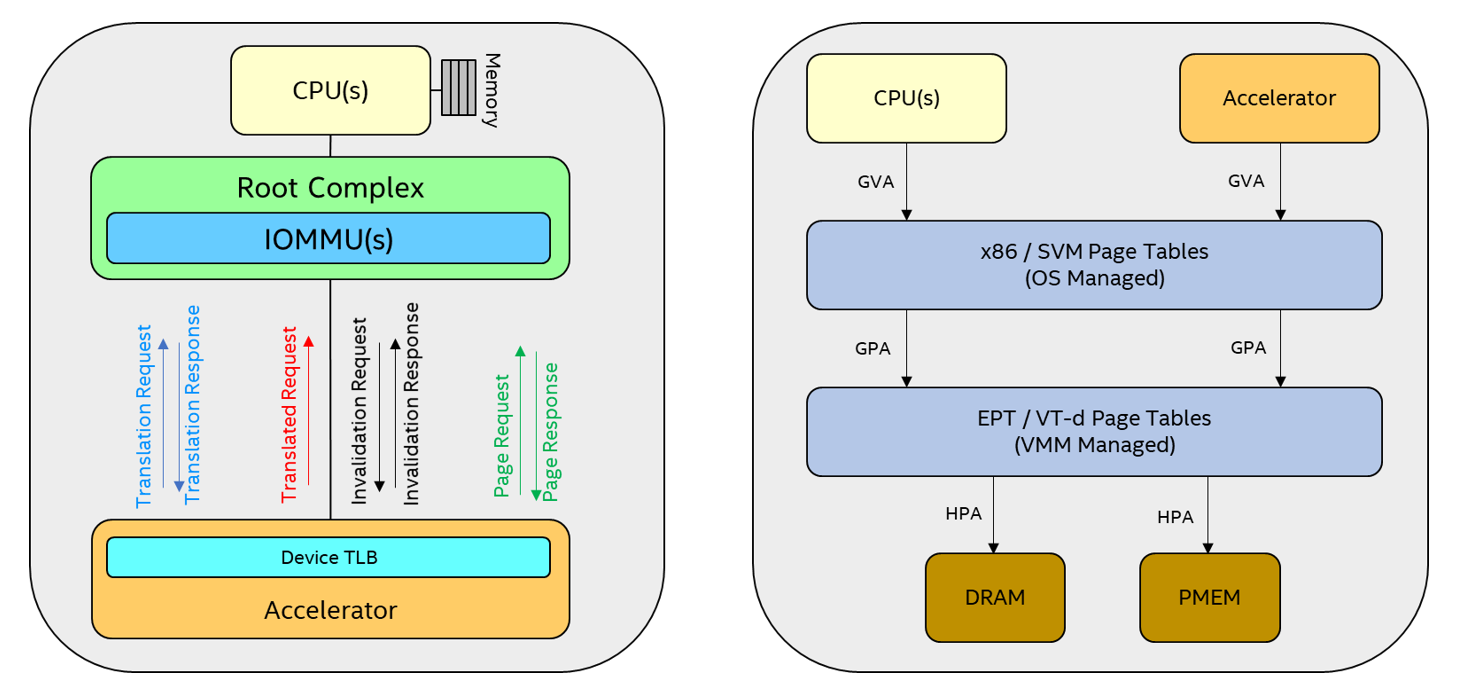
Upcoming Intel Xeon processors support SVM capabilities, such as process address space identifier (PASID), address translation services (ATS), and page request services (PRS). System software allocates a PASID to identify the address space of each client submitting the work, and Intel® Virtualization Technology (Intel® VT) for Directed I/O (Intel® VT-d) is extended to share the client’s CPU page-tables with Intel VT-d to perform PASID-granular DMA remapping and to help the accelerator recover from the I/O page-faults.
The accelerator uses SVM capabilities to process directly the data from the application address space. On receipt of a work descriptor, the accelerator looks-up the device translation lookaside buffer (DevTLB) for the DMA address translations; if address translations are already cached (a DevTLB hit scenario), the DMA requests are issued with the translated host physical addresses (HPA) acquired from the DevTLB. On a DevTLB miss, the accelerator issues an ATS address translation request to the IOMMU, which consults its address translation table(s) to acquire the translation. On successful translation, the returned address translation information is cached in the DevTLB, and the DMA requests are issued. On an unsuccessful translation (that is, I/O page-fault), the accelerator can issue a PRS page-request to system software to request "page-in" for the faulted page (like CPU page-fault handling). On receipt of successful page response, the accelerator reissues the address translation request to obtain the translations after the fault has been handled successfully on the host.
System software can change the application/VM page-tables by trimming the process’s working-set, handling overcommits to VMM memory, tearing down an application or a VM, and so on. If this occurs, system software tells the accelerator to invalidate the DevTLB entries associated with this change and then synchronizes the responses.
