
From traffic management to digital safety systems, computer vision techniques such as object detection have a wide range of applications but can be demanding on computer architecture. To meet these demands, Intel and Red Hat have teamed up to deliver a cloud-based platform optimized for data science operations, Red Hat OpenShift Data Science (RHODS)*. By leveraging Intel® GPUs and the Intel® Distribution of OpenVINO™ Toolkit, RHODS enables developers to seamlessly switch between CPU and GPU-based AI inference workloads to achieve more efficient object detection, faster task completion times, and lower overall utilization rates.
In this post we’ll demonstrate how to run AI inference workloads in RHODS using CPUs, and then GPUs, after a simple code change. You can follow along with the 14-minute demo on YouTube.
Leverage the power of Intel® Data Center Flex Series GPUs
The Intel Data Center GPU Flex Series offers a pair of flexible, robust GPUs designed to support AI for data centers and edge computing. The Intel® Data Center GPU Flex 140 features two GPUs per card with 8 Xe-cores per GPU (16 total), 12 GB memory, and a low profile for tight spaces. The Intel® Data Center GPU Flex 170 is a full-height, performance-focused option featuring 32 Xe-cores and up to 16 GB of memory.1 These offerings support diverse workloads: simulation and visualization, machine learning and AI inference, transcoding and streaming with support for AV1, content creation, virtual desktop infrastructure (VDI),1 and cloud gaming.
Manage GPUs in RHODS with Intel® Device Plugins Operator
RHODS provides managed tools to enable developers to develop, train, test, and scale AI workloads. One of these integrated tools is the Intel® Distribution of OpenVINO™ Toolkit, which helps accelerate development of deep learning applications from edge to cloud. When installed through RHODS, OpenVINO supports integration with Jupyter Notebooks*.
To seamlessly integrate Intel GPUs into RHODS, Intel provides a device plugin operator that exposes Intel GPU accelerators in Kubernetes* and OpenShift*. The Intel® Data Center GPU device plugin works with both integrated and discrete GPUs. To allow for greater flexibility in workload management, developers can share a GPU among containers (as long as shared-dev-num > 1) for less intensive workloads, or dedicate an entire GPU to tackle more intensive workloads.
