This article was originally published on pytorch.org
Overview
Recent years, the growing complexity of AI models have been posing requirements on hardware for more and more compute capability. Reduced precision numeric format has been proposed to address this problem. Bfloat16 is a custom 16-bit floating point format for AI which consists of one sign bit, eight exponent bits, and seven mantissa bits. With the same dynamic range as float32, bfloat16 doesn’t require a special handling such as loss scaling. Therefore, bfloat16 is a drop-in replacement for float32 when running deep neural networks for both inference and training.
The 3rdGen Intel® Xeon® Scalable processor (codenamed Cooper Lake), is the first general purpose x86 CPU with native bfloat16 support. Three new bfloat16 instructions were introduced in Intel® Advanced Vector Extensions-512 (Intel® AVX-512): VCVTNE2PS2BF16, VCVTNEPS2BF16, and VDPBF16PS. The first two instructions perform conversion from float32 to bfloat16, and the last one performs a dot product of bfloat16 pairs. Bfloat16 theoretical compute throughput is doubled over float32 on Cooper Lake. On the next generation of Intel® Xeon® Scalable processors, bfloat16 compute throughput will be further enhanced through Intel® Advanced Matrix Extensions (Intel® AMX) instruction set extension.
Intel and Meta previously collaborated to enable bfloat16 on PyTorch*, and the related work was published in an earlier blog during launch of Cooper Lake. In that blog, we introduced the hardware advancement for native bfloat16 support and showcased a performance boost of 1.4x to 1.6x of bfloat16 over float32 from DLRM, ResNet-50 and ResNext-101-32x4d.
In this blog, we will introduce the latest software enhancement on bfloat16 in PyTorch 1.12, which would apply to much broader scope of user scenarios and showcase even higher performance boost.
Native Level Optimization on bfloat16
On PyTorch CPU bfloat16 path, the compute intensive operators, e.g., convolution, linear and bmm, use oneDNN (oneAPI Deep Neural Network Library) to achieve optimal performance on Intel CPUs with AVX512_BF16 or Intel AMX support. The other operators, such as tensor operators and neural network operators, are optimized at PyTorch native level. We have enlarged bfloat16 kernel level optimizations to majority of operators on dense tensors, both inference and training applicable (sparse tensor bfloat16 support will be covered in future work), specifically:
- Bfloat16 vectorization: Bfloat16 is stored as unsigned 16-bit integer, which requires it to be casted to float32 for arithmetic operations such as add, mul, etc. Specifically, each bfloat16 vector will be converted to two float32 vectors, processed accordingly and then converted back. While for non-arithmetic operations such as cat, copy, etc., it is a straight memory copy and no data type conversion will be involved.
- Bfloat16 reduction: Reduction on bfloat16 data uses float32 as accumulation type to guarantee numerical stability, e.g., sum, BatchNorm2d, MaxPool2d, etc.
- Channels Last optimization: For vision models, Channels Last is the preferable memory format over Channels First from performance perspective. We have implemented fully optimized CPU kernels for all the commonly used CV modules on channels last memory format, taking care of both float32 and bfloat16.
Run bfloat16 with Auto Mixed Precision
To run model on bfloat16, typically user can either explicitly convert the data and model to bfloat16, for example:
# with explicit conversion
input = input.to(dtype=torch.bfloat16)
model = model.to(dtype=torch.bfloat16)
or utilize torch.amp (Automatic Mixed Precision) package. The autocast instance serves as context managers or decorators that allow regions of your script to run in mixed precision, for example:
# with AMP
with torch.autocast(device_type="cpu", dtype=torch.bfloat16):
output = model(input)
Generally, the explicit conversion approach and AMP approach have similar performance. Even though, we recommend run bfloat16 models with AMP, because:
-
Better user experience with automatic fallback: If your script includes operators that don’t have bfloat16 support, autocast will implicitly convert them back to float32 while the explicit converted model will give a runtime error.
-
Mixed data type for activation and parameters: Unlike the explicit conversion which converts all the model parameters to bfloat16, AMP mode will run in mixed data type. To be specific, input/output will be kept in bfloat16 while parameters, e.g., weight/bias, will be kept in float32. The mixed data type of activation and parameters will help improve performance while maintaining the accuracy.
Performance Gains
We benchmarked inference performance of TorchVision models on Intel® Xeon® Platinum 8380H processor at 2.90 GHz (codenamed Cooper Lake), single instance per socket (batch size = 2 x number of physical cores). Results show that bfloat16 has 1.4x to 2.2x performance gain over float32.
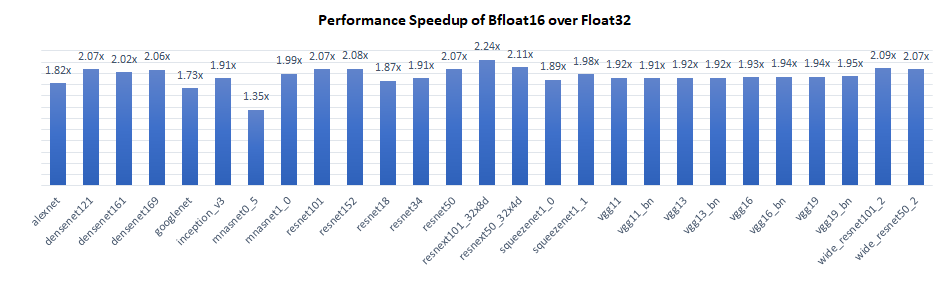
The Performance Boost Of bfloat16 Over float32 Primarily Comes From 3 Aspects:
- The compute intensive operators take advantage of the new bfloat16 native instruction VDPBF16PS which doubles the hardware compute throughput.
- Bfloat16 have only half the memory footprint of float32, so theoretically the memory bandwidth intensive operators will be twice faster.
- On Channels Last, we intentionally keep the same parallelization scheme for all the memory format aware operators (can’t do this on Channels First though), which increases the data locality when passing each layer’s output to the next. Basically, it keeps the data closer to CPU cores while data would reside in cache anyway. And bfloat16 will have a higher cache hit rate compared with float32 in such scenarios due to smaller memory footprint.
Conclusion and Future Work
In this blog, we introduced recent software optimizations on bfloat16 introduced in PyTorch 1.12. Results on the 3rdGen Intel® Xeon® Scalable processor show that bfloat16 has 1.4x to 2.2x performance gain over float32 on the TorchVision models. Further improvement is expected on the next generation of Intel® Xeon® Scalable Processors with Intel AMX instruction support. Though the performance number for this blog is collected with TorchVision models, the benefit is broad across all topologies. And we will continue to extend the bfloat16 optimization effort to a broader scope in the future!
Acknowledgment
The results presented in this blog is a joint effort of Meta and Intel PyTorch team. Special thanks to Vitaly Fedyunin and Wei Wei from Meta who spent precious time and gave substantial assistance! Together we made one more step on the path of improving the PyTorch CPU ecosystem.