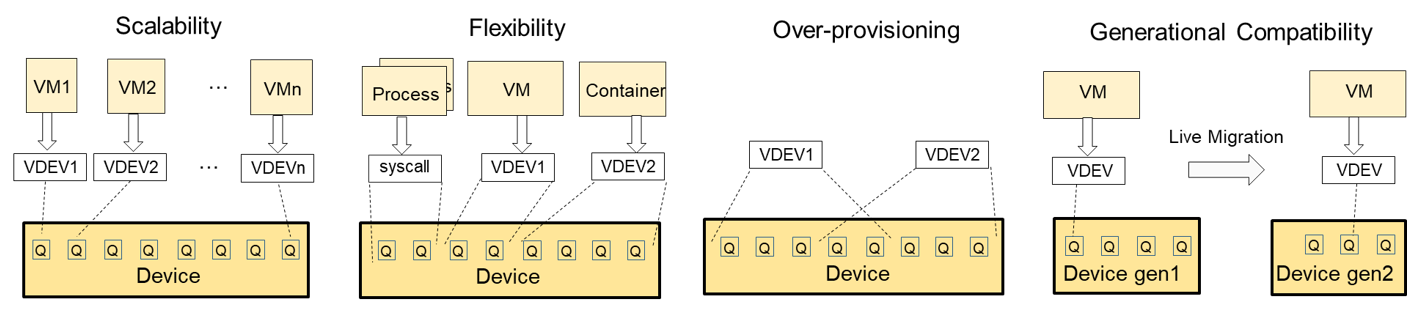
Intel® Scalable I/O Virtualization (Intel® Scalable IOV)
Intel Scalable IOV is a novel approach to hardware-assisted I/O virtualization. It enables fine-grained, flexible, high-performance sharing of I/O devices across isolated domains (applications, VMs, containers, and more), while reducing the complexity of such sharing for endpoint hardware devices. It also enables fine-grained, provisioned, device resources (for example, work queue, queue-pair, or context) to be independently assigned to client domains. Software accesses to the accelerator are categorized as either ‘direct path’ or ‘intercepted path’. Direct-path accesses (for example, work submission or work completion processing) are mapped directly to the accelerator resources for performance. The intercepted-path accesses, like configuration operations, are emulated by a virtual device composition module (VDCM) for greater flexibility. Intel Scalable IOV also extends Intel® VT-d to support PASID-granular, DMA remapping for fine-grained isolation among device resources assigned to different domains.
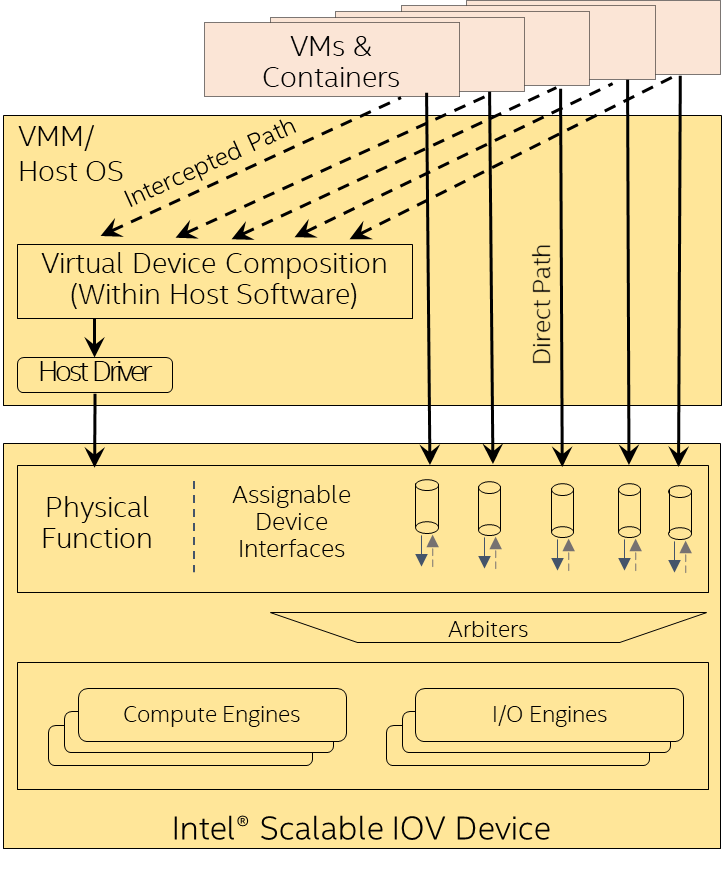
Intel Scalable IOV provides flexible sharing of device resources that have different address domains and use different abstractions, such as system calls for application processes or virtual device interfaces for VMs. It also enables dynamic mapping of VDEVs to device resources, allowing a VMM to over-provision device resources. More broadly, Intel Scalable IOV enables a VMM to maintain generational compatibility in a datacenter by using VDCM to virtualize the VDEV’s capability and present compatible VDEV capabilities irrespective of the different generations of physical I/O devices. This ensures that a given guest operating system image with a VDEV driver can be deployed or migrated to any of the physical machines.