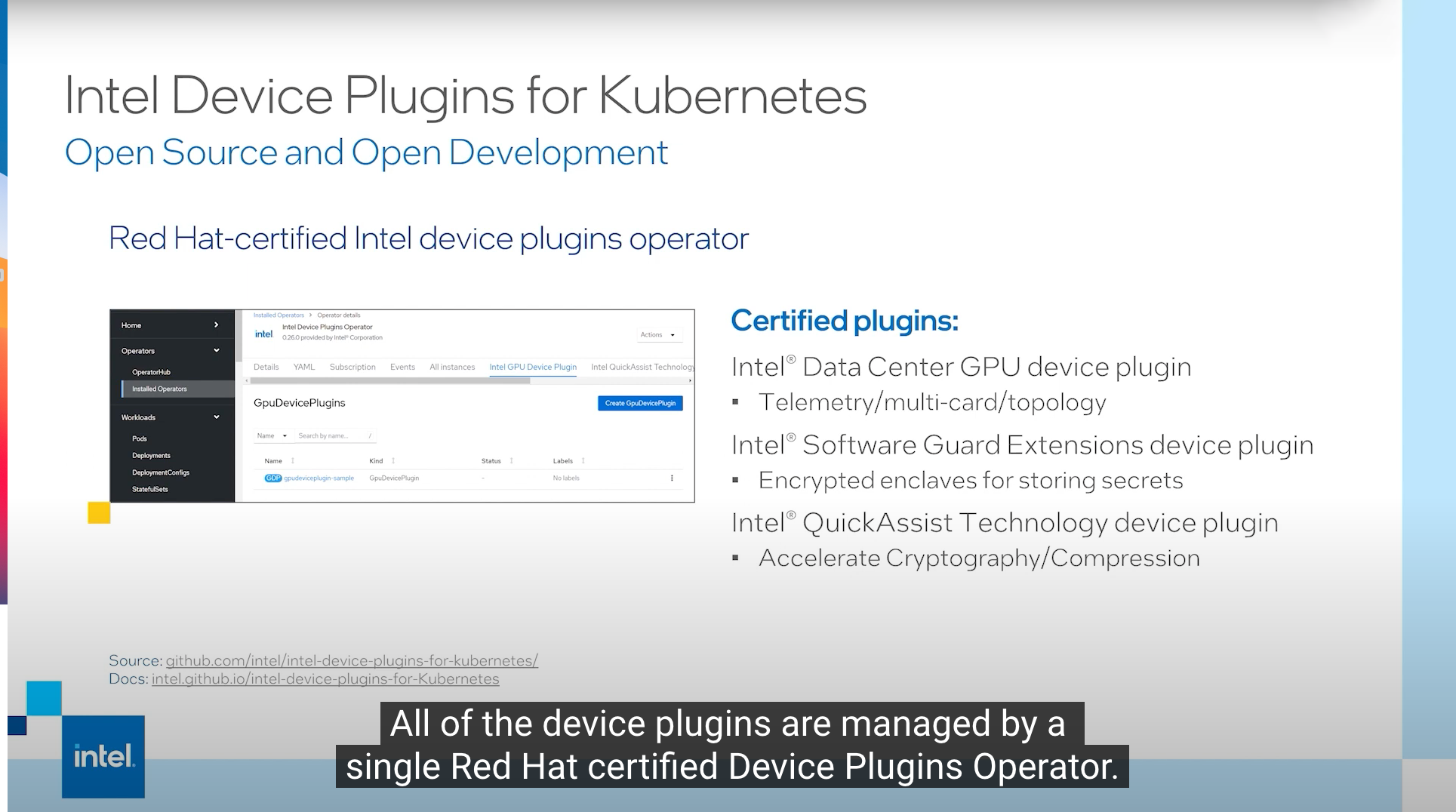
The Intel® Device Plugins operator, pictured here, enables easy plugin installation and management in a single view.
Developers can also install the Intel® Software Guard Extensions (Intel® SGX) device plugin to store encrypted data, such as the private keys for assigning certificates, and the Intel® QuickAssist Technology (Intel® QAT) device plugin, which can be used to accelerate cryptography or compression/decompression.
Installing the Intel Device Plugins operator
The Intel Device Plugins operator is in the Red Hat Ecosystem catalog. If you’re using regular Kubernetes, you can install the device plug-in operator from OperatorHub.io. This requires a Red Hat certified Node Feature Discovery operator installed within your cluster to label all the node capabilities. The plugin uses node selector to ensure that it only runs on nodes where a GPU is found.
Installing Intel GPU drivers
This demo was launched in April at KubeCon + CloudNativeCon Europe 2023, as of that date the Intel GPU driver was not fully integrated into the Red Hat core OS as an in-tree driver. Because it’s out-of-tree, you’ll need to install the Red Hat Kernel Module Management (KMM) operator. For specific Intel® technologies like SGX and QAT, you should also install Intel technologies enabling for OpenShift.
OpenVINO CPU/GPU demo setup and parameters
Improved AI performance using OpenVINO can be demonstrated by running a simple OpenVINO video on a Jupyter Notebook. For this demo we’re using a 30-second video and an object detection model for detecting classes such as person, bicycle, and car.
If you go to your compute node in the OpenShift console, then click on GPU node and then click on YAML, you can see the details of the node as Kubernetes labels. On line 47, the node is labeled with “gpu: true.” Both the GPU driver and the GPU plugin use the “gpu: true” label to know to run on this node. These labels are automatically added from the Node Feature Discovery operator.
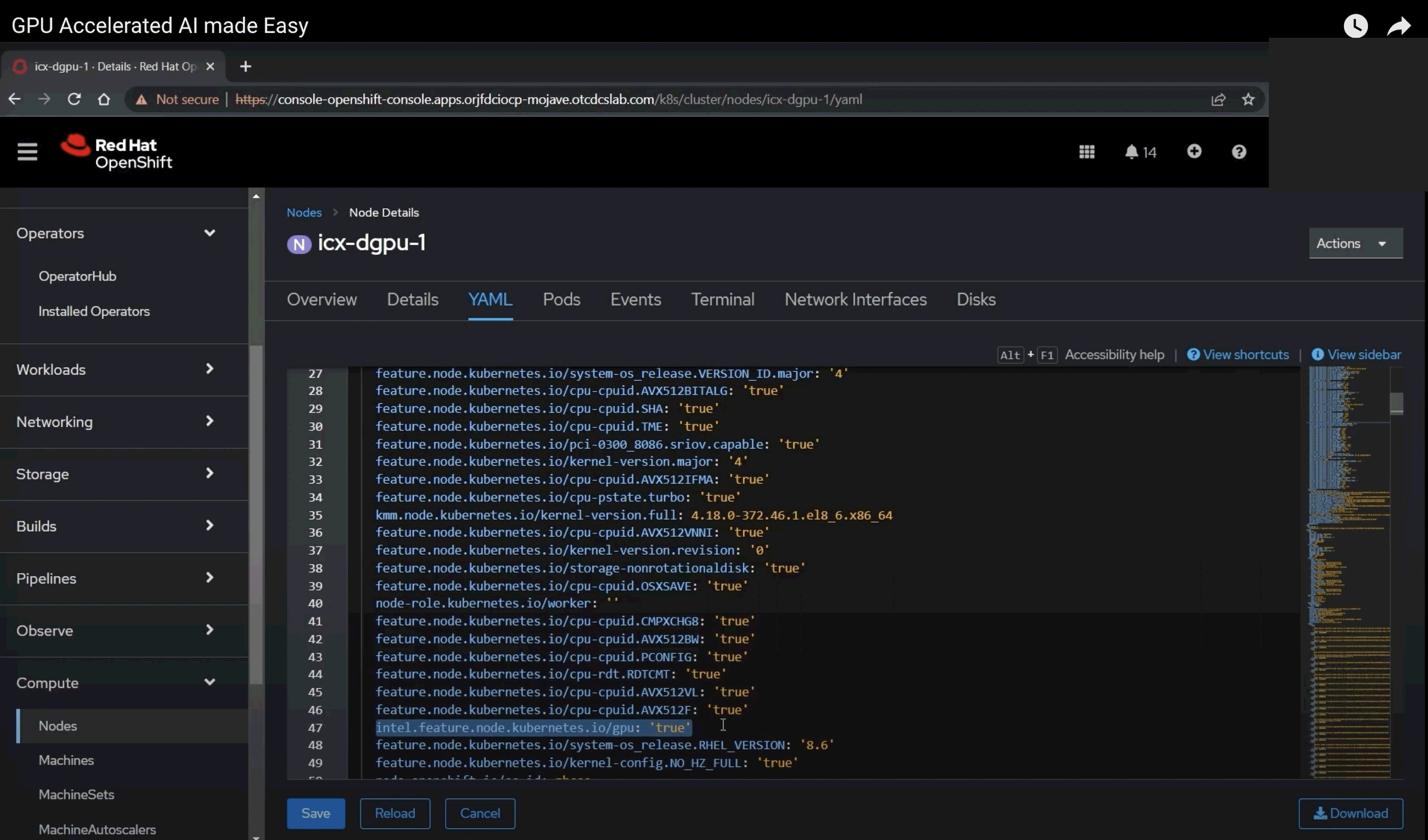
Line 47 of the node YAML code with “gpu: true” lets the GPU driver and plugin know to run on this node.
To demo the GPU offload, we’ll be using the Jupyter Notebooks plugin under the OpenVINO Toolkit Operator, located under Installed Operators in RHODS. In the Notebook YAML, under resources and requests, we have the line gpu.intel.com/i915: '1' to make sure the notebook runs as a pod on that GPU node. You can then create a notebook in the OpenVINO Operator under Notebook > Create Notebook.
Inference using the CPU
In the OpenVINO Jupyter Notebook server, we’re using an existing OpenVINO sample object detection model that’s already trained and converted to the OpenVINO intermediate representation (IR) format. Let’s start with inference using just the CPU.