Accelerator Interfacing Technologies with Intel® Data Streaming Accelerator
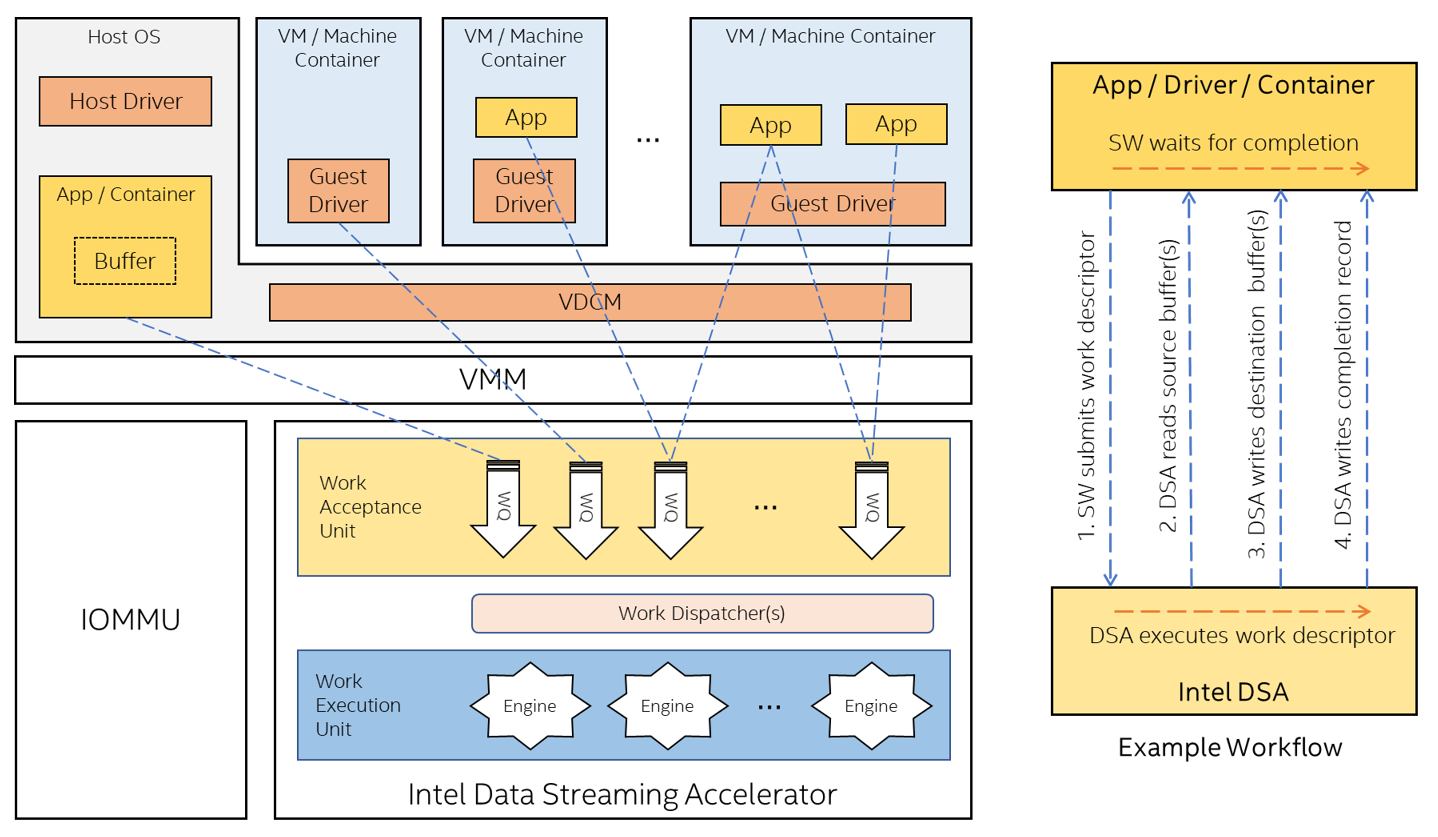
Intel® Data Streaming Accelerator (Intel® DSA), a high-performance accelerator for copying and transforming data, is integrated into upcoming Intel Xeon processors. The purpose of Intel DSA is to optimize the movement and transformation of streaming data, which is common in applications designed for high-performance storage, networking, persistent memory, and various data processing applications.
Intel DSA makes use of the accelerator-interfacing technologies stated earlier to enable efficient and scalable accelerator offload while reducing the cost and complexity associated with building such a scalable accelerator hardware.
Intel DSA supports device-hosted dedicated work queues (DWQ), which allow individual clients to own or control the flow/occupancy of their work queues, and device-hosted shared work queues (SWQ) which enable scalable sharing. As shown in the figure below, software may assign the DWQ to an individual client while map the SWQ to one or more clients. Software uses the MOVDIR64B instruction to submit 64-byte work descriptors to DWQs and ENQCMD/S instructions to submit 64-byte work descriptor to SWQs. The work descriptor can also request a completion interrupt, a completion write, or both thereby, enabling efficient synchronization via UMONITOR/UMWAIT instructions.
Intel DSA supports SVM and recoverable I/O page-faults, enabling a simplified programming model and making its adoption seamless in applications, operating systems and hypervisor software. Support for scalable I/O virtualization capabilities enable Intel DSA offload in virtual-machine or container-based deployments and make the live-migration viable while keeping the Intel DSA virtual device assigned to the VM or container.