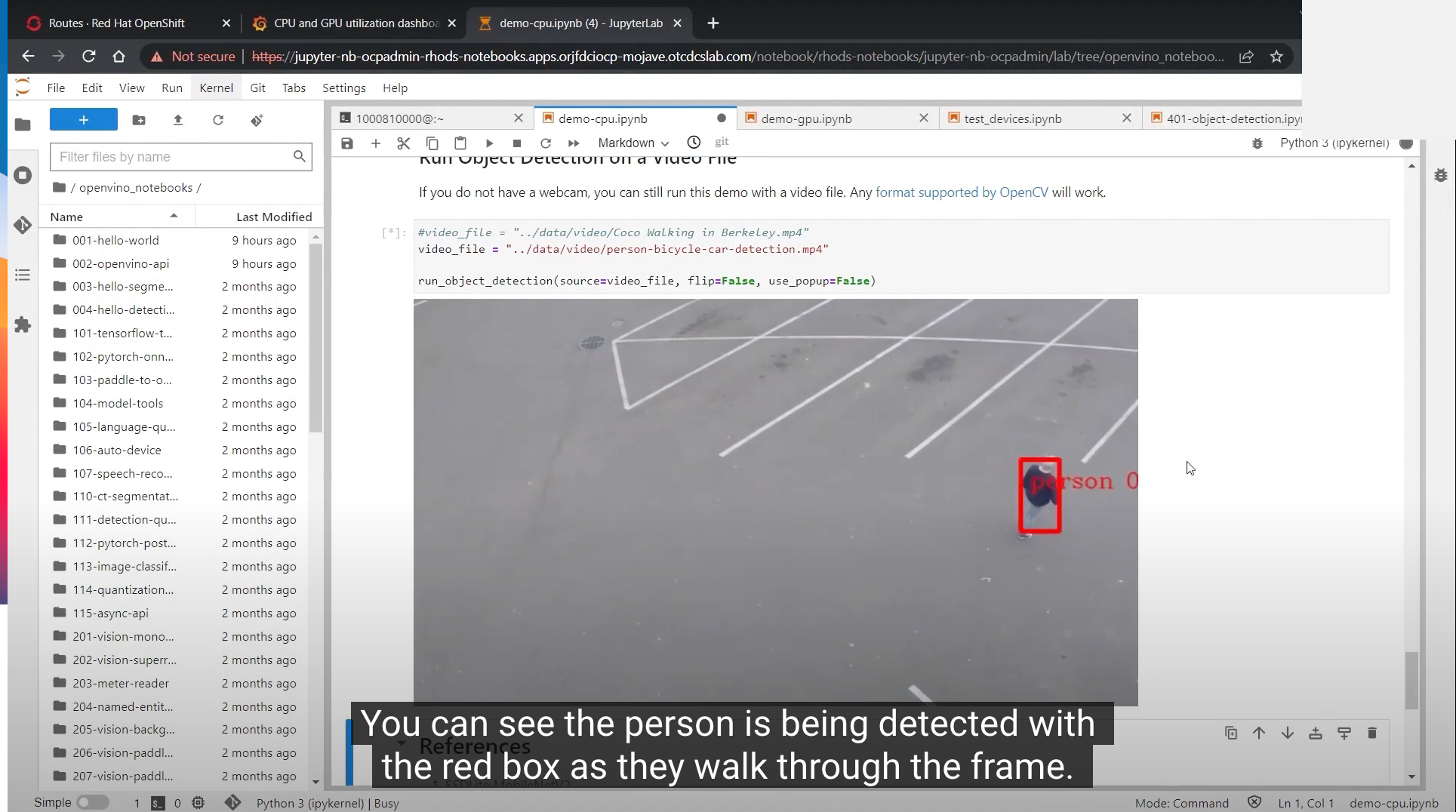
In a sample video, an object detection model has been set up to detect people, cars, bicycles, and more.
When OpenVINO uses the CPU acceleration to run the inference, the CPU utilization spikes slightly, while the GPU utilization remains at zero.
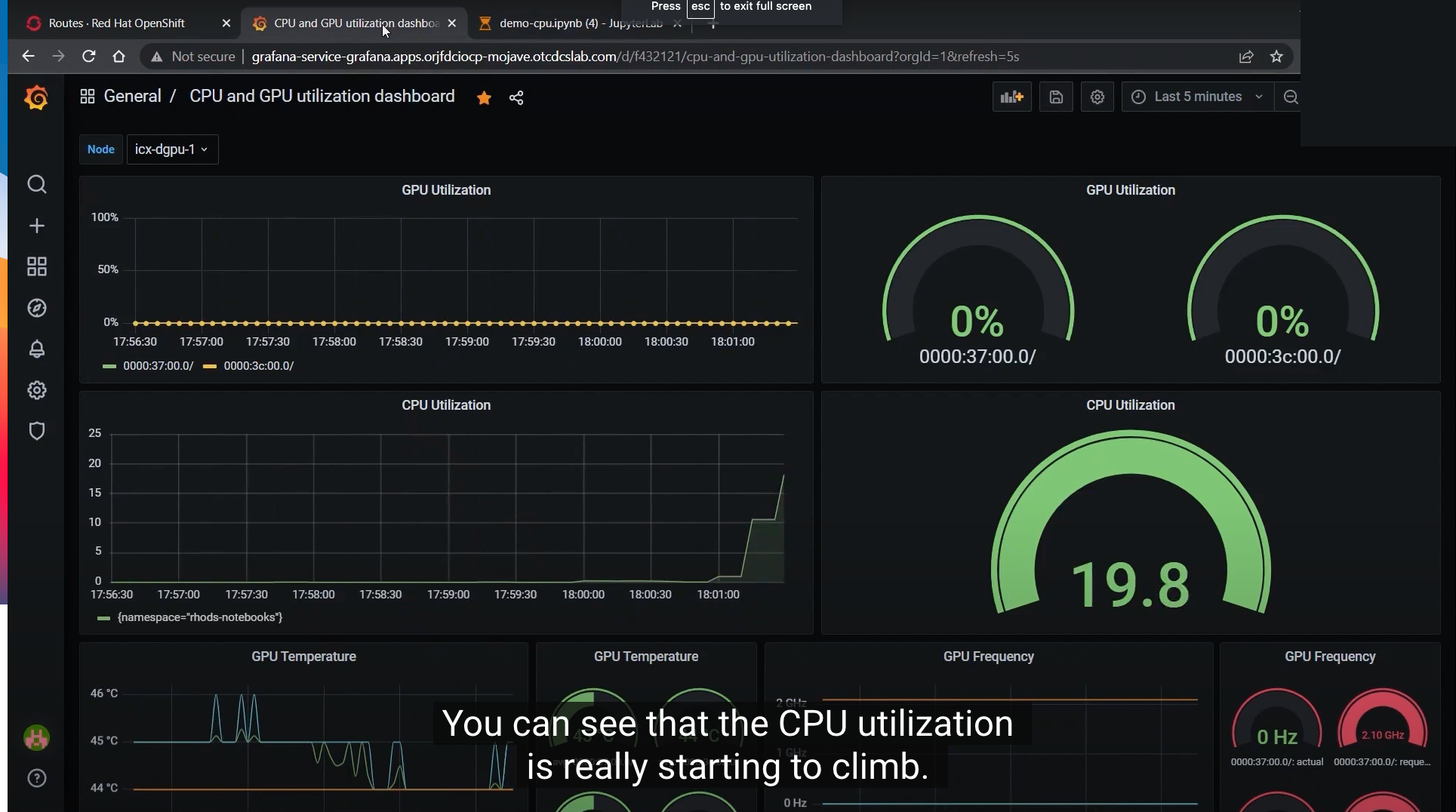
Using Grafana to monitor utilization, the object detection workload causes the CPU utilization to climb.
Inference using the GPU
Let’s repeat the same exercise using a GPU inference. In the OpenVINO cluster, a single letter change from “C” to “G” in the code switches where the workload is run.

In the “load the model section” of the OpenVINO cluster, developers can switch the workload from running on the CPU to the GPU by changing one letter.
When you run the same object detection model on the GPU, the Intel Data Center Flex Series GPU tackles the entire task on one GPU. The CPU utilization has dropped significantly while the job runs on the GPU, freeing up a significant number of CPU cycles.
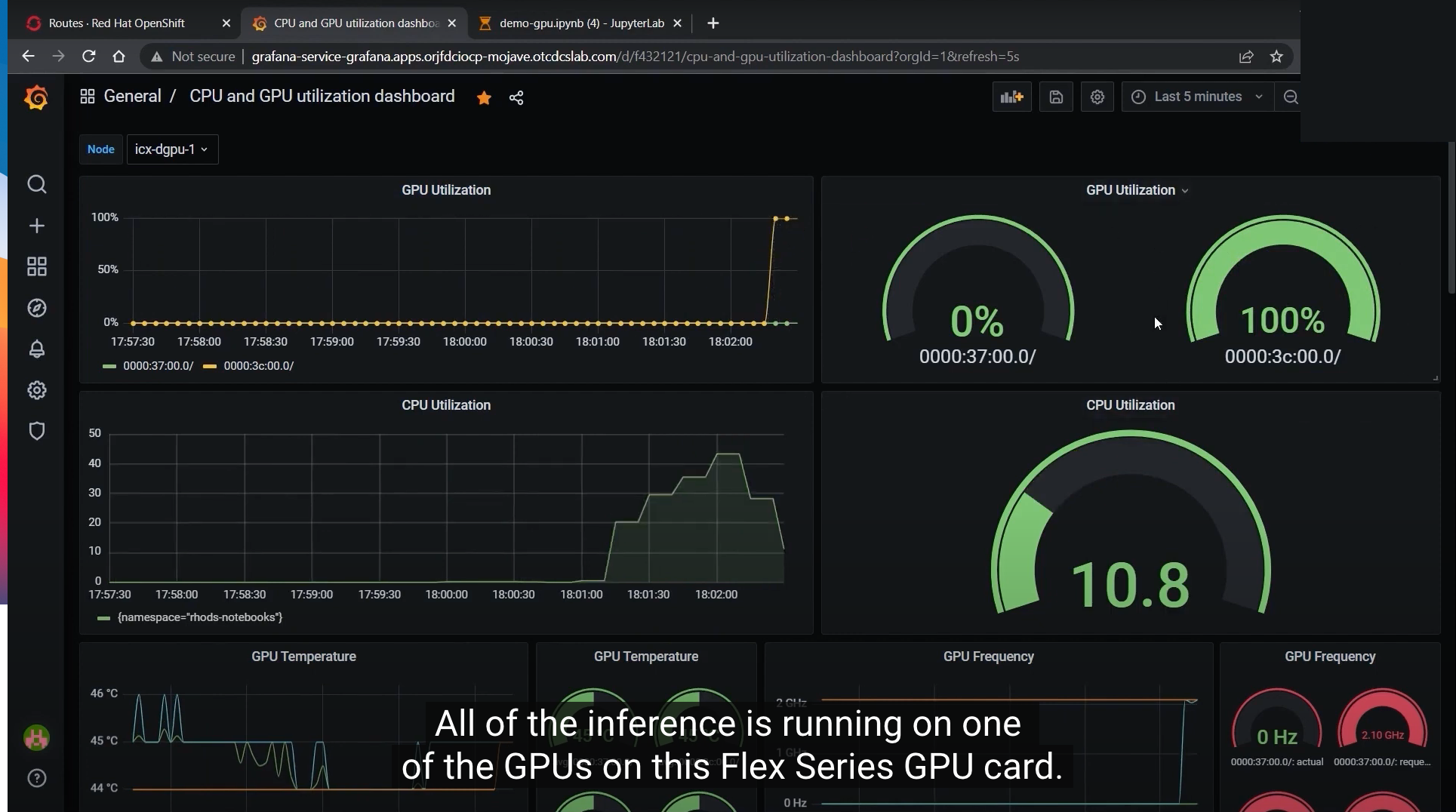
When the same workload is switched to the GPU, the entire inference can be run on one GPU at 100 percent utilization.
Learn more
The Intel Data Center GPU Flex Series, coupled with OpenShift and the OpenVINO toolkit, offers a powerful solution for accelerating AI workloads in data centers and edge computing environments. With the ability to seamlessly switch between CPU and GPU acceleration to tackle AI inference workloads more efficiently, RHODS offers developers and data scientists enhanced performance and reduced latency.
Disclaimers
- Reflects capabilities of Intel® Data Center GPU Flex Series that will be available when product is fully mature.
About the Presenter
Eric Adams is a Cloud Software Engineer at Intel, whose 21-year career at the company has spanned from software development, software validation, program management to technical marketing for both hardware and software and, most recently, focusing on Kubernetes.